SET: Stream-Event-Triggered Scheduling for Efficient CUDA Graph Pipelines
Pith reviewed 2026-06-28 03:56 UTC · model grok-4.3
The pith
A multi-stream CUDA pipeline model with event-chaining and work-stealing reduces host-device synchronization delays and raises throughput on GPU graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
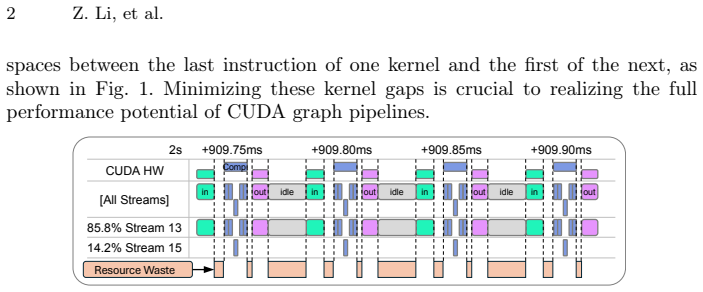
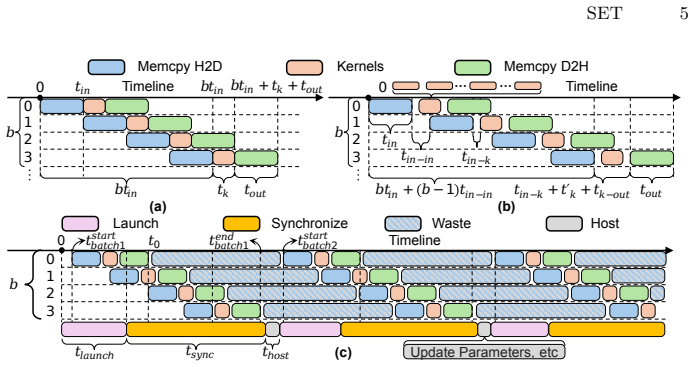
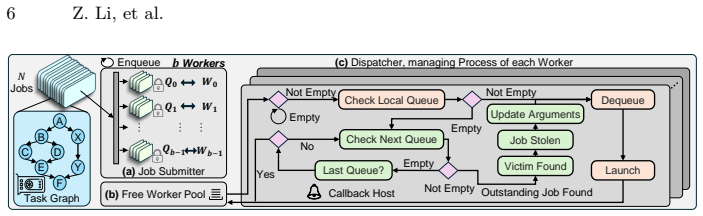
The paper claims that combining a multi-stream task-parallel pipeline model, which uses event-chaining to link dependent tasks and work-stealing to balance load across streams, with a graph-based execution flow that maintains per-stream buffers, removes most host-device synchronization points and closes execution gaps. This setup keeps multiple in-flight jobs running safely on the same GPU while fully occupying compute cores and copy engines.
What carries the argument
The multi-stream task-parallel pipeline model with event-chaining for dependency signaling, work-stealing for dynamic load balance, and per-stream buffers inside a graph-based execution flow.
