Federated Semantic Knowledge Graphs for Laboratory Workflows: A Structured Expert Elicitation Methodology Demonstrated Through Bioanalytical Workflow Twins
Pith reviewed 2026-06-30 18:51 UTC · model grok-4.3
The pith
Federated semantic knowledge graphs capture tacit laboratory knowledge to identify where automation masks scientific failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
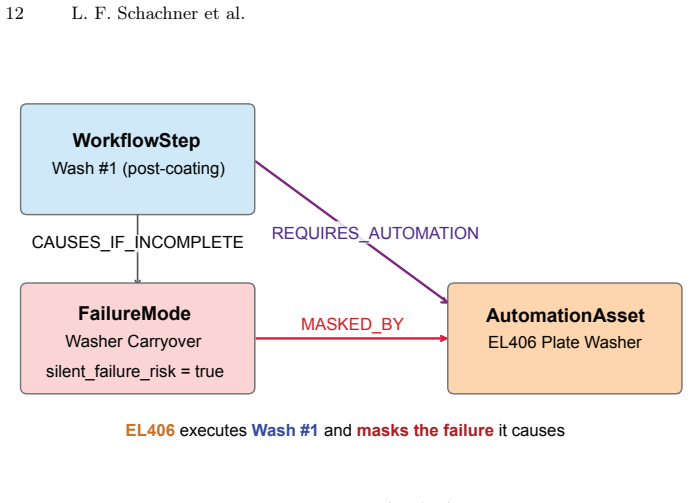
A MASKED_BY relationship in the federated graph encodes laboratory risks that remain invisible to protocol documents, sensor streams, and existing ontologies, because it links execution assets that report success to underlying compromises in scientific validity that only domain experts can identify.
What carries the argument
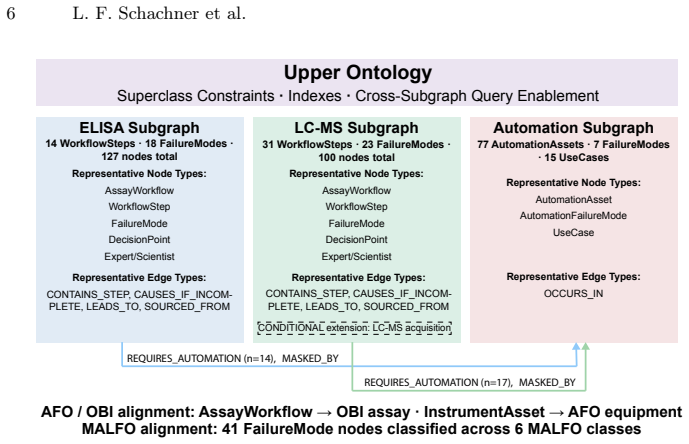
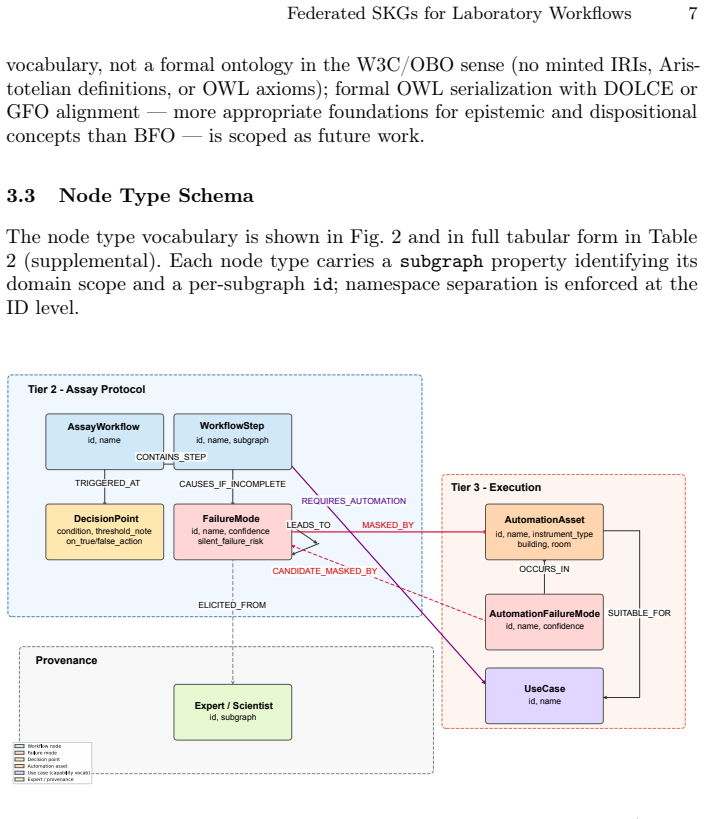
The federated Semantic Knowledge Graph (SKG) constructed from three tiers of elicited knowledge and aligned by a shared upper ontology, with the MASKED_BY edge as the central link for cross-subgraph reasoning.
