Spatial mixed models for assessing environmental exposure effects on the microbiome
Pith reviewed 2026-06-26 23:29 UTC · model grok-4.3
The pith
Spatial mixed model with conditional autoregressive priors accounts for dependencies to better detect environmental effects on the microbiome.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
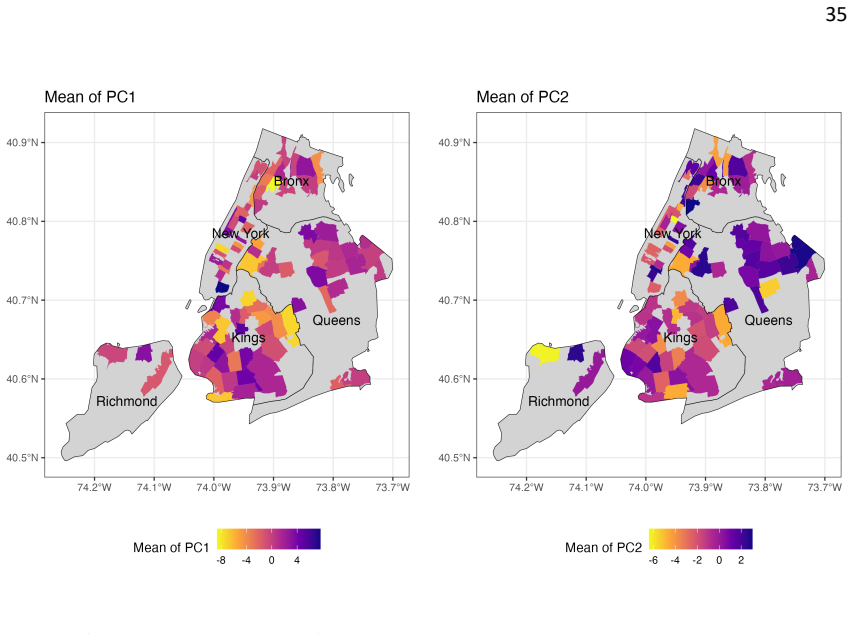
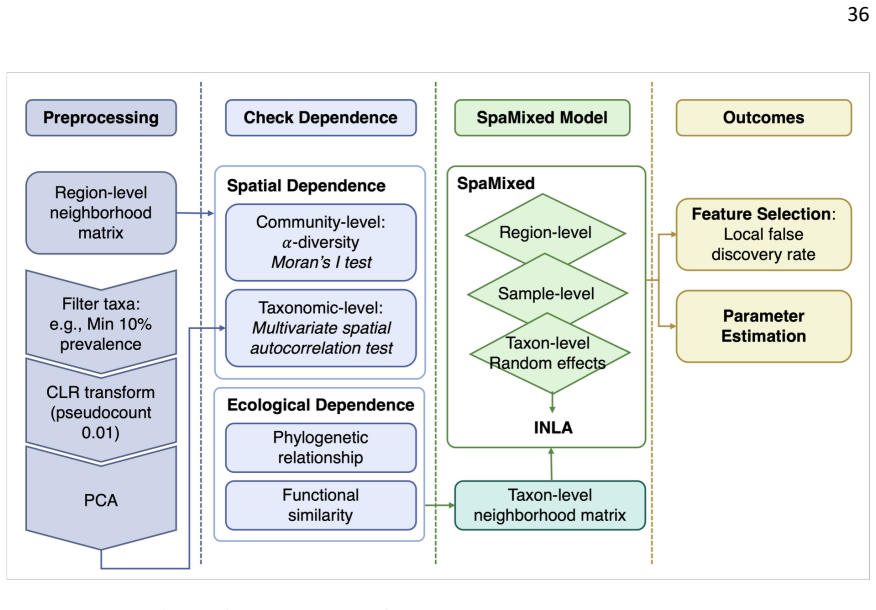
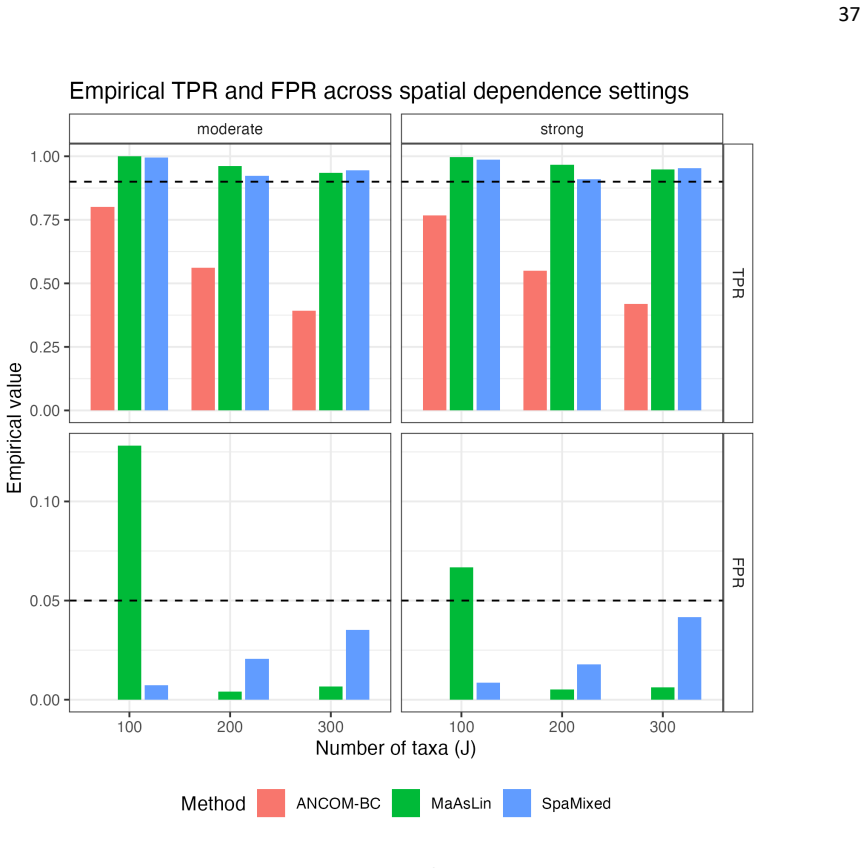
We introduce a novel spatial mixed modeling framework for microbiome data that accounts for both region-level spatial dependency and taxon-level ecological dependency using conditional autoregressive priors. Through simulations, we demonstrate that this framework outperforms existing methods that ignore such dependencies, by achieving high detection power in feature selection while maintaining low false positive rates and reduced mean squared error in estimation. Applied to two real studies with fine particulate matter exposures, our model identified genera involved in pollution-related health outcomes as well as novel taxa.
What carries the argument
Mixed effects model that places conditional autoregressive priors on both sampling regions and microbial taxa to capture spatial and ecological dependencies jointly.
If this is right
- Higher power to select microbial features linked to exposures when spatial and taxon dependencies are present.
- Lower mean squared error in estimating the strength of exposure effects.
- Recovery of both known and novel taxa in air pollution microbiome datasets.
- A general tool for microbiome analyses that involve region-level sampling and taxon correlations.
Where Pith is reading between the lines
- The framework could be tested on other spatially sampled biological datasets such as soil or water microbial communities.
- Experimental follow-up on the novel taxa would be needed to confirm any mediating role in pollution responses.
- If the conditional autoregressive structure proves inadequate for certain datasets, alternative spatial priors could be substituted and compared directly.
Load-bearing premise
Conditional autoregressive priors sufficiently capture the spatial dependencies across sampling regions and ecological correlations among microbial taxa without introducing bias or failing to account for other unmodeled structures.
What would settle it
A simulation study with known spatial and taxon correlation structures where the new model shows no gain in detection power or higher false positive rates than standard non-spatial models.
Figures
read the original abstract
