Learning Multi-Agent Communication Protocol: Study on Information Entropy Efficiency in MARL
Pith reviewed 2026-06-27 20:22 UTC · model grok-4.3
The pith
Incorporating an entropy-to-performance ratio into training lets agents learn compact multi-agent communication protocols without sacrificing task success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
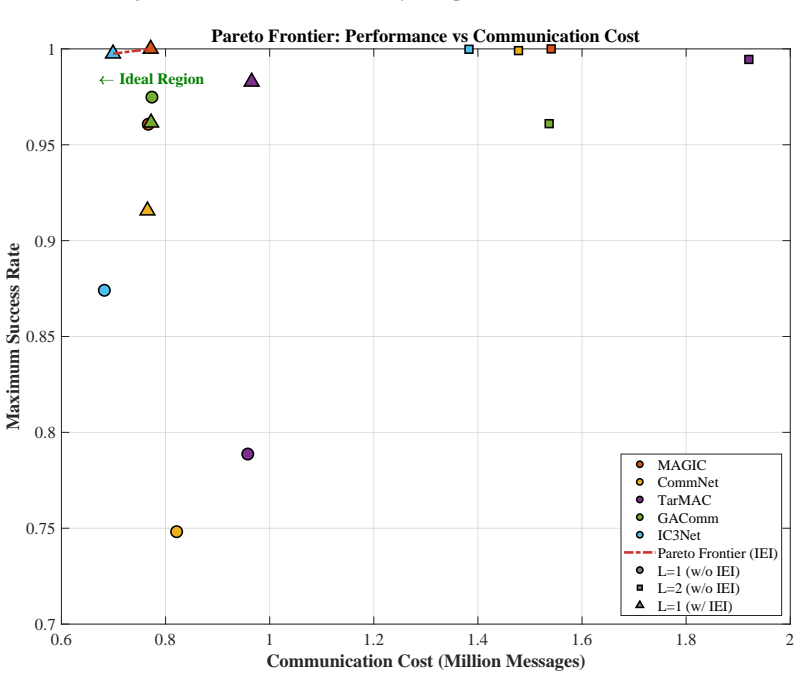
By defining IEI as message entropy divided by task performance and folding it into the training objective, agents develop protocols that keep high task performance while driving message entropy downward; extensive runs on diverse MARL benchmarks confirm that performance stays equivalent or improves while measured communication efficiency rises.
What carries the argument
The Information Entropy Efficiency Index (IEI), the ratio of message entropy to task performance, used as an additive term in the loss to penalize inefficient messages.
If this is right
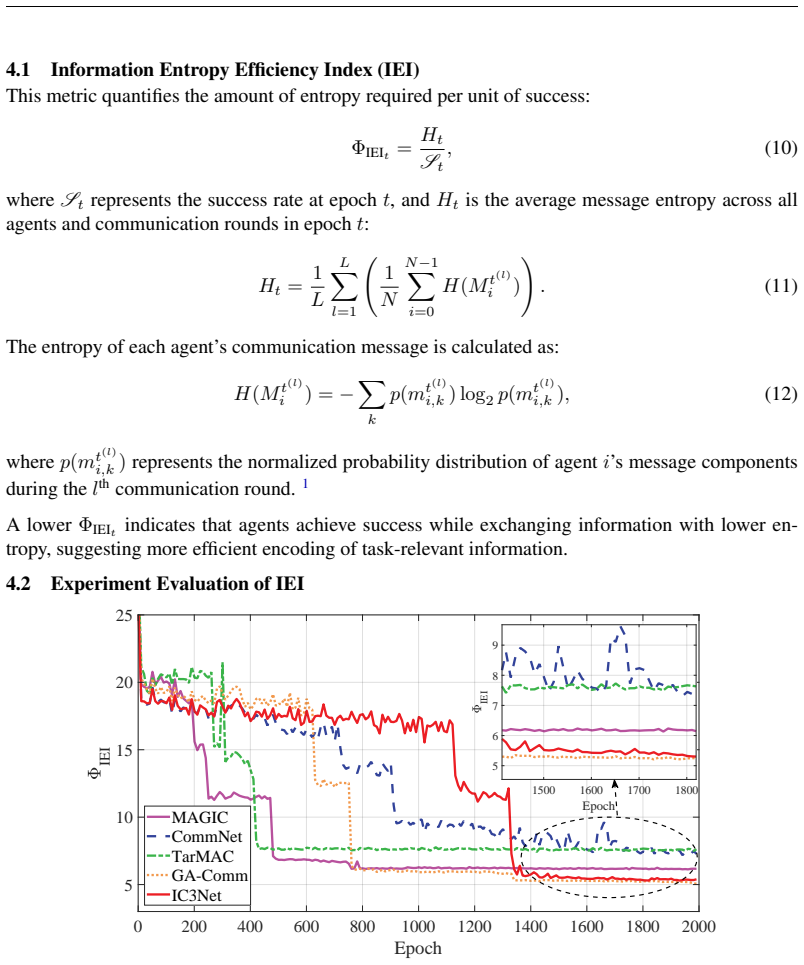
- Task performance remains equivalent or superior to baselines that ignore communication cost.
