Reluctant Transfer Learning in Penalized Regressions for Individualized Treatment Rules under Effect Heterogeneity
Pith reviewed 2026-05-17 23:11 UTC · model grok-4.3
The pith
Reluctant transfer learning updates individualized treatment rules under effect shifts by selective component transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the Reluctant Transfer Learning framework allows efficient adaptation of ITR estimation models by selectively transferring essential model components like regression coefficients from source data to target data without individual-level access, using reluctant modeling to add adjustments only when they improve target performance, supporting multi-armed treatments with variable selection, and deriving a regret bound for the difference in value between the optimal and estimated ITR.
What carries the argument
The Reluctant Transfer Learning (RTL) framework based on penalized regressions that selectively incorporates transfers and adjustments according to target performance gains.
If this is right
- ITR models can be efficiently updated for datasets with shifted treatment-covariate relationships.
- Model complexity is controlled by reluctant incorporation of adjustments.
- Variable selection enhances interpretability while handling multi-armed treatments.
- A regret bound is established for the suboptimality of the estimated ITR.
- Superior performance is shown in simulations and BestAIR trial data.
Where Pith is reading between the lines
- Such methods may enable better use of historical clinical data without compromising privacy.
- Applications could extend to dynamic treatment regimes in ongoing patient monitoring.
- Further work might explore robustness when performance improvement detection is noisy.
Load-bearing premise
Performance improvements from model adjustments can be reliably identified on the target dataset without overfitting or bias in multi-armed treatment scenarios.
What would settle it
A simulation or real-world dataset where the RTL-estimated ITR shows no improvement or higher regret compared to retraining from scratch or no transfer under effect heterogeneity would challenge the framework's benefits.
Figures
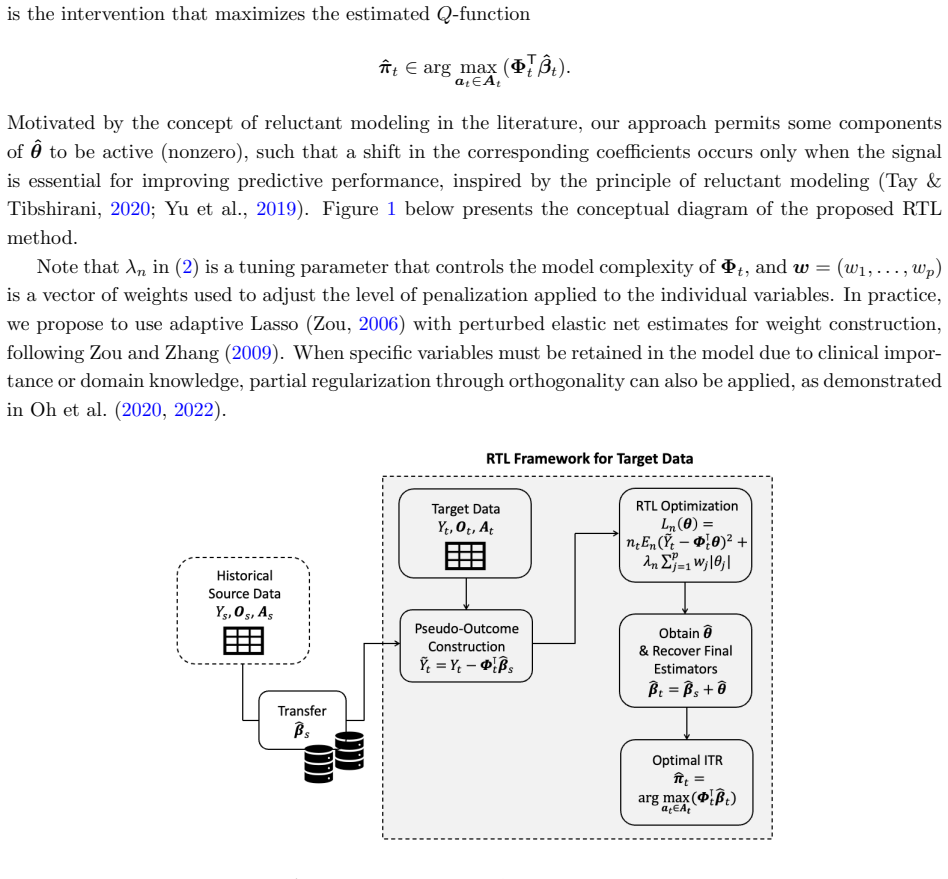
read the original abstract
Estimating individualized treatment rules (ITRs) is fundamental to precision medicine, where the goal is to tailor treatment decisions to individual patient characteristics. While numerous methods have been developed for ITR estimation, there is limited research on model updating that accounts for shifted treatment-covariate relationships in the ITR setting. In practice, models trained on source data must be updated for new (target) datasets that exhibit shifts in treatment effects. To address this challenge, we propose a Reluctant Transfer Learning (RTL) framework that enables efficient model adaptation by selectively transferring essential model components (e.g., regression coefficients) from source to target data, without requiring access to individual-level source data. Leveraging the principle of reluctant modeling, the RTL approach incorporates model adjustments only when they improve performance on the target dataset, thereby controlling complexity and enhancing generalizability. Our method supports multi-armed treatment settings, performs variable selection for interpretability, and provides a regret bound for the difference in value of the optimal ITR and that of the estimated ITR. Through simulation studies and an application to a real data example from the Best Apnea Interventions for