ExSpike: A General Full-Event Neuromorphic Architecture for Exploiting Irregular Sparsity with Event Compression
Pith reviewed 2026-06-26 15:17 UTC · model grok-4.3
The pith
ExSpike enables pure event-driven execution across all layers of spiking neural networks by optimizing dataflow and compressing adjacent spikes, delivering up to 10 times higher PE-normalized energy efficiency than prior FPGA accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
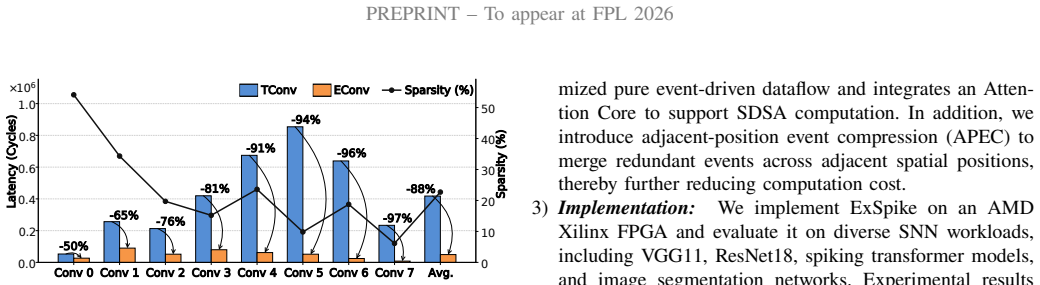
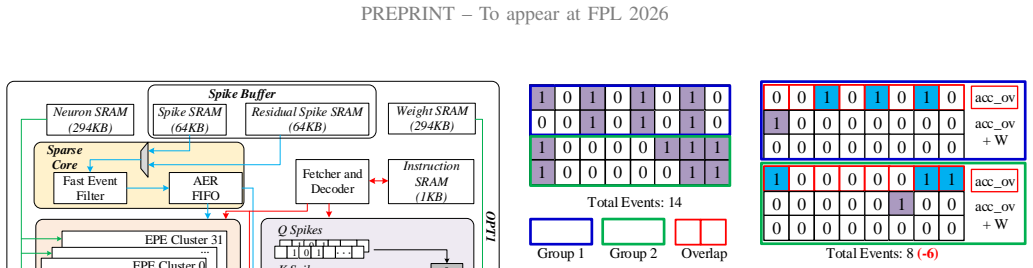
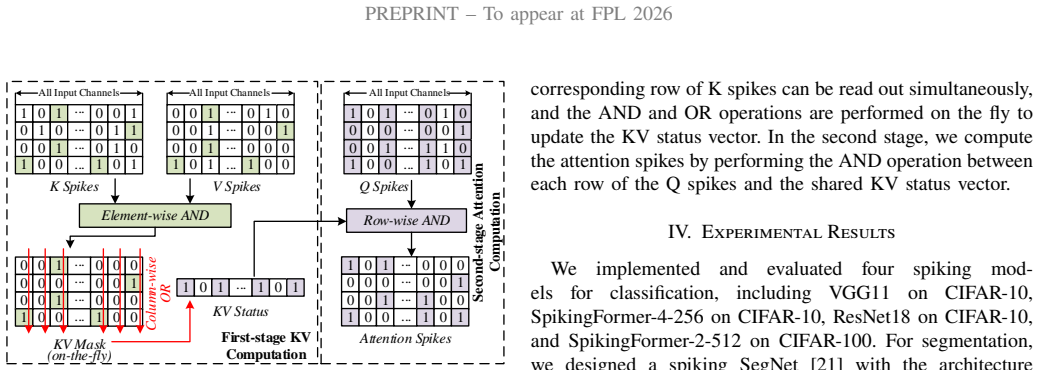
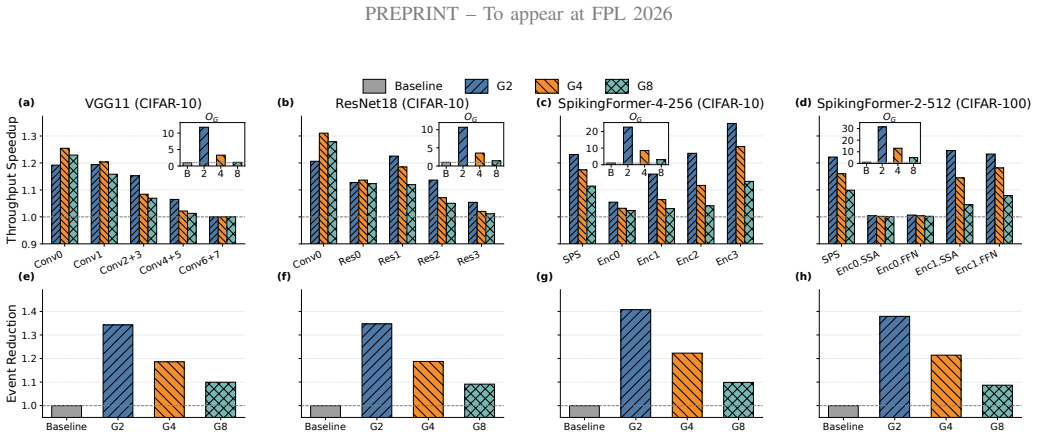
