A Systematic Survey on Event Camera Representation Learning
Pith reviewed 2026-06-26 06:31 UTC · model grok-4.3
The pith
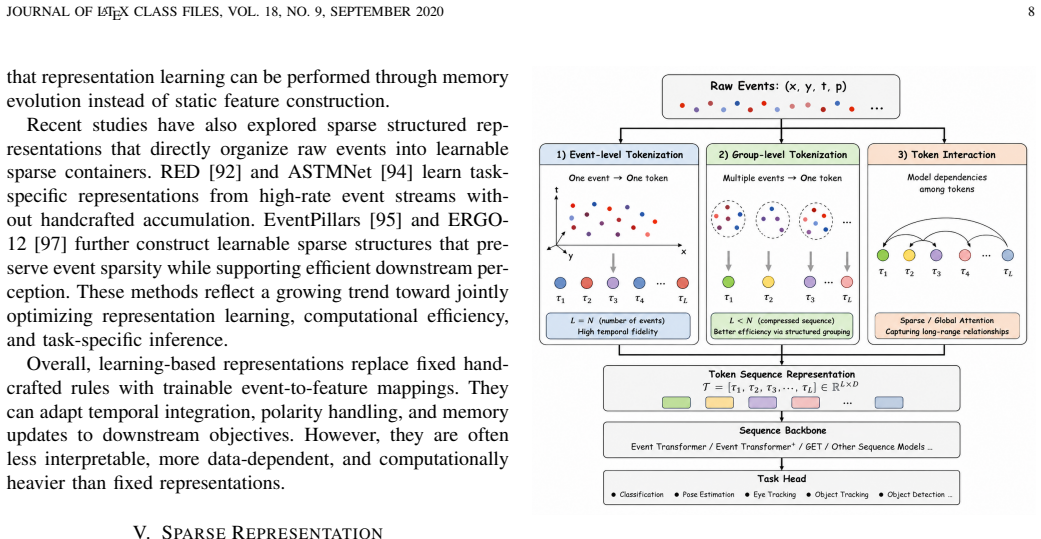
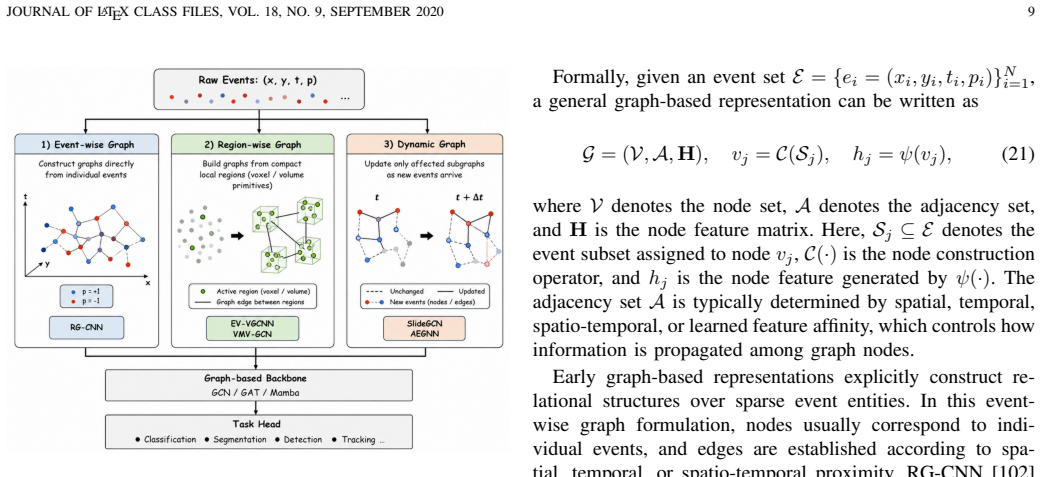
Event camera representation learning splits into dense grid conversions and sparse discrete structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
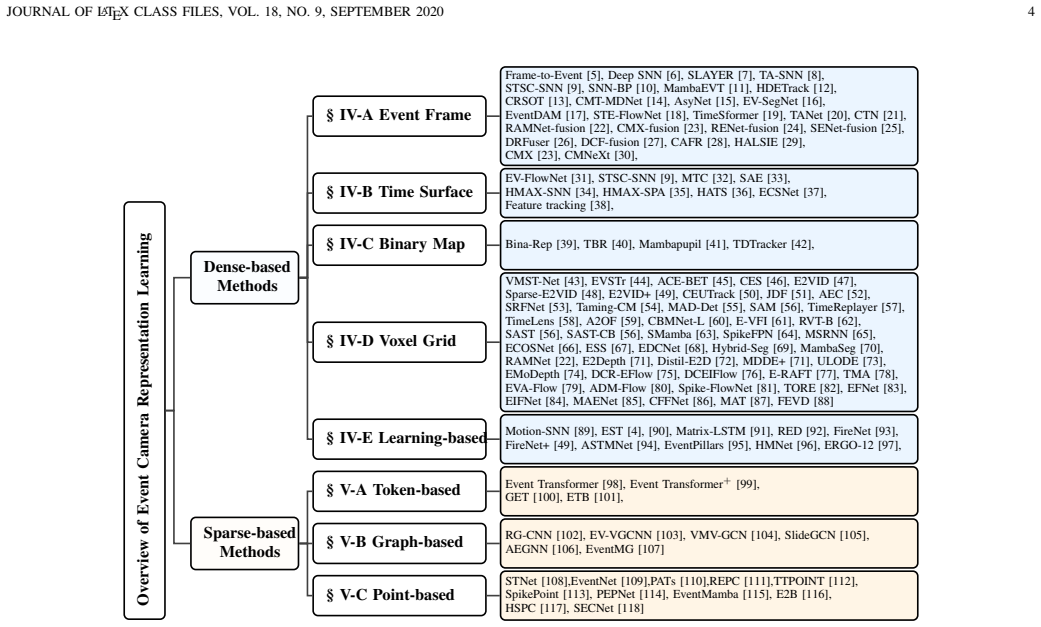
Existing methods for event camera representation learning can be organized into two main categories—dense-based representations that transform raw event streams into regular grid-like structures and sparse-based representations that retain events as discrete spatio-temporal structures—clarifying balances among structural regularity, temporal fidelity, sparsity preservation, and architectural compatibility.