If this is right
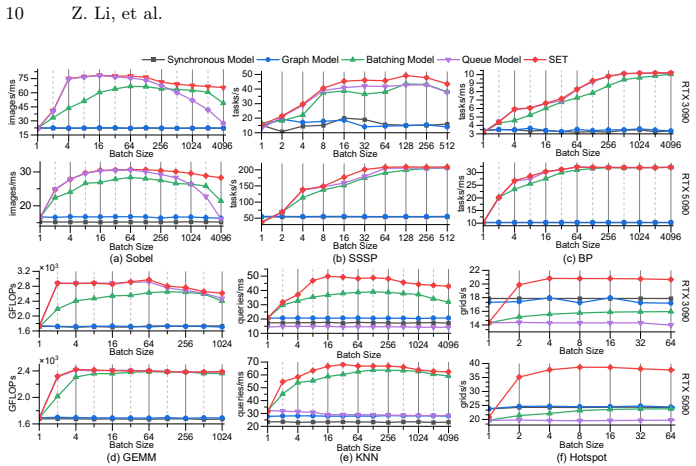
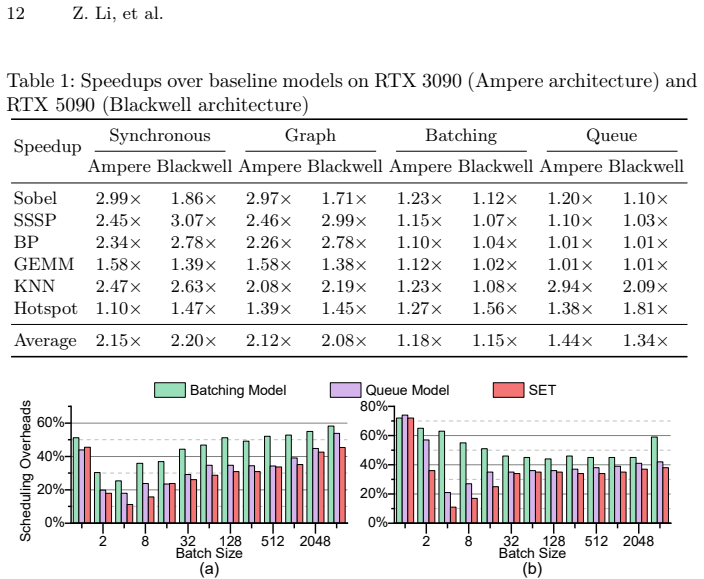
- Scheduling overhead drops 18-54% compared with current CUDA graph methods.
- Overall throughput rises 1.15-1.44X on representative workloads.
- Compute cores and copy engines stay occupied with smaller gaps between kernel launches.
- Multiple jobs can remain in flight without losing memory safety.
Where Pith is reading between the lines
- The same event-trigger pattern might reduce idle time in multi-GPU systems where streams span devices.
- Work-stealing could be tested on workloads whose task sizes vary more widely than the evaluated set.
- If buffer management scales, the model may support finer-grained tasks than current graph limits allow.
Load-bearing premise
Event-chaining and work-stealing across multiple streams can keep all hardware units busy while per-stream buffers still prevent memory conflicts among concurrent jobs.
What would settle it
Running the same real-world workloads on unmodified CUDA graph baselines and measuring whether the 1.15-1.44X speedups and 18-54% overhead reductions disappear.
Figures
read the original abstract
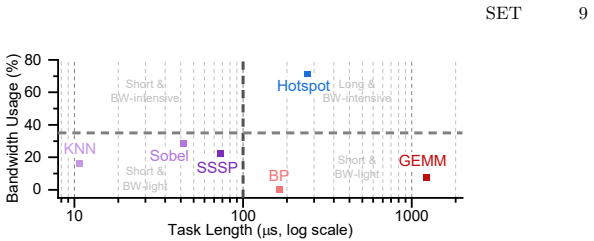
Achieving peak GPU performance remains a significant challenge as the system throughput is constrained by host-device synchronization delays and kernel scheduling overheads, even with aggressive kernel optimizations and batch processing. Furthermore, existing approaches often underutilize hardware resources such as compute cores and copy engines due to scheduling overheads. To address these problems, we propose a CUDA runtime framework for task-parallel pipelines to minimize the synchronization overheads and the gap between kernel executions. The proposed solution combines two innovations: (1) a multi-stream task-parallel pipeline programming model that leverages event-chaining and work-stealing mechanisms to fully utilize available hardware resources; (2) a graph-based execution flow with per-stream buffers to ensure memory safety for multiple in-flight jobs running concurrently. Extensive evaluations on representative real-world workloads show 1.15--1.44X speedup and reduce scheduling overheads by 18--54% compared to state-of-the-art CUDA graph baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SET, a CUDA runtime framework for task-parallel pipelines. It combines a multi-stream programming model that uses event-chaining and work-stealing to improve hardware utilization with a graph-based execution model that employs per-stream buffers to maintain memory safety for concurrent in-flight jobs. The central empirical claim is that this approach delivers 1.15--1.44X speedups and reduces scheduling overheads by 18--54% relative to state-of-the-art CUDA graph baselines on representative real-world workloads.
