Understanding CDCL Solvers via Scalability Studies and Proofdoors
Pith reviewed 2026-05-19 15:24 UTC · model grok-4.3
The pith
Proofdoors explain why CDCL solvers scale linearly on some bounded model checking instances but exponentially on others.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CDCL solvers compute small proofdoors for linearly-scaling BMC instances; for exponentially-scaling instances the sampled proofdoors grow exponentially and are typically not incrementally absorbed; scrambling a linearly-scaling instance produces larger proofdoors and degrades solver performance.
What carries the argument
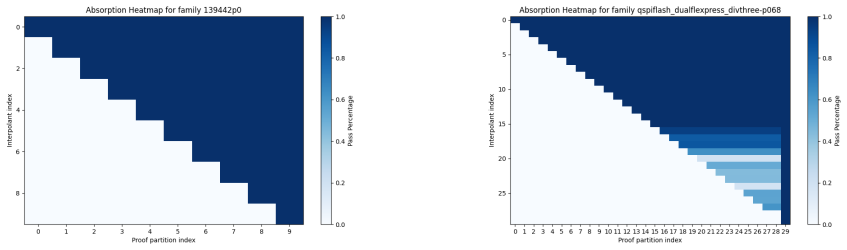
A proofdoor is a sequence of interpolants between successive chunks of the input formula, each interpolant standing for the memoization of reasoning already performed on earlier chunks.
If this is right
- Linear scaling arises when the solver maintains small proofdoors across formula chunks.
- Exponential scaling arises when proofdoors grow exponentially and are not absorbed incrementally.
- Altering branching order by scrambling enlarges proofdoors and converts linear scaling into worse scaling.
Where Pith is reading between the lines
- Estimating proofdoor size before search could serve as a practical predictor of which BMC instances will be easy for CDCL.
- Solver heuristics could be redesigned to favor decisions that keep emerging proofdoors small.
- The same chunk-wise memoization idea might be tested on other structured formula families outside bounded model checking.
Load-bearing premise
The sampled interpolants computed between formula chunks faithfully represent the memoization that actually occurs inside the running CDCL solver.
What would settle it
Measure the actual interpolants produced by a CDCL solver on a linearly scaling BMC instance and find that they are large, or find that a small, incrementally absorbed proofdoor exists for an instance that scales exponentially.
Figures



read the original abstract
Over the past several decades, CDCL SAT solvers have proven remarkably effective on large industrial formulas, despite SAT being NP-complete and widely believed to be intractable. While considerable empirical research has been done on solver performance over benchmarks like the SAT competition, as well as scaling studies on random and crafted families, surprisingly little effort has gone into systematic scaling studies over industrial instances. To address this gap, we collect a large benchmark of Bounded Model Checking (BMC) instances (76,600+ across 766 families) and perform a systematic scaling study of solver performance. We observe a spectrum: some families scale linearly, others polynomially or exponentially. Building on this foundation, we study the structural parameters that have been proposed to explain this phenomenon. We first show that previously proposed parameters -- clause-variable ratio, treewidth, and community structure -- fail to discriminate between the linear and exponential regimes. By contrast, the recently proposed \emph{proofdoor} parameter explains this phenomenon well. Informally, a proofdoor is a sequence of interpolants between chunks of a formula, where each interpolant represents the solver's memoization of reasoning effort on chunks it has already analyzed. In support of the proofdoor hypothesis, we make three key contributions. First, we empirically show that CDCL solvers do compute small proofdoors for linearly-scaling BMC instances. Second, we show that for exponentially-scaling instances, sampled proofdoors scale exponentially and are typically not incrementally absorbed. Third, we show that scrambling linearly-scaling instances yields larger proofdoor sizes relative to pre-scrambling, relating poor branching order to larger proofdoor sizes and drop in solver performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale empirical scaling study of CDCL SAT solvers on a benchmark of 76,600+ BMC instances across 766 families, identifying linear, polynomial, and exponential regimes. It evaluates structural parameters and finds that clause-variable ratio, treewidth, and community structure fail to discriminate regimes, while the recently proposed proofdoor parameter (sequences of interpolants between formula chunks, each representing solver memoization) succeeds. Three supporting results are reported: small proofdoors on linear-scaling instances, exponential growth and poor absorption on hard instances, and larger proofdoors after scrambling.