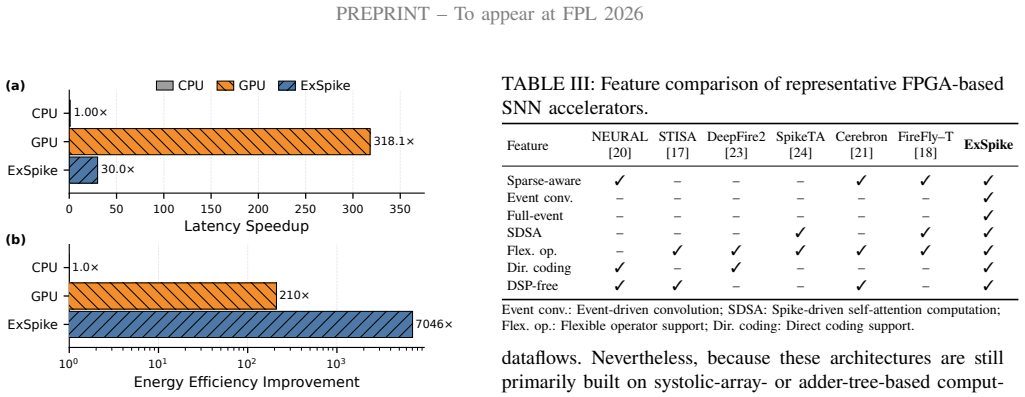
ExSpike is a general full-event neuromorphic architecture that supports pure event-driven dataflow through layer-input optimizations, includes an Attention Core for spike-driven self-attention, and applies adjacent-position event compression to reduce redundant accumulations across spatially adjacent spike sequences; when implemented on AMD Xilinx Virtex-7 FPGA it reaches 479.15 GOPS, 281.85 GOPS/W, and 0.80 GOPS/W/PE while preserving competitive accuracy on classification and segmentation workloads and outperforming the prior FireFly-T design by up to 10 times in PE-normalized energy efficiency.
