Endpoint Anticipation for Low-Latency Spoken Dialogue
Pith reviewed 2026-06-27 05:35 UTC · model grok-4.3
The pith
A speech model forecasts conversation turn ends up to 2.56 seconds ahead, cutting spoken dialogue latency by 505 ms on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that shifting from reactive turn-completion detection to proactive forecasting of end-of-turn signals with a speech-based model allows anticipation of endpoints up to 2.56 seconds in advance. This forecast supports speculative execution of LLM and TTS pipelines on partial context. New metrics quantify the resulting trade-off between latency reduction and computational redundancy. Evaluation on conversational and task-oriented datasets shows consistent outperformance of VAP-based baselines, while integration with the Unmute framework yields a 505 ms average latency reduction and a 28.4 percent increase in speculative computation.
What carries the argument
Endpoint Anticipation, a speech-based forecasting model that predicts end-of-turn signals from partial audio to trigger early downstream pipeline execution.
If this is right
- The model outperforms competitive VAP-based baselines on both conversational and task-oriented datasets.
- Integration produces a 505 ms average latency reduction.
- Speculative computation rises by 28.4 percent while still masking sequential bottlenecks.
- Trade-off metrics reliably separate realized latency gains from redundancy across the tested datasets.
Where Pith is reading between the lines
- If the forecasts hold under varied conditions, the approach could free time for deeper reasoning inside real-time voice systems without raising user-perceived delay.
- The same partial-input prediction pattern might apply to other chained processing pipelines that can usefully begin work on incomplete data.
- The introduced metrics could serve as a template for balancing early action against wasted effort in additional interactive domains.
Load-bearing premise
The model's endpoint forecasts on partial audio must be accurate enough that early execution produces net latency gains despite any incorrect predictions.
What would settle it
An evaluation on held-out conversation data in which the measured end-to-end latency rises instead of falling, or in which the added speculative computation exceeds 28.4 percent without offsetting latency savings.
Figures
read the original abstract
While low-latency interaction is critical for spoken dialogue, cascaded architectures are often bottlenecked by reactive turn-completion detection. We propose Endpoint Anticipation, shifting from reactive detection to proactive forecasting of end-of-turn signals. Our speech-based model anticipates endpoints upto 2.56 seconds in advance, enabling speculative execution of LLM and TTS pipelines on partial context. We introduce metrics to quantify the trade-off between realized latency reduction and computational redundancy. Evaluation across conversational and task-oriented datasets shows our model consistently outperforms competitive VAP-based baselines. Integration with the Unmute framework demonstrates a 505 ms average latency reduction with a 28.4% increase in speculative computation, effectively masking sequential bottlenecks to enable complex reasoning in real-time speech-to-speech interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Endpoint Anticipation, a speech-based model that proactively forecasts end-of-turn signals up to 2.56 seconds ahead in spoken dialogue. This enables speculative execution of LLM and TTS pipelines on partial audio context. New metrics quantify the latency-reduction versus computational-redundancy trade-off. The model is reported to outperform VAP baselines on conversational and task-oriented datasets; integration with the Unmute framework yields a 505 ms average latency reduction accompanied by a 28.4 % increase in speculative computation.
Significance. If the endpoint forecasts prove sufficiently accurate and the new trade-off metrics are shown to be well-calibrated, the work could meaningfully reduce perceived latency in cascaded speech-to-speech systems and support more complex on-device reasoning. The shift from reactive detection to proactive forecasting and the explicit redundancy metric are conceptually useful contributions.
major comments (2)
- [Abstract, §4] Abstract and §4 (Evaluation): The central claim that the model 'anticipates endpoints up to 2.56 seconds in advance' and produces a 505 ms latency reduction rests on the assumption that partial-context forecasts are accurate enough for reliable speculative execution. No horizon-specific precision, recall, MAE, or false-positive rates are reported, nor is the operational definition of 'up to' or the penalty function inside the new trade-off metrics supplied. Without these quantities the 28.4 % redundancy figure cannot be interpreted.