What carries the argument
Two-category taxonomy separating dense-based grid transformations from sparse-based discrete event retention.
If this is right
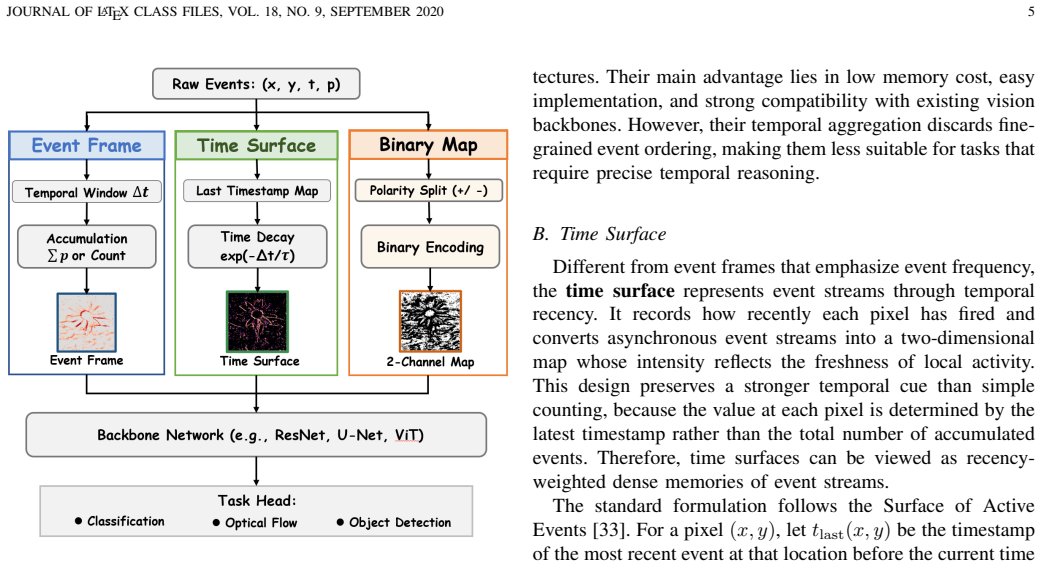
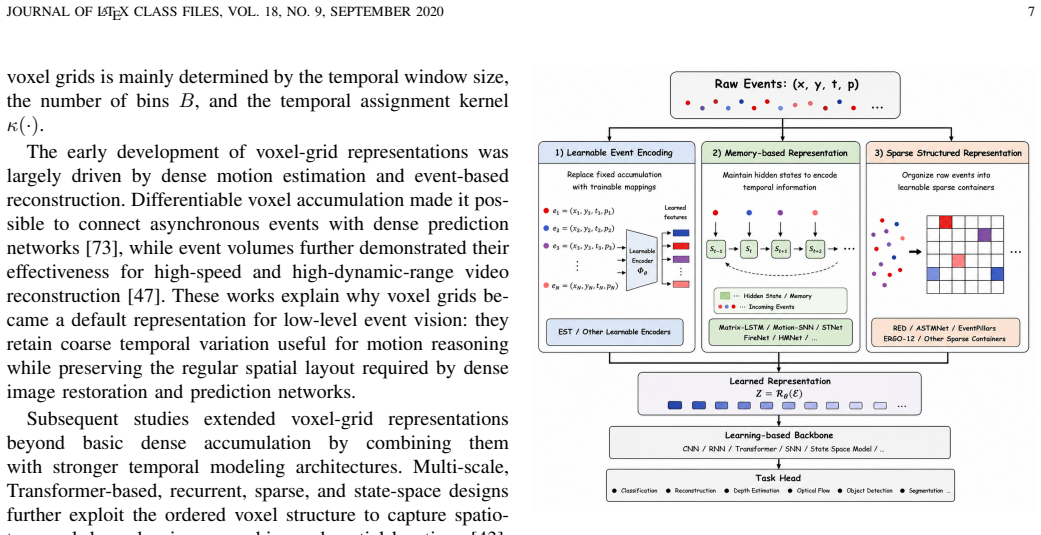
- Dense representations support direct use of existing RGB network backbones and multimodal fusion methods.