What carries the argument
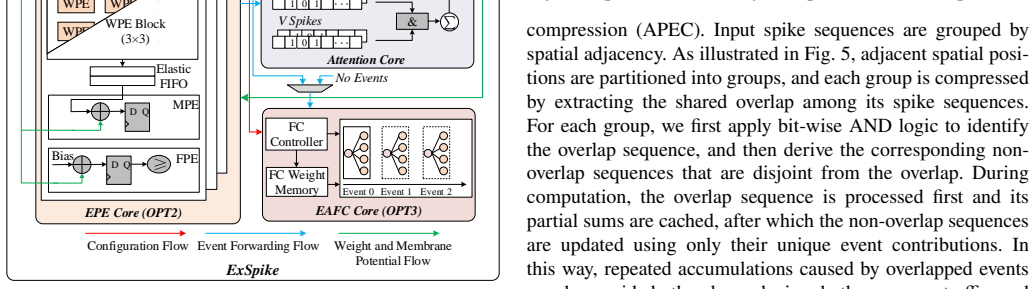
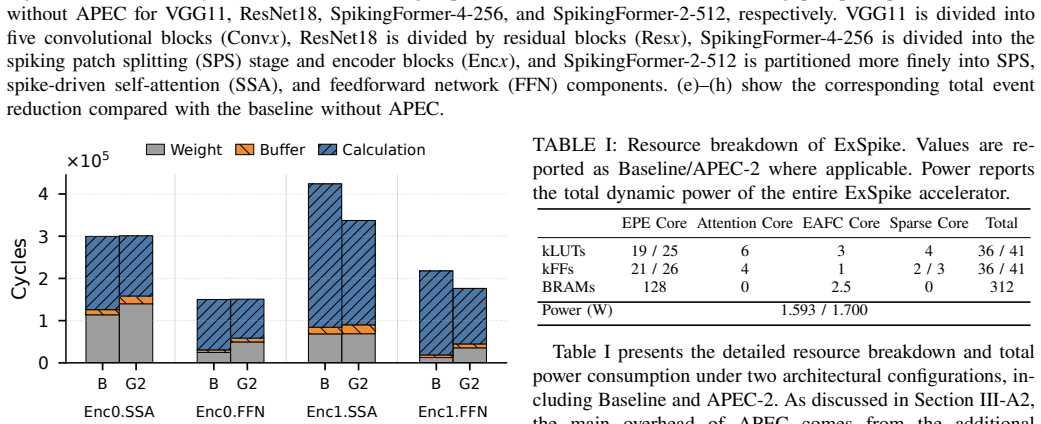
The ExSpike full-event architecture, which combines dataflow optimizations to enforce spike-based layer inputs with adjacent-position event compression to eliminate redundant accumulations.
If this is right
- SNN accelerators can maintain full spike-driven execution end-to-end without reverting to dense operations at any layer.
- Adjacent-position event compression reduces accumulations enough to raise overall throughput and efficiency on FPGA hardware.
- The architecture supports both classification and segmentation tasks while achieving up to 10 times better PE-normalized energy efficiency than FireFly-T.
- An Attention Core can be integrated into the event-driven flow to handle spike-driven self-attention without breaking sparsity.
Where Pith is reading between the lines
- The same compression and dataflow ideas could be tested on ASIC targets to see whether the efficiency gains scale beyond FPGA resources.
- If the spike-based input constraint holds for larger or recurrent SNNs, the design might reduce the need for hybrid dense-sparse hardware blocks.
- Applying the adjacent-position compression outside SNNs to other sparse temporal data streams could be checked for similar accumulation savings.
Load-bearing premise
The dataflow optimizations can keep every layer input spike-based with negligible overhead or accuracy loss on the evaluated SNN models and workloads.
What would settle it
Running the same SNN models on ExSpike after removing the dataflow optimizations and observing either a shift away from spike-based inputs, a measurable accuracy drop, or energy efficiency falling below the reported 0.80 GOPS/W/PE would falsify the central performance claim.
Figures


read the original abstract
Spiking neural networks (SNNs) promise energy-efficient computing due to their sparse spatio-temporal activity. However, effectively translating such irregular sparsity into practical performance and energy gains remains challenging, as full-event computing architectures are still underexplored. This paper proposes ExSpike, a general full-event neuromorphic architecture that fully exploits irregular sparsity in SNNs. To realize pure event-driven execution, we first propose a set of dataflow optimizations to ensure that the inputs to each SNN layer remain spike-based, thereby enabling full-event execution throughout the network. We then design a hardware-efficient full-event architecture, named ExSpike, which supports the optimized pure event-driven dataflow and an additional Attention Core for spike-driven self-attention. To further improve computing efficiency, we introduce adjacent-position event compression to reduce redundant accumulations across spatially adjacent spike sequences. ExSpike is implemented on an AMD Xilinx Virtex-7 FPGA and evaluated on both classification and segmentation workloads. Experimental results show that ExSpike achieves high normalized energy efficiency across diverse SNN models while maintaining competitive accuracy, delivering up to 479.15 GOPS, 281.85 GOPS/W, and 0.80 GOPS/W/PE. In particular, ExSpike achieves up to 10$\times$ higher PE-normalized energy efficiency than the SOTA FPGA-based SNN accelerator (FireFly-T). The code for ExSpike is available at https://github.com/xiaoyuehai/ExSpike.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ExSpike, a full-event neuromorphic architecture for SNNs that employs dataflow optimizations to maintain spike-based inputs across layers and adjacent-position event compression to reduce redundant accumulations. It includes an Attention Core for spike-driven self-attention, is implemented on AMD Xilinx Virtex-7 FPGA, and is evaluated on classification and segmentation workloads. The paper reports peak metrics of 479.15 GOPS, 281.85 GOPS/W, and 0.80 GOPS/W/PE, claiming up to 10× higher PE-normalized energy efficiency than the SOTA FPGA accelerator FireFly-T while preserving competitive accuracy; the implementation code is released openly.