If this is right
- Seven distinct query classes become possible that cannot be answered from any single source such as a protocol document or execution log.
- Cross-subgraph paths can locate decision points where human judgment cannot be replaced by automated checks.
- Execution assets can be classified according to whether they mask or surface validity-compromising conditions.
- The same elicitation method can be repeated to produce additional workflow twins that join the same federated structure.
Where Pith is reading between the lines
- The same elicitation lenses could be applied to non-bioanalytical domains that also combine protocol steps with physical instrumentation.
- Adding real-time sensor data streams as additional subgraphs might allow the MASKED_BY relation to trigger during live runs rather than after the fact.
- If the elicited graphs prove stable, they could serve as a training substrate for laboratory agents that must decide when to defer to human oversight.
Load-bearing premise
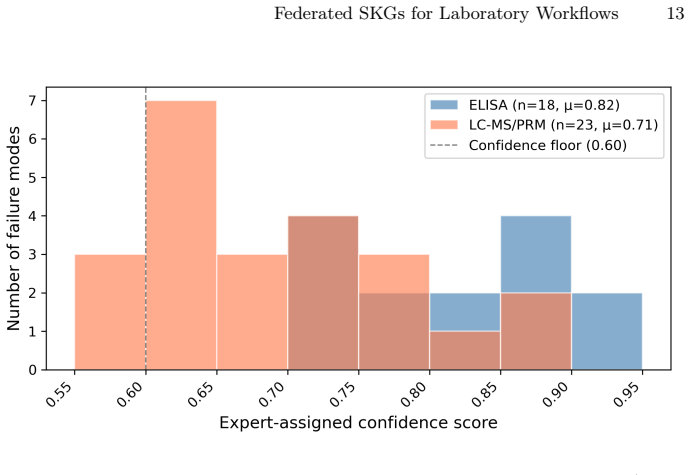
The confidence scores experts assign during elicitation remain accurate and consistent enough to support valid reasoning across separately built subgraphs.
What would settle it
A documented case in which a MASKED_BY traversal flags an automation-masked failure yet independent laboratory review confirms that scientific validity was preserved throughout the run.