- [Abstract, §3] Abstract and §3 (Model): No model architecture, training procedure, loss function, or dataset statistics (speaker count, turn duration distribution, train/test split) are provided. Consequently the claim of consistent outperformance over VAP baselines cannot be assessed for statistical significance or generalization.
minor comments (2)
- [Abstract] The abstract states performance numbers without error bars or confidence intervals; these should be added to all reported figures.
- [§4] Notation for the new trade-off metrics should be defined explicitly (e.g., symbols for realized latency gain and redundancy) before their numerical results are presented.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater detail on evaluation metrics and model specifications. We will revise the manuscript to incorporate the requested information, ensuring the claims are fully supported and interpretable.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Evaluation): The central claim that the model 'anticipates endpoints up to 2.56 seconds in advance' and produces a 505 ms latency reduction rests on the assumption that partial-context forecasts are accurate enough for reliable speculative execution. No horizon-specific precision, recall, MAE, or false-positive rates are reported, nor is the operational definition of 'up to' or the penalty function inside the new trade-off metrics supplied. Without these quantities the 28.4 % redundancy figure cannot be interpreted.
Authors: We agree that horizon-specific performance metrics and explicit definitions are required to substantiate the latency-reduction claims and interpret the redundancy metric. In the revised version, we will add tables and text in §4 reporting precision, recall, MAE, and false-positive rates at multiple horizons up to 2.56 s. We will also define the operational meaning of 'up to' (maximum reliable forecast horizon) and detail the penalty function within the trade-off metrics. revision: yes
-
Referee: [Abstract, §3] Abstract and §3 (Model): No model architecture, training procedure, loss function, or dataset statistics (speaker count, turn duration distribution, train/test split) are provided. Consequently the claim of consistent outperformance over VAP baselines cannot be assessed for statistical significance or generalization.
Authors: The referee is correct that these implementation and data details are necessary for evaluating the outperformance claims. We will expand §3 to describe the model architecture, training procedure, loss function, and full dataset statistics (speaker counts, turn-duration distributions, and train/test splits). This will permit assessment of statistical significance and generalization. revision: yes
Circularity Check
No circularity; empirical claims rest on external evaluation
full rationale
The manuscript advances an empirical model for endpoint anticipation and reports measured latency reductions and outperformance versus VAP baselines. No equations, parameter-fitting steps, or derivation chain appear in the provided text that could reduce a claimed prediction to a fitted input or self-citation by construction. The 505 ms and 28.4 % figures are presented as experimental outcomes from integration with the Unmute framework and dataset evaluations, not as quantities forced by the model's own definitions or prior self-citations. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
pipeline
Introduction Real-time spoken dialogue systems [1] have seen significant growth, driven by advances in large language models (LLMs). These systems [2–9] aim to process audio with low latency to perform complex tasks, often utilizing streaming speech inputs paired with the reasoning capabilities of LLMs to generate re- sponses. While end-to-end training of...
-
[2]
We propose a speech-basedEndpoint Anticipationtask and model designed for low-latency spoken dialogue systems
-
[3]
We define a set of metrics to quantify the trade-off between Realized Anticipation (the actual latency reduction provided within the target window) and Premature Anticipation (the resulting downstream computational redundancy due to pre- dictions made before the valid horizon)
-
[4]
We evaluate the framework across various anticipation targets ranging from 320 ms to 2560 ms
-
[5]
We open-source our implementation and provide a reference integration with the Unmute full-duplex framework.3
-
[6]
Related Work Early End-of-Utterance Prediction.Several approaches uti- lize ASR to predict End-of-Utterance (EOU) tokens ahead of time. Sakuma et al. [17, 18] propose a two-stage method: first generating a text hypothesis from streaming ASR, followed by a language model that predicts future EOU tokens. Chang et al. [19] similarly exploit early endpoint si...
Pith/arXiv arXiv 2026
-
[7]
Proposed approach In this section, we describe the model backbone and introduce the modeling framework for endpoint anticipation. 3.1. Dual-stream audio representation Similar to [12, 21], we process User (u) and System (s) audio streams to provide interaction context. Lettdenote the times- tamp of the current frame. LetX (u) ≤t andX (s) ≤t represent the ...