The influence of environmental exposures, such as air pollution, on human health has become increasingly recognized. A growing body of evidence suggests that the microbiome may mediate these effects, explaining the relationship between the environment and host biology. However, the impact of environmental exposures on the microbiome is not yet fully understood, and statistical modeling in this context is challenged by complex dependency structures. In particular, microbiome data exhibit spatial dependencies across sampling regions as well as ecological correlations among microbial taxa, which, if ignored, can substantially reduce detection power, leading to missed true signals. We introduce a novel spatial mixed modeling framework for microbiome data that accounts for both region-level spatial dependency and taxon-level ecological dependency using conditional autoregressive priors. Through simulations, we demonstrate that this framework outperforms existing methods that ignore such dependencies, by achieving high detection power in feature selection while maintaining low false positive rates and reduced mean squared error in estimation. Applied to two real studies-data from Food and Microbiome Longitudinal Investigation study and lung microbiome dataset-with fine particulate matter (PM_2.5) exposures, our model identified genera, which are known to be involved in pollution-related health outcomes, as well as novel taxa that may mediate host responses to air pollution. This novel approach offers a powerful and flexible tool for uncovering biologically meaningful associations in complex environmental data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a spatial mixed modeling framework for microbiome data that incorporates conditional autoregressive (CAR) priors to capture both region-level spatial dependencies and taxon-level ecological correlations. It claims that simulations demonstrate superior performance over methods ignoring these dependencies, with higher detection power, lower false positives, and reduced MSE in feature selection and estimation. The framework is then applied to two real datasets (Food and Microbiome Longitudinal Investigation and a lung microbiome study) with PM2.5 exposure, identifying both known pollution-related genera and novel taxa.
Significance. If the simulation results hold under misspecification and the real-data associations are robust, the framework could improve statistical power for detecting environmental effects on the microbiome while controlling errors, addressing a recognized challenge in the field. The real-data applications provide initial evidence of biological plausibility, though the absence of parameter-free derivations or machine-checked proofs limits the strength of the contribution relative to purely theoretical advances.
major comments (2)
- [Simulation Study] Simulation Study section: The central claim of outperformance (high detection power, low FPR, reduced MSE) rests on simulation evidence, but the data-generating process must be shown to include scenarios that deviate from the exact CAR structure assumed by the model (e.g., non-CAR spatial dependence or different taxon correlation forms). If data are generated under the fitted model, superior performance is expected by construction and does not test robustness.
