crossfit: A Graph-Based Cross-Fitting Engine in R
Pith reviewed 2026-05-19 18:03 UTC · model grok-4.3
pith:OE3BD6IU Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{OE3BD6IU}
Prints a linked pith:OE3BD6IU badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
The crossfit R package provides a general-purpose cross-fitting engine using user-specified DAGs of nuisance models with custom fold allocations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
crossfit is a software tool that executes cross-fitting by traversing a user-defined DAG of nuisance models, applying node-specific fold widths for training and target-specific windows for evaluation, while enforcing out-of-sample use to support valid semiparametric inference such as in double/debiased machine learning. The package returns either a scalar estimate or a cross-fitted predictor function and includes explicit scheduling, reuse-aware caching, and failure isolation.
What carries the argument
Directed acyclic graph (DAG) of nuisance models with node-specific training fold widths and target-specific evaluation windows, executed by the engine's scheduler and caching logic to generate cross-fitted outputs without data leakage.
If this is right
- Enables valid estimation of low-dimensional targets amid high-dimensional nuisance functions by enforcing out-of-sample predictions.
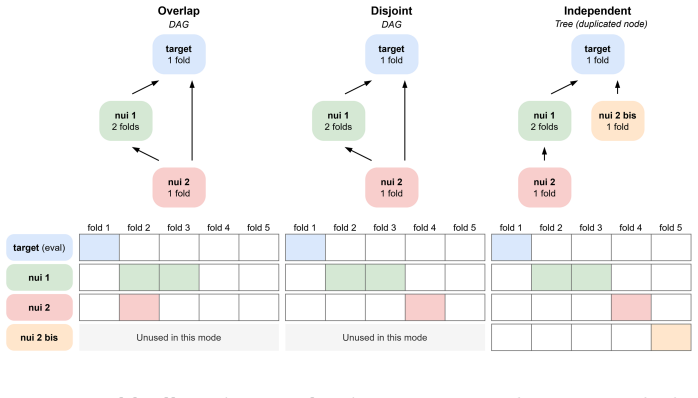
- Allows precise control of dependence between nuisance components via disjoint and independence-enforcing allocation modes that duplicate reused nodes.
- Delivers explicit and auditable fold schedules suitable for simulation-heavy benchmarking and method development.
- Provides reuse-aware caching and failure isolation to support efficient execution over large experiment grids.
Where Pith is reading between the lines
- The DAG-based specification of fold geometry could be used to empirically measure how different dependence structures affect finite-sample variance of cross-fitted estimators.
- This design may be adapted to other languages or ML libraries to create consistent cross-fitting backends for causal inference pipelines.
- Explicit caching rules could reduce redundant computation when testing many variants of the same target functional.
Load-bearing premise
The package's internal scheduler and caching logic correctly execute the user-specified DAG and fold-allocation rules without introducing unintended data leakage or dependence between nuisance branches.
What would settle it
Run a simulation using the independence-enforcing mode on models known to share data and check whether nuisance predictions from different branches show zero correlation on held-out evaluation data.
Figures
read the original abstract
Cross-fitting is a key ingredient in many semiparametric estimation procedures, such as double/debiased machine learning (DML), enabling valid estimation of low-dimensional targets in the presence of high-dimensional nuisance functions by enforcing out-of-sample use of nuisance predictions. crossfit is an R package that provides a general-purpose, estimator-agnostic cross-fitting engine. Users specify (i) a target functional and (ii) a directed acyclic graph (DAG) of nuisance models, with node-specific training fold widths and target-specific evaluation windows. The engine executes a reproducible schedule over folds, panels, and repetitions, returning either a scalar estimate (mode="estimate") or a cross-fitted predictor function for application to new data (mode="predict"). Beyond standard cross-fitting, crossfit implements fold-allocation modes that control how training data are shared across nuisance components, including disjoint and independence-enforcing allocations that duplicate reused nodes to reduce dependence between nuisance branches. The implementation targets simulation-heavy benchmarking and method development, with explicit and auditable schedules, defensive validation of specifications and nuisance dependencies, reuse-aware caching to avoid redundant refits, and failure isolation policies for large experiment grids. The crossfit package is available on CRAN, openly developed on GitHub under GPL-3, and is intended as a lightweight, tested foundation to prototype and empirically evaluate cross-fitted estimators with explicit control over fold geometry, dependence, and computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the crossfit R package as a general-purpose, estimator-agnostic cross-fitting engine for semiparametric procedures such as double/debiased machine learning. Users specify a target functional together with a directed acyclic graph (DAG) of nuisance models, including node-specific training fold widths and target-specific evaluation windows. The engine runs reproducible schedules over folds, panels, and repetitions and returns either a scalar estimate (mode='estimate') or a cross-fitted predictor (mode='predict'). It additionally implements fold-allocation modes, notably disjoint and independence-enforcing allocations that duplicate reused nodes to reduce dependence between nuisance branches, together with caching, defensive validation, and failure-isolation features aimed at simulation-heavy benchmarking.