Significance. If the representational link holds, the work supplies a novel, empirically grounded structural parameter that distinguishes scaling behavior on industrial instances where prior parameters do not. The size of the BMC benchmark and the direct measurements of proofdoor sizes constitute a clear strength, offering concrete, falsifiable predictions about when CDCL will scale linearly.
major comments (2)
- The central explanatory claim requires that sampled interpolants between formula chunks accurately reconstruct the solver's internal memoization and branching decisions. However, the construction is performed externally via chosen chunking and interpolation; no evidence is supplied that the resulting objects correspond to lemmas actually computed or absorbed by a running CDCL solver, nor that chunk boundaries align with the solver's variable decisions and clause-learning process. This assumption is load-bearing for the linear-vs-exponential discrimination and is not addressed by the benchmark correlations alone.
- Methodological details on proofdoor sampling, interpolation computation, and statistical controls are insufficient. Without these, it is difficult to assess reproducibility or to rule out that the reported size differences are artifacts of the external sampling procedure rather than reflections of actual solver behavior.
minor comments (3)
- The informal definition of a proofdoor in the abstract would benefit from a precise formal statement or explicit pointer to the original proposal, including how interpolants are extracted from the formula chunks.
- Related-work discussion should more explicitly contrast the proofdoor hypothesis with prior structural explanations such as backdoors or resolution-width measures.
- Scaling plots would be clearer if they included variance or confidence intervals for the sampled proofdoor sizes across multiple runs or instances.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important aspects of the proofdoor hypothesis that we will clarify in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: The central explanatory claim requires that sampled interpolants between formula chunks accurately reconstruct the solver's internal memoization and branching decisions. However, the construction is performed externally via chosen chunking and interpolation; no evidence is supplied that the resulting objects correspond to lemmas actually computed or absorbed by a running CDCL solver, nor that chunk boundaries align with the solver's variable decisions and clause-learning process. This assumption is load-bearing for the linear-vs-exponential discrimination and is not addressed by the benchmark correlations alone.
Authors: We agree that direct correspondence between externally computed interpolants and internal CDCL lemmas is not demonstrated in the current manuscript. The proofdoor is introduced as a hypothesized structural parameter whose size is measured via interpolation on fixed chunk boundaries chosen to reflect BMC structure. The reported results show consistent correlations: small proofdoors on linear-scaling families, exponential growth and poor absorption on hard families, and increased sizes after scrambling. These patterns support the model but do not constitute direct validation of internal solver state. In revision we will add an explicit limitations subsection that (a) states the external nature of the construction, (b) explains why BMC chunking is a reasonable proxy given the sequential unrolling, and (c) outlines future instrumentation experiments that could test alignment with learned clauses. We believe the existing empirical discrimination remains valuable as a falsifiable prediction even under the acknowledged modeling assumptions. revision: partial
-
Referee: Methodological details on proofdoor sampling, interpolation computation, and statistical controls are insufficient. Without these, it is difficult to assess reproducibility or to rule out that the reported size differences are artifacts of the external sampling procedure rather than reflections of actual solver behavior.
