The revisited knockoffs method for variable selection in L1-penalised regressions
Pith reviewed 2026-05-25 01:34 UTC · model grok-4.3
The pith
A revisited knockoffs method determines the penalty parameter for variable selection in L1-penalized regressions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a new method based on the knockoffs idea to handle the choice of the penalty parameter in L1-penalised regression models. This revisited knockoffs method is general and suitable for a wide range of regressions with various types of response variables. It works when the number of observations is smaller than the number of covariates and gives an order of importance of the covariates.
What carries the argument
The revisited knockoffs method, which adapts the knockoffs framework to select the penalty parameter and rank covariates in L1-penalized regressions.
If this is right
- It enables variable selection in regressions with more covariates than observations.
- It applies to various response variable types beyond standard linear models.
- It provides a ranking of covariate importance rather than just selection.
- It can be compared to other variable selection methods through experimental results.
Where Pith is reading between the lines
- The method might extend to other penalized regression types if the knockoffs adaptation generalizes.
- It could reduce reliance on cross-validation for choosing the penalty in high-dimensional settings.
- It connects to broader uses of knockoffs for controlling false discoveries in variable selection.
Load-bearing premise
The knockoffs framework can be adapted to L1-penalized regressions without needing extra assumptions on the data distribution or model specifics.
What would settle it
An experiment showing that the method fails to correctly identify relevant variables or select the penalty in a controlled simulation with known ground truth when n is less than p.
Figures








read the original abstract
We consider the problem of variable selection in regression models. In particular, we are interested in selecting explanatory covariates linked with the response variable and we want to determine which covariates are relevant, that is which covariates are involved in the model. In this framework, we deal with L1-penalised regression models. To handle the choice of the penalty parameter to perform variable selection, we develop a new method based on the knockoffs idea. This revisited knockoffs method is general, suitable for a wide range of regressions with various types of response variables. Besides, it also works when the number of observations is smaller than the number of covariates and gives an order of importance of the covariates. Finally, we provide many experimental results to corroborate our method and compare it with other variable selection methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a 'revisited knockoffs' procedure to select the L1 penalty parameter λ for variable selection in penalized regression. It claims the method applies to a wide range of response distributions, remains valid when n < p, produces an ordering of covariate importance, and is supported by experimental comparisons against other selection methods.
Significance. A procedure that extends knockoff-based selection to arbitrary GLMs and the high-dimensional regime without Gaussian assumptions would address a practical gap; however, the abstract provides no indication that such an extension is achieved, limiting assessment of potential impact.
major comments (2)
- [Abstract] Abstract: the assertion that the method is 'suitable for a wide range of regressions with various types of response variables' and 'works when the number of observations is smaller than the number of covariates' is load-bearing for the central claim, yet no construction of knockoff variables X̃ is supplied that preserves the joint exchangeability (X, X̃) under the null for non-Gaussian responses or rank-deficient designs.
- [Abstract] Abstract and method description: the procedure is said to 'give an order of importance of the covariates' via the λ path, but no derivation shows how the knockoff statistics are extracted or why the resulting ordering inherits FDR control (or an analogous guarantee) once the response distribution is arbitrary.
minor comments (1)
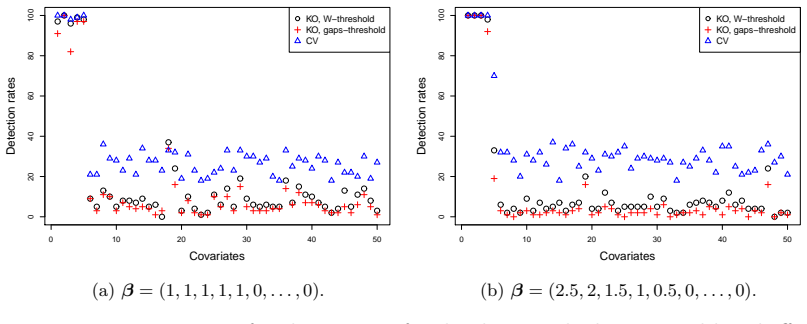
- [Abstract] The abstract states that 'many experimental results' corroborate the method; a brief indication of the simulation settings, response types, and performance metrics would help readers evaluate the scope of the reported corroboration.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the method is 'suitable for a wide range of regressions with various types of response variables' and 'works when the number of observations is smaller than the number of covariates' is load-bearing for the central claim, yet no construction of knockoff variables X̃ is supplied that preserves the joint exchangeability (X, X̃) under the null for non-Gaussian responses or rank-deficient designs.
