SWAP: Symmetric Equivariant World-Model for Agile Robot Parkour
Pith reviewed 2026-06-26 17:00 UTC · model grok-4.3
The pith
Embedding left-right symmetry directly into a robot world model and policies enables record parkour leaps and climbs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
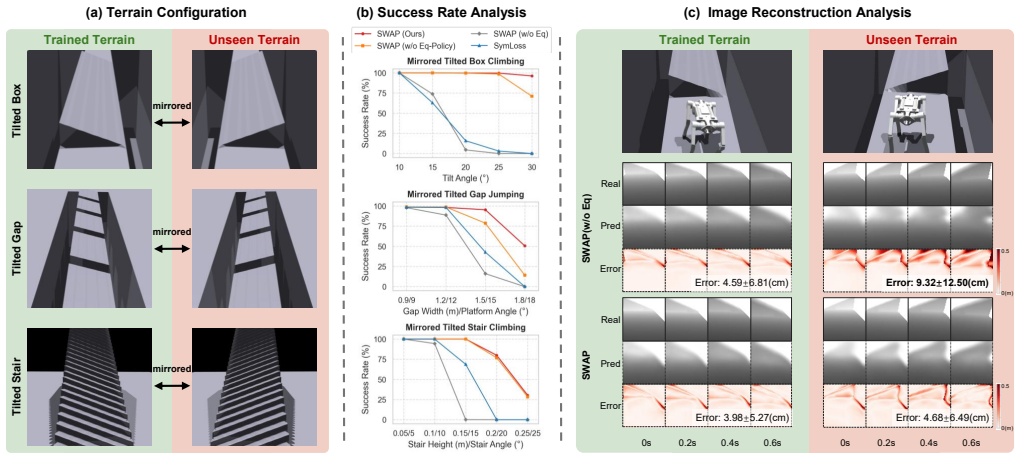
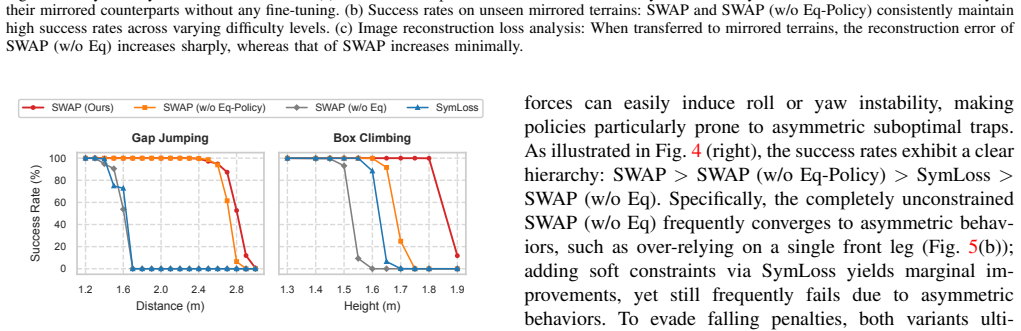
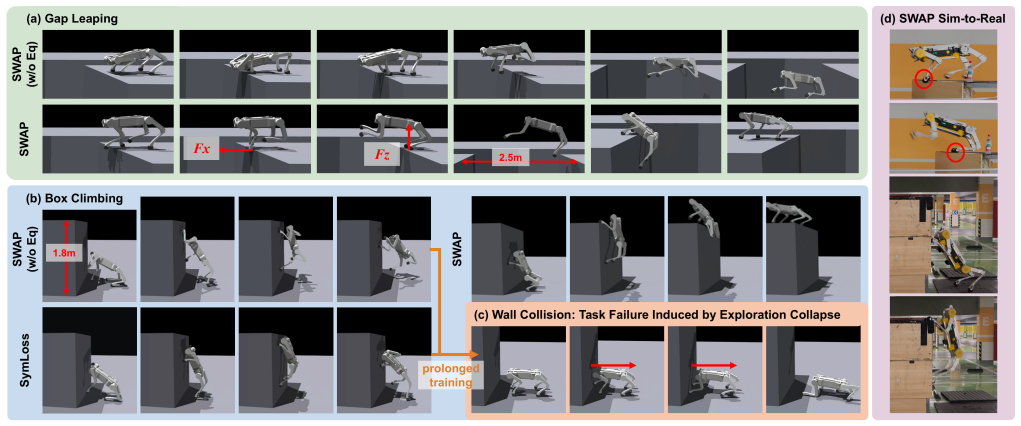
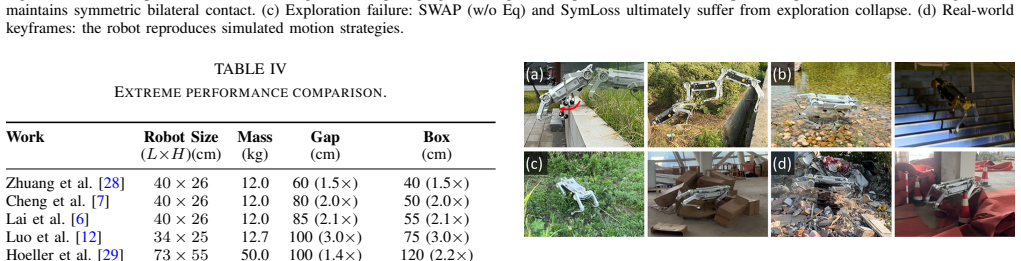
The SWAP framework embeds symmetry equivariance directly into both the world model and the actor-critic networks, allowing the robot to leap a 2.13 m gap and climb a 1.63 m platform while showing robust generalization to unseen mirrored terrains and zero-shot transfer across outdoor environments.
What carries the argument
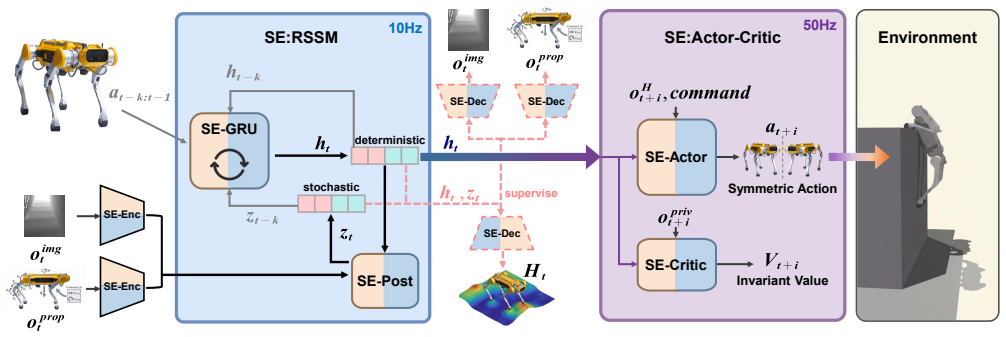
The SWAP symmetric equivariant world model, which enforces left-right symmetry in latent dynamics predictions and control policies.
If this is right
- The robot reaches higher physical performance limits than prior data-driven methods on the same hardware.
- Generalization to mirrored obstacle layouts occurs without retraining or additional data.
- Zero-shot transfer succeeds across diverse outdoor environments.
- Symmetry reduces redundant encoding of bilateral interactions in the latent space.
Where Pith is reading between the lines
- The same symmetry prior could be added to other bilateral robot tasks such as manipulation or bipedal walking.
- Training data requirements for agile behaviors may decrease because symmetric features are learned once.
- The approach could be combined with other geometric priors to further compress the latent representation.
Load-bearing premise
That directly embedding symmetry into the world model and actor-critic networks captures all necessary geometric regularities without discarding asymmetric information required for stable control.
What would settle it
Training an otherwise identical non-equivariant world model on the same data and checking whether it matches the 2.13 m gap and 1.63 m climb distances plus mirrored-terrain robustness.
