Distributed Zeroth-Order Policy Gradient for Networked Multi-agent Reinforcement Learning from Human Feedback
Pith reviewed 2026-05-19 19:18 UTC · model grok-4.3
The pith
Agents in a network can learn collaborative policies from local human feedback on short trajectory pairs without needing global states or reward signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A distributed zeroth-order policy gradient algorithm enables networked multi-agent reinforcement learning from human feedback. Each agent uses human preference comparisons between current and Gaussian-perturbed joint policies on H-horizon trajectory pairs aggregated over its κ-hop neighborhood to estimate local gradients. The method requires no explicit rewards or centralized control and is shown to converge to an ε-stationary point with polynomial sample complexity.
What carries the argument
Human preference feedback from spatiotemporally truncated trajectories, which aggregates H-horizon pairs over each agent's κ-hop neighborhood to yield unbiased local policy gradient estimates for zeroth-order updates.
If this is right
- The learning process operates in a fully distributed manner with feedback depending only on local neighborhood information.
- Convergence to an ε-stationary point is guaranteed with a number of samples that scales polynomially.
- The algorithm achieves collaborative optimization in environments like stochastic GridWorld and predator-prey without reward functions.
- Scalability is improved for large-scale networked systems compared to centralized methods.
Where Pith is reading between the lines
- This could allow human-in-the-loop training for large teams of robots where only local observations are shared.
- Preference-based methods might reduce the need for designing numerical reward functions in multi-agent settings.
- Extensions could include handling communication delays or heterogeneous agent capabilities within the network structure.
Load-bearing premise
The human preference feedback from spatiotemporally truncated trajectories depends only on local state-action information and can generate unbiased estimates of each agent's local policy gradient.
What would settle it
Implement the algorithm in the predator-prey environment and check if the joint policy's average return plateaus near an ε-stationary value after the predicted number of preference queries, or verify if gradient estimates become biased when neighborhood information is restricted further.
Figures
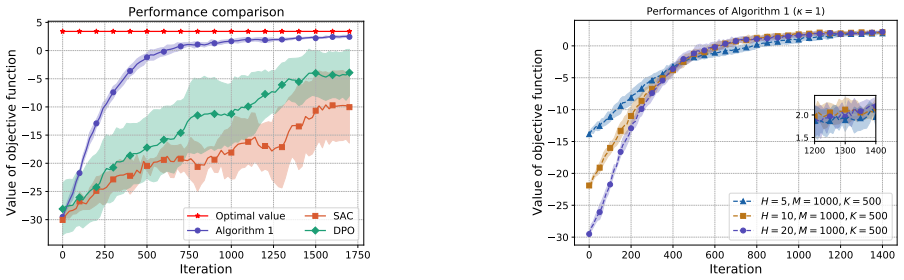





read the original abstract
We study a networked multi-agent reinforcement learning (NMARL) problem with human feedback in an infinite-horizon setting, where agents interact over an underlying network with localized state dependencies and aim to collaboratively maximize the average discounted return. Existing approaches with preference feedback are primarily developed for single-agent settings and rely on centralized training, which limits their scalability and applicability to large-scale networked multi-agent systems. To address this, we introduce a novel human feedback mechanism based on spatiotemporally truncated trajectories, defined as $H$-horizon trajectory pairs aggregated over each agent's $\kappa$-hop neighborhood. Building on this, we develop a distributed zeroth-order policy gradient algorithm, where each agent estimates its local policy gradient using human preference feedback generated from both the current joint policy and a perturbed joint policy drawn from zero-mean Gaussian distribution. Specifically, the algorithm is fully distributed, as the feedback received by each agent depends solely on the state-action information within its $\kappa$-hop neighborhood and does not require explicit reward signals or centralized control. We further rigorously establish that the proposed algorithm converges to an $\epsilon$-stationary point with polynomial sample complexity. Finally, simulation results in a stochastic GridWorld environment and a predator-prey environment further demonstrate that the effectiveness and scalability of the proposed algorithm in achieving collaborative optimization based solely on human preference feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a distributed zeroth-order policy gradient method for networked multi-agent RL from human feedback. Agents use preferences on H-horizon trajectory pairs aggregated over κ-hop neighborhoods to estimate local gradients without explicit rewards or central coordination. The central claim is a rigorous proof that the algorithm converges to an ε-stationary point of the infinite-horizon average discounted return with polynomial sample complexity; supporting simulations are shown in GridWorld and predator-prey environments.
