Clean Me If You Can: A Large Collection of Real-World Addresses for Data Cleaning Benchmarking
Pith reviewed 2026-07-01 02:06 UTC · model grok-4.3
The pith
A large real-world dataset of dirty postal addresses with ground truth shows existing data cleaning methods have significant limitations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By releasing a large dirty dataset of postal entries paired with accurate ground truth, the authors enable better evaluation of data cleaning approaches, which are shown to have limitations on this realistic data, and provide guidelines for future research.
What carries the argument
The dataset of postal addresses with ground truth, which acts as a benchmark to test and reveal weaknesses in data cleaning methods.
If this is right
- Existing data cleaning approaches perform poorly when applied to this realistic collection of dirty postal data.
- Future research should follow the derived guidelines to address the complexities of real-world errors.
- Benchmarking efforts need to shift toward datasets that capture actual production data distributions rather than controlled test cases.
Where Pith is reading between the lines
- The same collection process could be repeated for other tabular domains such as financial or medical records to create additional benchmarks.
- The dataset offers a concrete testbed for developing and comparing machine learning models aimed at address correction.
- Hybrid systems that combine rule-based and learned cleaning steps may show improved results when measured against this resource.
Load-bearing premise
The collected postal entries are representative of real-world dirty data and the provided ground truth is accurate and unbiased.
What would settle it
Independent verification showing systematic errors in the ground truth labels, or a cleaning method achieving high accuracy across the full dataset without having seen its contents during development.
Figures

read the original abstract
There has been extensive research on automating and scaling data cleaning, i.e., the detection and correction of erroneous values in tabular data. Yet, existing approaches often perform well only within controlled environments. One of the major bottlenecks in data cleaning research is the lack of real-world datasets. In this paper, we address this gap by providing a large, dirty dataset with postal entries and their corresponding ground truth. We discuss the design decisions and challenges for obtaining the dataset. We demonstrate the limitations of existing cleaning approaches when faced with our proposed datasets and derive guidelines for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a large collection of real-world dirty postal address entries paired with corresponding ground truth. It discusses design decisions and challenges encountered during dataset construction, evaluates the performance of existing data cleaning methods on the new data to illustrate their limitations, and derives guidelines for future data cleaning research.
