Exploiting Task-Based Parallelism for the Red-Black Gauss-Seidel Method on 2D Grids
Pith reviewed 2026-07-03 06:23 UTC · model grok-4.3
The pith
Task-based red-black Gauss-Seidel matches divide-and-conquer performance on 2D Poisson solves while tolerating more hardware asynchronicity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
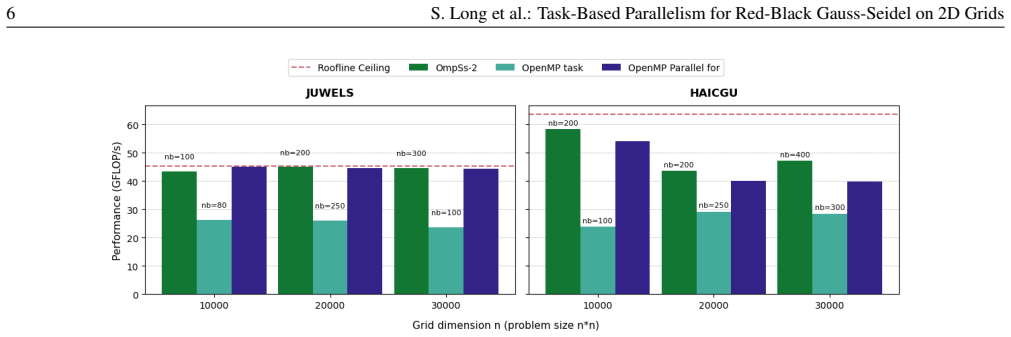
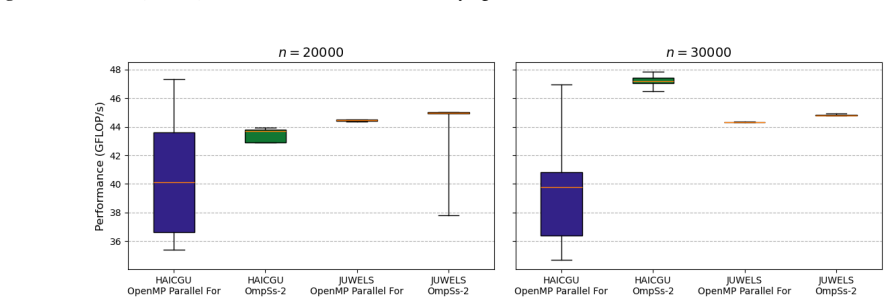
Task-based implementations of the red-black Gauss-Seidel method on 2D grids achieve performance comparable to conventional divide-and-conquer parallelization while providing greater resilience to hardware-level asynchronicity, as shown by benchmarks on the 2D Poisson equation; the approach extends naturally to general multi-color schemes from unstructured grids and wider stencils.
What carries the argument
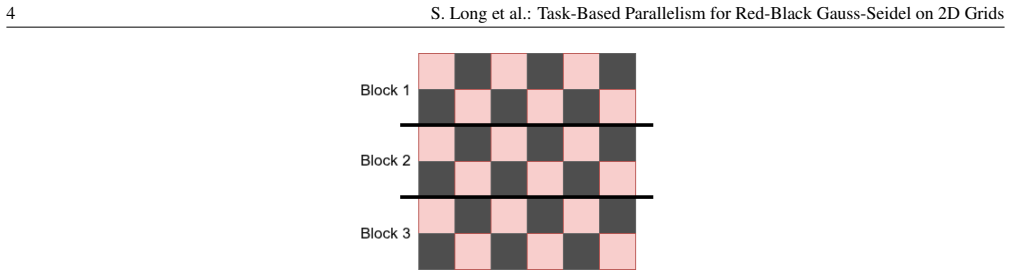
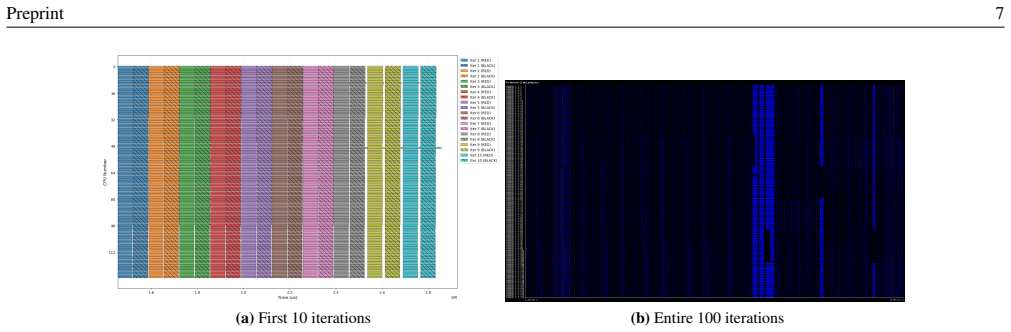
Red-black Gauss-Seidel realized through task-based models that permit fine-grained parallelism and partial overlap of color updates without global barriers.