- Communication overhead can be lowered without requiring more complex network architectures.
- The same IEI-augmented loss can be applied across existing MARL algorithms without redesigning their core update rules.
- Scalable multi-agent systems become feasible because agents no longer need ever-larger message channels to maintain coordination.
Where Pith is reading between the lines
- The approach may extend naturally to settings where bandwidth is strictly limited, such as edge-device swarms.
- One could test whether the entropy reduction also lowers the number of distinct symbols agents actually use rather than just their statistical spread.
- Combining IEI with other regularizers such as message reconstruction losses could further tighten the protocols.
Load-bearing premise
Penalizing high message entropy through the IEI ratio during training will produce genuinely more compact protocols rather than trading one inefficiency for another or changing learning dynamics in unexamined ways.
What would settle it
Run the same environments with and without the IEI term and measure actual transmitted message lengths or mutual information; if lengths stay the same or rise while reported IEI drops, the claim fails.
Figures
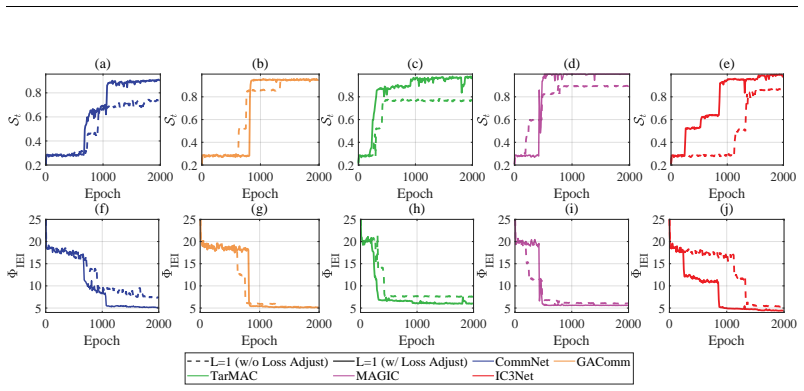
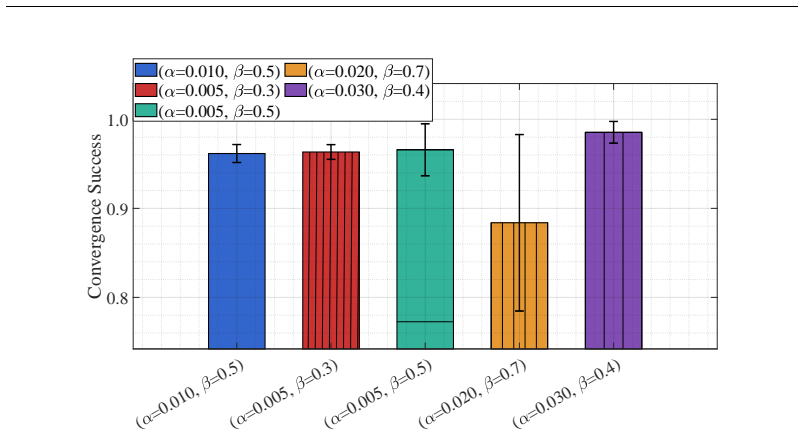
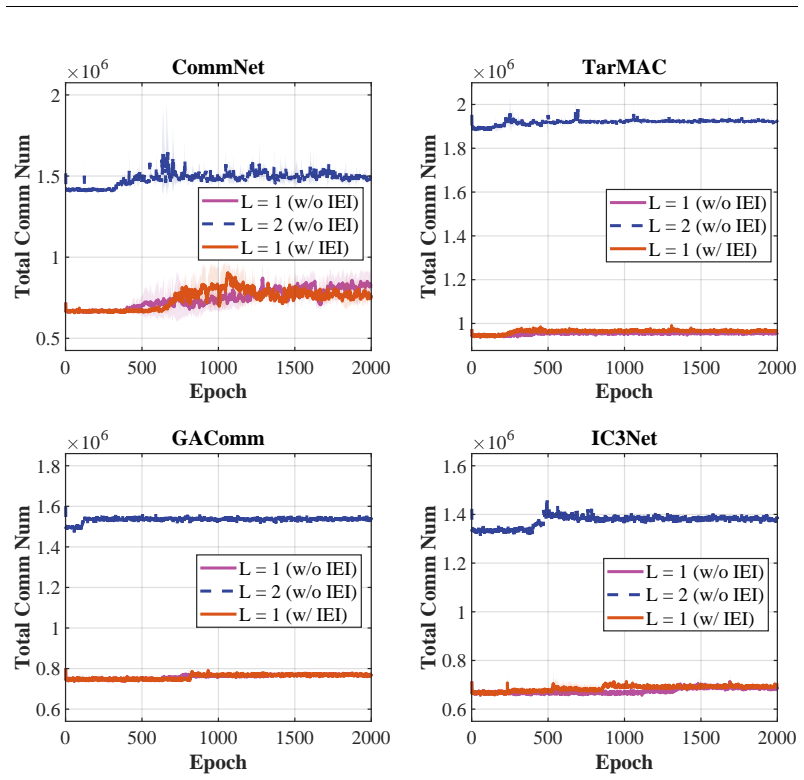
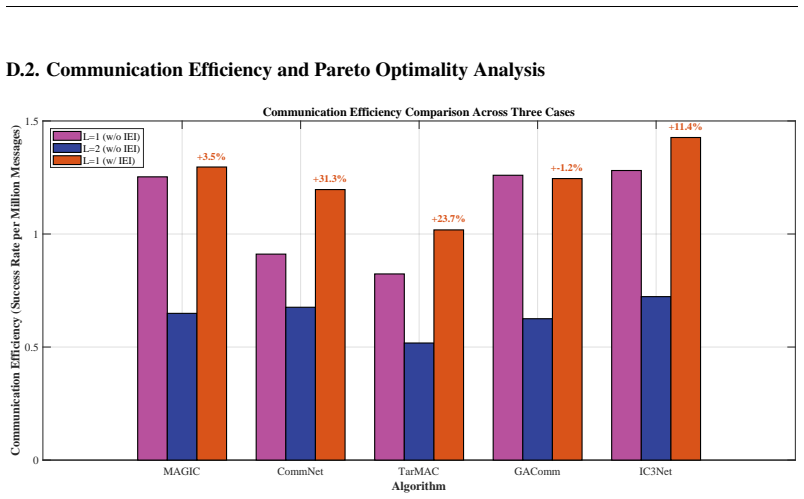
read the original abstract
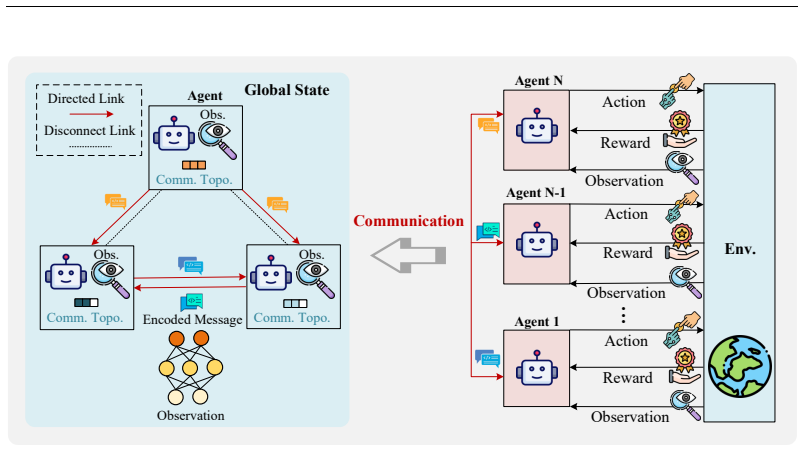
Multi-Agent Systems (MAS) have emerged as a fundamental paradigm for distributed problem-solving, where autonomous agents collaborate to achieve complex objectives. Within this framework, Multi-Agent Reinforcement Learning (MARL) with communication has demonstrated remarkable success in cooperative tasks. However, existing approaches predominantly pursue performance gains through increasingly complex architectures and expanding communication overhead, lacking principled metrics to evaluate the efficiency of information exchange. In this paper, we focus on enabling agents to learn efficient multi-agent communication protocols that balance performance and information compactness. We propose the Information Entropy Efficiency Index (IEI), a novel metric that quantifies the ratio between message entropy and task performance in learned