A Unified Three-Stage Weighting Framework for Causal Inference and Mediation Analysis under Case-Control Sampling
Pith reviewed 2026-06-26 04:31 UTC · model grok-4.3
The pith
A three-stage weighting framework recovers unbiased causal and mediation effects from case-control samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
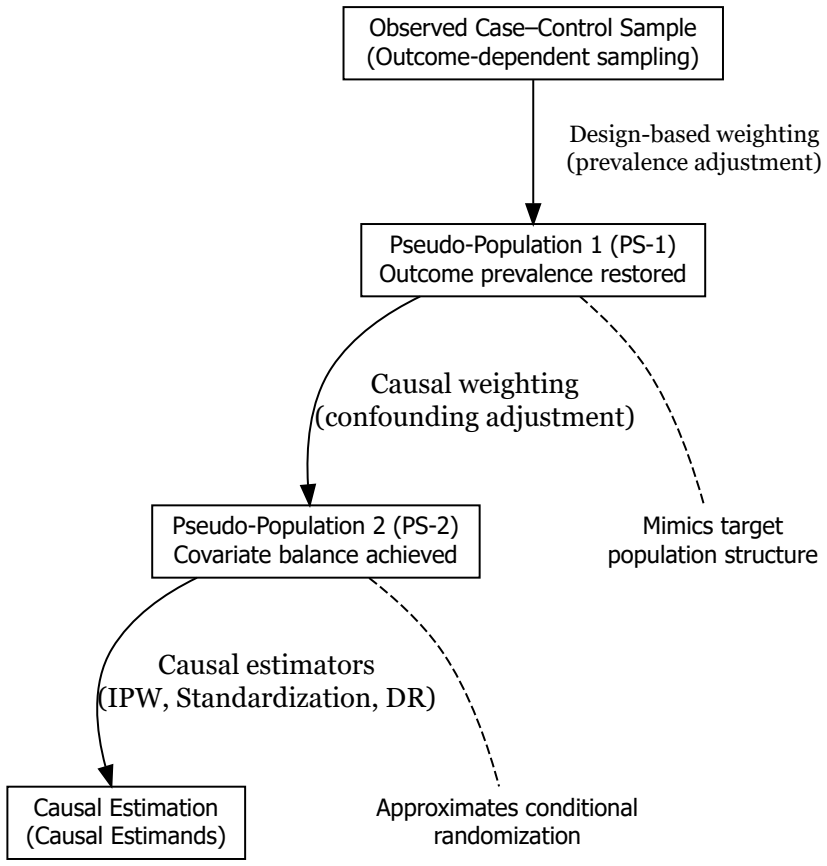
The authors introduce a three-stage weighting procedure in which population outcome prevalence is first estimated via density-ratio learning and label-shift correction using external covariates, prevalence-based design weights are then used to recover the target population distribution, and stabilized causal and mediation weights are finally applied within marginal structural models to estimate total, pure direct, pure indirect, and interaction effects under case-control sampling.
What carries the argument
The three-stage weighting procedure that combines prevalence estimation by density-ratio learning, design weighting to reconstruct the population, and stabilized weighting inside marginal structural models.