If this is right
- Global synchronization barriers can be removed while still reaching the same iteration throughput.
- Updates to different colors can safely overlap in time without correctness loss.
- Load imbalance from hardware timing variation has smaller impact on total runtime.
- The same task decomposition applies without change to multi-color orderings on unstructured meshes.
Where Pith is reading between the lines
- The resilience property could reduce the engineering cost of running the same solver across heterogeneous clusters.
- Extending the same task model to three-dimensional problems would test whether the overlap benefit grows with stencil size.
- Direct comparison on irregular grids would show whether the claimed generality holds when load balance is harder to achieve by hand.
Load-bearing premise
Results on the 2D Poisson equation with the red-black scheme on structured grids stand in for the behavior of multi-color schemes on unstructured grids and wider stencils.
What would settle it
A timing measurement on the 2D Poisson problem in which either task-based version is markedly slower or loses more performance under injected asynchronicity than the divide-and-conquer version would falsify the main performance claim.
Figures
read the original abstract
Gauss-Seidel is a well-established iterative method for the solution of linear systems, and multicoloring has been widely used to increase parallelism in iterative solution techniques. Implementing multi-color Gauss-Seidel with conventional divide-and-conquer parallelization strategies, however, may be inefficient due to global synchronization requirements and load imbalances. Task-based programming models can mitigate these issues by enabling fine-grained parallelism, removing global barriers and allowing updates of different colors to partially overlap in time. In this work, we implement the red-black Gauss-Seidel method using two task-based programming models and compare them with a classical divide-and-conquer parallel implementation to evaluate the impact of fine-grained parallelism on execution efficiency. The red-black scheme serves as a representative example, as task-based approaches naturally extend to more general multi-color schemes arising from unstructured grids and wider stencils. Using the solve of the 2D Poisson equation as benchmark, our results show that task-based implementations can achieve performance comparable to conventional divide-and-conquer parallelization while providing greater resilience to hardware-level asynchronicity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript implements the red-black Gauss-Seidel method for solving the 2D Poisson equation on structured grids using two task-based programming models. It compares these against a conventional divide-and-conquer parallel implementation, claiming comparable performance with greater resilience to hardware-level asynchronicity. The red-black scheme is presented as a representative example whose task-based treatment naturally extends to multi-color schemes on unstructured grids and wider stencils.
Significance. If the performance and resilience results hold under the reported conditions, the work would supply concrete evidence that task-based models can reduce synchronization overhead in iterative solvers on regular grids. The explicit framing as a representative case for broader multi-color schemes would increase the result's reach if the extension is substantiated.
major comments (1)
- [Abstract] Abstract: the headline claim that task-based implementations provide greater resilience while naturally extending to unstructured grids and wider stencils rests on a benchmark confined to the 2D Poisson equation with regular red-black coloring. No experiments or analysis address load imbalance or synchronization patterns that arise with unstructured meshes or stencils requiring more than two colors, so the generality asserted in the abstract is unsupported by the presented evidence.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that task-based implementations provide greater resilience while naturally extending to unstructured grids and wider stencils rests on a benchmark confined to the 2D Poisson equation with regular red-black coloring. No experiments or analysis address load imbalance or synchronization patterns that arise with unstructured meshes or stencils requiring more than two colors, so the generality asserted in the abstract is unsupported by the presented evidence.