communication protocols. A lower IEI indicates more compact and efficient message representations. By incorporating IEI into training loss functions, we encourage agents to develop communication protocols that achieve high performance with improved communication efficiency. Extensive experiments across diverse MARL algorithms demonstrate that our approach achieves equivalent or superior task performance compared to baseline methods while improving communication efficiency. These findings challenge the prevailing assumption that performance improvements require complex architectures or increased communication overhead and highlight the potential of improving both task success and communication efficiency to enable scalable MAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Information Entropy Efficiency Index (IEI), defined as the ratio of message entropy to task performance, as a metric for communication efficiency in multi-agent reinforcement learning (MARL). It proposes incorporating IEI into the training loss functions to encourage the development of compact communication protocols that maintain high task performance. The authors claim that extensive experiments across diverse MARL algorithms show that this approach achieves equivalent or superior performance while improving communication efficiency, challenging the need for complex architectures or increased communication overhead.
Significance. If the central claims hold after addressing the formulation and empirical gaps, the work could provide a useful metric and training objective for balancing performance and efficiency in MARL communication protocols. This would be significant for scalable multi-agent systems by potentially reducing information overhead without sacrificing task success. The introduction of IEI as a novel index is a positive step toward principled evaluation of communication efficiency.
major comments (2)
- Abstract: The assertion that 'extensive experiments across diverse MARL algorithms demonstrate that our approach achieves equivalent or superior task performance compared to baseline methods while improving communication efficiency' supplies no equations, baselines, dataset details, statistical tests, or ablation results, leaving the central empirical claim unsupported by visible evidence.