Figures
read the original abstract
Laboratory workflows in pharmaceutical and biomedical research encode substantial tacit knowledge -- expert judgment about failure conditions, decision branching logic, and contextual dependencies -- that remains inaccessible to protocol documents, sensor streams, and existing biomedical ontologies. We present a repeatable structured expert elicitation methodology and federated Semantic Knowledge Graph (SKG) architecture for capturing and querying this knowledge, demonstrated through deployment at the Biochemical and Cellular Pharmacology Department of Genentech. Knowledge is elicited via the Protocol Intelligence Co-pilot, a purpose-built AI interview agent that applies structured elicitation lenses to surface tacit procedural knowledge with expert-assigned confidence scores, producing graph representations across three tiers: program-level decision milestones, assay protocol knowledge, and physical execution infrastructure. Separately constructed subgraphs, exemplified by immunoassay (ELISA), quantitative mass spectrometry (LC-MS/PRM), and laboratory automation, are aligned through a shared upper ontology and queried as a single federated graph. Evaluation demonstrates seven query types structurally unavailable from any individual data source, including a cross-subgraph traversal that identifies automation-masked silent failures -- conditions where execution logs report success while scientific validity is compromised. Critically, the MASKED_BY graph relationship encodes a class of laboratory risk invisible to current informatics platforms -- the structural gap that prevents existing systems from reasoning about scientific validity. This architecture provides the semantic world model that AI laboratory agents currently lack: a queryable representation of where workflows fail silently, where human judgment is irreplaceable, and which execution assets mask rather than detect failure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a structured expert elicitation methodology and federated Semantic Knowledge Graph (SKG) architecture for capturing tacit procedural knowledge in laboratory workflows (e.g., failure conditions and decision logic) that is inaccessible to standard documents or ontologies. It describes the Protocol Intelligence Co-pilot for eliciting knowledge with expert confidence scores, constructs aligned subgraphs for immunoassay (ELISA), quantitative mass spectrometry (LC-MS/PRM), and laboratory automation at Genentech, and introduces the MASKED_BY relationship. Evaluation is claimed to demonstrate seven new query types, including cross-subgraph traversals that identify automation-masked silent failures.
Significance. If the elicited graphs and MASKED_BY traversals prove reliable, the work would supply a queryable semantic layer that current laboratory informatics and AI agents lack, enabling reasoning about scientific validity and masked risks. The real-world deployment at Genentech and the explicit encoding of tacit knowledge via structured elicitation are concrete strengths that distinguish this from purely theoretical ontology work.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the claim that the evaluation 'demonstrates seven query types' and the utility of MASKED_BY traversals for identifying masked failures rests on demonstration alone, with no quantitative metrics, error analysis, inter-expert agreement scores, or validation against ground-truth failure cases. This is load-bearing for the central claim that the federated SKG supports valid cross-subgraph reasoning about scientific validity.
- [Methodology / Co-pilot description] Methodology and Protocol Intelligence Co-pilot description: the assumption that expert-assigned confidence scores remain accurate and consistent enough to support sound inference across subgraphs is stated but not tested (e.g., no reported inter-rater reliability, score calibration against known outcomes, or sensitivity analysis of query results to score variation).
minor comments (2)
- [Architecture] The upper ontology alignment process between subgraphs is described at a high level; a concrete example of how a specific concept (e.g., a decision milestone) is mapped across the ELISA, LC-MS, and automation subgraphs would improve reproducibility.
- [Graph representation] Notation for the three-tier graph structure (program-level, assay protocol, execution infrastructure) and the MASKED_BY relationship could be formalized with a small diagram or set of example triples to reduce ambiguity for readers outside the immediate domain.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, agreeing that the evaluation is demonstrative in nature and proposing revisions to clarify scope and limitations.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the claim that the evaluation 'demonstrates seven query types' and the utility of MASKED_BY traversals for identifying masked failures rests on demonstration alone, with no quantitative metrics, error analysis, inter-expert agreement scores, or validation against ground-truth failure cases. This is load-bearing for the central claim that the federated SKG supports valid cross-subgraph reasoning about scientific validity.
Authors: We agree that the evaluation consists of structural demonstration of the seven query types rather than quantitative validation with metrics or ground-truth cases. This reflects the paper's focus on a new methodology and architecture for capturing tacit knowledge that is inaccessible to existing systems. We will revise the abstract and Evaluation section to explicitly frame the work as a demonstration of enabled query capabilities, to note the lack of quantitative metrics as a limitation, and to discuss challenges in obtaining ground-truth for masked failures (which are undetected by standard informatics). revision: yes
-
Referee: [Methodology / Co-pilot description] Methodology and Protocol Intelligence Co-pilot description: the assumption that expert-assigned confidence scores remain accurate and consistent enough to support sound inference across subgraphs is stated but not tested (e.g., no reported inter-rater reliability, score calibration against known outcomes, or sensitivity analysis of query results to score variation).