Significance. If the reported speedups and overhead reductions prove robust under detailed scrutiny, the work would offer a practical improvement to GPU pipeline efficiency by reducing host-device synchronization and kernel-launch costs, which remains a recurring bottleneck in high-performance CUDA applications.
major comments (1)
- [Evaluation (abstract and §5)] The abstract states speedups and overhead reductions from evaluations, but supplies no details on experimental setup, error bars, workload selection criteria, or statistical significance. This absence prevents verification of the central performance claims.
minor comments (1)
- Clarify the precise definition of 'scheduling overhead' (e.g., whether it includes only launch latency or also includes event synchronization costs) to allow direct comparison with prior CUDA-graph work.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our experimental reporting. We address the single major comment below and will revise the manuscript accordingly to strengthen verifiability of the reported results.
read point-by-point responses
-
Referee: [Evaluation (abstract and §5)] The abstract states speedups and overhead reductions from evaluations, but supplies no details on experimental setup, error bars, workload selection criteria, or statistical significance. This absence prevents verification of the central performance claims.
Authors: We agree that the abstract, constrained by length, omits these specifics, and that Section 5 should be expanded for full verifiability. The manuscript already describes the workloads, hardware platform, and measurement approach in §5, but does not report error bars from repeated runs, explicit workload selection criteria, or statistical tests. We will revise §5 to add: (1) error bars computed over at least five independent runs per configuration, (2) explicit criteria used to select the representative real-world workloads, and (3) any statistical significance analysis performed. If space allows, we will also insert a short clause in the abstract referencing these details. These changes directly address the referee's concern without altering the core claims. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external baselines
full rationale
The paper describes a CUDA runtime framework with two innovations (multi-stream pipeline model using event-chaining/work-stealing, and graph-based execution with per-stream buffers) followed by empirical speedups measured against state-of-the-art CUDA graph baselines. No equations, fitted parameters, self-citations, or derivation steps are referenced in the provided text. The central performance claims are externally falsifiable via direct comparison to independent implementations and do not reduce to internal definitions or self-referential predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CUDA streams and events can be chained and used with work-stealing while preserving memory safety for concurrent jobs.
Reference graph
Works this paper leans on
-
[1]
Augonnet, C., et al.: StarPU: A Unified Platform for Task Scheduling on Hetero- geneous Multicore Architectures, pp. 863–874. Springer Berlin Heidelberg (2009). https://doi.org/10.1007/978-3-642-03869-3_80 14 Z. Li, et al
-
[2]
In: 2012 International Conference for High Performance Computing, Networking, Storage and Analysis
Bauer, M., Treichler, S., Slaughter, E., Aiken, A.: Legion: Expressing locality and independence with logical regions. In: 2012 International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE (Nov 2012). https://doi.org/10.1109/sc.2012.71
-
[3]
Quarterly of Applied Mathematics16(1), 87– 90 (Apr 1958)
Bellman, R.: On a routing problem. Quarterly of Applied Mathematics16(1), 87– 90 (Apr 1958). https://doi.org/10.1090/qam/102435