If this is right
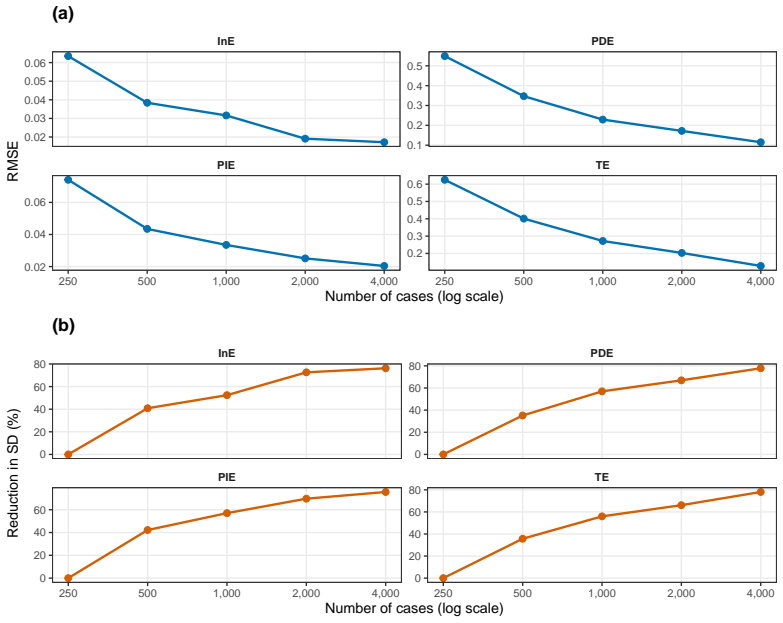
- Analyses that ignore retrospective sampling bias produce substantial errors in both total effect and mediation effect estimates.
- The three-stage weights recover the target population causal parameters across a range of case-control sampling fractions.
- Pure direct effects, pure indirect effects, and interaction effects can be estimated without distortion from the sampling design.
- The framework supports valid causal and mediation inference in settings where outcomes are rare or prospective follow-up is impractical.
Where Pith is reading between the lines
- The same three-stage structure could be adapted to other outcome-dependent sampling schemes such as case-cohort or nested case-control designs.
- Replacing the density-ratio step with more flexible machine-learning estimators might reduce sensitivity to the choice of external covariates.
- The weighting approach could be extended to time-to-event outcomes by incorporating survival marginal structural models at the final stage.
Load-bearing premise
External covariate information together with density-ratio learning and label-shift correction can accurately recover the true population outcome prevalence from the case-control sample.
What would settle it
A simulation study in which the true population prevalence and causal effects are known in advance but the three-stage weights produce estimates that remain biased after the sampling distortion is applied.
Figures
read the original abstract
Case-control studies are widely used in epidemiology and biomedical research because they provide substantial efficiency gains when outcomes are rare or prospective follow-up is impractical. However, retrospective outcome-dependent sampling distorts the population outcome distribution, creating fundamental challenges for causal inference. We propose a unified three-stage weighting (3S-weighting) framework for causal inference and causal mediation analysis from case--control studies. The proposed approach first estimates the unknown population outcome prevalence using density-ratio learning and label-shift correction combined with externally available covariate information. Next, prevalence-based design weights are used to reconstruct the target population distribution from the retrospective sample. Finally, stabilized causal and mediation weights are applied within a marginal structural modeling framework to estimate total and pathway-specific causal effects, including the pure direct effect, pure indirect effect, and interaction effect. Simulation studies demonstrate that conventional analyses that ignore retrospective sampling can produce substantial bias in both total and mediation effect estimates, whereas the proposed approach consistently recovers the target population causal parameters across a range of sampling scenarios. An application of data from the National Health and Nutrition Examination Survey further illustrates the practical implementation and utility of the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified three-stage weighting (3S-weighting) framework for causal inference and mediation analysis under case-control sampling. Stage 1 estimates the unknown population outcome prevalence π via density-ratio learning and label-shift correction that incorporates externally available covariate information. Stage 2 applies prevalence-based design weights to reconstruct the target population distribution from the retrospective sample. Stage 3 uses stabilized causal and mediation weights inside a marginal structural modeling framework to estimate total effects as well as pure direct, pure indirect, and interaction effects. Simulation studies are reported to show substantial bias in conventional analyses that ignore retrospective sampling and consistent recovery of target parameters by the proposed method across sampling scenarios; an NHANES application is also presented.