Significance. If the experimental claims are substantiated with adequate controls, the work offers a concrete hardware realization of pure event-driven execution for irregular SNN sparsity, extending prior accelerators by supporting attention mechanisms within the same dataflow. The open-source code release is a clear strength that supports reproducibility and further research in neuromorphic FPGA design.
major comments (2)
- [Evaluation] Evaluation section: The central 10× PE-normalized efficiency claim (0.80 GOPS/W/PE vs. FireFly-T) and the assertion that dataflow optimizations 'ensure that the inputs to each SNN layer remain spike-based' with negligible overhead require per-layer spike-rate tables, ablation results on accuracy impact, and overhead measurements for the evaluated models; these data are absent, leaving the pure full-event execution assumption unverified and load-bearing for the reported 281.85 GOPS/W figure.
- [Experimental Results] Experimental setup: Workload selection criteria, precise baseline configurations (e.g., whether FireFly-T was re-implemented on the identical Virtex-7 device with matching SNN topologies and bit-widths), and error bars or run-to-run variation for the GOPS/W and GOPS/W/PE numbers are not reported, undermining confidence in the cross-accelerator comparison.
minor comments (2)
- [Figures/Tables] Figure captions and tables should explicitly state the SNN models, input spike rates, and layer counts used for each efficiency bar to allow direct comparison.
- [Architecture] Clarify in the architecture description whether the Attention Core operates fully event-driven or requires any rate-coded preprocessing.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central 10× PE-normalized efficiency claim (0.80 GOPS/W/PE vs. FireFly-T) and the assertion that dataflow optimizations 'ensure that the inputs to each SNN layer remain spike-based' with negligible overhead require per-layer spike-rate tables, ablation results on accuracy impact, and overhead measurements for the evaluated models; these data are absent, leaving the pure full-event execution assumption unverified and load-bearing for the reported 281.85 GOPS/W figure.
Authors: We agree that providing per-layer spike-rate tables, ablation studies on accuracy, and overhead measurements would strengthen the verification of the full-event execution. In the revised version, we will add these details for the evaluated models to substantiate the claims of negligible overhead and pure spike-based inputs across layers. This will support the reported efficiency figures. revision: yes
-
Referee: [Experimental Results] Experimental setup: Workload selection criteria, precise baseline configurations (e.g., whether FireFly-T was re-implemented on the identical Virtex-7 device with matching SNN topologies and bit-widths), and error bars or run-to-run variation for the GOPS/W and GOPS/W/PE numbers are not reported, undermining confidence in the cross-accelerator comparison.