Significance. A well-documented, large-scale benchmark with verified ground truth and representative error patterns would address a recognized gap in data cleaning research, where most evaluations rely on synthetic or small-scale data. If the collection and verification processes are shown to be independent and unbiased, the resource could enable more realistic method comparisons and the guidelines could usefully inform subsequent work. The contribution is primarily the dataset release itself rather than new algorithms or proofs.
major comments (2)
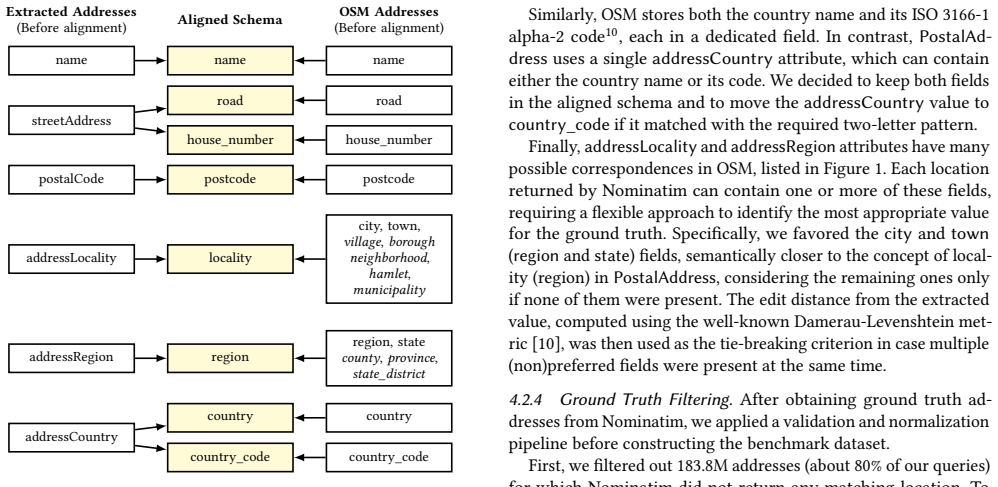
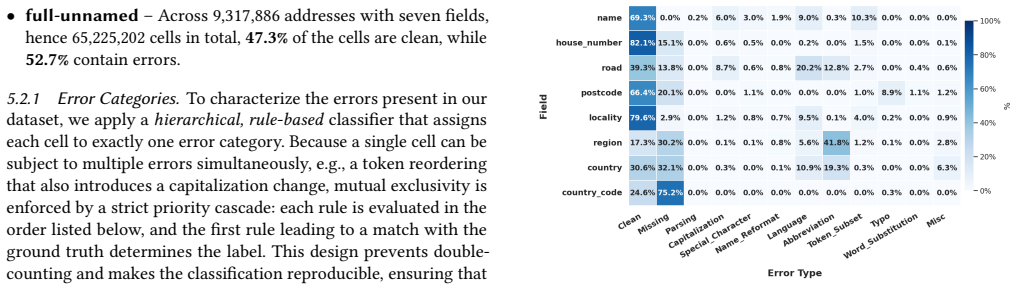
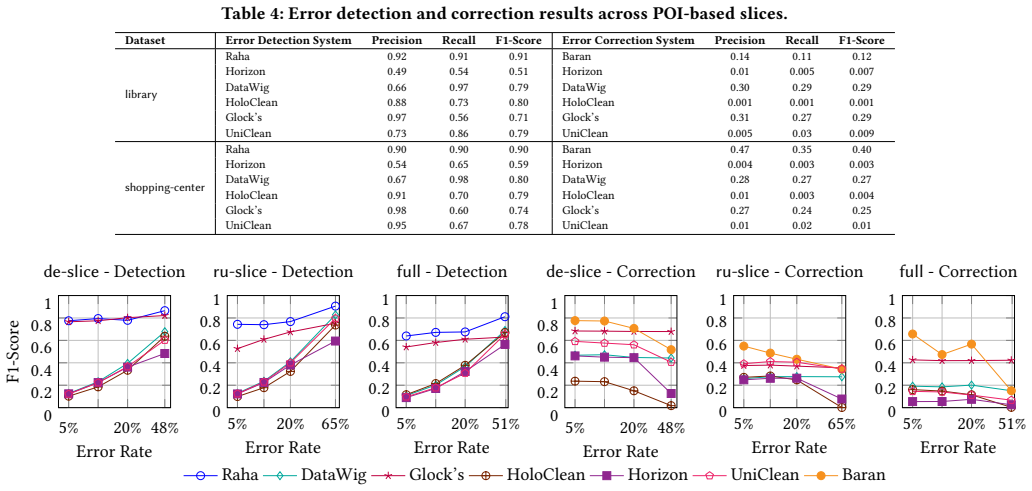
- [Abstract] Abstract and design decisions discussion: the central claim that the dataset is 'large' with 'corresponding ground truth' and that existing methods fail on it is unsupported by any quantitative details on collection methodology, total number of entries, error-type distribution, or the independent verification process used to establish ground truth. Without these, the benchmark value and the demonstration of method limitations cannot be assessed.
- [Design decisions section] The section discussing design decisions and challenges does not address how ground truth was obtained in a manner independent of the cleaning methods being benchmarked, nor does it report any cross-validation or external reference checks. This directly affects the weakest assumption that the ground truth is accurate and unbiased for postal addresses.
minor comments (1)
- [Abstract] The abstract could explicitly state the scale (number of addresses, number of methods evaluated) rather than using only qualitative descriptors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to strengthen the presentation of quantitative details and the ground truth verification process. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and design decisions discussion: the central claim that the dataset is 'large' with 'corresponding ground truth' and that existing methods fail on it is unsupported by any quantitative details on collection methodology, total number of entries, error-type distribution, or the independent verification process used to establish ground truth. Without these, the benchmark value and the demonstration of method limitations cannot be assessed.
Authors: We agree that the abstract and design decisions discussion would benefit from explicit quantitative support for the claims. Although the manuscript body contains these details in the dataset construction and evaluation sections, we will revise the abstract to include a concise summary of collection methodology, total entries, error-type distribution, and verification approach. We will also add a short quantitative overview paragraph to the design decisions section. This will make the benchmark value and method limitations clearer without altering the core contribution. revision: yes
-
Referee: [Design decisions section] The section discussing design decisions and challenges does not address how ground truth was obtained in a manner independent of the cleaning methods being benchmarked, nor does it report any cross-validation or external reference checks. This directly affects the weakest assumption that the ground truth is accurate and unbiased for postal addresses.