Significance. If the three-stage procedure is shown to be robust, the framework would address a practically important problem in epidemiology and biomedical research, where case-control designs are common but outcome-dependent sampling distorts the population distribution and invalidates standard causal and mediation estimators. The combination of density-ratio learning for prevalence estimation, design weights, and stabilized MSM weights is a coherent extension of existing weighting ideas. The reported simulation recovery and real-data illustration are positive features, but the load-bearing role of the external-covariate prevalence step means the overall contribution hinges on validation of that component.
major comments (3)
- [Methods (Stage 1 description)] The central claim that the method 'consistently recovers the target population causal parameters' rests on accurate recovery of π in Stage 1. The manuscript supplies no theoretical guarantees, no explicit model specification for the density-ratio estimator, and no simulation scenarios in which the external covariate sample has different support or the ratio model is misspecified; these omissions make the recovery claim difficult to evaluate.
- [Simulation studies section] Simulation studies are described as demonstrating recovery 'across a range of sampling scenarios,' yet the text does not report how the external covariate information is generated, what overlap exists between case-control and external samples, or any sensitivity checks for distribution shift; without these, the contrast with 'substantial bias' in conventional analyses cannot be fully assessed.
- [Application section] The NHANES application is presented as illustrating practical utility, but the abstract and main text supply no equations, exclusion rules, error-bar details, or sensitivity checks for the prevalence estimation step, leaving the empirical support for the framework incomplete.
minor comments (2)
- Notation for the pure direct effect, pure indirect effect, and interaction effect should be introduced with explicit definitions and links to the marginal structural model parameters early in the Methods section.
- The abstract would benefit from a one-sentence statement of the key identifying assumptions (e.g., correct specification of the density-ratio model and sufficient external covariate overlap).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional detail will improve the manuscript. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Methods (Stage 1 description)] The central claim that the method 'consistently recovers the target population causal parameters' rests on accurate recovery of π in Stage 1. The manuscript supplies no theoretical guarantees, no explicit model specification for the density-ratio estimator, and no simulation scenarios in which the external covariate sample has different support or the ratio model is misspecified; these omissions make the recovery claim difficult to evaluate.
Authors: We will revise the Methods section to provide an explicit description of the model specification used for the density-ratio estimator. New simulation scenarios will be added that include limited overlap between the external covariate sample and the case-control sample as well as misspecification of the ratio model. We acknowledge that the current manuscript does not supply formal theoretical guarantees for the Stage 1 estimator under arbitrary conditions; the consistency claims rest on established properties of density-ratio learning and label-shift correction when the working model is correctly specified. revision: partial
-
Referee: [Simulation studies section] Simulation studies are described as demonstrating recovery 'across a range of sampling scenarios,' yet the text does not report how the external covariate information is generated, what overlap exists between case-control and external samples, or any sensitivity checks for distribution shift; without these, the contrast with 'substantial bias' in conventional analyses cannot be fully assessed.
Authors: The Simulation studies section will be expanded to report the data-generating process for the external covariate sample, quantitative measures of overlap with the case-control sample, and sensitivity analyses under distribution shift. These additions will allow readers to more fully evaluate the reported recovery results. revision: yes
-
Referee: [Application section] The NHANES application is presented as illustrating practical utility, but the abstract and main text supply no equations, exclusion rules, error-bar details, or sensitivity checks for the prevalence estimation step, leaving the empirical support for the framework incomplete.
Authors: The Application section will be revised to include the equations for prevalence estimation, the exclusion criteria applied to the NHANES data, details on error-bar construction, and sensitivity checks for the prevalence estimation step. These changes will make the empirical illustration more transparent and complete. revision: yes
- Request for formal theoretical guarantees on the consistency of the density-ratio estimator in Stage 1 under general misspecification
Circularity Check
No circularity: three-stage weighting derives from external prevalence estimation and standard MSM weighting
full rationale
The derivation chain begins with density-ratio learning plus label-shift correction on external covariates to recover population prevalence π (stage 1), constructs design weights from that estimate (stage 2), and applies stabilized weights inside marginal structural models (stage 3). None of these steps is shown to reduce to a fitted parameter renamed as a prediction, nor does the abstract or described framework invoke a self-citation chain or uniqueness theorem that imports the target result. Simulations are presented as external validation rather than the source of the claimed recovery. The framework therefore remains self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A., and Luque-Fernandez, M
Abdollahpour, I., Nedjat, S., Almasi-Hashiani, A., Nazemipour, M., Mansournia, M. A., and Luque-Fernandez, M. A. (2021). Estimating the marginal causal effect and potential impact of waterpipe smoking on risk of multiple sclerosis using the targeted maximum likelihood estimation method: a large, population-based incident case-control study. American journ...