- Sparse representations maintain the original high temporal resolution and low data density of event streams.
- The split organizes implications for both high-level perception tasks and low-level vision tasks.
- Common benchmarks and evaluation protocols are collected for representative tasks.
- Open problems point toward future work on efficiency, scalability, and robustness.
Where Pith is reading between the lines
- Hybrid representations mixing grid and discrete elements could be designed to capture advantages from both sides.
- The same dense-versus-sparse distinction may apply to other asynchronous sensors in robotics or sensing.
- New methods that cross category boundaries would require updating or expanding the taxonomy.
- The open problems section could motivate benchmarks that measure computational cost alongside accuracy.
Load-bearing premise
All recent methods fit cleanly into either the dense or sparse category with no major omissions or overlaps.
What would settle it
A published event representation method that cannot be placed in either the dense-based or sparse-based category.
Figures



read the original abstract
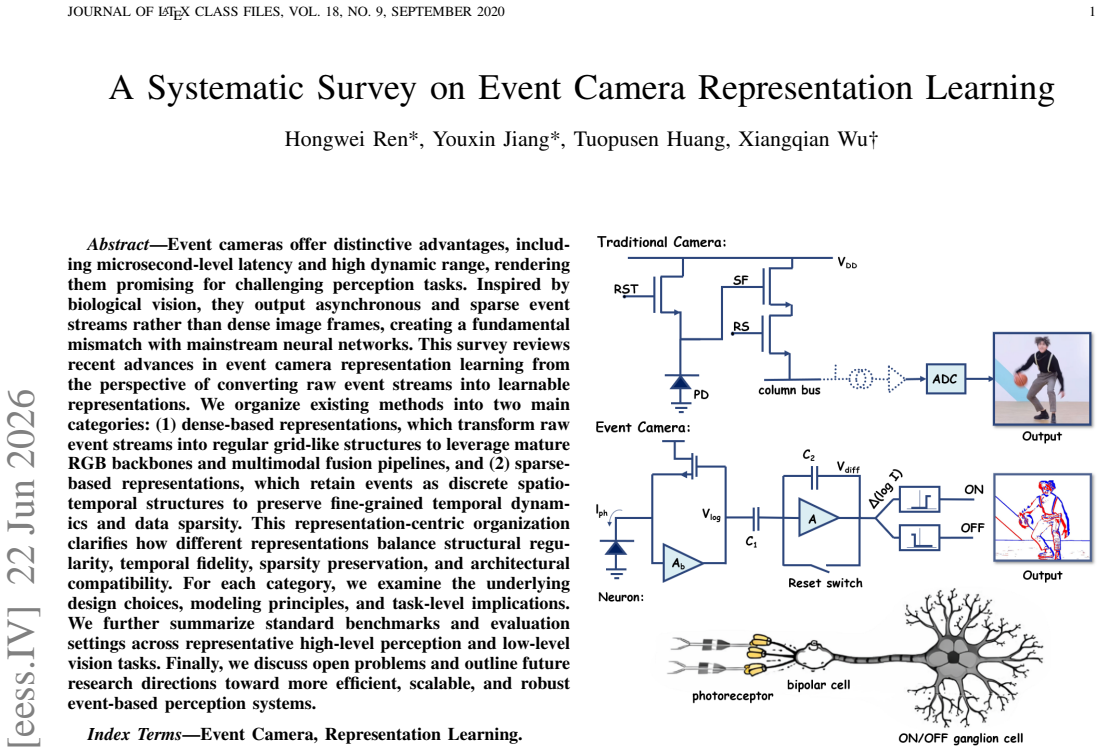
Event cameras offer distinctive advantages, including microsecond-level latency and high dynamic range, rendering them promising for challenging perception tasks. Inspired by biological vision, they output asynchronous and sparse event streams rather than dense image frames, creating a fundamental mismatch with mainstream neural networks. This survey reviews recent advances in event camera representation learning from the perspective of converting raw event streams into learnable representations. We organize existing methods into two main categories: (1) dense-based representations, which transform raw event streams into regular grid-like structures to leverage mature RGB backbones and multimodal fusion pipelines, and (2) sparse-based representations, which retain events as discrete spatio-temporal structures to preserve fine-grained temporal dynamics and data sparsity. This representation-centric organization clarifies how different representations balance structural regularity, temporal fidelity, sparsity preservation, and architectural compatibility. For each category, we examine the underlying design choices, modeling principles, and task-level implications.We further summarize standard benchmarks and evaluation settings across representative high-level perception and low-level vision tasks. Finally, we discuss open problems and outline future research directions toward more efficient, scalable, and robust event-based perception systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey reviews advances in event camera representation learning, organizing methods into two categories—dense-based (converting event streams to regular grid-like structures for compatibility with RGB backbones) and sparse-based (retaining discrete spatio-temporal event structures)—while discussing design choices, task implications, benchmarks for high- and low-level vision tasks, and future directions.