Authors: We agree that the abstract's statement regarding natural extension to unstructured grids and wider stencils is not backed by experiments or analysis in the manuscript. The presented results are confined to the 2D Poisson equation with red-black coloring on regular grids. The phrasing was intended to indicate that the task-based formulation (fine-grained tasks without global barriers) is structured in a way that could apply to multi-color schemes, but this remains a conceptual observation rather than an empirically validated claim. No load-imbalance or synchronization analysis for unstructured cases is provided. To address the concern, we will revise the abstract to remove the generality assertion and limit the scope to the demonstrated red-black case, with any discussion of broader applicability moved to the introduction or conclusions as a direction for future work. revision: yes
Circularity Check
No circularity: empirical performance comparison with no derivation or fitting
full rationale
The paper is an empirical study comparing task-based and conventional parallel implementations of red-black Gauss-Seidel on 2D structured grids for the Poisson equation. No equations, derivations, parameter fitting, or predictions appear in the provided text; the central claim rests on benchmark timings rather than any reduction of outputs to inputs by construction. The representativeness statement in the abstract is an explicit scoping assumption, not a self-referential definition or self-citation chain. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A hybridization methodology for high-performance linear algebra software for GPUs
Emmanuel Agullo, Cédric Augonnet, Jack Dongarra, Hatem Ltaief, Raymond Namyst, Samuel Thibault, and Stanimire Tomov. A hybridization methodology for high-performance linear algebra software for GPUs. InGPU Computing Gems Jade Edition, pages 473–484. Elsevier, 2012
2012
-
[2]
Achieving high performance on supercomputers with a sequential task-based programming model.IEEE Transactions on Parallel and Distributed Systems, 2017
Emmanuel Agullo, Olivier Aumage, Mathieu Faverge, Nathalie Furmento, Florent Pruvost, Marc Sergent, and Samuel Paul Thibault. Achieving high performance on supercomputers with a sequential task-based programming model.IEEE Transactions on Parallel and Distributed Systems, 2017
2017
-
[3]
Task-based FMM for multicore architectures.SIAM Journal on Scientific Computing, 36(1):C66–C93, 2014
Emmanuel Agullo, Bérenger Bramas, Olivier Coulaud, Eric Darve, Matthias Messner, and Toru Takahashi. Task-based FMM for multicore architectures.SIAM Journal on Scientific Computing, 36(1):C66–C93, 2014
2014
-
[4]
StarPU: a unified platform for task scheduling on heterogeneous multicore architectures
Cédric Augonnet, Samuel Thibault, Raymond Namyst, and Pierre-André Wacrenier. StarPU: a unified platform for task scheduling on heterogeneous multicore architectures. InEuro-Par 2009 Parallel Processing: 15th International Euro-Par Conference, Delft, the Netherlands, August 25-28, 2009. Proceedings 15, pages 863–874. Springer, 2009
2009
-
[5]
The design of OpenMP tasks.IEEE Transactions on Parallel and Distributed systems, 20(3):404–418, 2008
Eduard Ayguadé, Nawal Copty, Alejandro Duran, Jay Hoeflinger, Yuan Lin, Federico Massaioli, Xavier Teruel, Priya Unnikrishnan, and Guansong Zhang. The design of OpenMP tasks.IEEE Transactions on Parallel and Distributed systems, 20(3):404–418, 2008
2008
-
[6]
Extrae: Instrumentation framework for performance analysis
Barcelona Supercomputing Center. Extrae: Instrumentation framework for performance analysis. Software available from tools.bsc.es,
-
[7]
Available at https://tools.bsc.es/extrae
-
[8]
Nanos6 Runtime System for OmpSs-2
Barcelona Supercomputing Center. Nanos6 Runtime System for OmpSs-2. Software available from github.com/bsc-pm/nanos6, 2026. Available at https://github.com/bsc-pm/nanos6
2026
-
[9]
Paraver: A Trace-Based Performance Analysis Tool
Barcelona Supercomputing Center (BSC). Paraver: A Trace-Based Performance Analysis Tool. Software and Documentation Website, 2026
2026
-
[10]
Cilk: An efficient multithreaded runtime system.ACM SigPlan Notices, 30(8):207–216, 1995
Robert D Blumofe, Christopher F Joerg, Bradley C Kuszmaul, Charles E Leiserson, Keith H Randall, and Yuli Zhou. Cilk: An efficient multithreaded runtime system.ACM SigPlan Notices, 30(8):207–216, 1995
1995
-
[11]
Task-based programming for seismic imaging: Preliminary results
Lionel Boillot, George Bosilca, Emmanuel Agullo, and Henri Calandra. Task-based programming for seismic imaging: Preliminary results. In2014 IEEE Intl Conf on High Performance Computing and Communications, 2014 IEEE 6th Intl Symp on Cyberspace Safety and Security, 2014 IEEE 11th Intl Conf on Embedded Software and Syst (HPCC, CSS, ICESS), pages 1259–1266. ...
