CQC-RAG: Robust Retrieval-Augmented Generation via Cross-Query Consistency
Pith reviewed 2026-06-27 05:34 UTC · model grok-4.3
The pith
CQC-RAG filters hallucinations in retrieval-augmented generation by checking whether candidate answers keep stable high confidence across syntactically varied but meaning-equivalent queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
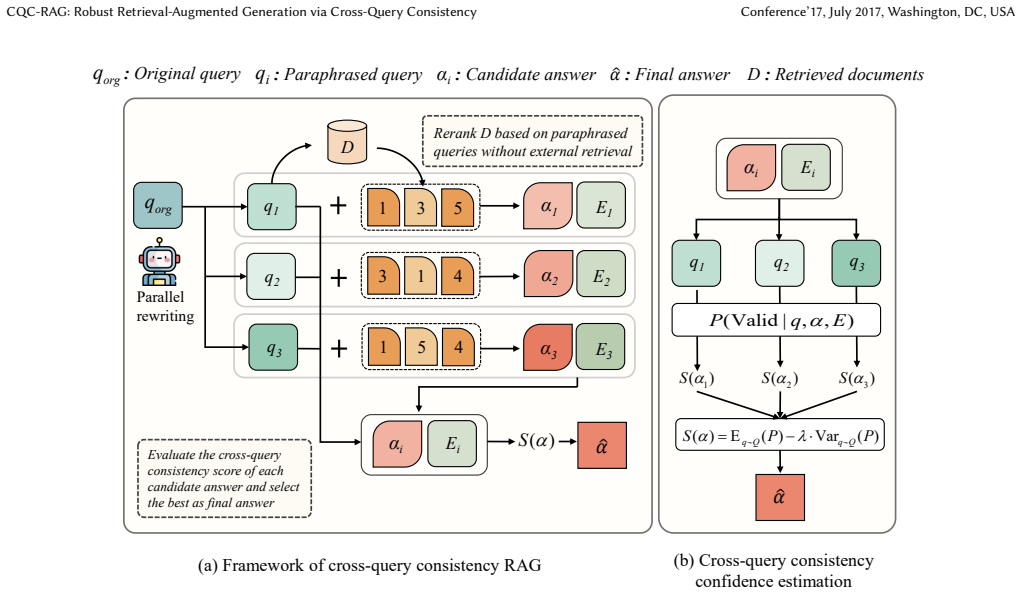
The Cross-Query Consistency Hypothesis states that correct answers maintain high confidence across semantically equivalent but syntactically diverse queries, whereas noise-induced hallucinations exhibit unstable confidence under such query variations. CQC-RAG operationalizes the hypothesis by rewriting the original question, reranking a shared document pool to form query-conditioned contexts, applying an evidence-grounded extraction protocol, and selecting the answer with the most stable confidence across those contexts, thereby performing self-evaluation without external supervision or expanded retrieval.
What carries the argument
The Cross-Query Consistency Hypothesis together with the co-designed pipeline of query rewriting, shared-pool reranking, evidence-grounded pair extraction, and stability-based selection.
If this is right
- Multi-query RAG no longer needs external voting or expanded retrieval sets; internal consistency across query variants suffices for selection.
- The same consistency signal can be used to reject answers that are unstable even when they appear confident on the original query.
- The method works on existing LLMs without additional training or supervision.
- Gains appear on both single-hop (TriviaQA) and multi-hop (MuSiQue) datasets, suggesting the mechanism is not limited to one reasoning depth.
Where Pith is reading between the lines
- If the hypothesis holds, the same stability check could be applied to chain-of-thought traces or tool-use sequences to detect internal contradictions.
- The approach might be combined with retrieval re-ranking that explicitly favors documents supporting multiple query variants.
- A practical deployment could cache the rewritten queries and their contexts so that repeated similar questions incur little extra cost.
Load-bearing premise
That an answer which is factually correct will reliably produce higher and more stable model confidence when the question is rephrased in different syntactic forms.
What would settle it
A controlled test in which known correct answers are shown to drop in confidence or change identity when the input question is rewritten into semantically equivalent variants while keeping the retrieved evidence fixed.