Authors: We will revise the design decisions section to explicitly describe the ground truth acquisition process and its independence from the benchmarked cleaning methods. The revision will include details on any cross-validation steps or external reference sources used to confirm accuracy. This directly addresses the concern about potential bias and strengthens the assumption of reliable ground truth. revision: yes
Circularity Check
Dataset release with no derivations or fitted results
full rationale
The paper contributes a collection of real-world dirty postal address data together with ground truth and empirical benchmarks of existing cleaners. No equations, predictions, parameters, or derivation chains appear in the manuscript. Claims rest on data collection methodology and direct experimental comparison rather than any self-referential reduction, fitted-input prediction, or self-citation load-bearing step. The ground-truth verification process is a methodological decision external to any mathematical construction and does not create circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mohamed Abdelaal, Christian Hammacher, and Harald Schöning. 2023. REIN: A Comprehensive Benchmark Framework for Data Cleaning Methods in ML Pipelines. InProceedings of the International Conference on Extending Database Technology (EDBT). 499–511. https://doi.org/10.48786/edbt.2023.43
-
[2]
Akcora, Mourad Ouzzani, Paolo Papotti, and Michael Stonebraker
Ziawasch Abedjan, Cuneyt G. Akcora, Mourad Ouzzani, Paolo Papotti, and Michael Stonebraker. 2015. Temporal Rules Discovery for Web Data Cleaning. Proceedings of the VLDB Endowment (PVLDB)9, 4 (2015), 336–347. https://doi. org/10.14778/2856318.2856328
-
[3]
Ilyas, Mourad Ouzzani, Paolo Papotti, Michael Stonebraker, and Nan Tang
Ziawasch Abedjan, Xu Chu, Dong Deng, Raul Castro Fernandez, Ihab F. Ilyas, Mourad Ouzzani, Paolo Papotti, Michael Stonebraker, and Nan Tang. 2016. De- tecting Data Errors: Where are we and what needs to be done?Proceedings of the VLDB Endowment (PVLDB)9, 12 (2016), 993–1004. https://doi.org/10.14778/ 2994509.2994518
arXiv 2016
-
[4]
Arocena, Boris Glavic, Giansalvatore Mecca, Renée J
Patricia C. Arocena, Boris Glavic, Giansalvatore Mecca, Renée J. Miller, Paolo Papotti, and Donatello Santoro. 2015. Messing Up with BART: Error Generation for Evaluating Data-Cleaning Algorithms.Proceedings of the VLDB Endowment (PVLDB)9, 2 (2015), 36–47. https://doi.org/10.14778/2850578.2850579
-
[5]
Christopher Barrington-Leigh and Adam Millard-Ball. 2017. The World’s User- Generated Road Map Is More Than 80% Complete.PLOS ONE12, 8 (2017), e0180698. https://doi.org/10.1371/journal.pone.0180698
-
[6]
Divya Bhadauria, Hazar Harmouch, Felix Naumann, Divesh Srivastava, and Lisa Ehrlinger. 2026. A Catalog of Data Errors.CoRRabs/2604.09277 (2026). https://doi.org/10.48550/ARXIV.2604.09277 arXiv:2604.09277
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09277 2026
-
[7]
Felix Bießmann, Tammo Rukat, Philipp Schmidt, Prathik Naidu, Sebastian Schel- ter, Andrey Taptunov, Dustin Lange, and David Salinas. 2019. DataWig: Missing Value Imputation for Tables.Journal of Machine Learning Research (JMLR)20, Article 175 (2019), 6 pages. https://jmlr.org/papers/v20/18-753.html
2019
-
[8]
Alexander Brinkmann, Anna Primpeli, and Christian Bizer. 2023. The Web Data Commons Schema.org Data Set Series. InCompanion Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, Ying Ding, Jie Tang, Juan F. Sequeda, Lora Aroyo, Carlos Castillo, and Geert-Jan Houben (Eds.). ACM, 136–139. https://doi.org/10.1145/...