Authors: We accept this criticism and will substantially expand the methods section. The revision will include: precise definition of chunk boundaries for BMC instances, the interpolation algorithm employed together with any simplifications, the exact procedure for measuring and aggregating proofdoor sizes (including absorption checks), and the statistical tests used to compare regimes. We will also release the full sampling scripts and a reproducibility package. These additions should allow independent verification that the observed size differences are not artifacts of the chosen procedure. revision: yes
Circularity Check
No circularity: empirical correlation between independently measured scaling and sampled proofdoor sizes
full rationale
The paper first measures solver runtime scaling (linear vs. exponential) directly on a large set of BMC instances. It then defines proofdoors via external interpolant sampling between formula chunks and reports that the resulting sizes correlate with the observed scaling regimes. This correlation is not forced by construction because the scaling data and the interpolant sizes are obtained through separate procedures; the definition of proofdoor as representing memoization is an interpretive hypothesis tested against the data rather than a self-referential fit or renaming of the scaling itself. No load-bearing step reduces to a self-citation chain or fitted parameter renamed as prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CDCL solvers perform clause learning and backtracking search on SAT formulas
invented entities (1)
-
proofdoor
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a proofdoor is a sequence of interpolants between chunks of a formula, where each interpolant represents the solver's memoization of reasoning effort on chunks it has already analyzed
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
small proofdoors if it has a proofdoor with parameters (c, w, s) satisfying c=O(n), w=O(log n), s=O(log n)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proofdoors and Efficiency of CDCL Solvers
Sunidhi Singh et al. “Proofdoors and Efficiency of CDCL Solvers”. In:28th International Confer- ence on Theory and Applications of Satisfiability Testing (SAT 2026). To appear. Preprint: https:// arxiv.org/abs/2603.26286. 2026
-
[2]
Bounded Model Checking Using Satisfiability Solving
Edmund Clarke et al. “Bounded Model Checking Using Satisfiability Solving”. In:Formal Methods in System Design19.1 (2001), pp. 7–34.DOI: 10. 1023/A:1011276507260
work page 2001
-
[3]
Benefits of bounded model checking at an industrial setting
Fady Copty et al. “Benefits of bounded model checking at an industrial setting”. In:Interna- tional Conference on Computer Aided Verifica- tion. Springer. 2001, pp. 436–453
work page 2001
-
[4]
The Complexity of Theorem- Proving Procedures
Stephen A. Cook. “The Complexity of Theorem- Proving Procedures”. In:Proceedings of the Third Annual ACM Symposium on Theory of Computing (STOC ’71). ACM, 1971, pp. 151–158.DOI: 10. 1145/800157.805047
-
[5]
On the Unreasonable Effectiveness of SAT Solvers
Vijay Ganesh and Moshe Y . Vardi. “On the Unreasonable Effectiveness of SAT Solvers”. In: Beyond the Worst-Case Analysis of Algorithms. Ed. by Tim Roughgarden. Cambridge Univer- sity Press, 2021, pp. 547–566.DOI: 10 . 1017 / 9781108637435.032
work page 2021
-
[6]
Understanding and Enhancing CDCL-based SAT Solvers
Edward Zulkoski. “Understanding and Enhancing CDCL-based SAT Solvers”. PhD thesis. Univer- sity of Waterloo, 2018.URL: https : / / uwspace . uwaterloo.ca/handle/10012/13525
work page 2018
-
[8]
The Effect of Structural Measures and Merges on SAT Solver Perfor- mance
Edward Zulkoski et al. “The Effect of Structural Measures and Merges on SAT Solver Perfor- mance”. In:Principles and Practice of Constraint Programming (CP). V ol. 11008. Lecture Notes in Computer Science. Springer, 2018, pp. 436–452. DOI: 10.1007/978-3-319-98334-9 29
-
[9]
Impact of Community Structure on SAT Solver Performance
Zack Newsham et al. “Impact of Community Structure on SAT Solver Performance”. In:Theory and Applications of Satisfiability Testing (SAT). Ed. by Carsten Sinz and Uwe Egly. V ol. 8561. Lecture Notes in Computer Science. Springer, 2014, pp. 252–268.DOI: 10 . 1007 / 978 - 3 - 319 - 09284-3 20
work page 2014
-
[10]
Community Structure in Industrial SAT Instances
Carlos Ans ´otegui, Maria Luisa Bonet, and Jordi Levy. “Community Structure in Industrial SAT Instances”. In:Theory and Applications of Satisfi- ability Testing (SAT). Lecture Notes in Computer Science. Extended version: arXiv:1606.03329. Springer, 2012