Figures
read the original abstract
Retrieval-Augmented Generation (RAG) has become a common approach for improving the factuality of Large Language Models (LLMs), yet its reliability remains highly sensitive to how external evidence is retrieved and used. Semantically equivalent queries with different syntactic forms may lead to different retrieval results, while irrelevant or misleading documents can further induce hallucinated answers. Existing multi-path reasoning methods improve robustness by sampling multiple candidate answers and applying voting- or confidence-based selection, but they still face two limitations: diversity is often injected through uncontrollable decoding randomness, and answer evaluation is usually confined to a single query-induced evidence view. To address these limitations, we propose a Cross-Query Consistency Hypothesis: correct answers tend to maintain high confidence across semantically equivalent but syntactically diverse queries, whereas noise-induced hallucinations exhibit unstable confidence under such query variations. Based on this hypothesis, we introduce CQC-RAG, a framework that co-designs query-level diversity injection with cross-query consistency evaluation. CQC-RAG rewrites the original question into diverse but meaning-preserving queries, reranks a shared document pool to construct query-conditioned reasoning contexts, applies an evidence-grounded protocol to extract answer-evidence pairs and selects answers according to their confidence stability across these contexts. This design enables self-evaluation without external supervision and does not rely on expanded retrieval coverage. Experiments on four open-domain question answering benchmarks show that CQC-RAG outperforms the strongest previous multi-query baseline by +4.76 pp EM on TriviaQA and +9.12 pp EM on MuSiQue, validating the effectiveness of cross-query consistency for filtering noise-induced hallucinations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Cross-Query Consistency Hypothesis—that correct answers maintain stable high confidence across syntactically diverse but semantically equivalent queries, while hallucinations induced by noise exhibit unstable confidence—and introduces the CQC-RAG framework that implements this via query rewriting for diversity, shared-pool reranking, evidence-grounded answer extraction, and selection by cross-query confidence stability. It reports empirical gains of +4.76 pp EM on TriviaQA and +9.12 pp EM on MuSiQue over the strongest prior multi-query baseline, claiming validation of the hypothesis on four open-domain QA benchmarks without external supervision or expanded retrieval.
Significance. If the reported gains are attributable to the consistency-based filtering mechanism rather than query diversity alone, the work would offer a practical self-evaluation approach for improving RAG factuality. The co-design of diversity injection and stability evaluation addresses a recognized limitation in existing multi-path methods, but the absence of direct hypothesis tests limits the assessed impact to incremental empirical improvement pending further validation.
major comments (1)
- [Abstract] Abstract: The central claim that the results validate the Cross-Query Consistency Hypothesis rests on aggregate EM improvements (+4.76 pp on TriviaQA, +9.12 pp on MuSiQue) versus a multi-query baseline. No direct measurements (e.g., confidence stability distributions or variance statistics conditioned on answer correctness) or ablations that isolate the consistency filter from query rewriting and reranking are described, leaving open the possibility that gains arise from increased query diversity alone.
minor comments (1)
- [Abstract] Abstract: The text states experiments on four benchmarks but reports detailed gains only for TriviaQA and MuSiQue; the results for the remaining two benchmarks should be summarized for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the results validate the Cross-Query Consistency Hypothesis rests on aggregate EM improvements (+4.76 pp on TriviaQA, +9.12 pp on MuSiQue) versus a multi-query baseline. No direct measurements (e.g., confidence stability distributions or variance statistics conditioned on answer correctness) or ablations that isolate the consistency filter from query rewriting and reranking are described, leaving open the possibility that gains arise from increased query diversity alone.
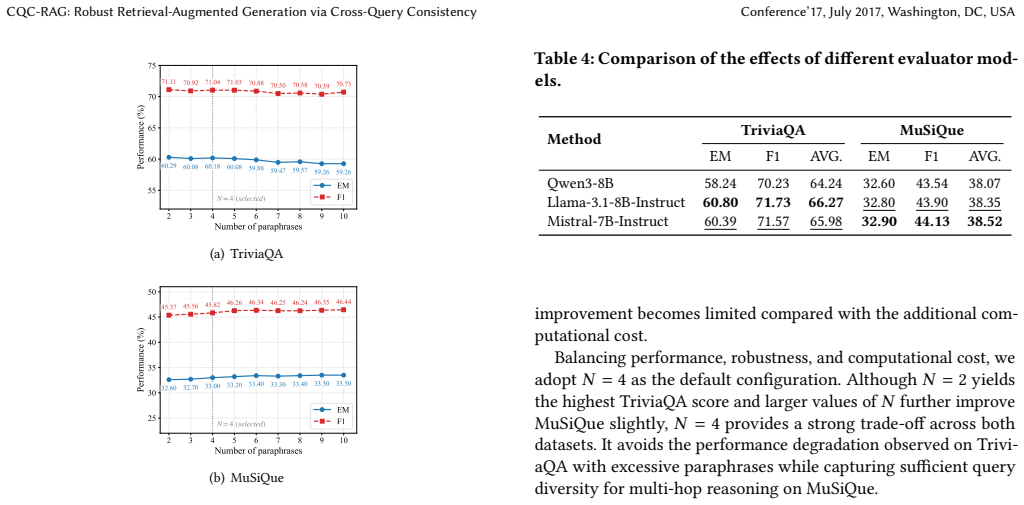
Authors: We appreciate the referee's observation. The strongest prior multi-query baseline already incorporates query diversity through multiple paths, so the reported gains over this baseline are attributable to the addition of cross-query consistency filtering rather than diversity alone. That said, we agree that direct measurements (such as confidence stability distributions and variance statistics conditioned on answer correctness) and an ablation isolating the consistency filter would provide stronger, more explicit support for the hypothesis. In the revised version we will add these analyses, including the requested statistics and ablation, and will adjust the abstract to reflect the expanded evidence. revision: yes
Circularity Check
No circularity: empirical hypothesis and benchmark evaluation remain independent
full rationale
The paper states the Cross-Query Consistency Hypothesis explicitly as a new premise, then describes a co-designed framework (query rewriting, reranking, consistency-based selection) whose effectiveness is measured by end-to-end EM gains on TriviaQA and MuSiQue. No equations, fitted parameters, or self-referential definitions appear that would make any reported quantity equivalent to its inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is therefore self-contained against external benchmarks and does not reduce to tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Correct answers tend to maintain high confidence across semantically equivalent but syntactically diverse queries, whereas noise-induced hallucinations exhibit unstable confidence under such query variations.