-
[9]
Xu Chu, Ihab F. Ilyas, and Paolo Papotti. 2013. Holistic Data Cleaning: Putting Violations Into Context. InProceedings of the IEEE International Conference on Data Engineering (ICDE). 458–469. https://doi.org/10.1109/ICDE.2013.6544847
-
[10]
Fred Damerau. 1964. A Technique for Computer Detection and Correction of Spelling Errors.Communications of the ACM (CACM)7, 3 (1964), 171–176. https://doi.org/10.1145/363958.363994
-
[11]
Edith Desiree de Leeuw. 1992. Data Quality in Mail, Telephone and Face to Face Surveys. https://eric.ed.gov/?id=ED374136
1992
-
[12]
Xiaoou Ding, Zekai Qian, Hongzhi Wang, Siying Chen, Yafeng Tang, Hongbin Su, Huan Hu, and Chen Wang. 2025. UniClean: A Scalable Data Cleaning Solution for Mixed Errors based on Unified Cleaners and Optimized Cleaning Workflow.Proceedings of the VLDB Endowment (PVLDB)18, 11 (2025), 4117–4130. https://doi.org/10.14778/3749646.3749681
-
[13]
Anna-Christina Glock, Christine Dominka-Kiss, Philipp Korom, and Lisa Ehrlinger. 2025. Detecting and Cleaning Errors in Personal Contact Information with Large Language Models.Proceedings of the VLDB Endowment (PVLDB) (2025)
2025
-
[14]
Jean-Nicholas Hould. 2017. Craft Beers Dataset. https://www.kaggle.com/ nickhould/craft-cans. Version 1
2017
-
[15]
Ykä Huhtala, Juha Kärkkäinen, Pasi Porkka, and Hannu Toivonen. 1999. TANE: An Efficient Algorithm for Discovering Functional and Approximate Dependen- cies.Comput. J.42, 2 (1999), 100–111. https://doi.org/10.1093/COMJNL/42.2.100
-
[16]
Philipp Jung, Sebastian Jäger, Nicholas Chandler, and Felix Biessmann. 2025. Towards Realistic Error Models for Tabular Data.ACM J. Data Inf. Qual.17, 4 (2025), 28:1–28:27. https://doi.org/10.1145/3774914
-
[17]
Bojan Karlas, Peng Li, Renzhi Wu, Nezihe Merve Gürel, Xu Chu, Wentao Wu, and Ce Zhang. 2020. Nearest Neighbor Classifiers over Incomplete Information: From Certain Answers to Certain Predictions.Proceedings of the VLDB Endowment (PVLDB)14, 3 (2020), 255–267. https://doi.org/10.14778/3430915.3430917
-
[18]
Levenshtein
Vladimir I. Levenshtein. 1966. Binary Codes Capable of Correcting Deletions, Insertions, and Reversals.Soviet Physics Doklady10, 8 (1966), 707–710
1966
-
[19]
Peng Li, Xi Rao, Jennifer Blase, Yue Zhang, Xu Chu, and Ce Zhang. 2021. CleanML: A Study for Evaluating the Impact of Data Cleaning on ML Classification Tasks. InProceedings of the IEEE International Conference on Data Engineering (ICDE). https://doi.org/10.1109/ICDE51399.2021.00009
-
[20]
Xian Li, Xin Luna Dong, Kenneth Lyons, Weiyi Meng, and Divesh Srivastava
-
[21]
https://doi.org/10.14778/2535568
Truth Finding on the Deep Web: Is the Problem Solved?Proceedings of the VLDB Endowment (PVLDB)6, 2 (2012), 97–108. https://doi.org/10.14778/2535568. 2448943
-
[22]
Yi Li and Gao Cong. 2025. GeoBloom: Revisiting Lightweight Models for Geo- graphic Information Retrieval.Proceedings of the VLDB Endowment (PVLDB)18, 5 (2025), 1348–1361. https://doi.org/10.14778/3718057.3718064
-
[23]
Yiding Liu, Tuan-Anh Nguyen Pham, Gao Cong, and Quan Yuan. 2017. An Experimental Evaluation of Point-of-interest Recommendation in Location-based Social Networks.Proceedings of the VLDB Endowment (PVLDB)10, 10 (2017), 1010–1021. https://doi.org/10.14778/3115404.3115407
-
[24]
Mohammad Mahdavi and Ziawasch Abedjan. 2020. Baran: Effective Error Correction via a Unified Context Representation and Transfer Learning.Pro- ceedings of the VLDB Endowment (PVLDB)13, 11 (2020), 1948–1961. https: //doi.org/10.14778/3407790.3407801
-
[25]
Mohammad Mahdavi, Ziawasch Abedjan, Raul Castro Fernandez, Samuel Mad- den, Mourad Ouzzani, Michael Stonebraker, and Nan Tang. 2019. Raha: A Configuration-Free Error Detection System. InProceedings of the ACM In- ternational Conference on Management of Data (SIGMOD). 865–882. https: //doi.org/10.1145/3299869.3324956
-
[26]
