MORN: Metacognitive Object-Goal Regulation for Resource-Rational Long-Horizon Navigation
Pith reviewed 2026-05-19 20:23 UTC · model grok-4.3
The pith
MORN adds a metacognitive meta-controller to frozen navigation agents so they can estimate progress velocity and perceptual uncertainty and abort infeasible subgoals early.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
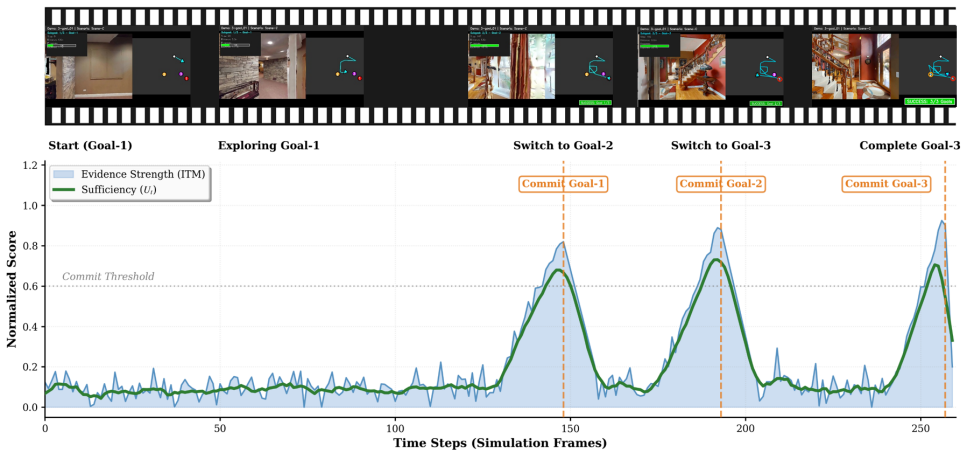
MORN augments frozen navigation backbones with a System 2 meta-controller that continuously monitors the System 1 locomotor by formalizing Potentiality Index, Persistence Gating, and Evidence Accumulation; it then dynamically regulates the mission schedule according to online estimates of progress velocity and perceptual uncertainty, neutralizing the sunk cost fallacy so agents abort zombie goals early and commit to achievable ones.
What carries the argument
The System 2 meta-controller that monitors the System 1 locomotor using three neuro-cognitive states to estimate progress velocity and perceptual uncertainty and regulate the mission schedule.
If this is right
- Agents reach more goals without retraining or replacing the underlying navigation model.
- Fewer steps are spent on unreachable subgoals, preserving battery and time for remaining mission segments.
- The same regulation logic applies across different frozen backbones and environments with partial observability.
- Local exploration can be balanced against global mission viability without explicit global planning.
- Early termination of infeasible goals reduces exposure to compounding errors from repeated failed attempts.
Where Pith is reading between the lines
- The same three-state monitoring approach could be tested on mobile manipulation tasks where partial observability also produces zombie subgoals.
- Real-world battery-life gains would follow if the controller's estimates remain accurate when sensor noise increases beyond simulation levels.
- The architecture suggests a general template for adding lightweight executive oversight to any reactive policy in long-horizon sequential decision problems.
Load-bearing premise
The three neuro-cognitive states can be formalized and estimated online from a frozen navigation backbone in a way that reliably distinguishes feasible from infeasible subgoals under partial observability.
What would settle it
An ablation experiment on HM3D that disables the meta-controller estimates or replaces them with random values and measures whether goal completion rate stays at 0.23 and wasted step fraction stays at 0.90.
Figures






read the original abstract
Robots deployed in unstructured human environments must frequently execute long-horizon missions, such as find the mug, then the chair, then the printer, under strict operational constraints. While contemporary zero-shot Object Navigation (ObjectNav) agents leverage Vision-Language Models (VLMs) to effectively localize semantic targets, they operate as purely reactive systems that inherently lack global resource awareness. Consequently, these agents inadvertently exhaust critical budgets, including time and battery, on infeasible subgoals due to partial observability, failing to balance local exploration with global mission viability. To bridge this gap by injecting resource-rationality into the navigation loop, we present MORN (Metacognitive Object-goal Regulation Navigation), an executive architecture inspired by Dual-Process Theory in cognitive science. MORN augments frozen navigation backbones with a System 2 meta-controller that continuously monitors the System 1 locomotor. By formalizing three neuro-cognitive states, Potentiality Index, Persistence Gating, and Evidence Accumulation, MORN dynamically regulates the mission schedule based on online estimates of progress velocity and perceptual uncertainty. This mechanism effectively neutralizes the Sunk Cost Fallacy, enabling agents to abort zombie goals early and decisively commit to achievable ones. Extensive experiments on the HM3D dataset demonstrate that MORN improves Goal Completion Rate (CR) from 0.23 to 0.30 and reduces Wasted Step Fraction (WSF) from 0.90 to 0.70, establishing that in resource-constrained autonomy, the metacognitive awareness of global resources is as critical as the reactive ability to navigate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MORN, an executive architecture that augments frozen ObjectNav backbones with a System-2 meta-controller. The controller formalizes three neuro-cognitive states (Potentiality Index, Persistence Gating, Evidence Accumulation) to monitor online progress velocity and perceptual uncertainty, thereby regulating subgoal persistence and mitigating sunk-cost behavior on infeasible long-horizon missions. Experiments on HM3D report raising Goal Completion Rate from 0.23 to 0.30 and lowering Wasted Step Fraction from 0.90 to 0.70.