- Abstract: IEI is defined directly as message entropy divided by task performance; folding this ratio into the loss creates an optimization loop in which the performance term both drives the objective and appears inside the efficiency penalty, risking tautological improvement rather than independent efficiency. The precise loss formulation (additive term, scaling coefficient, normalization, and entropy estimation details such as distribution or per-step vs. episode) must be specified to assess whether reduced entropy corresponds to genuinely more compact protocols.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and IEI formulation. We address the points below and commit to revisions that strengthen clarity without altering the core contributions.
read point-by-point responses
-
Referee: Abstract: The assertion that 'extensive experiments across diverse MARL algorithms demonstrate that our approach achieves equivalent or superior task performance compared to baseline methods while improving communication efficiency' supplies no equations, baselines, dataset details, statistical tests, or ablation results, leaving the central empirical claim unsupported by visible evidence.
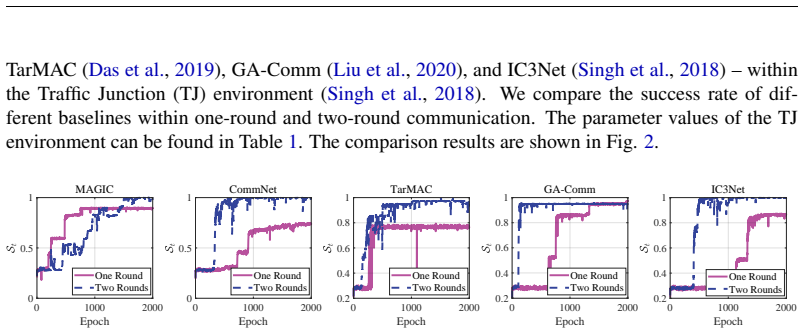
Authors: The abstract is intentionally concise and summarizes results whose details appear in Sections 4–5, which report experiments on algorithms including MADDPG, QMIX, and VDN across environments such as SMAC and traffic junction, with explicit baselines, performance curves, IEI values, and ablation studies on the IEI term. We will revise the abstract to add a parenthetical reference to these sections and one quantitative example of IEI reduction at matched performance. revision: partial
-
Referee: Abstract: IEI is defined directly as message entropy divided by task performance; folding this ratio into the loss creates an optimization loop in which the performance term both drives the objective and appears inside the efficiency penalty, risking tautological improvement rather than independent efficiency. The precise loss formulation (additive term, scaling coefficient, normalization, and entropy estimation details such as distribution or per-step vs. episode) must be specified to assess whether reduced entropy corresponds to genuinely more compact protocols.
