Quantum Computing and Data Processing for Frequent Itemset Mining
Pith reviewed 2026-06-29 05:25 UTC · model grok-4.3
The pith
QFM quantum framework for frequent itemset mining delivers 96% average improvement over classical baselines through specialized qubit encoding and oracles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QFM introduces bit-vector qubit encoding to organize transaction data into branchless bit-vectors for systematic uncomputation, mining-aware candidate superposition to prepare a quantum superposition over valid candidates at each lattice level rather than the full itemset lattice, and bit-parallel threshold marking to construct a logarithmic-depth threshold-marking oracle for reliable repeated support verification within hardware coherence limits, with theoretical time complexity analysis and empirical results showing 96% improvement on average.
What carries the argument
Bit-parallel threshold marking, the logarithmic-depth oracle that enables repeated support verification on quantum hardware.
Load-bearing premise
The bit-parallel threshold-marking oracle can perform reliable repeated support verification within hardware coherence limits.
What would settle it
Demonstrating that decoherence prevents accurate support marking after several oracle applications on a real quantum processor would disprove the practicality of the approach.
Figures


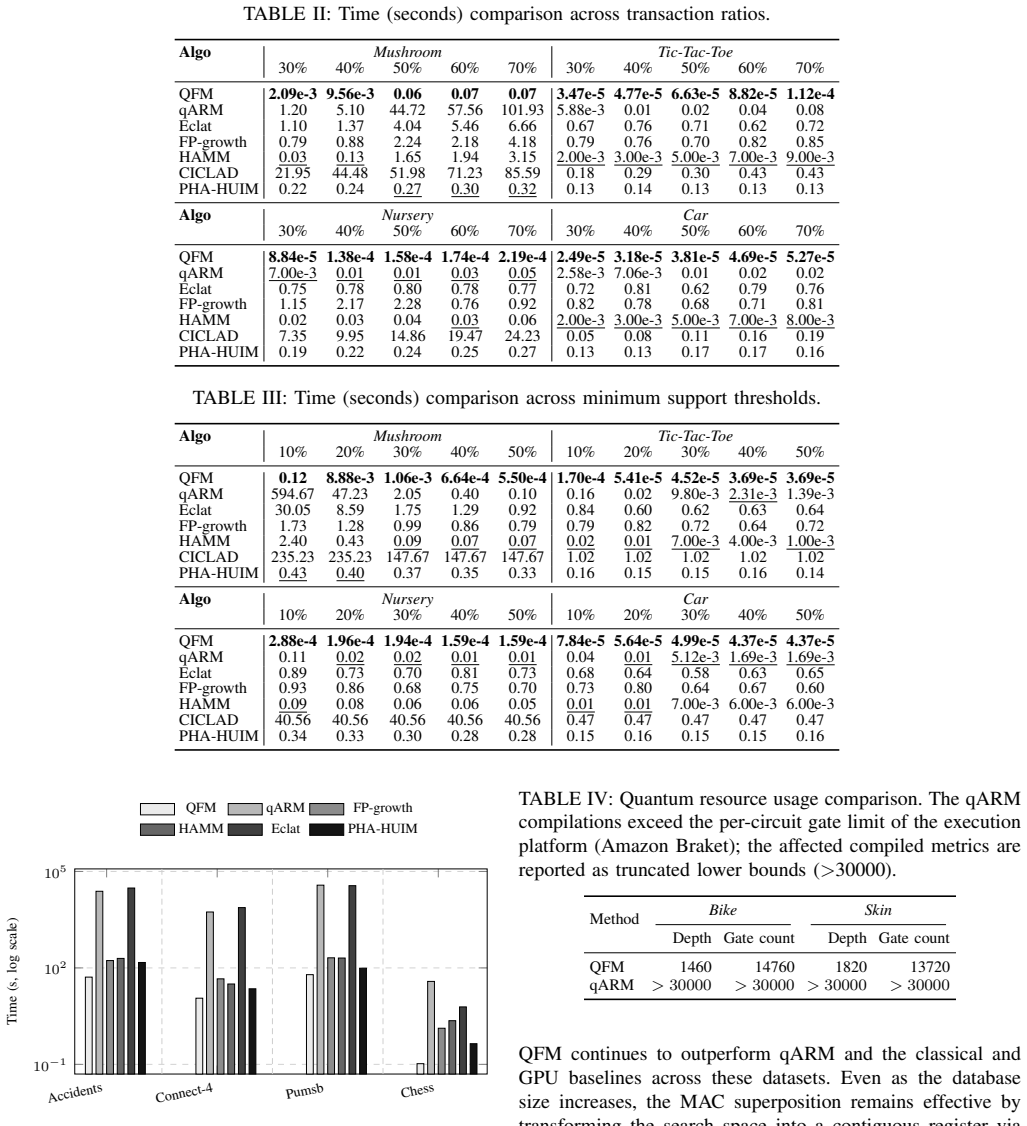
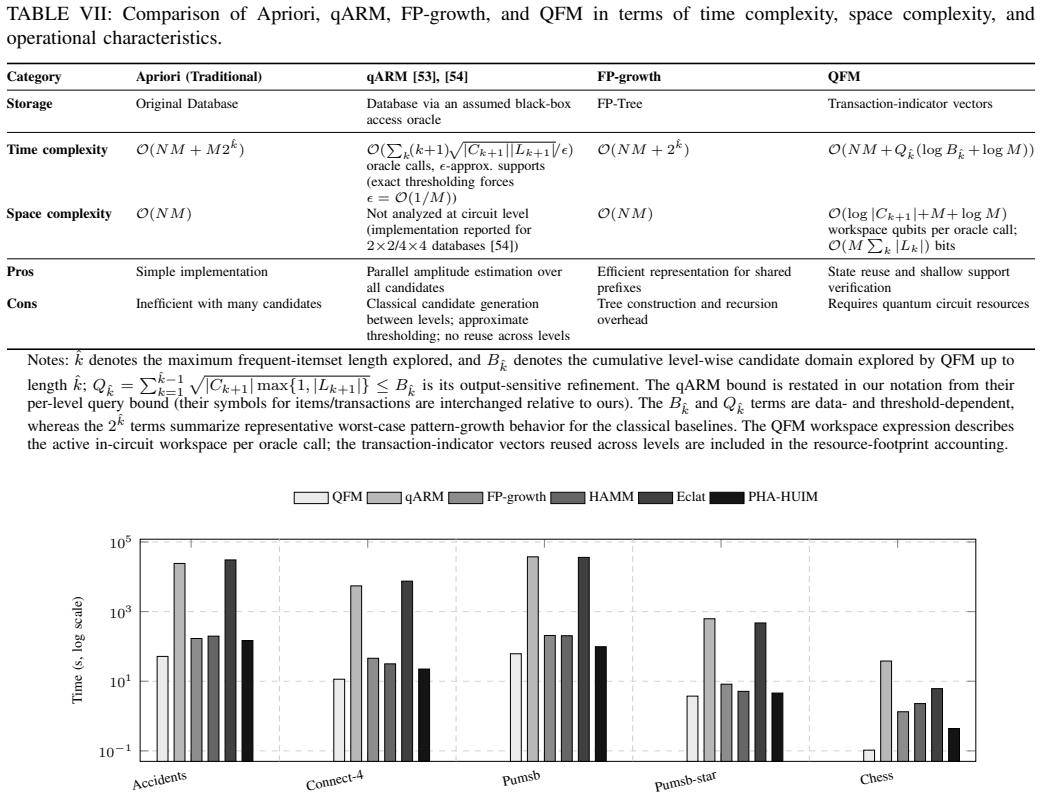
read the original abstract