Authors: The workloads were selected as representative classification and segmentation tasks from the SNN literature to demonstrate generality. For the baseline, FireFly-T results are cited from the original paper since its source code is not publicly available for re-implementation on the Virtex-7 with exact matching configurations; we will explicitly state this in the revision. The FPGA design is deterministic, so error bars are not applicable, but we will report any measured variations if available. We will also detail the workload selection criteria. revision: partial
Circularity Check
No circularity; claims rest on FPGA measurements and implementation
full rationale
The paper describes a hardware architecture (ExSpike) with dataflow optimizations and reports measured results (GOPS, GOPS/W, comparisons to FireFly-T) from Virtex-7 FPGA implementation on classification/segmentation workloads. No equations, fitted parameters, or first-principles derivations are present that could reduce to inputs by construction. Efficiency numbers derive from physical execution traces rather than any self-referential loop. Self-citation is absent from the provided text, and the open-source code link further decouples claims from internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exploring neuromorphic computing based on spiking neural networks: Algorithms to hardware,
N. Rathi, I. Chakraborty, A. Kosta, A. Sengupta, A. Ankit, P. Panda, and K. Roy, “Exploring neuromorphic computing based on spiking neural networks: Algorithms to hardware,”ACM Comput. Surv., vol. 55, Mar. 2023
2023
-
[2]
Going deeper with directly-trained larger spiking neural networks,
H. Zheng, Y. Wu, L. Deng, Y. Hu, and G. Li, “Going deeper with directly-trained larger spiking neural networks,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 11062–11070, May 2021
2021
-
[3]
Temporal separation with entropy regularization for knowledge distillation in spiking neural networks,
K. Yu, C. Yu, T. Zhang, X. Zhao, S. Yang, H. Wang, Q. Zhang, and Q. Xu, “Temporal separation with entropy regularization for knowledge distillation in spiking neural networks,” in2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8806–8816, 2025
2025
-
[4]
The architecture design and training optimization of spiking neural network with low-latency and high-performance for classification and segmentation,
W. Ye, S. Chen, H. Liu, Y. Liu, Y. Chen, Y. Cui, and W. Lin, “The architecture design and training optimization of spiking neural network with low-latency and high-performance for classification and segmentation,”Neural Networks, vol. 191, p. 107790, 2025
2025
-
[5]
BriLLM: Brain- inspired large language model,
H. Zhao, H. Wu, D. Yang, A. Zou, and J. Hong, “BriLLM: Brain- inspired large language model,” 2025
2025
-
[6]
A large scale event- based detection dataset for automotive,
P. de Tournemire, D. Nitti, E. Perot, and A. Sironi, “A large scale event- based detection dataset for automotive,”arXiv preprint arXiv, 2020
2020
-
[7]
Spike- driven transformer,
M. Yao, J. Hu, Z. Zhou, L. Yuan, Y. Tian, B. Xu, and G. Li, “Spike- driven transformer,”Advances in neural information processing systems, vol. 36, pp. 64043–64058, 2023
2023
-
[8]
Spikingformer: A key foundation model for spiking neural networks,
C. Zhou, L. Yu, Z. Zhou, H. Zhang, J. Wang, H. Zhou, Z. Ma, and Y. Tian, “Spikingformer: A key foundation model for spiking neural networks,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, pp. 2236–2244, 2026
2026
-
[9]
Spiking transformer with spatial-temporal attention,
D. Lee, Y. Li, Y. Kim, S. Xiao, and P. Panda, “Spiking transformer with spatial-temporal attention,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13948–13958, 2025
2025
-
[10]
An energy-efficient unstructured sparsity-aware deep SNN accelerator with 3-D computation array,
C. Fang, Z. Shen, Z. Wang, C. Wang, S. Zhao, F. Tian, J. Yang, and M. Sawan, “An energy-efficient unstructured sparsity-aware deep SNN accelerator with 3-D computation array,”IEEE Journal of Solid-State Circuits, vol. 60, no. 3, pp. 977–989, 2025
2025
-
[11]
MINT: Multiplier-less integer quantization for energy efficient spiking neural networks,
R. Yin, Y. Li, A. Moitra, and P. Panda, “MINT: Multiplier-less integer quantization for energy efficient spiking neural networks,” in2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), pp. 830–835, 2024
2024
-
[12]
