λ-PSD: Scalable Approximate SNR-Optimised Polynomial Stein Discrepancies
Pith reviewed 2026-06-26 03:55 UTC · model grok-4.3
The pith
Reformulating polynomial Stein discrepancies as explicit SNR² maximisation yields a covariance-aware reweighting scheme that stabilises signal-to-noise ratio under Gaussian assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
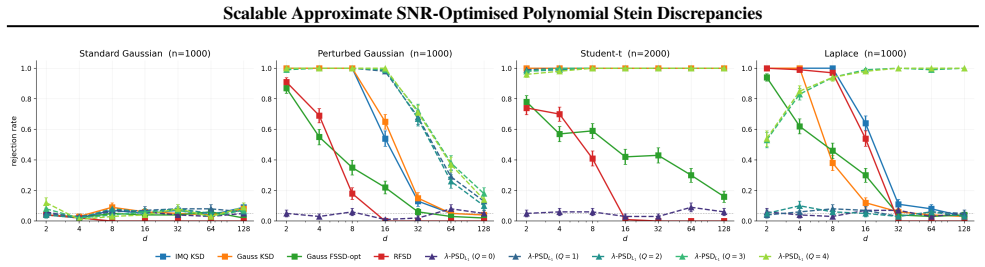
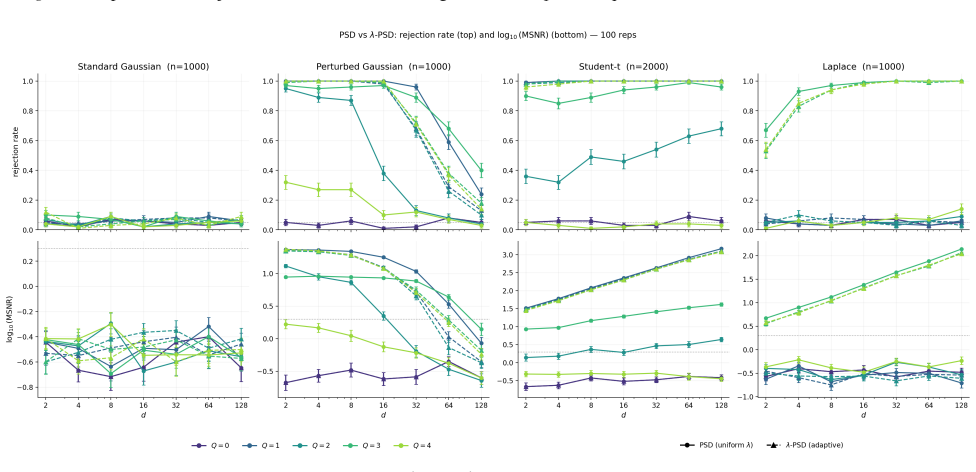
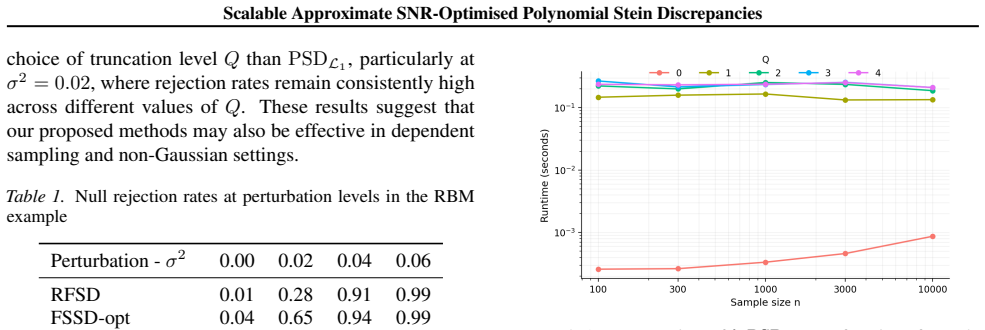
Increasing polynomial degree in PSD primarily amplifies signal without controlling variance, which under suitable assumptions can cause SNR² to decay exponentially with degree. Reformulating the discrepancy as an explicit SNR² maximisation problem produces a Rayleigh quotient over Stein features. This leads to λ-PSD, an approximate scalable covariance-aware reweighting scheme in a low-dimensional subspace. Under Gaussian settings λ-PSD avoids the exponential SNR² collapse and maintains a stable SNR² while delivering substantially higher test power at linear cost in the number of samples.