Significance. If the mechanism and gains are reproducible, the work supplies a lightweight, backbone-agnostic route to resource-rational navigation that preserves the strengths of existing reactive agents while adding global viability awareness. The modest, directionally consistent improvements and the explicit separation of System-1 locomotion from System-2 regulation are practical strengths for deployment under time and energy constraints.
major comments (2)
- [§4] §4 (Experiments): the reported CR and WSF deltas are presented without baselines, episode counts, random seeds, variance, or statistical significance tests, preventing assessment of whether the 0.23-to-0.30 and 0.90-to-0.70 changes are reliable or merely within run-to-run fluctuation.
- [§3.1–3.3] §3.1–3.3: the online estimation procedures for Potentiality Index, Persistence Gating, and Evidence Accumulation are described at a high level but lack explicit equations or pseudocode showing how each quantity is computed from a frozen backbone’s outputs under partial observability; this is load-bearing for the claim that the meta-controller can reliably distinguish feasible from infeasible subgoals.
minor comments (2)
- [Abstract] Abstract: the baseline agent achieving the 0.23/0.90 figures is not named; adding this single clause would improve immediate readability.
- [§3] Notation: the three states are introduced with capitalized names but later referenced inconsistently; a single definitions table or consistent acronym usage would reduce reader effort.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and outline the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the reported CR and WSF deltas are presented without baselines, episode counts, random seeds, variance, or statistical significance tests, preventing assessment of whether the 0.23-to-0.30 and 0.90-to-0.70 changes are reliable or merely within run-to-run fluctuation.
Authors: We agree that the experimental reporting in §4 requires additional rigor to allow proper evaluation of the reported improvements. The initial submission presented aggregate deltas without sufficient supporting statistics. In the revised manuscript we will expand §4 to include: the total number of evaluation episodes and scenes used, the random seeds for reproducibility, mean and standard deviation of CR and WSF across multiple runs, and results of appropriate statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests) confirming that the observed changes exceed run-to-run variability. We will also explicitly restate the baseline conditions against which the 0.23-to-0.30 and 0.90-to-0.70 figures are measured. revision: yes
-
Referee: [§3.1–3.3] §3.1–3.3: the online estimation procedures for Potentiality Index, Persistence Gating, and Evidence Accumulation are described at a high level but lack explicit equations or pseudocode showing how each quantity is computed from a frozen backbone’s outputs under partial observability; this is load-bearing for the claim that the meta-controller can reliably distinguish feasible from infeasible subgoals.
Authors: We concur that explicit computational definitions are necessary to substantiate the meta-controller’s ability to operate under partial observability. Although the manuscript outlines the neuro-cognitive states conceptually, it does not supply the precise update rules. In the revision we will add, in §3, the full mathematical formulations: Potentiality Index as a normalized function of estimated progress velocity and perceptual uncertainty derived from VLM confidence scores; Persistence Gating as a dynamic threshold applied to accumulated evidence; and Evidence Accumulation as a recursive Bayesian-style update over successive observations. We will also insert pseudocode that shows the exact sequence of operations performed on the frozen backbone’s outputs (e.g., object detection logits, spatial embeddings, and uncertainty estimates) at each time step. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes MORN as an executive architecture that augments a frozen navigation backbone with a System 2 meta-controller monitoring progress velocity and perceptual uncertainty via three formalized neuro-cognitive states. All reported performance gains (CR from 0.23 to 0.30, WSF from 0.90 to 0.70 on HM3D) are presented as empirical outcomes of this added mechanism rather than quantities derived from or fitted to the same experimental data. No equations, self-citations, or uniqueness theorems are invoked in the provided text to justify the core claims, leaving the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dual-Process Theory from cognitive science provides a useful model for separating reactive navigation from higher-level resource monitoring in robots.