Phi: Leveraging pattern-based hierarchical sparsity for high-efficiency spiking neural networks,
C. Wei, B. Duan, C. Guo, J. Zhang, Q. Song, H. Li, and Y. Chen, “Phi: Leveraging pattern-based hierarchical sparsity for high-efficiency spiking neural networks,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ISCA ’25, (New York, NY, USA), p. 930–943, Association for Computing Machinery, 2025
2025
-
[13]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
Pith/arXiv arXiv 2014
-
[14]
SiBrain: A sparse spatio-temporal parallel neuromorphic architecture for accelerating spiking convolution neural networks with low latency,
Y. Chen, W. Ye, Y. Liu, and H. Zhou, “SiBrain: A sparse spatio-temporal parallel neuromorphic architecture for accelerating spiking convolution neural networks with low latency,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 12, pp. 6482–6494, 2024
2024
-
[15]
Exploring the sparsity-quantization interplay on a novel hybrid SNN event-driven architecture,
I. Aliyev, J. Lopez, and T. Adegbija, “Exploring the sparsity-quantization interplay on a novel hybrid SNN event-driven architecture,” in2025 Design, Automation & Test in Europe Conference (DATE), pp. 1–7, 2025
2025
-
[16]
FireFly-S: Exploiting dual-side sparsity for spiking neural networks acceleration with reconfigurable spatial architecture,
T. Li, J. Li, G. Shen, D. Zhao, Q. Zhang, and Y. Zeng, “FireFly-S: Exploiting dual-side sparsity for spiking neural networks acceleration with reconfigurable spatial architecture,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 8, pp. 4007–4020, 2025
2025
-
[17]
STISA: A 0.16-GOPS/W/PE single-shot inference FPGA-based SNN accelerator with algorithm and hardware co-design,
K. Wang, C. Yang, L. Liu, C. Yu, Y. S. Ang, B. Wang, and A. Wang, “STISA: A 0.16-GOPS/W/PE single-shot inference FPGA-based SNN accelerator with algorithm and hardware co-design,”IEEE Transactions on Circuits and Systems I: Regular Papers, pp. 1–14, 2025
2025
-
[18]
FireFly-T: High- throughputsparsityexploitationforspikingtransformeraccelerationwith dual-engine overlay architecture,
T. Li, J. Li, G. Shen, D. Zhao, Q. Zhang, and Y. Zeng, “FireFly-T: High- throughputsparsityexploitationforspikingtransformeraccelerationwith dual-engine overlay architecture,”IEEE Transactions on Computers, pp. 1–14, 2026
2026
-
[19]
SpikeHard: Efficiency-driven neu- romorphic hardware for heterogeneous systems-on-chip,
J. Clair, G. Eichler, and L. P. Carloni, “SpikeHard: Efficiency-driven neu- romorphic hardware for heterogeneous systems-on-chip,”ACM Trans. Embed. Comput. Syst., vol. 22, Sept. 2023
2023
-
[20]
NEURAL: An elastic neuromorphic architec- ture with hybrid data-event execution and on-the-fly attention dataflow,
Y. Chen and F. Merchant, “NEURAL: An elastic neuromorphic architec- ture with hybrid data-event execution and on-the-fly attention dataflow,” in2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC), pp. 1110–1116, 2026
2026
-
[21]
Cerebron: A reconfigurable architecture for spatiotemporal sparse spiking neural networks,
Q. Chen, C. Gao, and Y. Fu, “Cerebron: A reconfigurable architecture for spatiotemporal sparse spiking neural networks,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 30, no. 10, pp. 1425– 1437, 2022
2022
-
[22]
SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence,
W. Fang, Y. Chen, J. Ding, Z. Yu, T. Masquelier, D. Chen, L. Huang, H. Zhou, G. Li, and Y. Tian, “SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence,”Science Advances, vol. 9, no. 40, p. eadi1480, 2023
2023
-
[23]
DeepFire2: A convolutional spiking neural network accelerator on FPGAs,
M. T. L. Aung, D. Gerlinghoff, C. Qu, L. Yang, T. Huang, R. S. M. Goh, T. Luo, and W.-F. Wong, “DeepFire2: A convolutional spiking neural network accelerator on FPGAs,”IEEE Transactions on Computers, vol. 72, no. 10, pp. 2847–2857, 2023
2023
-
[24]
Advancing neuromorphic architecture toward emerging spik- ing neural network on FPGA,
Y. Gao, T. Wang, Y. Yang, L. Gong, X. Chen, C. Wang, X. Li, and X. Zhou, “Advancing neuromorphic architecture toward emerging spik- ing neural network on FPGA,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 44, no. 9, pp. 3465–3478, 2025
2025
-
[25]
SConvNSys: Acceleratingspikingconvolutionalneuralnetworkswithareconfigurable neuromorphic architecture for diverse applications,