Frequent Itemset Mining (FIM) is an important task in data analytics, where classical algorithms face scalability bottlenecks from the combinatorial growth of candidates and the memory overhead of their data structures. Inspired by recent developments in quantum computing, in this paper, we propose the Quantum Frequent-itemset Mining (QFM) data-processing framework for FIM. Following the level-wise structure of the itemset lattice, QFM introduces three mechanisms: (1) Bit-Vector Qubit Encoding for quantum data representation, which organizes transaction data into branchless bit-vectors to facilitate systematic uncomputation; (2) Mining-Aware Candidate Superposition, which prepares a quantum superposition over valid candidates at each lattice level rather than the full itemset lattice; and (3) Bit-Parallel Threshold Marking, which constructs a logarithmic-depth threshold-marking oracle for reliable repeated support verification within hardware coherence limits. We provide theoretical time complexity analysis, implement QFM on IBM Qiskit and Amazon Braket, and evaluate it on real-world datasets against representative classical baselines, where QFM achieves 96% improvement on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Quantum Frequent-itemset Mining (QFM) framework for frequent itemset mining. It follows the level-wise itemset lattice structure and introduces three mechanisms: Bit-Vector Qubit Encoding for transaction data representation, Mining-Aware Candidate Superposition to prepare superpositions over valid candidates, and Bit-Parallel Threshold Marking to build a logarithmic-depth oracle for support verification. The manuscript provides theoretical time complexity analysis, reports an implementation on IBM Qiskit and Amazon Braket, and claims that QFM achieves a 96% average improvement over representative classical baselines on real-world datasets.