-
[11]
Marijn J. H. Heule et al., eds.Proceedings of SAT Competition 2024: Solver, Benchmark and Proof Checker Descriptions. V ol. B-2024-1. De- partment of Computer Science Report Series B. Department of Computer Science, University of Helsinki, 2024
work page 2024
-
[12]
Hardware Model Checking Competition 2019 (HWMCC’19)
Armin Biere, Nils Froleyks, and Mathias Preiner. Hardware Model Checking Competition 2019 (HWMCC’19). http : / / fmv . jku . at / hwmcc19/. Accessed: 2026-05-08. 2019
work page 2019
-
[13]
Yibo Dong et al.SuperCAR: A Hardware Model Checker Based on CAR. https : / / github . com / lijwen2748 / hwmcc24. Submission to the Hardware Model Checking Competition 2024 (HWMCC’24), 3rd place in the bit-level track. Software Engineering Institute, East China Nor- mal University. 2024
work page 2024
-
[15]
Clause-Learning Algorithms with Many Restarts and Bounded-Width Resolution
Albert Atserias, Johannes Klaus Fichte, and Marc Thurley. “Clause-Learning Algorithms with Many Restarts and Bounded-Width Resolution”. In: Journal of Artificial Intelligence Research40 (2011), pp. 353–373.DOI: 10.1613/JAIR.3152
-
[16]
Constraint satisfaction, bounded treewidth, and finite-variable logics
V ´ıctor Dalmau, Phokion G Kolaitis, and Moshe Y Vardi. “Constraint satisfaction, bounded treewidth, and finite-variable logics”. In:International Con- ference on Principles and Practice of Constraint Programming. Springer. 2002, pp. 310–326
work page 2002
-
[18]
Predicting Learnt Clauses Quality in Modern SAT Solvers
Gilles Audemard and Laurent Simon. “Predicting Learnt Clauses Quality in Modern SAT Solvers”. In:Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI). 2009, pp. 399–404
work page 2009
-
[19]
Improving SAT Solvers by Ex- ploiting Empirical Characteristics of CDCL
Chanseok Oh. “Improving SAT Solvers by Ex- ploiting Empirical Characteristics of CDCL”. PhD thesis. New York University, 2016
work page 2016
-
[21]
Robert Mateescu.Treewidth in Industrial SAT Benchmarks. Tech. rep. MSR-TR-2011-22. Cam- bridge, UK: Microsoft Research, Feb. 2011. URL: https : / / www . microsoft . com / en - us / research/publication/treewidth- in- industrial- sat- benchmarks/
work page 2011
-
[22]
Where the Really Hard Problems Are
Peter Cheeseman, Bob Kanefsky, and William M. Taylor. “Where the Really Hard Problems Are”. In:Proceedings of the 12th International Joint Conference on Artificial Intelligence (IJCAI’91). V ol. 1. Sydney, Australia: Morgan Kaufmann, 1991, pp. 331–337.URL: https://www.ijcai.org/ Proceedings/91-1/Papers/052.pdf
work page 1991
-
[23]
Community Structure in Industrial SAT Instances
Carlos Ans ´otegui et al. “Community Structure in Industrial SAT Instances”. In:Journal of Artificial Intelligence Research66 (2019), pp. 443–472. DOI: 10.1613/JAIR.1.11741
-
[24]
Hard and Easy Distributions of SAT Problems
David Mitchell, Bart Selman, and Hector Levesque. “Hard and Easy Distributions of SAT Problems”. In:Proceedings of the 10th National Conference on Artificial Intelligence (AAAI’92). 1992, pp. 459–465
work page 1992
-
[25]
Hardness of Random Re- ordered Encodings of Parity for Resolution and CDCL
Leroy Chew et al. “Hardness of Random Re- ordered Encodings of Parity for Resolution and CDCL”. In:Proceedings of the 38th AAAI Con- ference on Artificial Intelligence (AAAI’24). 2024. DOI: 10.1609/aaai.v38i8.28635
-
[26]
Serge Gaspers and Stefan Szeider. “Strong Back- doors to Bounded Treewidth SAT”. In:IEEE Symposium on Foundations of Computer Science (FOCS). 2013, pp. 489–498.DOI: 10.1109/FOCS. 2013.59
-
[27]
Hall.Lie Groups, Lie Algebras, and Representations: An Elementary Introduction
Carlos Ans ´otegui et al. “Using Community Struc- ture to Detect Relevant Learnt Clauses”. In: Theory and Applications of Satisfiability Testing (SAT). 2015, pp. 238–254.DOI: 10.1007/978-3- 319-24318-4 18
-
[28]
Backdoors To Typical Case Complexity
Ryan Williams, Carla P. Gomes, and Bart Sel- man. “Backdoors To Typical Case Complexity”. In:International Joint Conference on Artificial Intelligence (IJCAI). 2003, pp. 1173–1178
work page 2003
-
[29]
2016.Practical Hadoop Ecosystem: A Definitive Guide to Hadoop- Related Frameworks and Tools(1st ed.)