Authors: Knockoff construction operates solely on the covariate matrix X and is independent of the response distribution Y; exchangeability of (X, X̃) therefore holds regardless of whether the response is Gaussian or belongs to another GLM family. For the n < p regime we rely on existing high-dimensional knockoff constructions (e.g., those based on approximate exchangeability or SDP relaxations) that accommodate rank-deficient designs. We will revise the abstract and add an explicit paragraph in Section 2 describing the precise construction employed. revision: yes
-
Referee: [Abstract] Abstract and method description: the procedure is said to 'give an order of importance of the covariates' via the λ path, but no derivation shows how the knockoff statistics are extracted or why the resulting ordering inherits FDR control (or an analogous guarantee) once the response distribution is arbitrary.
Authors: The importance ordering is induced by the sequence of λ values at which each original variable enters the L1 path; knockoff statistics are formed by comparing entry λ’s of originals versus knockoffs, and the threshold is chosen to guarantee FDR control. Because the exchangeability property is a property of the design only, the control argument carries over to arbitrary response distributions. We will insert a short derivation subsection (new Section 3.2) that extracts the statistics explicitly and states the FDR guarantee under the stated assumptions. revision: yes
Circularity Check
No circularity: method adapts knockoffs without reducing claims to fitted inputs or self-citations by construction
full rationale
The paper introduces a revisited knockoffs procedure for choosing the L1 penalty in regressions, claiming generality across response types and n < p regimes. No quoted equations or sections exhibit self-definitional loops (e.g., defining a quantity in terms of itself), fitted parameters renamed as predictions, or load-bearing self-citations that substitute for independent justification. The central adaptation is presented as an extension supported by experiments rather than forced by prior author results or ansatz smuggling. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Analysis of ordinal categorical data
Alan Agresti. Analysis of ordinal categorical data . Wiley Series in Probability and Statistics. John Wiley & Sons, Inc., Hoboken, NJ, second edi tion, 2010
work page 2010
-
[2]
Alan Agresti. Categorical data analysis . Wiley series in probability and statistics. Wiley, 3ed. edition, 2013
work page 2013
-
[3]
Regression, discrimination and measurement models for ordered categorical variables
JA Anderson and PR Philips. Regression, discrimination and measurement models for ordered categorical variables. Applied statistics , pages 22–31, 1981. 16
work page 1981
-
[4]
Ivan E. Auger and Charles E. Lawrence. Algorithms for the optimal identification of segment neighborhoods. Bull. Math. Biol. , 51(1):39–54, 1989
work page 1989
- [5]
-
[6]
A knockoff filter for high-dimensional selective inference
Rina Foygel Barber and Emmanuel J Candes. A knockoff filter for high-dimensional selective inference. arXiv preprint arXiv:1602.03574 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
The elements of statistical learning
Trevor Hastie, Robert Tibshirani, and Jerome Friedman. The elements of statistical learning. Springer Series in Statistics. Springer-Verlag, New York , 2001. Data mining, inference, and prediction
work page 2001
-
[8]
Statistical learning with sparsity: the lasso and generalizations
Trevor Hastie, Robert Tibshirani, and Martin Wainwrigh t. Statistical learning with sparsity: the lasso and generalizations . CRC press, 2015
work page 2015
-
[9]