invented entities (3)
-
Potentiality Index
no independent evidence
-
Persistence Gating
no independent evidence
-
Evidence Accumulation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MORN augments frozen navigation backbones with a System 2 meta-controller that continuously monitors the System 1 locomotor. By formalizing three neuro-cognitive states, Potentiality Index, Persistence Gating, and Evidence Accumulation, MORN dynamically regulates the mission schedule based on online estimates of progress velocity and perceptual uncertainty.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
This mechanism effectively neutralizes the Sunk Cost Fallacy, enabling agents to abort zombie goals early and decisively commit to achievable ones.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation,
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation,” arXiv:2312.03275, 2023
-
[2]
ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings,
A. Majumdar, G. Aggarwal, B. S. Devnani, J. Hoffman, and D. Batra, “ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings,” inProc. NeurIPS, 2022
work page 2022
-
[3]
J. Chen, G. Li, S. Kumar, and F. Yu, “How To Not Train Your Dragon: Training-free Embodied Object Goal Navigation with Semantic Fron- tiers,” inProc. Robotics: Science and Systems (RSS), 2023
work page 2023
-
[4]
“ApexNav: An Adaptive Exploration Strategy for Zero-Shot Object Navigation with Target-centric Semantic Fusion,” arXiv:2504.14478, 2025
-
[5]
Zero-shot Object Navigation with Vision-Language Models Reasoning,
C. Wen et al. , “Zero-shot Object Navigation with Vision-Language Models Reasoning,” arXiv:2410.18570, 2024
-
[6]
SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation,” arXiv:2410.08189, 2024
-
[7]
Hier- archical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation,
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard, “Hier- archical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation,” arXiv:2403.17846, 2024
-
[8]
Open Scene Graphs for Open World Object-Goal Navigation,
J. Loo et al. , “Open Scene Graphs for Open World Object-Goal Navigation,” arXiv:2407.02473, 2024
-
[9]
Y . Tang et al. , “OpenObject-NA V: Open-V ocabulary Object-Oriented Navigation Based on Dynamic Carrier-Relationship Scene Graph,” arXiv:2409.18743, 2024
-
[10]
Towards Open-V ocabulary Scene Graph Generation with Prompt-based Finetuning,
T. He, L. Gao, J. Song, and Y .-F. Li, “Towards Open-V ocabulary Scene Graph Generation with Prompt-based Finetuning,” inProc. ECCV, 2022
work page 2022
-
[11]
OvSGTR: Fully Open-V ocabulary Scene Graph Generation,
Z. Chen et al. , “OvSGTR: Fully Open-V ocabulary Scene Graph Generation,” arXiv:2505.20106, 2025
-
[12]
REGNav: Room Expert Guided Image-Goal Navigation,
P. Li, K. Wu, J. Fu, and S. Zhou, “REGNav: Room Expert Guided Image-Goal Navigation,” inProc. AAAI Conf. on Artificial Intelli- gence, vol. 39, no. 5, pp. 4860–4868, 2025
work page 2025
-
[13]
REGNav: Room Expert Guided Image-Goal Navigation,
P. Li, K. Wu, J. Fu, and S. Zhou, “REGNav: Room Expert Guided Image-Goal Navigation,” arXiv:2502.10785, 2025
-
[14]
Target-Driven Visual Navigation in Indoor Scenes,
Y . Zhu et al. , “Target-Driven Visual Navigation in Indoor Scenes,” in Proc. IEEE Int. Conf. on Robotics and Automation (ICRA), 2017
work page 2017
-
[15]
Event-Equalized Dense Video Captioning,
K. Wu, P. Li, J. Fu, Y . Li, Y . Wu, Y . Liu, J. Wang, and S. Zhou, “Event-Equalized Dense Video Captioning,” inProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 8417– 8427
work page 2025
-
[16]
CEM- Net: Cross-Emotion Memory Network for Emotional Talking Face Generation,
K. Wu, P. Li, J. Fu, Y . Wu, Y . Liu, S. Zhou, and J. Wang, “CEM- Net: Cross-Emotion Memory Network for Emotional Talking Face Generation,” arXiv:2508.12368, 2025
-
[17]
MultiON: Benchmarking Semantic Map Memory using Multi-Object Navigation,
A. Wani et al. , “MultiON: Benchmarking Semantic Map Memory using Multi-Object Navigation,” inProc. NeurIPS, 2020
work page 2020
-
[18]
A Survey on Integrating Knowledge into Object Goal Navigation,
B. Suh, “A Survey on Integrating Knowledge into Object Goal Navigation,” OpenReview, 2025
work page 2025
-
[19]
Attention to Action: Willed and Au- tomatic Control of Behavior,
D. A. Norman and T. Shallice, “Attention to Action: Willed and Au- tomatic Control of Behavior,” inConsciousness and Self-Regulation, 1986