Research (BestAIR) trial, we demonstrate that RTL outperforms existing alternatives. The proposed framework offers an efficient, practically feasible approach to adaptive treatment decision-making under evolving treatment effect conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Reluctant Transfer Learning (RTL) framework for estimating individualized treatment rules (ITRs) under effect heterogeneity. It selectively transfers essential model components such as regression coefficients from source to target data only when they improve target-domain performance, supports multi-armed treatments and variable selection, derives a regret bound on the value difference between the optimal ITR and the estimated ITR, and reports outperformance versus alternatives in simulations and the BestAIR trial.
Significance. If the selective transfer rule and associated regret bound can be shown to control post-selection bias, the approach would provide a practical, data-efficient method for updating ITRs when source data cannot be shared and treatment-covariate relationships shift, filling a gap between standard penalized regression ITR estimators and full transfer-learning procedures.
major comments (2)
- [regret bound derivation] Regret bound (abstract and the section deriving the bound): the bound is stated for the difference in value between the optimal ITR and the estimated ITR, yet the RTL procedure selects which source components to transfer by comparing value estimates on the same finite target sample; the derivation appears to treat the selected model as fixed rather than data-dependent, so any optimism in the gain-detection step propagates into the bound and weakens the guarantee for the final estimator.
- [RTL procedure for multi-armed settings] Multi-armed ITR value comparison (section describing the reluctant modeling step): when deciding which regression coefficients to transfer, the method compares estimated value functions across candidate transfer sets on the identical target observations; this data-dependent selection introduces post-selection bias that is not addressed in the reported simulation or real-data comparisons, and it is load-bearing for the claim that RTL outperforms baselines without overfitting.
minor comments (2)
- [abstract] Abstract: the statement that RTL 'outperforms existing alternatives' should name the specific competing methods (e.g., standard Q-learning, OWL, or other transfer approaches) so readers can assess the scope of the improvement.
- [methodology] Notation: the penalty parameters in the penalized regressions are listed as free parameters; clarify whether they are chosen by cross-validation on the target data alone or jointly with the transfer decision.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript regarding the Reluctant Transfer Learning framework for individualized treatment rules. We provide point-by-point responses to the major comments below, indicating the revisions we plan to make to address the concerns about post-selection bias and the regret bound.
read point-by-point responses
-
Referee: Regret bound (abstract and the section deriving the bound): the bound is stated for the difference in value between the optimal ITR and the estimated ITR, yet the RTL procedure selects which source components to transfer by comparing value estimates on the same finite target sample; the derivation appears to treat the selected model as fixed rather than data-dependent, so any optimism in the gain-detection step propagates into the bound and weakens the guarantee for the final estimator.