2021
-
[2]
Anderson, J. A. (1972). Separate sample logistic discrimination. Biometrika , 59(1):19--35
1972
-
[3]
Balzer, L., Ahern, J., Galea, S., and Van Der Laan, M. (2016). Estimating effects with rare outcomes and high dimensional covariates: knowledge is power. Epidemiologic methods , 5(1):1--18
2016
-
[4]
and Robins, J
Bang, H. and Robins, J. M. (2005). Doubly robust estimation in missing data and causal inference models. Biometrics , 61(4):962--973
2005
-
[5]
Breslow, N. E. (1996). Statistics in epidemiology: the case-control study. Journal of the American Statistical Association , 91(433):14--28
1996
-
[6]
E., Day, N
Breslow, N. E., Day, N. E., and Heseltine, E. (1980). Statistical methods in cancer research
1980
-
[7]
National health and nutrition examination survey data
Centers for Disease Control and Prevention (CDC) and National Center for Health Statistics (NCHS) (2026). National health and nutrition examination survey data. Accessed: 2026-05-28
2026
-
[8]
Cornfield, J. (1951). A method of estimating comparative rates from clinical data. applications to cancer of the lung, breast, and cervix. Journal of the National Cancer Institute , 11(6):1269--1275
1951
-
[9]
Greenland, S. (1981). Multivariate estimation of exposure-specific incidence from case-control studies. Journal of chronic diseases , 34(9-10):445--453
1981
-
[10]
Greenland, S. (1987). Estimation of exposure-specific rates from sparse case-control data. Journal of chronic diseases , 40(12):1087--1094
1987
-
[11]
Hern \'a n, M. A. and Robins, J. M. (2010). Causal inference: What if
2010
-
[12]
Horvitz, D. G. and Thompson, D. J. (1952). A generalization of sampling without replacement from a finite universe. Journal of the American Statistical Association , 47(260):663--685
1952
-
[13]
W., Lemeshow, S., and Sturdivant, R
Hosmer Jr, D. W., Lemeshow, S., and Sturdivant, R. X. (2013). Applied logistic regression . John Wiley & Sons
2013
-
[14]
Imbens, G. W. and Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences . Cambridge university press
2015
-
[15]
J., Vandenbroucke, J
Knol, M. J., Vandenbroucke, J. P., Scott, P., and Egger, M. (2008). What do case-control studies estimate? survey of methods and assumptions in published case-control research. American journal of epidemiology , 168(9):1073--1081
2008
-
[16]
Penning de Vries, B
L. Penning de Vries, B. B. and Groenwold, R. H. (2022). Identification of causal effects in case-control studies. BMC medical research methodology , 22(1):7
2022
-
[17]
A., Hunink, M
Labrecque, J. A., Hunink, M. M., Ikram, M. A., and Ikram, M. K. (2021). Do case-control studies always estimate odds ratios? American journal of epidemiology , 190(2):318--321
2021
-
[18]
M \'e sidor, M., Xu, M., Diop, A., Fantodji, C., Parent, M.- \'E ., and Keil, A. (2026). Use of causal inference methods in case--control studies: a methodology review. American journal of epidemiology , 195(5):1438--1446
2026
-
[19]
Miettinen, O. (1976). Estimability and estimation in case-referent studies. American journal of epidemiology , 103(2):226--235
1976
-
[20]
M., Lawrence, K
O’Brien, K. M., Lawrence, K. G., and Keil, A. P. (2022). The case for case--cohort: an applied epidemiologist’s guide to reframing case--cohort studies to improve usability and flexibility. Epidemiology , 33(3):354--361
2022
-
[21]
Pearl, M., Balzer, L., and Ahern, J. (2016). Targeted estimation of marginal absolute and relative associations in case--control data: an application in social epidemiology. Epidemiology , 27(4):512--517
2016
-
[22]