Figures

read the original abstract
While latent world models enable the proactive predictions required for extreme parkour, their purely data-driven nature forces them to redundantly encode left-right symmetric interactions as independent patterns. This inflates the learning burden and hinders the capture of geometric regularities, restricting the latent space's efficiency for downstream policies. To address this, we propose SWAP, an end-to-end equivariant symmetric world model. This framework embeds symmetry directly into both the world model and the actor-critic networks. In real-world tests, the robot leaps across a 2.13 m gap and climbs a 1.63 m platform, breaking records for quadruped parkour. Furthermore, the framework exhibits robust geometric generalization to unseen mirrored terrains and exceptional zero-shot transferability across diverse outdoor environments. These results demonstrate that symmetry equivariance is an effective structural prior for pushing the physical boundaries of learned legged locomotion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SWAP, an end-to-end equivariant symmetric world model that embeds symmetry directly into the world model and actor-critic networks for quadruped parkour. It claims this structural prior reduces redundant encoding of left-right symmetric interactions, enabling record real-world performance (2.13 m gap leap, 1.63 m platform climb) and robust generalization to unseen mirrored terrains plus zero-shot outdoor transfer.
Significance. If the experimental claims hold, the work demonstrates that symmetry equivariance can serve as an effective architectural prior for extreme legged locomotion, improving latent-space efficiency and geometric generalization without requiring additional data or parameters for symmetric patterns.
major comments (2)
- [Abstract] Abstract: the central performance claims (2.13 m gap, 1.63 m platform) are presented without any baseline comparisons, ablation results, or statistical details, making it impossible to isolate the contribution of the equivariant design from other factors such as training regime or hardware.
- [Abstract] The manuscript does not specify how the reflection symmetry is realized in the latent space or actor-critic (e.g., via group-equivariant layers or data augmentation), leaving open whether asymmetric task information required for stable control is preserved or discarded.
Simulated Author's Rebuttal
We thank the referee for the feedback. The abstract is space-constrained and emphasizes the core claims and contributions, but we agree that additional context would strengthen it. The full manuscript contains the requested experimental details and architectural specifications. We address each point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (2.13 m gap, 1.63 m platform) are presented without any baseline comparisons, ablation results, or statistical details, making it impossible to isolate the contribution of the equivariant design from other factors such as training regime or hardware.
Authors: The abstract highlights the record performances as the primary outcome. The full manuscript includes extensive baseline comparisons (e.g., against non-equivariant world models and standard RL policies), ablation studies isolating the symmetry components, and statistical results from repeated trials with variance reported in the Experiments and Results sections. To better isolate the equivariant contribution in the abstract itself, we will add a brief clause noting the performance gains relative to ablated variants. revision: yes
-
Referee: [Abstract] The manuscript does not specify how the reflection symmetry is realized in the latent space or actor-critic (e.g., via group-equivariant layers or data augmentation), leaving open whether asymmetric task information required for stable control is preserved or discarded.