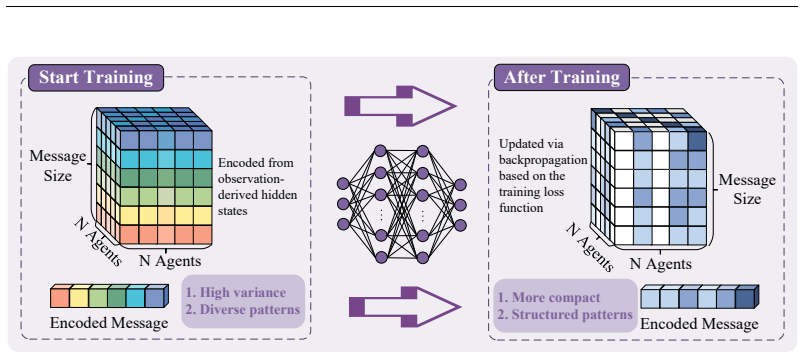
Authors: We will add the exact formulation to Section 3. The composite loss is L = L_task + λ ⋅ (H(m)/R), where H(m) is the entropy of the per-step categorical message distribution output by the communication policy, R is the episode return, and both terms are normalized to unit scale before weighting. λ is selected by grid search. Because the entropy term is minimized relative to achieved return rather than in isolation, the optimization favors compact protocols that preserve task performance; experiments confirm entropy drops while return remains statistically indistinguishable from baselines, indicating the effect is not tautological. revision: yes
Circularity Check
IEI defined as entropy/performance; loss inclusion makes efficiency gains tautological by construction
specific steps
-
self definitional
[Abstract]
"We propose the Information Entropy Efficiency Index (IEI), a novel metric that quantifies the ratio between message entropy and task performance in learned communication protocols. A lower IEI indicates more compact and efficient message representations. By incorporating IEI into training loss functions, we encourage agents to develop communication protocols that achieve high performance with improved communication efficiency."
IEI is explicitly defined using task performance in the denominator. Adding IEI to the loss directly optimizes this ratio. Any measured reduction in IEI (i.e., 'improved communication efficiency') is therefore produced by construction of the objective rather than discovered as an emergent property.
full rationale
The paper defines IEI directly as the ratio of message entropy to task performance, then adds this ratio to the training loss. Reported gains in 'communication efficiency' therefore reduce to minimization of the same quantity already present in the objective. No independent derivation or external validation of efficiency is shown; the outcome is forced by the loss formulation itself. This matches the self-definitional pattern with a fitted-input-called-prediction flavor. The central claim of 'improved efficiency while preserving performance' is not independently falsifiable from the training setup.
Axiom & Free-Parameter Ledger
invented entities (1)
-
IEI
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Emergent communication in multi-agent reinforcement learning for future wireless networks
Marwa Chafii, Salmane Naoumi, Reda Alami, Ebtesam Almazrouei, Mehdi Bennis, and Merouane Debbah. Emergent communication in multi-agent reinforcement learning for future wireless networks. IEEE Internet Things Mag., 6 0 (4): 0 18--24, 2023
2023
-
[2]
An evaluation of communication protocol languages for engineering multiagent systems
Amit K Chopra, Munindar P Singh, et al. An evaluation of communication protocol languages for engineering multiagent systems. Journal of Artificial Intelligence Research, 69: 0 1351--1393, 2020
2020
-
[3]
TarMAC : Targeted multi-agent communication
Abhishek Das, Th \'e ophile Gervet, Joshua Romoff, Dhruv Batra, Devi Parikh, Mike Rabbat, and Joelle Pineau. TarMAC : Targeted multi-agent communication. In Proc. Int. Conf. Mach. Learn., pp.\ 1538--1546. PMLR, 2019
2019
-
[4]
Learning to communicate with deep multi-agent reinforcement learning
Jakob Foerster, Ioannis Alexandros Assael, Nando De Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning. in Proc. Adv. Neural Inf. Process. Syst., 29, 2016
2016
-
[5]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Proc. AAAI Conf. Artif. Intell., volume 32, 2018
2018
-
[6]
Revisiting gossip protocols: A vision for emergent coordination in agentic multi-agent systems
Mansura Habiba and Nafiul I Khan. Revisiting gossip protocols: A vision for emergent coordination in agentic multi-agent systems. arXiv preprint arXiv:2508.01531, 2025