work page 1986
-
[20]
R. E. Bellman,Dynamic Programming. Princeton Univ. Press, 1957
work page 1957
-
[21]
Between MDPs and Semi- MDPs: A Framework for Temporal Abstraction in Reinforcement Learning,
R. S. Sutton, D. Precup, and S. Singh, “Between MDPs and Semi- MDPs: A Framework for Temporal Abstraction in Reinforcement Learning,”Artif. Intell., vol. 112, no. 1–2, pp. 181–211, 1999
work page 1999
-
[22]
Recent Advances in Hierarchical Reinforcement Learning,
A. G. Barto and S. Mahadevan, “Recent Advances in Hierarchical Reinforcement Learning,”Discrete Event Dynamic Systems, vol. 13, no. 4, pp. 341–379, 2003
work page 2003
-
[23]
Learning Transferable Visual Models From Natural Language Supervision,
A. Radford et al. , “Learning Transferable Visual Models From Natural Language Supervision,” inProc. ICML, 2021
work page 2021
-
[24]
J. Li et al. , “BLIP-2: Bootstrapping Language-Image Pre- training with Frozen Image Encoders and Large Language Models,” arXiv:2301.12597, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
S. Liu et al. , “Grounding DINO: Marrying DINO with Grounded Pre- Training for Open-Set Object Detection,” arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
A. Kirillov et al. , “Segment Anything,” arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
End-to-End Object Detection with Transformers,
N. Carion et al. , “End-to-End Object Detection with Transformers,” inProc. ECCV, 2020
work page 2020
-
[28]
Habitat: A Platform for Embodied AI Research,
M. Savva et al. , “Habitat: A Platform for Embodied AI Research,” inProc. IEEE Int. Conf. on Computer Vision (ICCV), 2019
work page 2019
-
[29]
On Evaluation of Embodied Navigation Agents
P. Anderson et al. , “On Evaluation of Embodied Navigation Agents,” arXiv:1807.06757, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots,
X. Puig et al. , “Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots,” arXiv:2301.13268, 2023
-
[31]
Habitat 2.0: Training Home Assistants to Rearrange their Habitat,
A. Szot et al. , “Habitat 2.0: Training Home Assistants to Rearrange their Habitat,” NeurIPS, 2021
work page 2021
-
[32]
Habitat: A Platform for Embodied AI Research,
M. Savva et al. , “Habitat: A Platform for Embodied AI Research,” ICCV , 2019
work page 2019
-
[33]
A Frontier-Based Approach for Autonomous Explo- ration,
B. Yamauchi, “A Frontier-Based Approach for Autonomous Explo- ration,” inIEEE Int. Symp. Comput. Intell. Robot. Autom., 1997, pp. 146–151
work page 1997
- [34]
-
[35]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiy et al. , “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” inProc. Int. Conf. on Learning Representations (ICLR), 2021
work page 2021
-
[36]
A. Vaswani et al. , “Attention Is All You Need,” inProc. NeurIPS, 2017
work page 2017
-
[37]
Deep Residual Learning for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” inProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
work page 2016
-
[38]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents, 2022
H. Chen et al. , “Language Models as Zero-shot Planners for Embodied Navigation,” arXiv:2201.07207, 2022
-
[39]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn et al. , “Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,” arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
PaLM-E: An Embodied Multimodal Language Model
D. Driess et al. , “PaLM-E: An Embodied Multimodal Language Model,” arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan et al. , “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control,” arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Distinctive Image Features from Scale-Invariant Key- points,
D. G. Lowe, “Distinctive Image Features from Scale-Invariant Key- points,”Int. J. Comput. Vis., vol. 60, no. 2, pp. 91–110, 2004
work page 2004
-
[43]
Representation Learning: A Review and New Perspectives,
Y . Bengio, A. Courville, and P. Vincent, “Representation Learning: A Review and New Perspectives,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 8, pp. 1798–1828, 2013
work page 2013
-
[44]
ViperGPT: Visual Inference via Python Execution for Reasoning
J. Zhu et al. , “ViperGPT: Visual Inference via Python Execution for Reasoning,” arXiv:2303.08128, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.