Significance. If the scheduler and caching logic correctly realize the claimed independence-enforcing duplication without introducing data leakage, the package would supply a lightweight, auditable foundation for prototyping and empirically evaluating cross-fitted estimators in R. Explicit control over fold geometry, dependence structure, and computational reuse would be particularly valuable for simulation studies and method development; the CRAN availability and open GitHub development further support reproducibility.
major comments (1)
- [Abstract] Abstract: the claim that independence-enforcing allocations 'duplicate reused nodes to reduce dependence between nuisance branches' is load-bearing for the out-of-sample guarantee that justifies the entire construction. The manuscript describes the intended behavior and defensive validation but supplies neither pseudocode for the scheduler, an invariant statement on cache keys under duplication, nor unit-test results confirming that shared cache entries or fold indices do not create unintended leakage between branches.
minor comments (1)
- The abstract would benefit from a concise, self-contained usage snippet showing how a simple DAG and mode are specified.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and for emphasizing the centrality of the independence-enforcing allocation mechanism. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that independence-enforcing allocations 'duplicate reused nodes to reduce dependence between nuisance branches' is load-bearing for the out-of-sample guarantee that justifies the entire construction. The manuscript describes the intended behavior and defensive validation but supplies neither pseudocode for the scheduler, an invariant statement on cache keys under duplication, nor unit-test results confirming that shared cache entries or fold indices do not create unintended leakage between branches.
Authors: We agree that the independence-enforcing duplication is central to the validity claim and that the current manuscript would be strengthened by explicit technical documentation. In the revised version we will add (i) pseudocode for the scheduler’s duplication logic in a new appendix, (ii) a precise invariant stating that cache keys are formed from the tuple (node_id, fold_id, duplication_tag) so that duplicated nodes receive distinct keys, and (iii) a concise report of unit-test results that verify no shared cache hits or fold-index collisions occur between branches. These additions will be placed in supplementary material to preserve the main text’s brevity while directly addressing the concern. revision: yes
Circularity Check
No derivation chain or fitted predictions present; software implementation is self-contained
full rationale
The manuscript describes an R package implementing cross-fitting over user-specified DAGs of nuisance models, with modes for fold allocation and caching. No equations, first-principles derivations, predictions of new quantities, or parameter fits are claimed. The central contribution is the engine's execution of user-defined schedules and independence rules; its correctness is evaluated against external benchmarks (CRAN tests, GitHub code, simulation use cases) rather than reducing to self-referential definitions or self-citations. No load-bearing step matches any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bickel PJ. On Adaptive Estimation. The Annals of Statistics. 1982;10(3):647-71. Available from:https://doi.org/10.1214/aos/ 1176345863
-
[2]
The Annals of Statistics , volume =
Schick A. On Asymptotically Efficient Estimation in Semiparametric Models. The Annals of Statistics. 1986;14(3):1139-51. Available from: https://doi.org/10.1214/aos/1176350055
-
[3]
Cross-Validated Targeted Minimum- Loss-Based Estimation