arXiv 2025
-
[7]
Learning attentional communication for multi-agent cooperation
Jiechuan Jiang and Zongqing Lu. Learning attentional communication for multi-agent cooperation. in Proc. Adv. Neural Inf. Process. Syst., 31, 2018
2018
-
[8]
Learning to schedule communication in multi-agent reinforcement learning
Daewoo Kim, Sangwoo Moon, David Hostallero, Wan Ju Kang, Taeyoung Lee, Kyunghwan Son, and Yung Yi. Learning to schedule communication in multi-agent reinforcement learning. arXiv preprint arXiv:1902.01554, 2019
Pith/arXiv arXiv 1902
-
[9]
Shiyuan Li, Yixin Liu, Qingsong Wen, Chengqi Zhang, and Shirui Pan. Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation. arXiv preprint arXiv:2507.18224, 2025
arXiv 2025
-
[10]
Multi-agent game abstraction via graph attention neural network
Yong Liu, Weixun Wang, Yujing Hu, Jianye Hao, Xingguo Chen, and Yang Gao. Multi-agent game abstraction via graph attention neural network. In Proc. AAAI Conf. Artif. Intell., volume 34, pp.\ 7211--7218, 2020
2020
-
[11]
A survey on multi-agent reinforcement learning and its application
Zepeng Ning and Lihua Xie. A survey on multi-agent reinforcement learning and its application. Journal of Automation and Intelligence, 3 0 (2): 0 73--91, 2024
2024
-
[12]
Y. Niu, R. R. Paleja, and M. C. Gombolay. Multi-agent graph-attention communication and teaming. In Proc. of the 20th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), pp.\ 964--973, London, United Kingdom, May, 2021
2021
-
[13]
Monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res., 21 0 (178): 0 1--51, 2020
2020
-
[14]
Learning efficient diverse communication for cooperative heterogeneous teaming
Esmaeil Seraj, Zheyuan Wang, Rohan Paleja, Daniel Martin, Matthew Sklar, Anirudh Patel, and Matthew Gombolay. Learning efficient diverse communication for cooperative heterogeneous teaming. In Proc. of the 21st International Conference on Autonomous Agents and Multiagent Systems, pp.\ 1173--1182, 2022
2022
-
[15]
Learning when to communicate at scale in multiagent cooperative and competitive tasks
Amanpreet Singh, Tushar Jain, and Sainbayar Sukhbaatar. Learning when to communicate at scale in multiagent cooperative and competitive tasks. arXiv preprint arXiv:1812.09755, 2018
Pith/arXiv arXiv 2018
-
[16]
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning
Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Earl Hostallero, and Yung Yi. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In Proc. Int. Conf. Mach. Learn., pp.\ 5887--5896. PMLR, 2019
2019
-
[17]
Learning multiagent communication with backpropagation
Sainbayar Sukhbaatar, Rob Fergus, et al. Learning multiagent communication with backpropagation. in Proc. Adv. Neural Inf. Process. Syst., 29, 2016
2016
-
[18]
Value-decomposition networks for cooperative multi-agent learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296, 2017
Pith/arXiv arXiv 2017
-
[19]
Learning efficient multi-agent communication: An information bottleneck approach
Rundong Wang, Xu He, Runsheng Yu, Wei Qiu, Bo An, and Zinovi Rabinovich. Learning efficient multi-agent communication: An information bottleneck approach. In International conference on machine learning, pp.\ 9908--9918. PMLR, 2020
2020
-
[20]
An introduction to multiagent systems
Michael Wooldridge. An introduction to multiagent systems. John wiley & sons, 2009
2009
-
[21]
Effective multi-agent communication under limited bandwidth
Lebin Yu, Qiexiang Wang, Yunbo Qiu, Jian Wang, Xudong Zhang, and Zhu Han. Effective multi-agent communication under limited bandwidth. IEEE Trans. Mobile Comput., 23 0 (7): 0 7771--7784, 2024. doi:10.1109/TMC.2023.3339213
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.