- [Real Data Applications] Application to real data (Food and Microbiome Longitudinal Investigation and lung microbiome sections): The identified genera are described as 'known to be involved in pollution-related health outcomes,' but no quantitative comparison (e.g., overlap statistics or p-value thresholds relative to literature) is provided to support this; the claim that the model uncovers 'novel taxa that may mediate' requires explicit sensitivity checks to unmodeled confounders such as batch effects or unmeasured spatial covariates.
minor comments (3)
- [Abstract] Abstract: No equations, model specification, or simulation design details are provided, which hinders immediate assessment of the framework's novelty relative to existing CAR or mixed-model approaches for compositional data.
- [Methods] Notation: The description of 'conditional autoregressive priors' for both regions and taxa should include explicit conditional distributions or precision matrix forms (e.g., referencing standard CAR formulations) to clarify identifiability and computational implementation.
- [Figures] Figure clarity: Simulation result figures lack error bars or confidence intervals on power/FPR/MSE metrics, making it difficult to judge the magnitude and variability of reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript. We address each major point below, agreeing where revisions are needed and clarifying the scope of our claims.
read point-by-point responses
-
Referee: [Simulation Study] Simulation Study section: The central claim of outperformance (high detection power, low FPR, reduced MSE) rests on simulation evidence, but the data-generating process must be shown to include scenarios that deviate from the exact CAR structure assumed by the model (e.g., non-CAR spatial dependence or different taxon correlation forms). If data are generated under the fitted model, superior performance is expected by construction and does not test robustness.
Authors: We agree that the current simulations are generated under the assumed CAR structure and therefore demonstrate performance when model assumptions hold exactly. This is a standard first step but does not fully address robustness. In revision we will add misspecification experiments: (i) spatial dependence generated via a Gaussian process on continuous coordinates rather than CAR on the lattice, and (ii) taxon-level correlations drawn from a different graphical model (e.g., sparse precision matrix not matching the CAR form). These additional scenarios will be reported alongside the original results to quantify degradation under misspecification. revision: yes
-
Referee: [Real Data Applications] Application to real data (Food and Microbiome Longitudinal Investigation and lung microbiome sections): The identified genera are described as 'known to be involved in pollution-related health outcomes,' but no quantitative comparison (e.g., overlap statistics or p-value thresholds relative to literature) is provided to support this; the claim that the model uncovers 'novel taxa that may mediate' requires explicit sensitivity checks to unmodeled confounders such as batch effects or unmeasured spatial covariates.
Authors: We acknowledge the value of quantitative support. In the revision we will add (a) overlap statistics between detected taxa and those previously reported in the pollution-microbiome literature (with citation counts or enrichment p-values where available) and (b) sensitivity analyses that include batch-correction covariates and additional spatial proxies (e.g., urban/rural indicators). These checks will be summarized in new supplementary tables. We note, however, that definitive mediation claims or exhaustive confounder control would require longitudinal or experimental data beyond the scope of the current observational studies; the real-data sections are presented as illustrative applications rather than definitive causal evidence. revision: partial
Circularity Check
No significant circularity; framework and simulations presented as independent validation
full rationale
The abstract introduces a novel spatial mixed model using CAR priors to account for region-level spatial and taxon-level ecological dependencies in microbiome data. It claims outperformance via simulations and identifies associations in real data from two studies. No equations, parameter-fitting steps, or self-citation chains are described that reduce predictions or uniqueness claims to the model's own inputs by construction. The derivation chain is self-contained, relying on external simulation benchmarks and real-data applications rather than tautological re-derivations or fitted quantities renamed as predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
to generate ASVs. Taxonomy was assigned using the Greengenes 2 reference database (October 2022 release), and a phylogenetic tree was constructed by inserting ASV sequences into the Greengenes reference phylogeny using the q2-frament-insertion plugin. Comprehensive cohort details are available in Kwak, Usyk [22]. 20 Lung Microbiome Study We performed an a...
2022
-
[2]
Nature Methods, 2026: p
Nickols, W.A., et al., MaAsLin 3: Refining and extending generalized mul<variable linear models for meta-omic associa<on discovery. Nature Methods, 2026: p. 1-11
2026
-
[3]
Lei, and N
Leroux, B.G., X. Lei, and N. Breslow, Es<ma<on of disease rates in small areas: a new mixed model for spa<al dependence, in Sta<s<cal models in epidemiology, the environment, and clinical trials. 2000, Springer. p. 179-191
2000
-
[4]
2005, Division of Biosta[s[cs, Stanford University
Efron, B., Local false discovery rates. 2005, Division of Biosta[s[cs, Stanford University
2005
-
[5]
Waller, L.A. and C.A. Gotway, Applied spa<al sta<s<cs for public health data. 2004: John Wiley & Sons
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.