-
[8]
Experimental setup 4.1. Dataset We train and evaluate on SpokenWOZ [26] (8 kHz, task- oriented) and Switchboard [27] (8 kHz, conversational), mod- eling theUserandSpeaker Astreams as primary speakers, re- spectively. To ensure precise endpoint supervision, we refine raw turn boundaries using Silero V AD [28] to strip trailing si- lence. To prevent prematu...
-
[9]
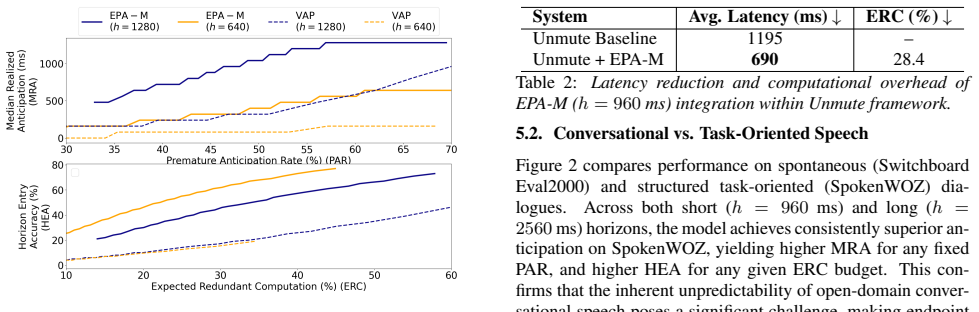
V AP vs EPA Figure 1 evaluates our proposed EPA-M model (Section 3.3) against the adapted V AP baseline
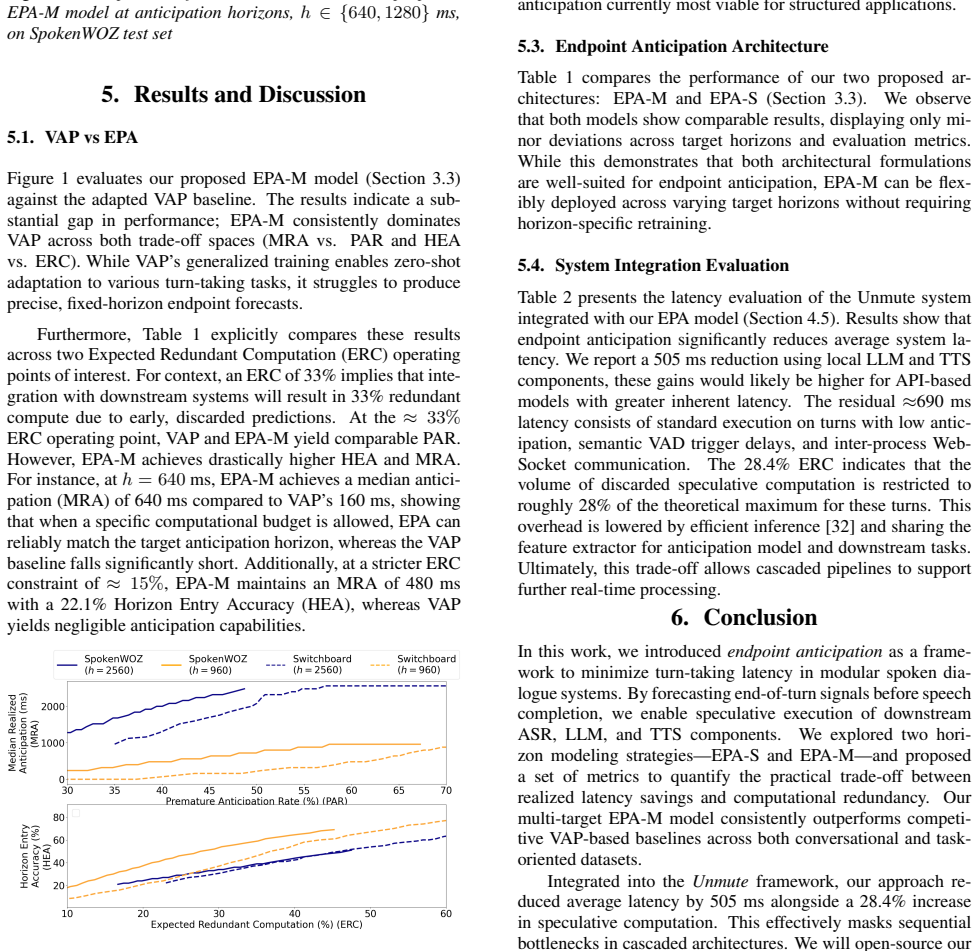
Results and Discussion 5.1. V AP vs EPA Figure 1 evaluates our proposed EPA-M model (Section 3.3) against the adapted V AP baseline. The results indicate a sub- stantial gap in performance; EPA-M consistently dominates V AP across both trade-off spaces (MRA vs. PAR and HEA vs. ERC). While V AP’s generalized training enables zero-shot adaptation to various...