Significance. If the taxonomy proves exhaustive and non-overlapping, the survey would provide a useful organizing framework that highlights trade-offs in structural regularity, temporal fidelity, sparsity, and architectural compatibility, potentially guiding efficient event-based perception research.
major comments (2)
- [Abstract] Abstract: The central claim that the two-category taxonomy (dense-based vs. sparse-based) comprehensively and non-overlappingly covers recent literature is load-bearing for the survey's clarifying value, yet the manuscript provides no explicit selection criteria, inclusion/exclusion rules, or mapping of all cited works to categories; this leaves open the possibility of hybrid methods or unclassified papers that would undermine the partition's utility.
- [Abstract] Abstract and taxonomy discussion sections: No analysis is given of boundary cases (e.g., methods that perform both a dense conversion step and retain explicit sparse structures), which directly affects whether the claimed organization clarifies balances among the four properties without circularity or omission.
minor comments (1)
- [Abstract] The abstract states that standard benchmarks are summarized, but without a dedicated table or section reference listing the exact datasets, tasks, and metrics used across the surveyed papers, readers cannot easily verify coverage.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The concerns regarding the taxonomy's documentation and boundary handling are valid, and we will revise the manuscript to address them directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the two-category taxonomy (dense-based vs. sparse-based) comprehensively and non-overlappingly covers recent literature is load-bearing for the survey's clarifying value, yet the manuscript provides no explicit selection criteria, inclusion/exclusion rules, or mapping of all cited works to categories; this leaves open the possibility of hybrid methods or unclassified papers that would undermine the partition's utility.
Authors: We agree that the current abstract and taxonomy sections lack explicit documentation of literature selection. In the revision we will add a dedicated 'Literature Review Methodology' subsection that specifies search databases and keywords, time range, inclusion/exclusion criteria, and the total number of papers screened versus retained. We will also include a supplementary table that maps every cited method to its assigned category, with a column noting any hybrid characteristics and the rationale for the final assignment. This will make the partition's scope and any edge cases transparent. revision: yes
-
Referee: [Abstract] Abstract and taxonomy discussion sections: No analysis is given of boundary cases (e.g., methods that perform both a dense conversion step and retain explicit sparse structures), which directly affects whether the claimed organization clarifies balances among the four properties without circularity or omission.
Authors: We will expand the taxonomy discussion section with a new paragraph on boundary cases. It will explicitly identify representative hybrid methods, describe the decision rule used to assign them (primary representation fed into the learning pipeline), and analyze how the four properties (structural regularity, temporal fidelity, sparsity preservation, architectural compatibility) are traded off in those cases. This addition will demonstrate that the taxonomy is applied consistently rather than circularly. revision: yes
Circularity Check
No circularity: literature survey with no derivations or load-bearing self-references
full rationale
This paper is a systematic survey that reviews and organizes existing event-camera representation methods into two categories (dense-based grid-like and sparse-based discrete). No equations, fitted parameters, predictions, or derivation chains appear in the provided text or abstract. The taxonomy is presented as an organizational lens drawn from the literature rather than derived from or reducing to any self-citation, ansatz, or input by construction. The central claim does not invoke uniqueness theorems or prior author work as load-bearing justification; it simply classifies published methods. This matches the default expectation for non-circular survey papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recent event camera innovations: A survey,
B. Chakravarthi, A. A. Verma, K. Daniilidis, C. Fermuller, and Y . Yang, “Recent event camera innovations: A survey,” inComputer Vision – ECCV 2024 Workshops, A. Del Bue, C. Canton, J. Pont-Tuset, and T. Tommasi, Eds. Cham: Springer Nature Switzerland, 2025, pp. 342–376
2024
-
[2]
G. Gallego, T. Delbruck, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. J. Davison, J. Conradt, K. Daniilidis, and D. Scaramuzza, “ Event-Based Vision: A Survey ,”IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 44, no. 01, pp. 154–180, Jan. 2022. [Online]. Available: https: //doi.ieeecomputersociety.org/10.1109/TPAMI.2...
-
[3]
A 128×128 120 db 15µs latency asynchronous temporal contrast vision sensor,
P. Lichtsteiner, C. Posch, and T. Delbruck, “A 128×128 120 db 15µs latency asynchronous temporal contrast vision sensor,”IEEE Journal of Solid-State Circuits, vol. 43, no. 2, pp. 566–576, 2008
2008
-
[4]
End-to- end learning of representations for asynchronous event-based data,
D. Gehrig, A. Loquercio, K. Derpanis, and D. Scaramuzza, “End-to- end learning of representations for asynchronous event-based data,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 5632–5642
2019
-
[5]
Mapping from frame- driven to frame-free event-driven vision systems by low-rate rate coding and coincidence processing–application to feedforward con- vnets,
J. A. P ´erez-Carrasco, B. Zhao, C. Serrano, B. Acha, T. Serrano- Gotarredona, S. Chen, and B. Linares-Barranco, “Mapping from frame- driven to frame-free event-driven vision systems by low-rate rate coding and coincidence processing–application to feedforward con- vnets,”IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 11, pp....