Significance. If the hardware implementation and empirical improvement claims hold after verification, the work would provide a concrete demonstration of quantum data-processing techniques applied to a core data-mining task, with potential relevance for hybrid quantum-classical analytics pipelines handling combinatorial search. The explicit design choices for uncomputation-friendly encoding and lattice-aware superposition constitute a strength worth preserving.
major comments (2)
- [Abstract] Abstract: the 96% average improvement claim is presented without error bars, dataset sizes or characteristics, exact classical baseline implementations and runtimes, or confirmation that the circuits were executed on physical hardware versus ideal simulation. These details are load-bearing for the central empirical result.
- [Abstract] Abstract (paragraph on Bit-Parallel Threshold Marking): the claim that the logarithmic-depth oracle enables 'reliable repeated support verification within hardware coherence limits' is unsupported by per-oracle error bounds, iteration counts per lattice level, or results from noisy simulation or real-device execution. This assumption underpins the scalability argument for the reported improvement.
minor comments (1)
- [Abstract] Abstract: the phrase 'real-world datasets' is used without naming the datasets or their scale, which would aid reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract. We agree that additional details and qualifications are needed to support the central claims and will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 96% average improvement claim is presented without error bars, dataset sizes or characteristics, exact classical baseline implementations and runtimes, or confirmation that the circuits were executed on physical hardware versus ideal simulation. These details are load-bearing for the central empirical result.
Authors: We agree the abstract should be self-contained on this point. The experimental section of the manuscript already details the real-world datasets (including sizes and characteristics), the representative classical baselines with their implementations and runtimes, and the simulation-based execution on Qiskit and Braket. We will revise the abstract to concisely incorporate error bars on the 96% figure, these dataset and baseline specifics, and explicit confirmation that results derive from ideal simulation (with any hardware runs noted separately if present). revision: yes
-
Referee: [Abstract] Abstract (paragraph on Bit-Parallel Threshold Marking): the claim that the logarithmic-depth oracle enables 'reliable repeated support verification within hardware coherence limits' is unsupported by per-oracle error bounds, iteration counts per lattice level, or results from noisy simulation or real-device execution. This assumption underpins the scalability argument for the reported improvement.
Authors: The abstract phrasing draws from the theoretical logarithmic-depth analysis of the oracle (detailed in the complexity section), which is intended to support repeated queries. However, we acknowledge the absence of per-oracle error bounds, explicit iteration counts, or noisy/hardware results in the current manuscript. We will revise the abstract to qualify or remove this specific claim, replacing it with a reference to the theoretical depth analysis while noting that empirical noisy-device validation remains future work. revision: yes
Circularity Check
QFM derivation self-contained; no circular reductions identified
full rationale
The paper proposes QFM via three explicit mechanisms (bit-vector encoding, mining-aware superposition, bit-parallel threshold oracle), supplies a theoretical complexity analysis, and reports empirical speedups from Qiskit/Braket implementations on real datasets. No equation, definition, or performance claim is shown to reduce by construction to a fitted parameter, self-referential definition, or self-citation chain; the 96% figure is presented as an observed outcome of the implemented algorithm rather than an input.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simulating physics with computers,