Sedir Mohammed, Lukas Budach, Moritz Feuerpfeil, Nina Ihde, Andrea Nathansen, Nele Sina Noack, Hendrik Patzlaff, Felix Naumann, and Hazar Har- mouch. 2025. The effects of data quality on machine learning performance on tabular data.Information Systems132, Article 102549 (2025), 18 pages. https://doi.org/10.1016/j.is.2025.102549
-
[27]
Sedir Mohammed, Lisa Ehrlinger, Hazar Harmouch, Felix Naumann, and Divesh Srivastava. 2025. The Five Facets of Data Quality Assessment.ACM SIGMOD Record54, 2 (2025), 18–27. https://doi.org/10.1145/3749116.3749120
-
[28]
Wei Ni, Xiaoye Miao, Xiangyu Zhao, Yangyang Wu, Shuwei Liang, and Jianwei Yin. 2024. Automatic Data Repair: Are We Ready to Deploy?Proceedings of the VLDB Endowment (PVLDB)17, 10 (2024), 2617–2630. https://doi.org/10.14778/ 3675034.3675051
arXiv 2024
-
[29]
Wei Ni, Kaihang Zhang, Xiaoye Miao, Xiangyu Zhao, Yangyang Wu, Yaoshu Wang, and Jianwei Yin. 2025. ZeroED: Hybrid Zero-Shot Error Detection Through Large Language Model Reasoning. In41st IEEE International Conference on Data Engineering, ICDE 2025, Hong Kong, May 19-23, 2025. IEEE, 3126–3139. https: //doi.org/10.1109/ICDE65448.2025.00234
-
[30]
Mourad Ouzzani, Hossam Hammady, Zbys Fedorowicz, and Ahmed Elmagarmid
-
[31]
https://doi.org/10.1186/s13643-016-0384-4
Rayyan—a web and mobile app for systematic reviews.Systematic Reviews 5, Article 210 (2016), 10 pages. https://doi.org/10.1186/s13643-016-0384-4
-
[32]
Theodoros Rekatsinas, Xu Chu, Ihab F. Ilyas, and Christopher Ré. 2017. Holo- Clean: Holistic Data Repairs with Probabilistic Inference.Proceedings of the VLDB Endowment (PVLDB)10, 11 (2017), 1190–1201. https://doi.org/10.14778/ 3137628.3137631
arXiv 2017
-
[33]
Valerie Restat, Gerrit Boerner, André Conrad, and Uta Störl. 2022. GouDa - Generation of universal Data Sets: Improving Analysis and Evaluation of Data Preparation Pipelines. InProceedings of the Workshop on Data Management for End-To-End Machine Learning (DEEM). Article 2, 6 pages. https://doi.org/10. 1145/3533028.3533311
arXiv 2022
-
[34]
Aref, Ahmed K
El Kindi Rezig, Mourad Ouzzani, Walid G. Aref, Ahmed K. Elmagarmid, Ahmed R. Mahmood, and Michael Stonebraker. 2021. Horizon: Scalable Dependency-driven Data Cleaning.Proceedings of the VLDB Endowment (PVLDB)14, 11 (2021), 2546–
2021
-
[35]
https://doi.org/10.14778/3476249.3476301
-
[36]
Sebastian Schelter, Tammo Rukat, and Felix Biessmann. 2021. JENGA - A Frame- work to Study the Impact of Data Errors on the Predictions of Machine Learning Models. InProceedings of the International Conference on Extending Database Technology (EDBT). 529–534. https://doi.org/10.5441/002/edbt.2021.63
-
[37]
Shafaq Siddiqi, Roman Kern, and Matthias Boehm. 2023. SAGA: A Scalable Framework for Optimizing Data Cleaning Pipelines for Machine Learning Ap- plications.Proceedings of the ACM on Management of Data (PACMMOD)1, 3, Article 218 (2023), 26 pages. https://doi.org/10.1145/3617338
-
[38]
Jasmin Singh and Heiko Gebauer. 2024. Clean Customer Master Data for Cus- tomer Analytics: A Neglected Element of Data Monetization.Digital4, 4 (2024), 1020–1038. https://doi.org/10.3390/digital4040051
-
[39]
Nishant Subramani, Sasha Luccioni, Jesse Dodge, and Margaret Mitchell. 2023. Detecting Personal Information in Training Corpora: an Analysis. InProceedings of the Workshop on Trustworthy Natural Language Processing (TrustNLP). 208–220. https://doi.org/10.18653/v1/2023.trustnlp-1.18
-
[40]
The Unicode Consortium. 2024. The Unicode Standard, Version 15.1. https: //www.unicode.org/versions/Unicode15.1.0/
2024
-
[41]
United States Postal Service. 2014. Undeliverable as Addressed Mail. https: //www.uspsoig.gov/reports/audit-reports/undeliverable-addressed-mail
2014
-
[42]
Yangyang Wu, Chen Yang, Mengying Zhu, Xiaoye Miao, Wei Ni, Meng Xi, Xinkui Zhao, and Jianwei Yin. 2025. A Zero-Training Error Correction System with Large Language Models. InProceedings of the IEEE International Conference on Data Engineering (ICDE). 2949–2962. https://doi.org/10.1109/ICDE65448.2025.00221 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.