Authors: We acknowledge that inter-rater reliability, calibration, and sensitivity analyses for the confidence scores are not reported. The scores are elicited directly from domain experts to represent their uncertainty in tacit knowledge and are intended to support filtering or weighting in queries. We will revise the Methodology section to discuss this assumption more explicitly, including implications for cross-subgraph inference, and to identify empirical validation of score consistency as future work. The subgraph-specific expert elicitation reduces some cross-rater concerns in the current deployment. revision: yes
Circularity Check
No circularity: methodology report without derivation or fitting
full rationale
The paper describes a structured expert elicitation process and federated SKG architecture for laboratory workflows, illustrated via deployment at Genentech. No equations, parameter fitting, predictions, or uniqueness theorems appear. Claims rest on the described methodology and example queries rather than any self-referential reduction or load-bearing self-citation chain. The work is self-contained as an applied methodology report.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Experts can assign accurate and consistent confidence scores to tacit procedural knowledge during structured AI interviews
- domain assumption Subgraphs from different assays can be aligned through a shared upper ontology without introducing semantic inconsistencies that invalidate cross-subgraph queries
invented entities (1)
-
MASKED_BY graph relationship
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abolhasani, M., Kumacheva, E.: The rise of self-driving labs in chemical and mate- rials sciences. Nat. Synth. 2(3), 197–206 (2023). https://doi.org/10.1038/s44160- 022-00231-0
-
[2]
https://www.allotrope.org
Allotrope Foundation: Allotrope Foundation Ontology (AFO). https://www.allotrope.org. Accessed April 2026
2026
-
[3]
Avizienis, A., Laprie, J.-C., Randell, B., Landwehr, C.: Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secure Comput. 1(1), 11–33 (2004). https://doi.org/10.1109/TDSC.2004.2
-
[4]
Bai, J., et al.: A dynamic knowledge graph approach to distributed self-driving laboratories. Nat. Commun. 5, 462 (2024). https://doi.org/10.1038/s41467-023- 44599-9
-
[5]
In: Formal Ontology in Information Systems – Proceedings of FOIS 2024
Compagno, D., Borgo, S.: MALFO: a BFO-grounded ontology of malfunction- related occurrents. In: Formal Ontology in Information Systems – Proceedings of FOIS 2024. IOS Press (2024). https://ebooks.iospress.nl/volumearticle/71401
2024
-
[6]
Oxford University Press, Oxford (1991)
Cooke, R.M.: Experts in Uncertainty: Opinion and Subjective Probability in Science. Oxford University Press, Oxford (1991)
1991
-
[7]
D’Amico, R.D., Sarkar, A., Karray, M.H., Addepalli, S., Erkoyuncu, J.A.: Knowledge transfer in Digital Twins: The methodology to develop Cog- nitive Digital Twins. CIRP J. Manuf. Sci. Technol. 52, 366–385 (2024). https://doi.org/10.1016/j.cirpj.2024.06.007
-
[8]
Nature 635, 890–897 (2024)
Dai, T., Vijayakrishnan, S., Szczypiński, F.T., et al.: Autonomous mobile robots for exploratory synthetic chemistry. Nature 635, 890–897 (2024)
2024
-
[9]
Nat Comput Sci 6, 67–82 (2026)
Darvish, K., Sohal, A., Mandal, A., et al.: MATTERIX: toward a digital twin for robotics-assisted chemistry laboratory automation. Nat Comput Sci 6, 67–82 (2026). https://doi.org/10.1038/s43588-025-00924-4
-
[10]
EFSA: Guidance on expert knowledge elicitation in food and feed safety risk assessment. EFSA J. 12(6), 3734 (2014). https://doi.org/10.2903/j.efsa.2014.3734
-
[11]
FDA: Bioanalytical Method Validation Guidance for Industry. U.S. Food and Drug Administration, Silver Spring, MD (May 2018). https://www.fda.gov/media/70858/download
2018
-
[12]
Gao, S., et al.: Large language model powered knowledge graph con- struction for mental health exploration. Nat. Commun. 16, 7121 (2025). https://doi.org/10.1038/s41467-025-62781-z