R. P. Feynman, “Simulating physics with computers,”International Journal of Theoretical Physics, vol. 21, no. 6-7, pp. 467–482, 1982
1982
-
[2]
Quantum theory, the Church–Turing principle and the universal quantum computer,
D. Deutsch, “Quantum theory, the Church–Turing principle and the universal quantum computer,”Proceedings of the Royal Society of London. Series A, Mathematical and Physical Sciences, vol. 400, no. 1818, pp. 97–117, 1985
1985
-
[3]
IBM Quantum Roadmap,
IBM Quantum, “IBM Quantum Roadmap,” 2024, accessed 13 May
2024
-
[4]
Available: https://www.ibm.com/roadmaps/quantum/
[Online]. Available: https://www.ibm.com/roadmaps/quantum/
-
[5]
Benchmarking an 11-qubit quantum computer,
K. Wrightet al., “Benchmarking an 11-qubit quantum computer,”Nature Communications, vol. 10, no. 1, p. 5464, 2019
2019
-
[6]
Quantum computational advantage with a programmable photonic processor,
L. S. Madsen, F. Laudenbach, M. Falamarzi Askaraniet al., “Quantum computational advantage with a programmable photonic processor,” Nature, vol. 606, no. 7912, pp. 75–81, 2022
2022
-
[7]
Quantum supremacy using a programmable superconduct- ing processor,
F. A.et al., “Quantum supremacy using a programmable superconduct- ing processor,”Nature, vol. 574, pp. 505–510, 2019
2019
-
[8]
Hardware for useful quantum computing,
IBM Quantum, “Hardware for useful quantum computing,” https://ww w.ibm.com/quantum/hardware, accessed: 2026-06-11
2026
-
[9]
Microsoft and Atom Computing offer a commercial quantum machine with the largest number of entangled logical qubits on record,
K. Svore, “Microsoft and Atom Computing offer a commercial quantum machine with the largest number of entangled logical qubits on record,” https://azure.microsoft.com/en-us/blog/quantum/2024/11/19/microsof t-and-atom-computing-offer-a-commercial-quantum-machine-with-t he-largest-number-of-entangled-logical-qubits-on-record/, Nov. 2024, accessed: 2026-06-11
2024
-
[10]
Meet Willow, our state-of-the-art quantum chip,
H. Neven, “Meet Willow, our state-of-the-art quantum chip,” https://bl og.google/innovation-and-ai/technology/research/google-willow-quant um-chip/, Dec. 2024, accessed: 2026-06-11
2024
-
[11]
Quantum machine learning,
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, “Quantum machine learning,”Nature, vol. 549, no. 7671, pp. 195–202, 2017
2017
-
[12]
Algorithms for quantum computation: Discrete logarithms and factoring,
P. W. Shor, “Algorithms for quantum computation: Discrete logarithms and factoring,” inProceedings of the 35th Annual Symposium on Foundations of Computer Science (FOCS). IEEE, 1994, pp. 124–134
1994
-
[13]
A fast quantum mechanical algorithm for database search,
L. K. Grover, “A fast quantum mechanical algorithm for database search,” inProceedings of the 28th Annual ACM Symposium on Theory of Computing (STOC ’96). ACM, 1996, pp. 212–219
1996
-
[14]
Quantum amplitude amplification and estimation,
G. Brassard, P. Høyer, M. Mosca, and A. Tapp, “Quantum amplitude amplification and estimation,” inQuantum Computation and Informa- tion, ser. Contemporary Mathematics. American Mathematical Society, 2002, vol. 305, pp. 53–74
2002
-
[15]
Fast algorithms for mining association rules,
R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” inProceedings of the 20th International Conference on Very Large Data Bases (VLDB ’94). Santiago, Chile: Morgan Kaufmann, 1994, pp. 487–499
1994
-
[16]
Mining frequent patterns without candidate generation: A frequent-pattern tree approach,
J. Han, J. Pei, Y . Yin, and R. Mao, “Mining frequent patterns without candidate generation: A frequent-pattern tree approach,”Data Mining and Knowledge Discovery, vol. 8, no. 1, pp. 53–87, 2004
2004
-
[17]
Scalable algorithms for association mining,
M. J. Zaki, “Scalable algorithms for association mining,”IEEE Transac- tions on Knowledge and Data Engineering, vol. 12, no. 3, pp. 372–390, 2000
2000
-
[18]
Mining high utility itemsets using prefix trees and utility vectors,
J. Qu, P. Fournier-Viger, M. Liu, B. Hang, and C. Hu, “Mining high utility itemsets using prefix trees and utility vectors,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 10, pp. 10 224–10 236, 2023