Stability approach to regularization selection (stars) for high dimensional graphical models
Han Liu, Kathryn Roeder, and Larry Wasserman. Stability approach to regularization selection (stars) for high dimensional graphical models. I n J. D. Lafferty, C. K. I. Williams, J. Shawe-Taylor, R. S. Zemel, and A. Culotta, edit ors, Advances in Neural Information Processing Systems 23 , pages 1432–1440. Curran Associates, Inc., 2010
work page 2010
-
[10]
The analysis of ordered catego rical data: an overview and a survey of recent developments
Ivy Liu and Alan Agresti. The analysis of ordered catego rical data: an overview and a survey of recent developments. Test, 14(1):1–73, 2005. With discussion and a rejoinder by the authors
work page 2005
-
[11]
Regression models for ordinal data
Peter McCullagh. Regression models for ordinal data. J. Roy. Statist. Soc. Ser. B , 42(2):109–142, 1980
work page 1980
-
[12]
L1-regularization pa th algorithm for general- ized linear models
Mee Young Park and Trevor Hastie. L1-regularization pa th algorithm for general- ized linear models. Journal of the Royal Statistical Society: Series B (Statist ical Methodology), 69(4):659–677, 2007
work page 2007
-
[13]
A statistical approach for CGH microarray data analysis
Franck Picard, St´ ephane Robin, Marc Lavielle, Christ ian Vaisse, Gilles Celeux, and Jean-Jacques Daudin. A statistical approach for CGH microarray data analysis . PhD thesis, INRIA, 2004
work page 2004
-
[14]
A segmenta- tion/clustering model for the analysis of array cgh data
Franck Picard, St´ ephane Robin, E Lebarbier, and J-J Da udin. A segmenta- tion/clustering model for the analysis of array cgh data. Biometrics, 63(3):758–766, 2007
work page 2007
-
[15]
Alternative analyses for the singly-order ed contingency table
Gary Simon. Alternative analyses for the singly-order ed contingency table. Journal of the American Statistical Association , 69(348):971–976, 1974
work page 1974
-
[16]
Or dinal graphical models: A tale of two approaches
Arun Sai Suggala, Eunho Yang, and Pradeep Ravikumar. Or dinal graphical models: A tale of two approaches. In Doina Precup and Yee Whye Teh, edi tors, Proceedings of the 34th International Conference on Machine Learning , volume 70 of Proceedings of Machine Learning Research , pages 3260–3269, International Convention Centre, Sydney, Australia, 06–11 Aug 2...
work page 2017
-
[17]
Regression shrinkage and selectio n via the lasso
Robert Tibshirani. Regression shrinkage and selectio n via the lasso. J. Roy. Statist. Soc. Ser. B , 58(1):267–288, 1996. 17
work page 1996
-
[18]
High dimensional v ariable selection
Larry Wasserman and Kathryn Roeder. High dimensional v ariable selection. Annals of statistics , 37(5A):2178, 2009
work page 2009
-
[19]
Analysis of conting ency tables having ordered response categories
O Dale Williams and James E Grizzle. Analysis of conting ency tables having ordered response categories. Journal of the American Statistical Association , 67(337):55–63, 1972
work page 1972
-
[20]
Genome-wide association analysis by lasso penalized logis tic regression
Tong Tong Wu, Yi Fang Chen, Trevor Hastie, Eric Sobel, an d Kenneth Lange. Genome-wide association analysis by lasso penalized logis tic regression. Bioinfor- matics, 25(6):714–721, 2009
work page 2009
-
[21]
On model selection consistency of L asso
Peng Zhao and Bin Yu. On model selection consistency of L asso. J. Mach. Learn. Res., 7:2541–2563, 2006
work page 2006
-
[22]
Classification of gene microar rays by penalized logistic regression
Ji Zhu and Trevor Hastie. Classification of gene microar rays by penalized logistic regression. Biostatistics, 5(3):427–443, 2004. 18
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.