2013
-
[6]
A low power, fully event-based gesture recognition system,
A. Amir, B. Taba, D. Berg, T. Melano, J. McKinstry, C. Di Nolfo, T. Nayak, A. Andreopoulos, G. Garreau, M. Mendozaet al., “A low power, fully event-based gesture recognition system,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7243–7252
2017
-
[7]
Slayer: Spike layer error reassignment in time,
S. B. Shrestha and G. Orchard, “Slayer: Spike layer error reassignment in time,” inAdvances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[8]
Temporal-wise attention spiking neural networks for event streams classification,
M. Yao, H. Gao, G. Zhao, D. Wang, Y . Lin, Z. Yang, and G. Li, “Temporal-wise attention spiking neural networks for event streams classification,” inProceedings of the IEEE/CVF International Confer- ence on Computer Vision, 2021, pp. 10 221–10 230
2021
-
[9]
Stsc-snn: Spatio- temporal synaptic connection with temporal convolution and attention for spiking neural networks,
Q. Xu, Y . Li, J. Shen, J. K. Liu, H. Tang, and G. Pan, “Stsc-snn: Spatio- temporal synaptic connection with temporal convolution and attention for spiking neural networks,”Frontiers in Neuroscience, vol. 16, p. 1079357, 2023
2023
-
[10]
Training deep spiking neural networks using backpropagation,
J. H. Lee, T. Delbruck, and M. Pfeiffer, “Training deep spiking neural networks using backpropagation,”Frontiers in neuroscience, vol. 10, p. 508, 2016
2016
-
[11]
Mambaevt: Event stream based visual object tracking using state space model,
X. Wang, C. Wang, S. Wang, X. Wang, Z. Zhao, L. Zhu, and B. Jiang, “Mambaevt: Event stream based visual object tracking using state space model,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[12]
Event stream-based visual object tracking: Hdetrack v2 and a high-definition benchmark,
S. Wang, X. Wang, C. Wang, L. Jin, L. Zhu, B. Jiang, Y . Tian, and J. Tang, “Event stream-based visual object tracking: Hdetrack v2 and a high-definition benchmark,”arXiv preprint arXiv:2502.05574, 2025
arXiv 2025
-
[13]
Crsot: Cross-resolution object tracking using unaligned frame and event cameras,
Y . Zhu, X. Wang, C. Li, B. Jiang, L. Zhu, Z. Huang, Y . Tian, and J. Tang, “Crsot: Cross-resolution object tracking using unaligned frame and event cameras,”IEEE Transactions on Multimedia, 2025
2025
-
[14]
Visevent: Reliable object tracking via collaboration of frame and event flows,
X. Wang, J. Li, L. Zhu, Z. Zhang, Z. Chen, X. Li, Y . Wang, Y . Tian, and F. Wu, “Visevent: Reliable object tracking via collaboration of frame and event flows,”IEEE transactions on cybernetics, vol. 54, no. 3, pp. 1997–2010, 2023
1997
-
[15]
Event-based asynchronous sparse convolutional networks,
N. Messikommer, D. Gehrig, A. Loquercio, and D. Scaramuzza, “Event-based asynchronous sparse convolutional networks,” inEuro- pean Conference on Computer Vision, 2020
2020
-
[16]
EV-SegNet: Semantic segmentation for event-based cameras,
I. Alonso and A. C. Murillo, “EV-SegNet: Semantic segmentation for event-based cameras,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019
2019
-
[17]
Depth any event stream: Enhancing event-based monocular depth estimation via dense-to-sparse distillation,
J. Zhu, T. Pan, Z. Cao, Y . Liu, J. T. Kwok, and H. Xiong, “Depth any event stream: Enhancing event-based monocular depth estimation via dense-to-sparse distillation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5146–5155
2025
-
[18]
Spatio-temporal recurrent networks for event-based optical flow esti- mation,
Z. Ding, R. Zhao, J. Zhang, T. Gao, R. Xiong, Z. Yu, and T. Huang, “Spatio-temporal recurrent networks for event-based optical flow esti- mation,” inProceedings of the AAAI Conference on Artificial Intelli- gence, vol. 36, no. 1, 2022, pp. 525–533
2022
-
[19]
Is space-time attention all you need for video understanding?