2023
-
[19]
Efim: A highly efficient algorithm for high-utility itemset mining,
S. Zida, P. Fournier-Viger, J. Lin, C. Wu, and V . S. Tseng, “Efim: A highly efficient algorithm for high-utility itemset mining,”Knowledge and Information Systems, vol. 51, no. 2, pp. 595–625, 2017
2017
-
[20]
FHM: Faster high-utility itemset mining using estimated utility co-occurrence pruning,
S.-P. Liu, C.-W. Wu, and V . S. Tseng, “FHM: Faster high-utility itemset mining using estimated utility co-occurrence pruning,” inProceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2012, pp. 883–892
2012
-
[21]
Tk- fim: Top-k frequent itemset mining with deep learning,
S. Iqbal, A. Shahid, M. Roman, Z. Khan, S. Al-Otaibi, and L. Yu, “Tk- fim: Top-k frequent itemset mining with deep learning,”PeerJ Computer Science, vol. 7, p. e717, 2021
2021
-
[22]
Efficient top-kfrequent itemset mining on massive data,
X. Wan, Q. Liu, and G. Li, “Efficient top-kfrequent itemset mining on massive data,”Data Science and Engineering, vol. 9, pp. 177–203, 2024
2024
-
[23]
Mining frequent patterns in data streams at multiple time granularities,
C. Giannella, J. Han, J. Pei, X. Yan, and P. S. Yu, “Mining frequent patterns in data streams at multiple time granularities,” 2003. [Online]. Available: https://hanj.cs.illinois.edu/pdf/fpstm03.pdf
2003
-
[24]
Gc-tree: A fast online algorithm for mining frequent closed itemsets,
J. Chen and S. Li, “Gc-tree: A fast online algorithm for mining frequent closed itemsets,” inAdvances in Knowledge Discovery and Data Mining (PAKDD 2007), ser. Lecture Notes in Computer Science, vol. 4426. Springer, 2007, pp. 457–468
2007
-
[26]
On When and How to use SAT to Mine Frequent Itemsets
[Online]. Available: https://arxiv.org/abs/1207.6253
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
A data structure perspective to the rdd-based apriori algorithm on spark,
P. Singh, S. Singh, P. K. Mishra, and R. Garg, “A data structure perspective to the rdd-based apriori algorithm on spark,” arXiv preprint arXiv:1908.01338, 2019. [Online]. Available: https: //arxiv.org/abs/1908.01338
-
[28]
S-fpg: An efficient parallel fp- growth algorithm under apache spark,
A. Diaby, I. Camara, and M. Ndiaye, “S-fpg: An efficient parallel fp- growth algorithm under apache spark,” inProceedings of the 2017 2nd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA). IEEE, 2017, pp. 360–364
2017
-
[29]
Frequent item set mining,
C. Borgelt, “Frequent item set mining,”Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 2, no. 6, pp. 437–456, 2012
2012
-
[30]
Frequent itemset mining for big data,
S. Moens, E. Aksehirli, and B. Goethals, “Frequent itemset mining for big data,” in2013 IEEE International Conference on Big Data, 2013, pp. 111–118
2013
-
[31]
Logical reversibility of computation,
C. H. Bennett, “Logical reversibility of computation,”IBM Journal of Research and Development, vol. 17, no. 6, pp. 525–532, 1973
1973
-
[32]
H-mine: Hyper-structure mining of frequent patterns in large databases,
J. Peiet al., “H-mine: Hyper-structure mining of frequent patterns in large databases,” inProceedings 2001 IEEE International Conference on Data Mining. IEEE, 2001, pp. 441–448
2001
-
[33]
Cp-tree: a tree structure for single-pass frequent pattern mining,
S. K. Tanbeer, C. F. Ahmed, B.-S. Jeong, and Y .-K. Lee, “Cp-tree: a tree structure for single-pass frequent pattern mining,” inPacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2008, pp. 1022–1027
2008
-
[34]
Cantree: a tree structure for efficient incremental mining of frequent patterns,
C.-S. Leung, Q. I. Khan, and T. Hoque, “Cantree: a tree structure for efficient incremental mining of frequent patterns,” inFifth IEEE International Conference on Data Mining (ICDM’05). IEEE, 2005, pp. 8–pp
2005
-
[35]
Mining frequent patterns without candidate generation,
J. Han, J. Pei, and Y . Yin, “Mining frequent patterns without candidate generation,” inProceedings of the 2000 ACM SIGMOD International Conference on Management of Data (SIGMOD ’00), 2000, pp. 1–12
2000
-
[36]