2014
-
[12]
OVNI: Obtuse but Versatile Nanoscale Instrumentation
BSC-PM (Barcelona Supercomputing Center - Programming Models). OVNI: Obtuse but Versatile Nanoscale Instrumentation. GitHub Repository, 2026
2026
-
[13]
Productive cluster programming with OmpSs
Javier Bueno, Luis Martinell, Alejandro Duran, Montse Farreras, Xavier Martorell, Rosa M Badia, Eduard Ayguade, and Jesús Labarta. Productive cluster programming with OmpSs. InEuro-Par 2011 Parallel Processing: 17th International Conference, Euro-Par 2011, Bordeaux, France, August 29-September 2, 2011, Proceedings, Part I 17, pages 555–566. Springer, 2011...
2011
-
[14]
Productive programming of GPU clusters with OmpSs
Javier Bueno, Judit Planas, Alejandro Duran, Rosa M Badia, Xavier Martorell, Eduard Ayguade, and Jesús Labarta. Productive programming of GPU clusters with OmpSs. In2012 IEEE 26th International Parallel and Distributed Processing Symposium, pages 557–568. IEEE, 2012
2012
-
[15]
A class of parallel tiled linear algebra algorithms for multicore architectures.Parallel Computing, 35(1):38–53, 2009
Alfredo Buttari, Julien Langou, Jakub Kurzak, and Jack Dongarra. A class of parallel tiled linear algebra algorithms for multicore architectures.Parallel Computing, 35(1):38–53, 2009
2009
-
[16]
Application of the parallex execution model to stencil-based problems.Computer Science-Research and Development, 28(2):253–261, 2013
Thomas Heller, Hartmut Kaiser, and Klaus Iglberger. Application of the parallex execution model to stencil-based problems.Computer Science-Research and Development, 28(2):253–261, 2013
2013
-
[17]
Characterizing the influence of system noise on large-scale applications by simulation
Torsten Hoefler, Timo Schneider, and Andrew Lumsdaine. Characterizing the influence of system noise on large-scale applications by simulation. InSC’10: Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–11. IEEE, 2010
2010
-
[18]
Performance impact of resource contention in multicore systems
Robert Hood, Haoqiang Jin, Piyush Mehrotra, Johnny Chang, Jahed Djomehri, Sharad Gavali, Dennis Jespersen, Kenichi Taylor, and Rupak Biswas. Performance impact of resource contention in multicore systems. In2010 IEEE international symposium on parallel & distributed processing (IPDPS), pages 1–12. IEEE, 2010
2010
-
[19]
Hpx: A task based programming model in a global address space
Hartmut Kaiser, Thomas Heller, Bryce Adelstein-Lelbach, Adrian Serio, and Dietmar Fey. Hpx: A task based programming model in a global address space. InProceedings of the 8th international conference on partitioned global address space programming models, pages 1–11, 2014
2014
-
[20]
Linux Man Pages, 2005
Andi Kleen.numactl(8) - Control NUMA policy for processes or shared memory. Linux Man Pages, 2005. Accessed: 2024-05-07
2005
-
[21]
Mitigating the NUMA effect on task-based runtime systems
Marcos Maroñas, Antoni Navarro, Eduard Ayguadé, and Vicenç Beltran. Mitigating the NUMA effect on task-based runtime systems. The Journal of Supercomputing, 79(13):14287–14312, 2023
2023
-
[22]
Memory bandwidth and machine balance in current high performance computers.IEEE computer society technical committee on computer architecture (TCCA) newsletter, 2(19-25), 1995
John D McCalpin et al. Memory bandwidth and machine balance in current high performance computers.IEEE computer society technical committee on computer architecture (TCCA) newsletter, 2(19-25), 1995
1995
-
[23]
Improving the integration of task nesting and dependencies in OpenMP
Josep M Perez, Vicenç Beltran, Jesus Labarta, and Eduard Ayguadé. Improving the integration of task nesting and dependencies in OpenMP. In2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 809–818. IEEE, 2017
2017
-
[24]
Putting intel® threading building blocks to work
Thomas Willhalm and Nicolae Popovici. Putting intel® threading building blocks to work. InProceedings of the 1st international workshop on Multicore software engineering, pages 3–4, 2008
2008
-
[25]
Roofline: an insightful visual performance model for multicore architec- tures.Communications of the ACM, 52(4):65–76, 2009
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architec- tures.Communications of the ACM, 52(4):65–76, 2009. Copyright line will be provided by the publisher
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.