What carries the argument
λ-PSD, the approximate covariance-aware reweighting scheme defined in a low-dimensional subspace that solves the Rayleigh quotient for SNR² maximisation.
If this is right
- Under Gaussian data the SNR² of λ-PSD stays stable as polynomial degree grows instead of decaying exponentially.
- Goodness-of-fit tests based on λ-PSD achieve higher power than standard PSD while keeping linear runtime in sample count.
- The same linear-time scaling and SNR-aware construction apply to measuring sample quality.
- The Rayleigh-quotient view supplies an explicit optimisation target that replaces ad-hoc degree selection.
Where Pith is reading between the lines
- The subspace-reweighting idea could be tested on mildly non-Gaussian targets to check whether stability persists beyond the stated Gaussian case.
- Choosing the subspace dimension becomes a practical hyper-parameter whose effect on power and runtime could be mapped empirically.
- Similar covariance-aware reweighting might be applied to other scalable Stein or discrepancy constructions that currently suffer variance inflation.
Load-bearing premise
The low-dimensional subspace approximation together with the Gaussian setting must hold for the claimed avoidance of exponential SNR² collapse.
What would settle it
A direct computation of SNR² versus polynomial degree on Gaussian data that shows continued exponential decay for λ-PSD would refute the stability claim.
Figures

read the original abstract
Polynomial Stein discrepancies (PSD) provide a scalable alternative to kernel Stein methods for measuring sample quality and goodness-of-fit testing, but their statistical properties remain poorly understood. We show that increasing polynomial degree primarily amplifies signal without adequately controlling variance, rather than directly optimising the signal-to-noise ratio (SNR). Under suitable assumptions, this might lead to a failure mode in which the $\text{SNR}^2$ can provably decay exponentially with polynomial degree. Motivated by this observation, we reformulate Stein discrepancy construction as an explicit $\text{SNR}^2$ maximisation problem, yielding a Rayleigh quotient over Stein features. This perspective motivates $\lambda$-PSD, an approximate scalable covariance-aware reweighting scheme defined in a low-dimensional subspace. Under Gaussian settings, we show that $\lambda$-PSD avoids the exponential $\text{SNR}^2$ collapse and achieves a stable $\text{SNR}^2$. Empirically, $\lambda$-PSD substantially improves test power while retaining linear-time complexity in the number of samples, highlighting the importance of SNR-aware design for scalable Stein discrepancies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces λ-PSD, a scalable approximate covariance-aware reweighting of polynomial Stein discrepancies (PSD) obtained by reformulating discrepancy construction as an explicit SNR² maximization problem (a Rayleigh quotient over Stein features). It shows that standard PSD can exhibit exponential SNR² decay with polynomial degree under suitable assumptions, proposes a low-dimensional subspace approximation for the reweighting, and proves that λ-PSD stabilizes SNR² under Gaussian settings while retaining linear time complexity; empirical results indicate substantially higher test power.
Significance. If the central claims hold, the work supplies a principled SNR-aware design principle for Stein discrepancies that directly targets the signal-to-noise tradeoff rather than signal strength alone. This addresses a documented limitation of existing polynomial Stein methods and yields a practical, linear-time procedure with improved power for goodness-of-fit testing. The explicit Gaussian restriction and subspace approximation are clearly scoped, and the reproducible linear-time property is a concrete strength.
major comments (1)
- [Abstract / Rayleigh quotient derivation] Abstract and the section deriving the exponential SNR² collapse: the proof that standard PSD suffers exponential decay is stated only under the Gaussian/low-dimensional regime; the manuscript must clarify whether the data-driven covariance estimate used for reweighting is computed on the same samples that enter the discrepancy, as this could introduce circular dependence that undermines the claimed stability (see also the Rayleigh-quotient formulation).
minor comments (2)
- Notation for the Stein features and the subspace projection should be introduced with a single consistent definition before the Rayleigh-quotient step to avoid reader confusion.