-
[13]
In: Dias, L.C., Mor- ton, A., Quigley, J
Gosling, J.P.: SHELF: the Sheffield elicitation framework. In: Dias, L.C., Mor- ton, A., Quigley, J. (eds.) Elicitation. International Series in Operations Re- search & Management Science, vol. 261, pp. 61–93. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-65052-4_4
-
[14]
Hanea, A.M., Hemming, V., Nane, G.F.: Uncertainty Quantification with Ex- perts: Present Status and Research Needs. Risk Anal. 42(2), 254–263 (2022). https://doi.org/10.1111/risa.13718 Federated SKGs for Laboratory Workflows 17
-
[15]
International Council for Harmonisation, Step 4 (May 2022)
ICH: ICH Harmonised Guideline M10: Bioanalytical Method Validation and Study Sample Analysis. International Council for Harmonisation, Step 4 (May 2022). https://www.ich.org/page/multidisciplinary-guidelines
2022
-
[16]
Interna- tional Council for Harmonisation, Step 4 (2023)
ICH: ICH Harmonised Guideline Q14: Analytical Procedure Development. Interna- tional Council for Harmonisation, Step 4 (2023). https://www.ich.org/page/quality- guidelines
2023
-
[17]
International Medical Device Reg- ulators Forum (2022)
IMDRF: Machine Learning-enabled Medical Devices: Key Terms and Definitions IMDRF/AIML WG/N67. International Medical Device Reg- ulators Forum (2022). https://www.imdrf.org/sites/default/files/2022- 05/IMDRF%20AIMD%20WG%20Final%20Document%20N67.pdf
2022
-
[18]
Inokuchi, K., Nakazato, J., Tsukada, M., Esaki, H.: Semantic digital twin for interoperability and Comprehensive Management of Data Assets. In: 2023 IEEE International Conference on Metaverse Computing, Net- working and Applications (MetaCom), Kyoto, Japan, pp. 217–225 (2023). https://doi.org/10.1109/MetaCom57706.2023.00049
-
[19]
Procedia Comput
Jungmann, M., Lazarova-Molnar, S.: Towards Fusing Data and Expert Knowledge for Better-Informed Digital Twins: An Initial Framework. Procedia Comput. Sci. 238, 639–646 (2024)
2024
-
[20]
Lakoff, G.: Hedges: A study in meaning criteria and the logic of fuzzy concepts. J. Philos. Log. 2, 458–508 (1973)
1973
-
[21]
IFAC-PapersOnLine 55(10), 13–18 (2022)
Meyers, B., et al.: Knowledge Graphs in Digital Twins for Manufacturing - Lessons Learned from an Industrial Case at Atlas Copco Airpower. IFAC-PapersOnLine 55(10), 13–18 (2022). https://doi.org/10.1016/j.ifacol.2022.09.361
-
[22]
Mihindukulasooriya, N., et al.: Knowledge graph induction enabling recommending and trend analysis: a corporate research community use case. In: Sattler, U., et al. (eds.) The Semantic Web – ISWC 2022. LNCS, vol. 13489, pp. 755–771. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19433-7_47
-
[23]
Osuagwu, C.C., Okafor, E.C.: Framework for eliciting knowledge for a medical laboratory diagnostic expert system. Expert Syst. Appl. 37(7), 5009–5016 (2010). https://doi.org/10.1016/j.eswa.2009.12.012
-
[24]
PLOS ONE 11(4), e0154556 (2016)
OBI Consortium: The Ontology for Biomedical Investigations. PLOS ONE 11(4), e0154556 (2016). https://doi.org/10.1371/journal.pone.0154556
-
[25]
In: ISR Europe 2023 – 56th International Symposium on Robotics (2023)
Odonkar, S., et al.: Towards a Semantic Digital Twin for Marine Robotics. In: ISR Europe 2023 – 56th International Symposium on Robotics (2023). https://doi.org/10.13140/RG.2.2.27995.13604
-
[26]
Ploennigs, J., et al.: Scaling knowledge graphs for automating AI of digital twins. In: Sattler, U., et al. (eds.) The Semantic Web – ISWC 2022. LNCS, vol. 13489, pp. 733–750. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19433-7_46
-
[27]
Ramonell, C., et al.: Knowledge graph-based data integration system for digital twins of built assets. Autom. Constr. 156, 105109 (2023). https://doi.org/10.1016/j.autcon.2023.105109
-
[28]
Remy, F., Demuynck, K., Demeester, T.: BioLORD-2023: semantic tex- tual representations fusing large language models and clinical knowledge graph insights. J. Am. Med. Inform. Assoc. 31(9), 1844–1855 (2024). https://doi.org/10.1093/jamia/ocae029