Authors: The abstract provides a high-level overview. The full manuscript details the realization via group-equivariant layers (specifically, reflection-equivariant convolutions and linear layers) applied to the world model encoder/decoder and actor-critic networks, as described in the Methods and Architecture sections. Asymmetric task information is preserved by applying equivariance only to the symmetric state features while retaining task-specific asymmetric inputs (e.g., goal directions) in the policy head. We will insert a short clarifying phrase in the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes SWAP as a new end-to-end architectural framework that directly embeds symmetry equivariance into the latent world model and actor-critic networks. The central claim rests on this design choice as a structural prior, validated by empirical real-world performance (2.13 m gap leap, 1.63 m platform climb, generalization to mirrored terrains). No derivation chain, first-principles prediction, or fitted parameter is presented that reduces by construction to its own inputs; the symmetry embedding is an explicit modeling decision rather than a result derived from data or self-citation. The argument is self-contained as an engineering prior with external falsifiability through robot experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Symmetry in markov decision pro- cesses and its implications for single agent and multiagent learning,
M. Zinkevich and T. R. Balch, “Symmetry in markov decision pro- cesses and its implications for single agent and multiagent learning,” inProceedings of the eighteenth international conference on machine learning, 2001, p. 632
2001
-
[2]
On-robot learning with equivariant models,
D. Wang, M. Jia, X. Zhu, R. Walters, and R. Platt, “On-robot learning with equivariant models,”arXiv preprint arXiv:2203.04923, 2022
arXiv 2022
-
[3]
Learning latent dynamics for planning from pixels,
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning latent dynamics for planning from pixels,” in International conference on machine learning. PMLR, 2019, pp. 2555–2565
2019
-
[4]
Dream to control: Learning behaviors by latent imagination,
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learning behaviors by latent imagination,” inProceedings of the International Conference on Learning Representations (ICLR), 2020. [Online]. Available: https://openreview.net/forum?id=S1l7maskCr
2020
-
[5]
Day- dreamer: World models for physical robot learning,
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg, “Day- dreamer: World models for physical robot learning,” inConference on robot learning. PMLR, 2023, pp. 2226–2240
2023
-
[6]
World model-based perception for visual legged locomotion,
H. Lai, J. Cao, J. Xu, H. Wu, Y . Lin, T. Kong, Y . Yu, and W. Zhang, “World model-based perception for visual legged locomotion,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 531–11 537
2025
-
[7]
Extreme parkour with legged robots,
X. Cheng, K. Shi, A. Agarwal, and D. Pathak, “Extreme parkour with legged robots,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 11 443–11 450
2024
-
[8]
Model-free reinforce- ment learning for robust locomotion using demonstrations from tra- jectory optimization,
M. Bogdanovic, M. Khadiv, and L. Righetti, “Model-free reinforce- ment learning for robust locomotion using demonstrations from tra- jectory optimization,”Frontiers in Robotics and AI, vol. 9, p. 854212, 2022
2022
-
[9]
Lumos: Language-conditioned imitation learning with world models,
I. Nematollahi, B. DeMoss, A. L. Chandra, N. Hawes, W. Burgard, and I. Posner, “Lumos: Language-conditioned imitation learning with world models,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 8219–8225
2025
-
[10]
N. Rudin, J. He, J. Aurand, and M. Hutter, “Parkour in the wild: Learn- ing a general and extensible agile locomotion policy using multi-expert distillation and rl fine-tuning,”arXiv preprint arXiv:2505.11164v1, 2025
arXiv 2025
-
[11]
Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,
I. M. A. Nahrendra, B. Yu, and H. Myung, “Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 5078–5084
2023
-
[12]
Pie: Parkour with implicit-explicit learning framework for legged robots,
S. Luo, S. Li, R. Yu, W. Zhicheng, J. Wu, and Q. Zhu, “Pie: Parkour with implicit-explicit learning framework for legged robots,”IEEE Robotics and Automation Letters, vol. PP, pp. 1–8, 11 2024
2024
-
[13]
Start: Traversing sparse footholds with terrain reconstruction,