-
[10]
By forecasting end-of-turn signals before speech completion, we enable speculative execution of downstream ASR, LLM, and TTS components
Conclusion In this work, we introducedendpoint anticipationas a frame- work to minimize turn-taking latency in modular spoken dia- logue systems. By forecasting end-of-turn signals before speech completion, we enable speculative execution of downstream ASR, LLM, and TTS components. We explored two hori- zon modeling strategies—EPA-S and EPA-M—and proposed...
-
[11]
No AI tools were used to generate technical content
Generative AI Use Disclosure The authors used Gemini 3 Pro exclusively for language refine- ment. No AI tools were used to generate technical content. The authors assume full responsibility for this manuscript
-
[12]
On the landscape of spoken language models: A comprehensive survey,
S. Arora, K.-W. Chang, C.-M. Chien, Y . Peng, H. Wu, Y . Adi, E. Dupoux, H.-Y . Lee, K. Livescu, and S. Watanabe, “On the landscape of spoken language models: A comprehensive survey,” arXiv preprint arXiv:2504.08528, 2025
Pith/arXiv arXiv 2025
-
[13]
Moshi: a speech-text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[14]
Effi- cient and Direct Duplex Modeling for Speech-to-Speech Lan- guage Model,
K. Hu, E. Hosseini-Asl, C. Chen, E. Casanova, S. Ghosh, P. ˙Zelasko, Z. Chen, J. Li, J. Balam, and B. Ginsburg, “Effi- cient and Direct Duplex Modeling for Speech-to-Speech Lan- guage Model,” inInterspeech, 2025, pp. 2715–2719
2025
-
[15]
Personaplex: V oice and role control for full duplex conversational speech models,
R. Roy, J. Raiman, S. gil Lee, T.-D. Ene, R. Kirby, S. Kim, J. Kim, and B. Catanzaro, “Personaplex: V oice and role control for full duplex conversational speech models,” 2026. [Online]. Available: https://arxiv.org/abs/2602.06053
arXiv 2026
-
[16]
Chipchat: Low-latency cascaded conversational agent in mlx,
T. Likhomanenko, L. Carlson, R. H. Bai, Z. Gu, H. Tran, Z. Aldeneh, Y . Zhang, R. Zhang, H. Zheng, and N. Jaitly, “Chipchat: Low-latency cascaded conversational agent in mlx,” arXiv preprint arXiv:2509.00078, 2025
arXiv 2025
-
[17]
Salmonn-omni: A standalone speech llm without codec injection for full-duplex conversation,
W. Yu, S. Wang, X. Yang, X. Chen, X. Tian, J. Zhang, G. Sun, L. Lu, Y . Wang, and C. Zhang, “Salmonn-omni: A standalone speech llm without codec injection for full-duplex conversation,” NeurIPS, 2025. [Online]. Available: arXiv:2505.17060
arXiv 2025
-
[18]
End-to-end listen, look, speak and act,
S. Wang, W. Yu, X. Chen, X. Tian, J. Zhang, L. Lu, and C. Zhang, “End-to-end listen, look, speak and act,”ICLR, 2026. [Online]. Available: arXiv:2510.16756
Pith/arXiv arXiv 2026
-
[19]
Glm-4-voice: Towards intelligent and human-like end- to-end spoken chatbot,
A. Zeng, Z. Du, M. Liu, K. Wang, S. Jiang, L. Zhao, Y . Dong, and J. Tang, “Glm-4-voice: Towards intelligent and human-like end- to-end spoken chatbot,”arXiv preprint arXiv:2412.02612, 2024
Pith/arXiv arXiv 2024
-
[20]
F-actor: Controllable conversational behaviour in full- duplex models,
M. Z ¨ufle, O. Klejch, N. Sanders, J. Niehues, A. Birch, and T. K. Lam, “F-actor: Controllable conversational behaviour in full- duplex models,”arXiv preprint arXiv:2601.11329, 2026
Pith/arXiv arXiv 2026
-
[21]
Endpoint Detection Using Grid Long Short-Term Memory Net- works for Streaming Speech Recognition,
S.-Y . Chang, B. Li, T. N. Sainath, G. Simko, and C. Parada, “Endpoint Detection Using Grid Long Short-Term Memory Net- works for Streaming Speech Recognition,” inInterspeech, 2017, pp. 3812–3816
2017
-
[22]