-
[29]
O’Reilly Media, Sebastopol, CA (2015)
Robinson, I., Webber, J., Eifrem, E.: Graph Databases: New Opportunities for Connected Data, 2nd edn. O’Reilly Media, Sebastopol, CA (2015)
2015
-
[30]
In: 4th IEEE International Conference on Industrial Cyber-Physical Systems (ICPS 2021)
Sahlab, N., et al.: Knowledge graphs as enhancers of intelligent digital twins. In: 4th IEEE International Conference on Industrial Cyber-Physical Systems (ICPS 2021). IEEE (2021). https://doi.org/10.1109/ICPS49255.2021.9468219 18 L. F. Schachner et al
-
[31]
Schröder, M., Staehlke, S., Groth, P., Nebe, J.B., Spors, S., Krüger, F.: Structure-based knowledge acquisition from electronic lab notebooks for re- search data provenance documentation. J. Biomed. Semantics 13(1), 4 (2022). https://doi.org/10.1186/s13326-021-00257-x
-
[32]
Shen, X., Wagg, D.J., Tipuric, M., et al.: Digital twins as self-models for intelligent structures. Sci Rep 15, 30327 (2025). https://doi.org/10.1038/s41598-025-14347-8
-
[33]
Value Health 27(10), 1393–1403 (2024)
Soares, M., et al.: Recommendations on the use of structured expert elicitation proto- cols for healthcare decision making: a good practices report of an ISPOR task force. Value Health 27(10), 1393–1403 (2024). https://doi.org/10.1016/j.jval.2024.07.027
-
[34]
In: Bue, A.D., Canton, C., Pont-Tuset, J., Tommasi, T
Steenwinckel,B.,etal.:Qualityincolor:usingknowledgegraphsforenhancedquality control in an automotive paintshop. In: Dragoni, M., et al. (eds.) The Semantic Web – ISWC 2024. LNCS, vol. 15233. Springer, Cham (2024). https://doi.org/10.1007/978- 3-031-77847-6_13
-
[35]
IEEE International Confer- ence on Emerging Technologies and Factory Automation, pp
Steinmetz, C., Schroeder, G.N., Sulak, A., Tuna, K., Binotto, A.P.D., Rettberg, A., Pereira, C.E.: A methodology for creating semantic digital twin models supported by knowledge graphs. IEEE International Confer- ence on Emerging Technologies and Factory Automation, pp. 1–7 (2022). https://doi.org/10.1109/ETFA52439.2022.9921499
-
[36]
Tao, F., Zhang, H., Liu, A., Nee, A.Y.C.: Digital twin in indus- try: state-of-the-art. IEEE Trans. Ind. Inform. 15(4), 2405–2415 (2019). https://doi.org/10.1109/TII.2018.2873186
-
[37]
Thieme, A., Renwick, S., Marschmann, M., Guimaraes, P.I., Weissenborn, S., Clifton, J.: Deep integration of low-cost liquid handling robots in an industrial pharmaceutical development environment. SLAS Technol. 29(5), 100180 (2024). https://doi.org/10.1016/j.slast.2024.100180
-
[38]
Tom, G., et al.: Self-driving laboratories for chemistry and materials science. Chem. Rev. 124(16), 9633–9732 (2024). https://doi.org/10.1021/acs.chemrev.4c00055
-
[39]
W3C Recommendation (2013)
W3C: PROV-O: The PROV Ontology. W3C Recommendation (2013). http://www.w3.org/TR/2013/REC-prov-o-20130430/
2013
-
[40]
Wierenga, R.P., et al.: PyLabRobot: an open-source, hardware-agnostic inter- face for liquid-handling robots and accessories. Device 1(4), 100111 (2023). https://doi.org/10.1016/j.device.2023.100111
-
[41]
Zadeh, L.: A Fuzzy-Set-Theoretic Interpretation of Linguistic Hedges. J. Cybern. 3, 4–34 (1972). https://doi.org/10.1080/01969727208542910
-
[42]
In: The Semantic Web – ESWC 2024 Satellite Events
Zhang, B., et al.: OntoChat: a framework for conversational ontology engineering using language models. In: The Semantic Web – ESWC 2024 Satellite Events. LNCS. Springer, Cham (2025). https://doi.org/10.1007/978-3-031-78952-6_10
-
[43]
Zhang, Y., Sui, X., Pan, F., et al.: A comprehensive large-scale biomedical knowledge graph for AI-powered data-driven biomedical research. Nat. Mach. Intell. 7, 602–614 (2025). https://doi.org/10.1038/s42256-025-01014-w Supplemental Material Federated Semantic Knowledge Graphs for Laboratory Workflows: A Structured Expert Elicitation Methodology Demonstr...