R. Yu, Q. Wang, H. Li, Z. Jun, Z. Wang, J. Wu, and Q. Zhu, “Start: Traversing sparse footholds with terrain reconstruction,”IEEE Robotics and Automation Letters, vol. 11, no. 2, pp. 2194–2201, 2025
2025
-
[14]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, 2018. [Online]. Available: https://arxiv.org/abs/ 1803.10122
Pith/arXiv arXiv 2018
-
[15]
Mastering atari with discrete world models,
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba, “Mastering atari with discrete world models,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[16]
Mastering diverse control tasks through world models,
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering diverse control tasks through world models,”Nature, vol. 640, no. 8059, pp. 647–653, 2025. [Online]. Available: https://doi.org/10.1038/ s41586-025-08744-2
2025
-
[17]
Invariant transform experience replay: Data augmentation for deep re- inforcement learning,
Y . Lin, J. Huang, M. Zimmer, Y . Guan, J. Rojas, and P. Weng, “Invariant transform experience replay: Data augmentation for deep re- inforcement learning,”IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 6615–6622, 2020
2020
-
[18]
Learning symmetric and low-energy locomotion,
W. Yu, G. Turk, and C. K. Liu, “Learning symmetric and low-energy locomotion,”ACM Transactions on Graphics (TOG), vol. 37, no. 4, pp. 1–12, 2018
2018
-
[19]
Symme- try considerations for learning task symmetric robot policies,
M. Mittal, N. Rudin, V . Klemm, A. Allshire, and M. Hutter, “Symme- try considerations for learning task symmetric robot policies,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 7433–7439
2024
-
[20]
Group equivariant convolutional networks,
T. Cohen and M. Welling, “Group equivariant convolutional networks,” inInternational Conference on Machine Learning (ICML). PMLR, 2016, pp. 2990–2999
2016
-
[21]
Mdp homomorphic networks: Group symmetries in re- inforcement learning,
E. van der Pol, D. E. Worrall, H. van Hoof, F. A. Oliehoek, and M. Welling, “Mdp homomorphic networks: Group symmetries in re- inforcement learning,” inAdvances in Neural Information Processing Systems, vol. 33, 2020
2020
-
[22]
Tensor field networks: Rotation-and translation- equivariant neural networks for 3d point clouds,
N. Thomas, T. Smidt, S. Kearnes, L. Yang, L. Li, K. Kohlhoff, and P. Riley, “Tensor field networks: Rotation-and translation- equivariant neural networks for 3d point clouds,”arXiv preprint arXiv:1802.08219, 2018
Pith/arXiv arXiv 2018
-
[23]
Leveraging symmetry in rl- based legged locomotion control,
Z. Su, X. Huang, D. Ordo ˜nez-Apraez, Y . Li, Z. Li, Q. Liao, G. Turrisi, M. Pontil, C. Semini, Y . Wuet al., “Leveraging symmetry in rl- based legged locomotion control,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 6899–6906
2024
-
[24]
Coordinated humanoid robot locomotion with symmetry equivariant reinforcement learning policy,
B. Nie, Y . Zhang, R. Jin, Z. Cao, H. Lin, X. Yang, and Y . Gao, “Coordinated humanoid robot locomotion with symmetry equivariant reinforcement learning policy,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 22, 2026, pp. 18 523–18 531
2026
-
[25]
Symmetry-guided memory augmentation for efficient locomotion learning,
K. Bao, C. Li, Y . As, A. Krause, and M. Hutter, “Symmetry-guided memory augmentation for efficient locomotion learning,” 2026. [Online]. Available: https://arxiv.org/abs/2502.01521
arXiv 2026
-
[26]
Amp: Adversarial motion priors for stylized physics-based character con- trol,
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: Adversarial motion priors for stylized physics-based character con- trol,”ACM Transactions on Graphics (ToG), vol. 40, no. 4, pp. 1–20, 2021
2021
-
[27]
Equivariant reinforcement learning under partial observability,
H. H. Nguyen, A. Baisero, D. Klee, D. Wang, R. Platt, and C. Amato, “Equivariant reinforcement learning under partial observability,” in Conference on Robot Learning. PMLR, 2023, pp. 3309–3320
2023
-
[28]
Z. Zhuang, Z. Fu, J. Wang, C. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao, “Robot parkour learning,”arXiv preprint arXiv:2309.05665, 2023
arXiv 2023
-
[29]
Anymal parkour: Learning agile navigation for quadrupedal robots,
D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,”Science Robotics, vol. 9, no. 88, p. eadi7566, 2024
2024
-
[30]
High-speed control and navigation for quadrupedal robots on complex and discrete terrain,
H. Kim, H. Oh, J. Park, Y . Kim, D. Youm, M. Jung, M. Lee, and J. Hwangbo, “High-speed control and navigation for quadrupedal robots on complex and discrete terrain,”Science Robotics, vol. 10, no. 102, p. eads6192, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.