M. A. Nielsen and I. L. Chuang,Quantum Computation and Quantum Information, 10th ed. Cambridge, UK: Cambridge University Press, 2010
2010
-
[37]
Dbv-miner: A dynamic bit-vector approach for fast mining frequent closed itemsets,
B. V o, T.-P. Hong, and B. Le, “Dbv-miner: A dynamic bit-vector approach for fast mining frequent closed itemsets,”Expert Systems with Applications, vol. 39, no. 8, pp. 7196–7206, 2012
2012
-
[38]
Discovering frequent closed itemsets for association rules,
N. Pasquier, Y . Bastide, R. Taouil, and L. Lakhal, “Discovering frequent closed itemsets for association rules,” inDatabase Theory—ICDT’99: 7th International Conference Jerusalem, Israel, January 10–12, 1999 Proceedings 7. Springer, 1999, pp. 398–416
1999
-
[39]
Charm: An efficient algorithm for closed itemset mining,
M. J. Zaki and C.-J. Hsiao, “Charm: An efficient algorithm for closed itemset mining,” inProceedings of the 2002 SIAM International Con- ference on Data Mining. SIAM, 2002, pp. 457–473
2002
-
[40]
Fast and memory efficient mining of frequent closed itemsets,
C. Lucchese, S. Orlando, and R. Perego, “Fast and memory efficient mining of frequent closed itemsets,”IEEE Transactions on Knowledge and Data Engineering, vol. 18, no. 1, pp. 21–36, 2005
2005
-
[41]
Lcm ver. 2: Efficient mining algorithms for frequent/closed/maximal itemsets,
T. Uno, M. Kiyomi, H. Arimuraet al., “Lcm ver. 2: Efficient mining algorithms for frequent/closed/maximal itemsets,” inProceedings of the IEEE ICDM Workshop on Frequent Itemset Mining Implementations (FIMI), 2004
2004
-
[42]
Fpmax: Mining maximal frequent patterns without candidate generation,
W. Chenet al., “Fpmax: Mining maximal frequent patterns without candidate generation,”IEEE Transactions on Knowledge and Data Engineering, vol. 14, no. 5, pp. 1002–1016, 2002
2002
-
[43]
Multi-objective optimization for high-dimensional maximal frequent itemset mining,
Y . Zhang, W. Yu, X. Ma, H. Ogura, and D. Ye, “Multi-objective optimization for high-dimensional maximal frequent itemset mining,” Applied Sciences, vol. 11, no. 19, p. 8971, 2021
2021
-
[44]
Right-hand side expanding algorithm for maximal frequent itemset mining,
Y . Zhang, W. Yu, Q. Zhu, X. Ma, and H. Ogura, “Right-hand side expanding algorithm for maximal frequent itemset mining,”Applied Sciences, vol. 11, no. 21, p. 10399, 2021
2021
-
[45]
Ubp-miner: An efficient bit based high utility itemset mining algorithm,
P. Wu, X. Niu, P. Fournier-Viger, C. Huang, and B. Wang, “Ubp-miner: An efficient bit based high utility itemset mining algorithm,”Knowledge- Based Systems, vol. 248, p. 108865, 2022
2022
-
[46]
Efficient top-k identical frequent itemsets mining without support threshold parameter from transactional datasets produced by iot-based smart shopping carts,
S. U. Rehman, N. Alnazzawi, J. Ashraf, J. Iqbal, and S. Khan, “Efficient top-k identical frequent itemsets mining without support threshold parameter from transactional datasets produced by iot-based smart shopping carts,”Sensors, vol. 22, no. 20, p. 8063, 2022
2022
-
[47]
Parallel FP- growth for query recommendation,
H. Li, Y . Wang, D. Zhang, M. Zhang, and E. Y . Chang, “Parallel FP- growth for query recommendation,” inProceedings of the 2008 ACM Conference on Recommender Systems (RecSys ’08), 2008, pp. 107–114
2008
-
[48]
Eafim: efficient apriori- based frequent itemset mining algorithm on spark for big transactional data,
S. Raj, D. Ramesh, M. Sreenu, and K. K. Sethi, “Eafim: efficient apriori- based frequent itemset mining algorithm on spark for big transactional data,”Knowledge and Information Systems, vol. 62, pp. 3565–3583, 2020
2020
-
[49]
Gpu-based efficient parallel heuristic algorithm for high-utility itemset mining in large transaction datasets,
W. Fang, H. Jiang, H. Lu, J. Sun, X. Wu, and J. C.-W. Lin, “Gpu-based efficient parallel heuristic algorithm for high-utility itemset mining in large transaction datasets,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 2, pp. 652–667, 2024
2024
-
[50]
Quantum query algorithms and lower bounds,
A. Ambainis, “Quantum query algorithms and lower bounds,” in Classical and New Paradigms of Computation and their Complexity Hierarchies. Springer, 2004, pp. 15–32