Authors: We appreciate the referee highlighting this subtlety in the regret bound derivation. The current bound is presented for the estimator obtained after the reluctant selection process. While the derivation conditions on the selected components, we recognize that explicitly accounting for the data-dependent selection could strengthen the result. In the revision, we will update the theoretical section to include a more detailed discussion of the selection mechanism and note that the bound applies to the final selected model, with the reluctant principle helping to limit excessive optimism by only transferring when value improvement is detected on the target data. revision: partial
-
Referee: Multi-armed ITR value comparison (section describing the reluctant modeling step): when deciding which regression coefficients to transfer, the method compares estimated value functions across candidate transfer sets on the identical target observations; this data-dependent selection introduces post-selection bias that is not addressed in the reported simulation or real-data comparisons, and it is load-bearing for the claim that RTL outperforms baselines without overfitting.
Authors: The referee is correct that using the same target observations for both selection and evaluation can introduce post-selection bias. Our simulation studies and the BestAIR application demonstrate superior performance of RTL, but to more rigorously address this, we will revise the manuscript to incorporate additional experiments that use separate validation sets for the transfer selection step. This will help confirm that the outperformance is not due to overfitting and provide a clearer assessment of the method's robustness in multi-armed settings. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained
full rationale
The paper's central contribution is the RTL procedure for selective transfer of regression components in multi-armed ITR estimation, combined with a theoretical regret bound on the value difference between the optimal and estimated ITR. This bound is derived from the penalized regression framework and the reluctant modeling principle rather than reducing to a data-dependent fit by construction. No equations or steps are shown to equate a 'prediction' directly to its own inputs, and no self-citation chain or imported uniqueness theorem is invoked to justify the core method. The approach is supported by simulation studies and a real-data application (BestAIR trial), making the derivation independent of the specific fitted quantities on the target sample. The selective transfer rule, while data-dependent, does not render the regret bound circular under the enumerated patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- penalty parameters in regressions
axioms (2)
- domain assumption Reluctant modeling principle: adjustments incorporated only when they improve target performance
- domain assumption Treatment-covariate relationships exhibit shifts between source and target
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a Reluctant Transfer Learning (RTL) framework that enables efficient model adaptation by selectively transferring essential model components (e.g., regression coefficients) from source to target data... and provides a regret bound for the difference in value of the optimal ITR and that of the estimated ITR.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Motivated by the concept of reluctant modeling... our approach permits some components of ˆθ to be active (nonzero), such that a shift in the corresponding coefficients occurs only when the signal is essential for improving predictive performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chu, J., Lu, W., & Yang, S. (2023). Targeted optimal treatment regime learning using summary statistics. Biometrika,110(4), 913–931. Dahabreh, I. J., Petito, L. C., Robertson, S. E., Hern´ an, M. A., & Steingrimsson, J. A. (2020). Toward causally interpretable meta-analysis: Transporting inferences from multiple randomized trials to a new target populatio...
work page 2023
-
[2]
Mo, W., Qi, Z., & Liu, Y. (2021). Learning optimal distributionally robust individualized treatment rules. Journal of the American Statistical Association,116(534), 659–674. Murphy, S. A. (2003). Optimal dynamic treatment regimes.Journal of the Royal Statistical Society Series B: Statistical Methodology,65(2), 331–355. Murphy, S. A. (2005). A generalizati...
work page 2021
-
[3]
1√ 2p−|S| Y s∈S ePms(Xs) fs(Xs) · 1√ 2p−|T| Y t∈T ePnt(Xt) ft(Xt) # (70) ∝E
Robertson, S. E., Steingrimsson, J. A., & Dahabreh, I. J. (2023). Regression-based estimation of heteroge- neous treatment effects when extending inferences from a randomized trial to a target population. European journal of epidemiology,38(2), 123–133. Robins, J. M. (2004). Optimal structural nested models for optimal sequential decisions.Proceedings of ...
-
[4]
Zou, H. (2006). The adaptive lasso and its oracle properties.Journal of the American statistical association, 101(476), 1418–1429. 13 Zou, H., & Zhang, H. H. (2009). On the adaptive elastic-net with a diverging number of parameters.Annals of statistics,37(4),
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.