Edward Zulkoski et al. “Learning-Sensitive Back- doors with Restarts”. In:Principles and Prac- tice of Constraint Programming – CP 2018. Ed. by John N. Hooker. V ol. 11008. Lecture Notes in Computer Science. Cham: Springer, 2018, pp. 453–469.DOI: 10.1007/978- 3- 319- 98334- 9 30
-
[30]
Backbones and Backdoors in Satisfiability
Philip Kilby et al. “Backbones and Backdoors in Satisfiability”. In:Proceedings of the Twenti- eth National Conference on Artificial Intelligence (AAAI 2005). Pittsburgh, Pennsylvania, USA: AAAI Press, 2005, pp. 1368–1373
work page 2005
-
[31]
On the Power of Clause-Learning SAT Solvers
Katsumi Pipatsrisawat and Adnan Darwiche. “On the Power of Clause-Learning SAT Solvers”. In: Proceedings of the 13th International Conference on Principles and Practice of Constraint Pro- gramming (CP). 2007, pp. 654–668
work page 2007
-
[32]
Vijay D’Silva et al. “Interpolant Strength”. In: Verification, Model Checking, and Abstract Inter- pretation, 11th International Conference, VMCAI 2010, Madrid, Spain, January 17-19, 2010. Pro- ceedings. Ed. by Gilles Barthe and Manuel V . Hermenegildo. V ol. 5944. Lecture Notes in Com- puter Science. Springer, 2010, pp. 129–145.DOI: 10.1007/978-3-642-11319-2\ 12
-
[33]
Interpolation and SAT- Based Model Checking
Kenneth L. McMillan. “Interpolation and SAT- Based Model Checking”. In:Computer Aided Verification, 15th International Conference, CAV 2003, Boulder, CO, USA, July 8-12, 2003, Pro- ceedings. Ed. by Warren A. Hunt Jr. and Fabio Somenzi. V ol. 2725. Lecture Notes in Computer Science. Springer, 2003, pp. 1–13.DOI: 10.1007/ 978-3-540-45069-6\ 1
work page 2003
-
[34]
On the Power of Clause-Learning SAT Solvers as Res- olution Engines
Knot Pipatsrisawat and Adnan Darwiche. “On the Power of Clause-Learning SAT Solvers as Res- olution Engines”. In:Artificial Intelligence175.2 (2011), pp. 512–525
work page 2011
-
[35]
Richard E. Barlow et al.Statistical Inference under Order Restrictions: The Theory and Ap- plication of Isotonic Regression. London and New York: John Wiley & Sons, 1972.ISBN: 9780471049708
work page 1972
-
[36]
Tim Robertson, F. T. Wright, and Richard L. Dykstra.Order Restricted Statistical Inference. Chichester: John Wiley & Sons, 1988.ISBN: 9780471917878
work page 1988
-
[37]
Parakram Majumdar.FactorGraph: Factor graph algorithm for existential quantification on boolean formulae. https : / / github . com / appu226 / FactorGraph. Accessed: 2026-05-08. 2024
work page 2026
-
[38]
Manthan: A Data-Driven Approach for Boolean Function Synthesis
Priyanka Golia, Subhajit Roy, and Kuldeep S. Meel. “Manthan: A Data-Driven Approach for Boolean Function Synthesis”. In:Proceedings of the International Conference on Computer-Aided Verification (CAV). July 2020.DOI: 10 . 48550 / arXiv.2005.06922. arXiv: 2005.06922[cs.AI]
-
[39]
In: Chockler, H., Weissenbacher, G
S. Akshay et al. “What’s Hard About Boolean Functional Synthesis?” In:Computer Aided Ver- ification. V ol. 10981. Lecture Notes in Computer Science. Cham: Springer, 2018, pp. 251–269.DOI: 10.1007/978-3-319-96145-3 14
-
[40]
Leonardo de Moura and Nikolaj Bjørner. “Z3: An Efficient SMT Solver”. In:Tools and Algorithms 11 for the Construction and Analysis of Systems (TACAS). V ol. 4963. Lecture Notes in Computer Science. Springer, 2008, pp. 337–340.DOI: 10. 1007/978-3-540-78800-3\ 24
work page 2008
-
[41]
Consequence Finding Algo- rithms
Pierre Marquis. “Consequence Finding Algo- rithms”. In:Handbook of Defeasible Reasoning and Uncertainty Management Systems, Volume
- [42]
-
[43]
Adnan Darwiche and Pierre Marquis. “A Knowl- edge Compilation Map”. In:Journal of Artificial Intelligence Research17 (2002), pp. 229–264. Fig. 5: A family of BMC formulas where scalability is different for odd and even unfolding depths VII. APPENDIX A. Parity-Bifurcated Families Surprisingly, some families exhibit parity-dependent scaling: solving time on...
work page 2002
-
[44]
LetV A = Var(A),V B = Var(B), and Vs =V A ∩V B denote theshared variables
Setup:LetAandBbe CNF formulas withA∧B unsatisfiable. LetV A = Var(A),V B = Var(B), and Vs =V A ∩V B denote theshared variables. LetL A = VA \V s denote thelocal variablesofA. Definition VII.1(DP-style strongest interpolant).LetI s be the CNF formula obtained by applying Bounded Vari- able Elimination (BVE) with full Cartesian product (i.e., Davis–Putnam r...
-
[45]
Main Theorem: Theorem VII.1.IfFabsorbsI s, then for every CNF interpolantIof(A, B),FabsorbsI. The proof rests on two ingredients: prime-implicate completeness of Davis–Putnam resolution, and a mono- tonicity property of unit propagation under clause sub- sumption. Lemma VII.2(Prime-implicate completeness of DP). For every clauseCoverV s withA|=C, there ex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.