2004
-
[51]
Complexity measures and decision tree complexity: a survey,
H. Buhrman and R. De Wolf, “Complexity measures and decision tree complexity: a survey,”Theoretical Computer Science, vol. 288, no. 1, pp. 21–43, 2002
2002
-
[52]
Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets,
A. K.et al., “Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets,”Nature, vol. 549, pp. 242–246, 2017
2017
-
[53]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, “A quantum approximate optimization algorithm,” arXiv:1411.4028, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[54]
Quantum computing for finance: Overview and prospects,
R. Or ´us, S. Mugel, and E. Lizaso, “Quantum computing for finance: Overview and prospects,”Reviews in Physics, vol. 4, p. 100028, 2019
2019
-
[55]
Quantum algorithm for association rules mining,
C.-H. Yuet al., “Quantum algorithm for association rules mining,” Physical Review A, vol. 94, no. 4, p. 042311, 2016
2016
-
[56]
Experimental implementation of quantum algorithm for association rules mining,
C.-H. Yu, “Experimental implementation of quantum algorithm for association rules mining,”IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 12, no. 3, pp. 676–684, 2022
2022
-
[57]
Quantum Computing in the NISQ era and beyond
J. Preskill, “Quantum computing in the NISQ era and beyond,” Quantum, vol. 2, p. 79, Aug. 2018. [Online]. Available: https: //doi.org/10.22331/q-2018-08-06-79
work page internal anchor Pith review doi:10.22331/q-2018-08-06-79 2018
-
[58]
Ciclad: A fast and memory- efficient closed itemset miner for streams,
T. Martin, G. Francoeur, and P. Valtchev, “Ciclad: A fast and memory- efficient closed itemset miner for streams,” inProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’20), 2020, pp. 1810–1818
2020
-
[59]
Tight bounds on quan- tum searching,
M. Boyer, G. Brassard, P. Høyer, and A. Tapp, “Tight bounds on quan- tum searching,”Fortschritte der Physik: Progress of Physics, vol. 46, no. 4-5, pp. 493–505, 1998
1998
-
[60]
UCI machine learning repository,
D. Dua and C. Graff, “UCI machine learning repository,” https://archiv e.ics.uci.edu/, 2017
2017
-
[61]
SPMF: A Java open-source pattern mining library,
P. Fournier-Viger, A. Gomariz, T. Gueniche, A. Soltani, C.-W. Wu, and V . S. Tseng, “SPMF: A Java open-source pattern mining library,”Journal of Machine Learning Research, vol. 15, pp. 3389–3393, 2014, datasets: https://www.philippe-fournier-viger.com/spmf/index.php?link=datasets. php
2014
-
[62]
Comparing the Overhead of Topological and Concatenated Quantum Error Correction
M. Suchara, A. Faruque, C. Lai, G. Paz, F. T. Chong, and J. Kubiatowicz, “Comparing the overhead of topological and concatenated quantum error correction,”arXiv preprint arXiv:1312.2316, 2013. [Online]. Available: https://arxiv.org/abs/1312.2316
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[63]
A game of surface codes: Large-scale quantum computing with lattice surgery,
D. Litinski, “A game of surface codes: Large-scale quantum computing with lattice surgery,”Quantum, vol. 3, p. 128, 2019
2019
-
[64]
How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits,
C. Gidney and M. Eker ˚a, “How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits,”Quantum, vol. 5, p. 433, 2021
2048
-
[65]
Assessing the requirements for industry relevant quantum computation,
A. M. Krol, M. Erdmann, E. Munro, A. Luckow, and Z. Al-Ars, “Assessing the requirements for industry relevant quantum computation,”
-
[66]
Available: https://arxiv.org/abs/2408.02587
[Online]. Available: https://arxiv.org/abs/2408.02587
-
[67]
Qiskit: An open-source framework for quantum computing,
Qiskit Community, “Qiskit: An open-source framework for quantum computing,” 2017. [Online]. Available: https://github.com/Qiskit/qiskit APPENDIXA PSEUDOCODE ANDNOTATIONS Procedures 3 and 4 detail the pseudocode of Quantum Preprocessing and Representation (QPR) and Quantum Itemset Listing (QIL), respectively. 17 Table VI summarizes the nota- tions used in ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.