Real-time and continuous turn-taking prediction using voice ac- tivity projection,
K. Inoue, B. Jiang, E. Ekstedt, T. Kawahara, and G. Skantze, “Real-time and continuous turn-taking prediction using voice ac- tivity projection,”arXiv preprint arXiv:2401.04868, 2024
arXiv 2024
-
[23]
Streaming endpointer for spoken dialogue using neural audio codecs and label-delayed training,
S. Udupa, S. Watanabe, P. Schwarz, and J. Cernocky, “Streaming endpointer for spoken dialogue using neural audio codecs and label-delayed training,”ASRU, 2025. [Online]. Available: arXiv:2506.07081
arXiv 2025
-
[24]
G. Li, C. Wang, H. Xue, S. Wang, D. Gao, Z. Zhang, Y . Lin, W. Li, L. Xiao, Z. Fuet al., “Easy turn: Integrating acoustic and linguistic modalities for robust turn-taking in full-duplex spoken dialogue systems,”arXiv preprint arXiv:2509.23938, 2025
arXiv 2025
-
[25]
Universals and cultural variation in turn-taking in conversation,
T. Stivers, N. J. Enfield, P. Brown, C. Englert, M. Hayashi, T. Heinemann, G. Hoymann, F. Rossano, J. P. De Ruiter, K.-E. Yoonet al., “Universals and cultural variation in turn-taking in conversation,”Proceedings of the National Academy of Sciences, vol. 106, no. 26, pp. 10 587–10 592, 2009
2009
-
[26]
Kame: Tandem ar- chitecture for enhancing knowledge in real-time speech-to-speech conversational ai,
S. Kuroki, Y . Kubo, T. Akiba, and Y . Tang, “Kame: Tandem ar- chitecture for enhancing knowledge in real-time speech-to-speech conversational ai,”arXiv preprint arXiv:2510.02327, 2025
Pith/arXiv arXiv 2025
-
[27]
Timing in turn-taking and its im- plications for processing models of language,
S. C. Levinson and F. Torreira, “Timing in turn-taking and its im- plications for processing models of language,”Frontiers in psy- chology, vol. 6, p. 136034, 2015
2015
-
[28]
Response timing estima- tion for spoken dialog systems based on syntactic completeness prediction,
J. Sakuma, S. Fujie, and T. Kobayashi, “Response timing estima- tion for spoken dialog systems based on syntactic completeness prediction,” in2022 IEEE Spoken Language Technology Work- shop (SLT). IEEE, 2023, pp. 369–374
2023
-
[29]
Improving the response timing estimation for spoken dialogue systems by reduc- ing the effect of speech recognition delay
J. Sakuma, S. Fujie, H. Zhao, and T. Kobayashi, “Improving the response timing estimation for spoken dialogue systems by reduc- ing the effect of speech recognition delay.” inInterspeech, 2023, pp. 2668–2672
2023
-
[30]
Low latency speech recognition using end-to-end prefetching
S.-Y . Chang, B. Li, D. Rybach, Y . He, W. Li, T. N. Sainath, and T. Strohman, “Low latency speech recognition using end-to-end prefetching.” inInterspeech, 2020, pp. 1962–1966
2020
-
[31]
Predictive speech recognition and end-of-utterance detection to- wards spoken dialog systems,
O. Zink, Y . Higuchi, C. Mullov, A. Waibel, and T. Kobayashi, “Predictive speech recognition and end-of-utterance detection to- wards spoken dialog systems,”arXiv preprint arXiv:2409.19990, 2024
arXiv 2024
-
[32]
V oice activity projection: Self- supervised learning of turn-taking events,
E. Ekstedt and G. Skantze, “V oice activity projection: Self- supervised learning of turn-taking events,” inInterspeech, 2022, pp. 5190–5194
2022
-
[33]
Multilingual turn-taking prediction using voice activity projec- tion,
K. Inoue, B. Jiang, E. Ekstedt, T. Kawahara, and G. Skantze, “Multilingual turn-taking prediction using voice activity projec- tion,” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024), N. Calzolari, M.-Y . Kan, V . Hoste, A. Lenci, S. Sakti, and N. Xue, Eds. Torino...