G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” inIcml, vol. 2, no. 3, 2021, p. 4
2021
-
[20]
Tam: Temporal adaptive module for video recognition,
Z. Liu, L. Wang, W. Wu, C. Qian, and T. Lu, “Tam: Temporal adaptive module for video recognition,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 708–13 718
2021
-
[21]
Transformer-based domain adap- tation for event data classification,
J. Zhao, S. Zhang, and T. Huang, “Transformer-based domain adap- tation for event data classification,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 4673–4677
2022
-
[22]
Combining events and frames using recurrent asynchronous multimodal networks for monocular depth prediction,
D. Gehrig, M. R ¨uegg, M. Gehrig, J. Hidalgo-Carri ´o, and D. Scara- muzza, “Combining events and frames using recurrent asynchronous multimodal networks for monocular depth prediction,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2822–2829, 2021
2021
-
[23]
CMX: Cross-modal fusion for rgb-x semantic segmentation with transform- ers,
J. Zhang, H. Liu, K. Yang, X. Hu, R. Liu, and R. Stiefelhagen, “CMX: Cross-modal fusion for rgb-x semantic segmentation with transform- ers,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 12, pp. 14 679–14 694, 2023
2023
-
[24]
RGB-event fusion for moving object detection in autonomous driv- ing,
Z. Zhou, Z. Wu, R. Boutteau, F. Yang, C. Demonceaux, and D. Ginhac, “RGB-event fusion for moving object detection in autonomous driv- ing,” inProceedings of the IEEE International Conference on Robotics and Automation. IEEE, 2023
2023
-
[25]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132–7141
2018
-
[26]
Multimodal fusion for sensorimotor control in steering angle prediction,
F. Munir, S. Azam, K.-C. Yow, B.-G. Lee, and M. Jeon, “Multimodal fusion for sensorimotor control in steering angle prediction,”Engineer- ing Applications of Artificial Intelligence, vol. 126, p. 107087, 2023
2023
-
[27]
Calibrated RGB-D salient object detection,
W. Ji, J. Li, S. Yu, M. Zhang, Y . Piao, S. Yao, Q. Bi, K. Ma, Y . Zheng, H. Lu, and L. Cheng, “Calibrated RGB-D salient object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9471–9481
2021
-
[28]
Embracing events and frames with hierarchical feature refinement network for object detection,
H. Cao, Z. Zhang, Y . Xia, X. Li, J. Xia, G. Chen, and A. Knoll, “Embracing events and frames with hierarchical feature refinement network for object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 1–17
2024
-
[29]
HALSIE: Hybrid approach to learning segmentation by simultane- ously exploiting image and event modalities,
S. Das Biswas, A. Kosta, C. Liyanagedera, M. Apolinario, and K. Roy, “HALSIE: Hybrid approach to learning segmentation by simultane- ously exploiting image and event modalities,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 5964–5974
2024
-
[30]
De- livering arbitrary-modal semantic segmentation,
J. Zhang, H. Liu, K. Yang, X. Hu, R. Liu, and R. Stiefelhagen, “De- livering arbitrary-modal semantic segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1136–1147
2023
-
[31]
Ev-flownet: Self- supervised optical flow estimation for event-based cameras,
A. Z. Zhu, L. Yuan, K. Chaney, and K. Daniilidis, “Ev-flownet: Self- supervised optical flow estimation for event-based cameras,”arXiv preprint arXiv:1802.06898, 2018
Pith/arXiv arXiv 2018
-
[32]
Multi-cue event information fusion for pedestrian detection with neuromorphic vision sensors,
G. Chen, H. Cao, C. Ye, Z. Zhang, X. Liu, X. Mo, Z. Qu, J. Conradt, F. R ¨ohrbein, and A. Knoll, “Multi-cue event information fusion for pedestrian detection with neuromorphic vision sensors,”Frontiers in Neurorobotics, vol. 13, p. 10, 2019
2019
-
[33]
Event-based visual flow,
R. Benosman, C. Clercq, X. Lagorce, S.-H. Ieng, and C. Bartolozzi, “Event-based visual flow,”IEEE transactions on neural networks and learning systems, vol. 25, no. 2, pp. 407–417, 2013
2013
-
[34]
An event-driven categorization model for aer image sensors using multispike encoding and learning,
R. Xiao, H. Tang, Y . Ma, R. Yan, and G. Orchard, “An event-driven categorization model for aer image sensors using multispike encoding and learning,”IEEE Transactions on Neural Networks and Learning Systems, 2019
2019
-
[35]
Effective aer object classification using segmented probability-maximization learning in spiking neural networks,
Q. Liu, H. Ruan, D. Xing, H. Tang, and G. Pan, “Effective aer object classification using segmented probability-maximization learning in spiking neural networks,” inProceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 1308–1315
2020
-
[36]
Hats: Histograms of averaged time surfaces for robust event-based ob- ject classification,
A. Sironi, M. Brambilla, N. Bourdis, X. Lagorce, and R. Benosman, “Hats: Histograms of averaged time surfaces for robust event-based ob- ject classification,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1731–1740
2018
-
[37]
Ecsnet: Spatio- temporal feature learning for event camera,
Z. Chen, J. Wu, J. Hou, L. Li, W. Dong, and G. Shi, “Ecsnet: Spatio- temporal feature learning for event camera,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 2, pp. 701– 712, 2022
2022
-
[38]
Fast event-based corner detection,
E. Mueggler, C. Bartolozzi, and D. Scaramuzza, “Fast event-based corner detection,” 2017
2017
-
[39]
Bina-rep event frames: A simple and effective representation for event-based cameras,
S. Barchid, J. Mennesson, and C. Dj ´eraba, “Bina-rep event frames: A simple and effective representation for event-based cameras,” in2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 3998–4002
2022
-