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
2024
-
[2]
Tianyu Cao, Neel Bhandari, Akhila Yerukola, Akari Asai, and Maarten Sap. 2026. Out of Style: RAG’s Fragility to Linguistic Variation. InProceedings of the 19th CQC-RAG: Robust Retrieval-Augmented Generation via Cross-Query Consistency Conference’17, July 2017, Washington, DC, USA Conference of the European Chapter of the Association for Computational Lin-...
2026
-
[3]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[4]
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation.CoRRabs/2402.03216 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[6]
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. InAdvances in Neural Information Processing Systems 38: An- nual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[7]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave
-
[8]
Atlas: Few-shot Learning with Retrieval Augmented Language Models.J. Mach. Learn. Res.24 (2023), 251:1–251:43
2023
-
[9]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
-
[10]
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024. 7036–7050
2024
-
[11]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.CoRRabs/2310.06...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Weld, and Luke Zettlemoyer
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehen- sion. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers. 1601–1611
2017
- [13]
- [14]
-
[15]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information...
2020
- [16]
- [17]
-
[18]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-1...
2023
-
[19]
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. 2025. Confidence Improves Self-Consistency in LLMs. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025. 20090–20111
2025
-
[20]
Llama Team. 2024. The Llama 3 Herd of Models.CoRRabs/2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Hieu Tran, Zonghai Yao, Zhichao Yang, Junda Wang, Yifan Zhang, Shuo Han, Feiyun Ouyang, and Hong Yu. 2025. RARE: Retrieval-Augmented Reasoning Enhancement for Large Language Models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025. 18305–18330
2025
-
[22]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[23]
MuSiQue: Multihop Questions via Single-hop Question Composition.Trans. Assoc. Comput. Linguistics10 (2022), 539–554
2022
-
[24]
Weiqin Wang, Yile Wang, and Hui Huang. 2025. Ranked Voting based Self- Consistency of Large Language Models. InFindings of the Association for Compu- tational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025. 14410– 14426
2025
-
[25]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023
2023
-
[26]
Le, Huaixiu Steven Zheng, Swaroop Mishra, Vincent Perot, Yuwei Zhang, Anush Mattapalli, Ankur Taly, Jingbo Shang, Chen- Yu Lee, and Tomas Pfister
Zilong Wang, Zifeng Wang, Long T. Le, Huaixiu Steven Zheng, Swaroop Mishra, Vincent Perot, Yuwei Zhang, Anush Mattapalli, Ankur Taly, Jingbo Shang, Chen- Yu Lee, and Tomas Pfister. 2025. Speculative RAG: Enhancing Retrieval Aug- mented Generation through Drafting. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore,...
2025
-
[27]
Siye Wu, Jian Xie, Jiangjie Chen, Tinghui Zhu, Kai Zhang, and Yanghua Xiao
- [28]
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
-
[31]
Yuxin Yang, Gangda Deng, Ömer Faruk Akgül, Nima Chitsazan, Yash Govilkar, Akasha Tigalappanavara, Shi-Xiong Zhang, Sambit Sahu, and Viktor Prasanna
- [32]
-
[33]
Fabbri, Gabriel Bernadett- Shapiro, Rui Zhang, Prasenjit Mitra, Caiming Xiong, and Chien-Sheng Wu
Nan Zhang, Prafulla Kumar Choubey, Alexander R. Fabbri, Gabriel Bernadett- Shapiro, Rui Zhang, Prasenjit Mitra, Caiming Xiong, and Chien-Sheng Wu. 2025. SiReRAG: Indexing Similar and Related Information for Multihop Reasoning. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
2025
-
[34]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.