-
[4]
https://docs.nvidia.com/cuda/ cuda-c-programming-guide/index.html (Oct 2025), accessed: Nov
Corp., N.: Cuda c++ programming guide. https://docs.nvidia.com/cuda/ cuda-c-programming-guide/index.html (Oct 2025), accessed: Nov. 3, 2025
2025
-
[5]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Dao, T., et al.: Flashattention: Fast and memory-efficient exact attention with IO-awareness. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022), https://openreview.net/forum? id=H4DqfPSibmx
2022
-
[6]
Ekelund, J., Markidis, S., Peng, I.: Boosting performance of iterative applications on gpus: Kernel batching with cuda graphs. In: 2025 33rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP). pp. 70–77. IEEE (Mar 2025). https://doi.org/10.1109/pdp66500.2025.00019
-
[7]
Guevara, M., et al.: Enabling task parallelism in the cuda scheduler (2009), https: //api.semanticscholar.org/CorpusID:306206
2009
-
[8]
Guo, G., Wang, H., Bell, D., Bi, Y., Greer, K.: KNN Model-Based Approach in Classification, pp. 986–996. Springer Berlin Heidelberg (2003). https://doi.org/10. 1007/978-3-540-39964-3_62
2003
-
[9]
IEEE Transactions on Parallel and Distributed Systems33(6), 1303–1320 (Jun 2022)
Huang, T.W., Lin, D.L., Lin, C.X., Lin, Y.: Taskflow: A lightweight parallel and heterogeneous task graph computing system. IEEE Transactions on Parallel and Distributed Systems33(6), 1303–1320 (Jun 2022). https://doi.org/10.1109/tpds. 2021.3104255
-
[10]
IEEE Transactions on Very Large Scale Integration (VLSI) Sys- tems14(5), 501–513 (May 2006)
Huang, W., et al.: Hotspot: a compact thermal modeling methodology for early- stage vlsi design. IEEE Transactions on Very Large Scale Integration (VLSI) Sys- tems14(5), 501–513 (May 2006). https://doi.org/10.1109/tvlsi.2006.876103
-
[11]
McGraw-Hill international editions, McGraw- Hill, New York [u.a.], [nachdr.] edn
Mitchell, T.M.: Machine learning. McGraw-Hill international editions, McGraw- Hill, New York [u.a.], [nachdr.] edn. (2013)
2013
-
[12]
https: //doi.org/10.13140/RG.2.1.1912.4965
Sobel, I., Feldman, G.: An isotropic 3x3 image gradient operator (2015). https: //doi.org/10.13140/RG.2.1.1912.4965
-
[13]
Steinberger, M., Kainz, B., Kerbl, B., Hauswiesner, S., Kenzel, M., Schmalstieg, D.: Softshell: dynamic scheduling on gpus. ACM Transactions on Graphics31(6), 1–11 (Nov 2012). https://doi.org/10.1145/2366145.2366180
-
[14]
ACM Transactions on Graphics33(6), 1–11 (Nov 2014)
Steinberger, M., et al.: Whippletree: task-based scheduling of dynamic workloads on the gpu. ACM Transactions on Graphics33(6), 1–11 (Nov 2014). https://doi. org/10.1145/2661229.2661250
-
[15]
Wang, G., Lin, Y., Yi, W.: Kernel fusion: An effective method for better power efficiency on multithreaded gpu. In: 2010 IEEE/ACM International Conference on Green Computing and Communications & International Conference on Cyber, Physical and Social Computing. pp. 344–350. IEEE (Dec 2010). https: //doi.org/10.1109/greencom-cpscom.2010.102
-
[16]
In: 56th Annual IEEE/ACM International Symposium on Microarchitecture
Zheng, B., et al.: Grape: Practical and efficient graphed execution for dynamic deep neural networks on gpus. In: 56th Annual IEEE/ACM International Symposium on Microarchitecture. pp. 1364–1380. MICRO ’23, ACM (Oct 2023). https://doi. org/10.1145/3613424.3614248
-
[17]
IEEE Transactions on Parallel and Distributed Systems 25(6), 1522–1532 (Jun 2014)
Zhong, J., He, B.: Kernelet: High-throughput gpu kernel executions with dynamic slicing and scheduling. IEEE Transactions on Parallel and Distributed Systems 25(6), 1522–1532 (Jun 2014). https://doi.org/10.1109/tpds.2013.257
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.