- The empirical section would benefit from reporting the precise polynomial degrees and subspace dimensions used in the power comparisons so that the linear-time claim can be directly verified.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the helpful comment on clarifying the scope of our results and the covariance estimation details. We address the point below and will incorporate the necessary clarifications in the revision.
read point-by-point responses
-
Referee: [Abstract / Rayleigh quotient derivation] Abstract and the section deriving the exponential SNR² collapse: the proof that standard PSD suffers exponential decay is stated only under the Gaussian/low-dimensional regime; the manuscript must clarify whether the data-driven covariance estimate used for reweighting is computed on the same samples that enter the discrepancy, as this could introduce circular dependence that undermines the claimed stability (see also the Rayleigh-quotient formulation).
Authors: We thank the referee for this observation. The exponential SNR² decay result for standard PSD is derived under Gaussian assumptions in a low-dimensional regime, as already indicated in the relevant sections; we will revise the abstract and introduction to state this regime explicitly and without ambiguity. Regarding the covariance estimate, it is computed from the same samples that enter the discrepancy. However, λ-PSD applies this estimate only within a low-dimensional subspace approximation to the Rayleigh quotient, and the stability guarantee under Gaussian settings is established directly for this approximate procedure. The subspace construction ensures that the reweighting stabilizes SNR² without the dependence undermining the result. We will add a clarifying paragraph in the methods and theory sections describing the estimation step and its relation to the Rayleigh quotient, confirming that the claimed properties hold for the implemented estimator. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reformulates Stein discrepancy as explicit SNR² maximization yielding a Rayleigh quotient, then defines λ-PSD as an approximate covariance-aware scheme in low-dimensional subspace, and shows under Gaussian settings it avoids exponential collapse while retaining linear complexity. No quoted equations or steps reduce by construction to inputs (no self-definitional fits, no fitted parameters renamed as predictions, no load-bearing self-citations). The central claims rest on the stated Gaussian regime and subspace approximation rather than circular dependence on the target result itself, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda
axioms (2)
- domain assumption Suitable assumptions under which SNR² can provably decay exponentially with polynomial degree
- domain assumption Gaussian settings for proving stable SNR²
Reference graph
Works this paper leans on
-
[1]
The Polynomial
Narayan Srinivasan and Matthew Sutton and Christopher Drovandi and Leah F South , booktitle=. The Polynomial
-
[2]
and Oates, Chris J
Bhattacharya, Anirban and Linero, Antonio R. and Oates, Chris J. , title =. International Society for Bayesian Analysis , volume =
-
[3]
Statistical Science , volume=
Inference from iterative simulation using multiple sequences , author=. Statistical Science , volume=. 1992 , publisher=
1992
-
[4]
Semi-exact control functionals from
South, Leah F and Karvonen, Toni and Nemeth, Chris and Girolami, Mark and Oates, Chris J , journal=. Semi-exact control functionals from. 2022 , publisher=
2022
-
[5]
Rank-normalization, folding, and localization: An improved
Vehtari, Aki and Gelman, Andrew and Simpson, Daniel and Carpenter, Bob and B. Rank-normalization, folding, and localization: An improved. Bayesian Analysis , volume=. 2021 , publisher=
2021
-
[6]
Handbook of
Brooks, Steve and Gelman, Andrew and Jones, Galin and Meng, Xiao-Li , year=. Handbook of
-
[7]
A Conceptual Introduction to Hamiltonian Monte Carlo
A conceptual introduction to Hamiltonian Monte Carlo , author=. arXiv preprint arXiv:1701.02434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Handbook of markov chain monte carlo , pages=
MCMC using Hamiltonian dynamics , author=. Handbook of markov chain monte carlo , pages=. 2011 , publisher=
2011
-
[9]
, author=
The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. , author=. J. Mach. Learn. Res. , volume=
-
[10]
Journal of statistical software , volume=
Stan: A probabilistic programming language , author=. Journal of statistical software , volume=
-
[11]
Measuring sample quality with
Gorham, Jackson and Mackey, Lester , journal=. Measuring sample quality with
-
[12]
2004 , publisher=
Information theory and the central limit theorem , author=. 2004 , publisher=
2004
-
[13]
Postprocessing of
South, Leah F and Riabiz, Marina and Teymur, Onur and Oates, Chris J , journal=. Postprocessing of. 2022 , publisher=