-
[44]
All subgraphs contain failure modes
FailureMode What it represents: Any condition — arising from reagents, instruments, operators, environment, or protocol logic — that causes an assay to produce incorrect, unreliable, or undetectable results. All subgraphs contain failure modes. They differ by domain (immunoassay vs. mass spectrometry vs. robotics) but all answer the same questions: what w...
2024
-
[45]
Steps are sequentially ordered and may depend on the outcome of prior steps
WorkflowStep What it represents: A discrete, named action in a protocol that transforms the state of a sample, instrument, or dataset. Steps are sequentially ordered and may depend on the outcome of prior steps. Universal Properties — WorkflowStep Property Type Allowed Values Required Description id string STEP-[DOMAIN]-[NNN] YES Unique identifier step_na...
-
[46]
DecisionPoints capture the judgment calls that standard SOPs typically omit
DecisionPoint What it represents: An explicit choice a scientist or operator makes during protocol execution — one where the correct option depends on context and where the wrong choice causes downstream failure. DecisionPoints capture the judgment calls that standard SOPs typically omit. Universal Properties — DecisionPoint Property Type Allowed Values R...
-
[47]
The Expert node records who said what, under what conditions, and with what calibrated confidence — providing traceable provenance for every knowledge claim
Expert What it represents: A person whose tacit knowledge is the primary source for nodes in a given subgraph. The Expert node records who said what, under what conditions, and with what calibrated confidence — providing traceable provenance for every knowledge claim. Universal Properties — Expert Property Type Allowed Values Required Description id strin...
-
[48]
The same physical instrument may be referenced by multiple subgraphs — a liquid handler used in both the Automation and ELISA subgraphs, for instance
AutomationAsset What it represents: A physical instrument, device, or hardware component that participates in assay execution. The same physical instrument may be referenced by multiple subgraphs — a liquid handler used in both the Automation and ELISA subgraphs, for instance. Shared physical assets carry a single shared ID across subgraphs. AFO alignment...
-
[49]
UseCase nodes anchor the knowledge graph to its decision-theoretic purpose: assays exist to reduce uncertainty in service of specific decisions
UseCase What it represents: A scientific workflow or experimental objective that motivates the existence of one or more protocol subgraphs. UseCase nodes anchor the knowledge graph to its decision-theoretic purpose: assays exist to reduce uncertainty in service of specific decisions. Universal Properties — UseCase Property Type Required Description id str...
-
[50]
QualityFlags describe gaps in the knowledge graph itself — decisions not yet made, ambiguities not yet resolved — not failures in a protocol run
QualityFlag What it represents: An explicit marker that something in the subgraph is uncertain, unresolved, or known to be inconsistent with best practice. QualityFlags describe gaps in the knowledge graph itself — decisions not yet made, ambiguities not yet resolved — not failures in a protocol run. Universal Properties — QualityFlag Property Type Allowe...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.