[40]
Temporal binary representation for event-based action recognition,
S. U. Innocenti, F. Becattini, F. Pernici, and A. Del Bimbo, “Temporal binary representation for event-based action recognition,” in2020 25th JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 17 International Conference on Pattern Recognition (ICPR), 2021, pp. 10 426–10 432
2020
-
[41]
Mambapupil: Bidirectional selective recurrent model for event- based eye tracking,
Z. Wang, Z. Wan, H. Han, B. Liao, Y . Wu, W. Zhai, Y . Cao, and Z.-J. Zha, “Mambapupil: Bidirectional selective recurrent model for event- based eye tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5762–5770
2024
-
[42]
Exploring temporal dynamics in event-based eye tracker,
H. Huang, X. Lin, H. Ren, Y . Zhou, and B. Cheng, “Exploring temporal dynamics in event-based eye tracker,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5145–5154
2025
-
[43]
V oxel-based multi-scale transformer network for event stream processing,
D. Liu, T. Wang, and C. Sun, “V oxel-based multi-scale transformer network for event stream processing,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, pp. 2112–2124, 2023
2023
-
[44]
Event voxel set trans- former for spatiotemporal representation learning on event streams,
B. Xie, Y . Deng, Z. Shao, Q. Xu, and Y . Li, “Event voxel set trans- former for spatiotemporal representation learning on event streams,” IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[45]
Fast classification and action recognition with event-based imaging,
C. Liu, X. Qi, E. Y . Lam, and N. Wong, “Fast classification and action recognition with event-based imaging,”IEEE access, vol. 10, pp. 55 638–55 649, 2022
2022
-
[46]
Compressed event sensing (ces) volumes for event cameras,
S. Lin, Y . Ma, J. Chen, and B. Wen, “Compressed event sensing (ces) volumes for event cameras,”International Journal of Computer Vision, vol. 133, no. 1, pp. 435–455, 2025
2025
-
[47]
High speed and high dynamic range video with an event camera,
H. Rebecq, R. Ranftl, V . Koltun, and D. Scaramuzza, “High speed and high dynamic range video with an event camera,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 6, pp. 1964– 1980, 2019
1964
-
[48]
Sparse-e2vid: A sparse convolutional model for event-based video reconstruction trained with real event noise,
P. R. G. Cadena, Y . Qian, C. Wang, and M. Yang, “Sparse-e2vid: A sparse convolutional model for event-based video reconstruction trained with real event noise,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4150–4158
2023
-
[49]
Back to event basics: Self-supervised learning of image reconstruction for event cameras via photometric constancy,
F. Paredes-Valles and G. C. H. E. de Croon, “Back to event basics: Self-supervised learning of image reconstruction for event cameras via photometric constancy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3446–3455
2021
-
[50]
Revisiting color-event based tracking: A unified network, dataset, and metric,
C. Tang, X. Wang, J. Huang, B. Jiang, L. Zhu, S. Chen, J. Zhang, Y . Wang, and Y . Tian, “Revisiting color-event based tracking: A unified network, dataset, and metric,”Pattern Recognition, p. 112718, 2025
2025
-
[51]
Event-based vision enhanced: A joint detection framework in autonomous driving,
J. Li, S. Dong, Z. Yu, Y . Tian, and T. Huang, “Event-based vision enhanced: A joint detection framework in autonomous driving,” in Proceedings of the IEEE International Conference on Multimedia and Expo. IEEE, 2019
2019
-
[52]
Better and faster: Adaptive event conversion for event-based object detection,
Y . Peng, Y . Zhang, Z. Xiong, X. Sun, and F. Wu, “Better and faster: Adaptive event conversion for event-based object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 2, 2023, pp. 2056–2064
2023
-
[53]
Srfnet: Monocular depth estimation with fine-grained structure via spatial reliability-oriented fusion of frames and events,
T. Pan, Z. Cao, and L. Wang, “Srfnet: Monocular depth estimation with fine-grained structure via spatial reliability-oriented fusion of frames and events,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 10 695–10 702
2024
-
[54]
Secrets of event-based optical flow,
S. Shiba, Y . Aoki, and G. Gallego, “Secrets of event-based optical flow,” inEuropean Conference on Computer Vision, 2022, pp. 628–645
2022
-
[55]
Motion and appearance decoupling representation for event cameras,
N. Chen, B. Li, Y . Wang, X. Ying, L. Wang, C. Zhang, Y . Guo, M. Li, and W. An, “Motion and appearance decoupling representation for event cameras,”IEEE Transactions on Image Processing, vol. 34, pp. 5964–5977, 2025
2025
-
[56]
Y . Peng, H. Li, Y . Zhang, X. Sun, and F. Wu, “c,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 794–16 804
2024
-
[57]
Timereplayer: Unlocking the potential of event cameras for video interpolation,
W. He, K. You, Z. Qiao, X. Jia, Z. Zhang, W. Wang, H. Lu, Y . Wang, and J. Liao, “Timereplayer: Unlocking the potential of event cameras for video interpolation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 783–17 792
2022
-
[58]
Time lens: Event-based video frame interpolation,
S. Tulyakov, D. Gehrig, S. Georgoulis, J. Erbach, M. Gehrig, Y . Li, and D. Scaramuzza, “Time lens: Event-based video frame interpolation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 155–16 164
2021
-
[59]
Video interpolation by event-driven anisotropic adjustment of optical flow,
S. Wu, K. You, W. He, C. Yang, Y . Tian, Y . Wang, Z. Zhang, and J. Liao, “Video interpolation by event-driven anisotropic adjustment of optical flow,” inEuropean Conference on Computer Vision, 2022, pp. 267–283