2022
-
[14]
Advances in Applied Probability , volume=
Integral probability metrics and their generating classes of functions , author=. Advances in Applied Probability , volume=. 1997 , publisher=
1997
-
[15]
The Journal of Machine Learning Research , volume=
A kernel two-sample test , author=. The Journal of Machine Learning Research , volume=. 2012 , publisher=
2012
-
[16]
2009 , publisher=
Optimal transport: old and new , author=. 2009 , publisher=
2009
-
[17]
Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, Volume 2: Probability theory , volume=
A bound for the error in the normal approximation to the distribution of a sum of dependent random variables , author=. Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, Volume 2: Probability theory , volume=. 1972 , organization=
1972
-
[18]
Advances in Neural Information Processing Systems , volume=
A linear-time kernel goodness-of-fit test , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
2017 , organization=
Measuring sample quality with kernels , author=. 2017 , organization=
2017
-
[20]
A kernelized
Liu, Qiang and Lee, Jason and Jordan, Michael , booktitle=. A kernelized. 2016 , organization=
2016
-
[21]
Stochastic gradient
Nemeth, Christopher and Fearnhead, Paul , journal=. Stochastic gradient. 2021 , publisher=
2021
-
[22]
Stein variational gradient descent: A general purpose
Liu, Qiang and Wang, Dilin , journal=. Stein variational gradient descent: A general purpose
-
[23]
Artificial Intelligence and Statistics , pages=
Black-box importance sampling , author=. Artificial Intelligence and Statistics , pages=. 2017 , organization=
2017
-
[24]
Proceedings of the 28th
Bayesian learning via stochastic gradient Langevin dynamics , author=. Proceedings of the 28th
-
[25]
2016 , organization=
A kernel test of goodness of fit , author=. 2016 , organization=
2016
-
[26]
Large sample analysis of the median heuristic
Large sample analysis of the median heuristic , author=. arXiv preprint arXiv:1707.07269 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
European Journal of Operational Research , volume=
Optimization of computer simulation models with rare events , author=. European Journal of Operational Research , volume=. 1997 , publisher=
1997
-
[28]
Methodology and computing in applied probability , volume=
The cross-entropy method for combinatorial and continuous optimization , author=. Methodology and computing in applied probability , volume=. 1999 , publisher=
1999
-
[29]
2004 , publisher=
The cross-entropy method: a unified approach to combinatorial optimization, Monte-Carlo simulation, and machine learning , author=. 2004 , publisher=
2004
-
[30]
, author=
Solution of incorrectly formulated problems and the regularization method. , author=. Sov Dok , volume=
-
[31]
Technometrics , volume=
Ridge regression: Biased estimation for nonorthogonal problems , author=. Technometrics , volume=. 1970 , publisher=
1970
-
[32]
Journal of multivariate analysis , volume=
A well-conditioned estimator for large-dimensional covariance matrices , author=. Journal of multivariate analysis , volume=. 2004 , publisher=
2004
-
[33]
Statistical applications in genetics and molecular biology , volume=
A shrinkage approach to large-scale covariance matrix estimation and implications for functional genomics , author=. Statistical applications in genetics and molecular biology , volume=. 2005 , publisher=
2005
-
[34]
Learning the
Grathwohl, Will and Wang, Kuan-Chieh and Jacobsen, J. Learning the. 2020 , organization=
2020
-
[35]
Breakthroughs in statistics: Foundations and basic theory , pages=
A class of statistics with asymptotically normal distribution , author=. Breakthroughs in statistics: Foundations and basic theory , pages=. 1992 , publisher=
1992
-
[36]
International Conference on Learning Representations , year=
Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy , author=. International Conference on Learning Representations , year=
-
[37]
Journal of Multivariate Analysis , volume=
Dependent wild bootstrap for degenerate U-and V-statistics , author=. Journal of Multivariate Analysis , volume=. 2013 , publisher=
2013
-
[38]
Repasky, Matthew and Cheng, Xiuyuan and Xie, Yao , journal=. Neural. 2023 , publisher=
2023
-
[39]
Random feature
Huggins, Jonathan and Mackey, Lester , journal=. Random feature
-
[40]
Control Variates for
South, Leah and Sutton, Matthew , journal=. Control Variates for
-
[41]
Advances in Neural Information Processing Systems , volume=
A note on sparse generalized eigenvalue problem , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Sparse generalized eigenvalue problem: Optimal statistical rates via truncated
Tan, Kean Ming and Wang, Zhaoran and Liu, Han and Zhang, Tong , journal=. Sparse generalized eigenvalue problem: Optimal statistical rates via truncated. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.