Zheng W, van der Laan MJ. Cross-Validated Targeted Minimum- Loss-Based Estimation. In: Targeted Learning: Causal Inference for Observational and Experimental Data. New York, NY: Springer New York; 2011. p. 459-74. Available from:https://doi.org/10.1007/ 978-1-4419-9782-1_27
work page 2011
-
[4]
Cross-Fitting and Fast Remainder Rates for Semiparametric Estimation
Newey WK, Robins JR. Cross-Fitting and Fast Remainder Rates for Semiparametric Estimation. arXiv preprint arXiv:180109138. 2018. Available from:https://arxiv.org/abs/1801.09138. 15
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
The Econometrics Journal , volume =
Chernozhukov V, Chetverikov D, Demirer M, Duflo E, Hansen C, Newey W, et al. Double/debiased machine learning for treatment and struc- tural parameters. The Econometrics Journal. 2018;21(1):C1-C68. Avail- able from:https://doi.org/10.1111/ectj.12097
-
[6]
Orthogonal statistical learning
Foster DJ, Syrgkanis V. Orthogonal statistical learning. The Annals of Statistics. 2023;51(3):879-908. Available from:https://doi.org/10. 1214/23-AOS2258
work page 2023
-
[7]
Bouvier F, Peyrot E, Balendran A, Ségalas C, Roberts I, Petit F, et al. Do machine learning methods lead to similar individualized treat- ment rules? A comparison study on real data. Statistics in Medicine. 2024;43(11):2043-61. Available from:https://doi.org/10.1002/sim. 10059
work page doi:10.1002/sim 2024
-
[8]
DoubleML: An Object-Oriented Implementation of Double Machine Learning in R
BachP,KurzMS,ChernozhukovV,SpindlerM,KlaassenS. DoubleML: An Object-Oriented Implementation of Double Machine Learning in R. Journal of Statistical Software. 2024;108(3):1-56. Available from: https://www.jstatsoft.org/article/view/v108i03
work page 2024
-
[9]
Meta-Learners for Estimation of Causal Effects: Finite Sam- ple Cross-Fit Performance
Okasa G. Meta-Learners for Estimation of Causal Effects: Finite Sam- ple Cross-Fit Performance. arXiv. 2022. ArXiv:2201.12692 [econ.EM]. Available from:https://arxiv.org/abs/2201.12692
-
[10]
Ellul S, Vansteelandt S, Carlin JB, Moreno-Betancur M. Causal Ma- chine Learning Methods and Use of Cross-Fitting in Settings With High-Dimensional Confounding. Statistics in Medicine. 2025;44(20– 22):e70272. Available from:https://doi.org/10.1002/sim.70272
-
[11]
Double Cross-fit Doubly Robust Estimators: Beyond Series Regression
McClean A, Balakrishnan S, Kennedy EH, Wasserman L. Double Cross-fit Doubly Robust Estimators: Beyond Series Regression. arXiv preprint arXiv:240315175. 2024. Available from:https://arxiv.org/ abs/2403.15175
-
[12]
Fisher A, Fisher V. Three-way Cross-Fitting and Pseudo-Outcome Regression for Estimation of Conditional Effects and other Linear Functionals. arXiv preprint arXiv:230607230. 2023. Available from: https://arxiv.org/abs/2306.07230
-
[13]
Doubly Robust Triple Cross-Fit Es- timation for Causal Inference with Imaging Data
Ke D, Zhou X, Yang Q, Song X. Doubly Robust Triple Cross-Fit Es- timation for Causal Inference with Imaging Data. Statistics in Bio- sciences. 2024. Online first. Available from:https://doi.org/10. 1007/s12561-024-09458-1. 16
work page 2024
-
[14]
Journal of Business & Economic Statistics , volume =
Chiang HD, Kato K, Ma Y, Sasaki Y. Multiway Cluster Robust Dou- ble/DebiasedMachineLearning. JournalofBusiness&EconomicStatis- tics. 2022;40(3):1046-56. Available from:https://doi.org/10.1080/ 07350015.2021.1895815
-
[15]
Zivich PN, Breskin A. Machine Learning for Causal Inference: On the Use of Cross-fit Estimators. Epidemiology. 2021;32(3):393-401. Avail- able from:https://doi.org/10.1097/EDE.0000000000001332. A Recipe: DML for the partially linear regression model Thisappendixgivesacomplete, self-containedexampleofaDouble/Debiased MachineLearning(DML)estimatorforthePart...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.