Prentice, R. L. and Pyke, R. (1979). Logistic disease incidence models and case-control studies. Biometrika , 66(3):403--411
1979
-
[23]
Robins, J. (1986). A new approach to causal inference in mortality studies with a sustained exposure period—application to control of the healthy worker survivor effect. Mathematical modelling , 7(9-12):1393--1512
1986
-
[24]
Robins, J. M. (1997). Causal inference from complex longitudinal data. In Latent variable modeling and applications to causality , pages 69--117. Springer
1997
-
[25]
M., Hernan, M
Robins, J. M., Hernan, M. A., and Brumback, B. (2000). Marginal structural models and causal inference in epidemiology
2000
-
[26]
M., Rotnitzky, A., and Zhao, L
Robins, J. M., Rotnitzky, A., and Zhao, L. P. (1994). Estimation of regression coefficients when some regressors are not always observed. Journal of the American statistical Association , 89(427):846--866
1994
-
[27]
and van der Laan, M
Rose, S. and van der Laan, M. (2014). A double robust approach to causal effects in case-control studies. American journal of epidemiology , 179(6):663--669
2014
-
[28]
and van der Laan, M
Rose, S. and van der Laan, M. J. (2008). Simple optimal weighting of cases and controls in case-control studies. The International Journal of Biostatistics , 4(1):Article--19
2008
-
[29]
and Van Der Laan, M
Rose, S. and Van Der Laan, M. J. (2009). Why match? investigating matched case-control study designs with causal effect estimation. The international journal of biostatistics , 5(1):Article--1
2009
-
[30]
J., Greenland, S., Lash, T
Rothman, K. J., Greenland, S., Lash, T. L., et al. (2008). Modern epidemiology , volume 3. Wolters Kluwer Health/Lippincott Williams & Wilkins Philadelphia
2008
-
[31]
Rubin, D. B. (1974). Characterizing the estimation of parameters in incomplete-data problems. Journal of the American Statistical Association , 69(346):467--474
1974
-
[32]
Schlesselman, J. J. (1982). Case-control studies: design, conduct, analysis , volume 2. Oxford university press
1982
-
[33]
M., and Speed, T
Splawa-Neyman, J., Dabrowska, D. M., and Speed, T. P. (1990). On the application of probability theory to agricultural experiments. essay on principles. section 9. Statistical Science , pages 465--472
1990
-
[34]
Tsiatis, A. A. (2006). Semiparametric theory and missing data . Springer
2006
-
[35]
and VanderWeele, T
Valeri, L. and VanderWeele, T. J. (2013). Mediation analysis allowing for exposure--mediator interactions and causal interpretation: theoretical assumptions and implementation with sas and spss macros. Psychological methods , 18(2):137
2013
-
[36]
van der Laan, M. J. (2008). Estimation based on case-control designs with known prevalence probability. The International Journal of Biostatistics , 4(1)
2008
-
[37]
Van Der Laan, M. J. and Rubin, D. (2006). Targeted maximum likelihood learning. The International Journal of Biostatistics , 2(1)
2006
-
[38]
VanderWeele, T. (2015). Explanation in causal inference: methods for mediation and interaction . Oxford University Press
2015
-
[39]
VanderWeele, T. J. (2014). A unification of mediation and interaction: a 4-way decomposition. Epidemiology , 25(5):749--761
2014
-
[40]
VanderWeele, T. J. and Tchetgen Tchetgen, E. J. (2016). Mediation analysis with matched case-control study designs. American journal of epidemiology , 183(9):869--870
2016
-
[41]
VanderWeele, T. J. and Vansteelandt, S. (2010). Odds ratios for mediation analysis for a dichotomous outcome. American journal of epidemiology , 172(12):1339--1348
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.