2024
-
[34]
Can speech llms think while listening?
Y .-J. Shih, D. Raj, C. Wu, W. Zhou, S. Bong, Y . Gaur, J. Ma- hadeokar, O. Kalinli, and M. Seltzer, “Can speech llms think while listening?”arXiv preprint arXiv:2510.07497, 2025
arXiv 2025
-
[35]
Chain-of-Thought Training for Open E2E Spoken Dialogue Systems,
S. Arora, J. Tian, H. Futami, J. weon Jung, J. Shi, Y . Kashi- wagi, E. Tsunoo, and S. Watanabe, “Chain-of-Thought Training for Open E2E Spoken Dialogue Systems,” inInterspeech, 2025, pp. 4833–4837
2025
-
[36]
Stream rag: Instant and accurate spoken dialogue systems with streaming tool usage,
S. Arora, H. Khan, K. Sun, X. L. Dong, S. Choudhary, S. Moon, X. Zhang, A. Sagar, S. T. Appini, K. Patnaiket al., “Stream rag: Instant and accurate spoken dialogue systems with streaming tool usage,”arXiv preprint arXiv:2510.02044, 2025
arXiv 2025
-
[37]
Spokenwoz: A large-scale speech-text benchmark for spoken task-oriented dialogue agents,
S. Si, W. Ma, H. Gao, Y . Wu, T.-E. Lin, Y . Dai, H. Li, R. Yan, F. Huang, and Y . Li, “Spokenwoz: A large-scale speech-text benchmark for spoken task-oriented dialogue agents,”NeurIPS, vol. 36, pp. 39 088–39 118, 2023
2023
-
[38]
Switchboard: Telephone speech corpus for research and development,
J. J. Godfrey, E. C. Holliman, and J. McDaniel, “Switchboard: Telephone speech corpus for research and development,” in ICASSP, vol. 1. IEEE, 1992, pp. 517–520
1992
-
[39]
Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,
S. Team, “Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,” https:// github.com/snakers4/silero-vad, 2024
2024
-
[40]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” NeurIPS, vol. 30, 2017
2017
-
[41]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: Enhanced transformer with rotary position embedding,”Neuro- computing, vol. 568, p. 127063, 2024
2024
-
[42]
Streaming sequence-to-sequence learning with delayed streams modeling,
N. Zeghidour, E. Kharitonov, M. Orsini, V . V olhejn, G. de Marmiesse, E. Grave, P. P´erez, L. Mazar´e, and A. D´efossez, “Streaming sequence-to-sequence learning with delayed streams modeling,”arXiv preprint arXiv:2509.08753, 2025
arXiv 2025
-
[43]
Efficient memory manage- ment for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory manage- ment for large language model serving with pagedattention,” in Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[44]
G.-T. Lin, J. Lian, T. Li, Q. Wang, G. Anumanchipalli, A. H. Liu, and H.-y. Lee, “Full-duplex-bench: A benchmark to evaluate full- duplex spoken dialogue models on turn-taking capabilities,”arXiv preprint arXiv:2503.04721, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.