2022
-
[60]
Event-based video frame interpolation with cross-modal asymmetric bidirectional motion fields,
T. Kim, Y . Chae, H.-K. Jang, and K.-J. Yoon, “Event-based video frame interpolation with cross-modal asymmetric bidirectional motion fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 032–18 042
2023
-
[61]
Video frame interpolation via direct synthesis with the event-based reference,
Y . Liu, Y . Deng, H. Chen, and Z. Yang, “Video frame interpolation via direct synthesis with the event-based reference,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 8477–8487
2024
-
[62]
Recurrent vision transformers for object detection with event cameras,
M. Gehrig and D. Scaramuzza, “Recurrent vision transformers for object detection with event cameras,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 884–13 893
2023
-
[63]
SMamba: Sparse mamba for event-based object detection,
N. Yang, Y . Wang, Z. Liu, M. Li, Y . An, and X. Zhao, “SMamba: Sparse mamba for event-based object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9229–9237
2025
-
[64]
Automotive object detection via learning sparse events by spiking neurons,
H. Zhang, Y . Li, L. Leng, K. Che, Q. Liu, Q. Guo, J. Liao, and R. Cheng, “Automotive object detection via learning sparse events by spiking neurons,” 2024
2024
-
[65]
A multi-scale recurrent framework for motion segmentation with event camera,
S. Zhang, L. Sun, and K. Wang, “A multi-scale recurrent framework for motion segmentation with event camera,”IEEE Access, vol. 11, pp. 80 105–80 114, 2023
2023
-
[66]
Continuous-time object segmentation using high temporal resolution event camera,
L. Zhu, X. Chen, L. Wang, X. Wang, Y . Tian, and H. Huang, “Continuous-time object segmentation using high temporal resolution event camera,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[67]
ESS: Learning event-based semantic segmentation from still images,
Z. Sun, N. Messikommer, D. Gehrig, and D. Scaramuzza, “ESS: Learning event-based semantic segmentation from still images,” in European Conference on Computer Vision. Springer, 2022, pp. 341– 357
2022
-
[68]
Exploring event-driven dynamic context for accident scene segmentation,
J. Zhang, X. Yang, and R. Stiefelhagen, “Exploring event-driven dynamic context for accident scene segmentation,”IEEE Transactions on Intelligent Transportation Systems, 2021
2021
-
[69]
Efficient event-based semantic segmentation via exploiting frame-event fusion: A hybrid neural net- work approach,
K. Li, Y . Zhao, G. Lyu, and Y . Deng, “Efficient event-based semantic segmentation via exploiting frame-event fusion: A hybrid neural net- work approach,” inProceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[70]
MambaSeg: Harnessing mamba for accurate and efficient image-event semantic segmentation,
F. Gu, Y . Li, X. Long, K. Ji, C. Chen, Q. Gu, and Z. Ni, “MambaSeg: Harnessing mamba for accurate and efficient image-event semantic segmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[71]
Learning monocular dense depth from events,
J. Hidalgo-Carri ´o, D. Gehrig, and D. Scaramuzza, “Learning monocular dense depth from events,” in2020 International Conference on 3D Vision (3DV). IEEE, 2020, pp. 534–542
2020
-
[72]
Distil-e2d: Distilling image-to-depth priors for event-based monocular depth estimation,
J. L. Lee and G. H. Lee, “Distil-e2d: Distilling image-to-depth priors for event-based monocular depth estimation,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[73]
Unsupervised event- based learning of optical flow, depth, and egomotion,
A. Z. Zhu, L. Yuan, K. Chaney, and K. Daniilidis, “Unsupervised event- based learning of optical flow, depth, and egomotion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 989–997
2019
-
[74]
Self- supervised event-based monocular depth estimation using cross-modal consistency,
J. Zhu, L. Liu, B. Jiang, F. Wen, H. Zhang, W. Li, and Y . Liu, “Self- supervised event-based monocular depth estimation using cross-modal consistency,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 7704–7710
2023
-
[75]
DCR-EFlow: Dynamic correlation recurrent architecture for optical flow estimation based on event cameras,
F. Sun, C. Su, B. Xiong, and Y . Wang, “DCR-EFlow: Dynamic correlation recurrent architecture for optical flow estimation based on event cameras,”Intelligent Computing, vol. 4, p. 0243, 2025
2025
-
[76]
Learning dense and continuous optical flow from an event camera,
Z. Wan, Y . Dai, and Y . Mao, “Learning dense and continuous optical flow from an event camera,”IEEE Transactions on Image Processing, 2022
2022
-
[77]
E-RAFT: Dense optical flow from event cameras,
M. Gehrig, M. Millh ¨ausler, D. Gehrig, and D. Scaramuzza, “E-RAFT: Dense optical flow from event cameras,” inInternational Conference on 3D Vision, 2021, pp. 197–206
2021
-
[78]
TMA: Temporal motion aggregation for event-based optical flow,
H. Liu, G. Chen, S. Qu, Y . Zhang, Z. Li, A. Knoll, and C. Jiang, “TMA: Temporal motion aggregation for event-based optical flow,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9685–9694
2023
-
[79]
Towards anytime optical flow estimation with event cameras,
Y . Ye, H. Shi, K. Yang, Z. Wang, X. Yin, Y . Lin, M. Liu, Y . Wang, and K. Wang, “Towards anytime optical flow estimation with event cameras,”Sensors, vol. 25, no. 10, p. 3158, 2025
2025
-
[80]
Learning optical flow from event camera with rendered dataset,
X. Luo, K. Luo, A. Luo, Z. Wang, P. Tan, and S. Liu, “Learning optical flow from event camera with rendered dataset,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9847–9857
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.