W. Ye, Y. Liang, Y. Liu, Y. Cui, Y. Chen, and W. Lin, “SConvNSys: Acceleratingspikingconvolutionalneuralnetworkswithareconfigurable neuromorphic architecture for diverse applications,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, pp. 1–14, 2025
2025
-
[26]
ShortcutFusion: From tensorflow to FPGA-based accelerator with a reuse-aware memory allocation for shortcut data,
D. T. Nguyen, H. Je, T. N. Nguyen, S. Ryu, K. Lee, and H.-J. Lee, “ShortcutFusion: From tensorflow to FPGA-based accelerator with a reuse-aware memory allocation for shortcut data,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 6, pp. 2477– 2489, 2022
2022
-
[27]
FPGA-NHAP: A general FPGA- based neuromorphic hardware acceleration platform with high speed and low power,
Y. Liu, Y. Chen, W. Ye, and Y. Gui, “FPGA-NHAP: A general FPGA- based neuromorphic hardware acceleration platform with high speed and low power,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 6, pp. 2553–2566, 2022
2022
-
[28]
An FPGA- based event-driven SNN accelerator for DVS applications with structured sparsity and early-stop,
X. Cheng, S. Cao, S. Wang, M. Wang, W. Li, and X. Zeng, “An FPGA- based event-driven SNN accelerator for DVS applications with structured sparsity and early-stop,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 7, pp. 3298–3310, 2025
2025
-
[29]
Spiker+: A framework for the generation of efficient spiking neural networks FPGA accelerators for inference at the edge,
A. Carpegna, A. Savino, and S. D. Carlo, “Spiker+: A framework for the generation of efficient spiking neural networks FPGA accelerators for inference at the edge,”IEEE Transactions on Emerging Topics in Computing, vol. 13, no. 3, pp. 784–798, 2025
2025
-
[30]
Retina- inspired lightweight spiking convolutional neural network for single- image dehazing,
Y. Zhang, X. Luo, Q. Sun, Y. Wang, H. Qu, and Z. Yi, “Retina- inspired lightweight spiking convolutional neural network for single- image dehazing,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 7, pp. 12580–12594, 2025
2025
-
[31]
The implementation and optimization of neuromorphic hardware for supporting spiking neural networks with MLP and CNN topologies,
W. Ye, Y. Chen, and Y. Liu, “The implementation and optimization of neuromorphic hardware for supporting spiking neural networks with MLP and CNN topologies,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 2, pp. 448–461, 2023
2023
-
[32]
SyncNN: Evaluating and accel- erating spiking neural networks on FPGAs,
S. Panchapakesan, Z. Fang, and J. Li, “SyncNN: Evaluating and accel- erating spiking neural networks on FPGAs,” in2021 31st International Conference on Field-Programmable Logic and Applications (FPL), pp. 286–293, 2021
2021
-
[33]
DeepFire: Acceleration of convolutional spiking neural network on modern field programmable gate arrays,
M. T. L. Aung, C. Qu, L. Yang, T. Luo, R. S. M. Goh, and W.-F. Wong, “DeepFire: Acceleration of convolutional spiking neural network on modern field programmable gate arrays,” in2021 31st International Conference on Field-Programmable Logic and Applications (FPL), pp. 28–32, 2021
2021
-
[34]
FPSpike: A fully parallel and reconfigurable architecture for accelerating spiking neural networks with structured sparsity,
M. Li, Y. Kan, M. Wu, R. Zhang, and Y. Nakashima, “FPSpike: A fully parallel and reconfigurable architecture for accelerating spiking neural networks with structured sparsity,”IEEE Transactions on Circuits and Systems I: Regular Papers, pp. 1–14, 2026
2026
-
[35]
PULSE: Parametric hardware units for low- power sparsity-aware convolution engine,
I. Aliyev and T. Adegbija, “PULSE: Parametric hardware units for low- power sparsity-aware convolution engine,” in2024 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5, 2024
2024
-
[36]
Low-cost deployment and acceleration of event-based spiking convolutional neural networks,
Q. Tian, F. Chen, L. Xie, Y. Zhou, Z. Wu, L. Wu, R. Ying, and P. Liu, “Low-cost deployment and acceleration of event-based spiking convolutional neural networks,” in2025 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5, 2025
2025
-
[37]
ActiveN: A scalable and flexibly-programmable event-driven neuromorphic processor,
X. Liu, Z. Pu, P. Qu, W. Zheng, and Y. Zhang, “ActiveN: A scalable and flexibly-programmable event-driven neuromorphic processor,” in 2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 1122–1137, 2024. PREPRINT – To appear at FPL 2026
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.