Significance. If the unbiasedness of the truncated-feedback estimator holds and the convergence analysis accounts for the resulting bias term, the result would provide a scalable, fully decentralized alternative to centralized preference-based MARL methods, with potential impact on large networked systems where global state or reward signals are unavailable.
major comments (2)
- [§4] §4 (Convergence Analysis) and the statement of the main theorem: the proof treats the human-preference estimator derived from H-horizon, κ-hop truncated pairs as unbiased (or bias o(ε)) for the local policy gradient of the infinite-horizon global objective. The bias induced by the tail γ^H/(1-γ) and by influences outside the κ-hop neighborhood is not shown to be driven below ε while preserving polynomial dependence on 1/ε, 1/(1-γ), and network size; without an explicit additive bias term in the descent lemma or a separate lemma bounding the approximation error, the ε-stationary guarantee applies only to a surrogate objective.
- [Assumption 3] Assumption 3 (or the paragraph immediately preceding the main theorem): the claim that 'the feedback received by each agent depends solely on the state-action information within its κ-hop neighborhood and produces unbiased estimates' is used to justify the zeroth-order gradient estimator. This assumption is load-bearing for the entire convergence result; a counter-example or explicit bias bound showing that the estimator remains unbiased for the true global return under the stated truncation would be required.
minor comments (2)
- [§6] The experimental section reports results on two environments but does not specify the precise values of H and κ used, nor does it include an ablation on how performance degrades as H or κ is reduced; adding these details would strengthen the empirical support for the truncation scheme.
- [Algorithm 1] Notation for the perturbed policy (zero-mean Gaussian perturbation) and the exact form of the zeroth-order estimator should be written explicitly in the algorithm box or in Eq. (X) rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for the thorough review and insightful comments on our work. We address each major comment below, clarifying our approach and outlining revisions to strengthen the analysis.
read point-by-point responses
-
Referee: [§4] §4 (Convergence Analysis) and the statement of the main theorem: the proof treats the human-preference estimator derived from H-horizon, κ-hop truncated pairs as unbiased (or bias o(ε)) for the local policy gradient of the infinite-horizon global objective. The bias induced by the tail γ^H/(1-γ) and by influences outside the κ-hop neighborhood is not shown to be driven below ε while preserving polynomial dependence on 1/ε, 1/(1-γ), and network size; without an explicit additive bias term in the descent lemma or a separate lemma bounding the approximation error, the ε-stationary guarantee applies only to a surrogate objective.
Authors: We appreciate this observation. The current analysis controls the truncation error through parameter choices but does not isolate the bias term explicitly in the main descent lemma or theorem statement. In the revised manuscript we will insert a new supporting lemma that bounds the total approximation error by O(γ^H/(1-γ) + δ_κ), where δ_κ captures the influence outside the κ-hop neighborhood under the network mixing assumption. By selecting H = Θ(log(1/ε)) and κ sufficiently large (still polynomial in the relevant parameters), the bias is driven below ε/2 while preserving the overall polynomial sample complexity in 1/ε, 1/(1-γ), and network size. The descent lemma will be updated with an additive bias term, and the main theorem will be restated to reflect convergence to an ε-stationary point of the true objective up to this controllable approximation error. revision: yes
-
Referee: [Assumption 3] Assumption 3 (or the paragraph immediately preceding the main theorem): the claim that 'the feedback received by each agent depends solely on the state-action information within its κ-hop neighborhood and produces unbiased estimates' is used to justify the zeroth-order gradient estimator. This assumption is load-bearing for the entire convergence result; a counter-example or explicit bias bound showing that the estimator remains unbiased for the true global return under the stated truncation would be required.
Authors: We agree that the localized-feedback claim in Assumption 3 is central and requires stronger justification. The assumption encodes the design of our spatiotemporally truncated preference mechanism, but the unbiasedness claim for the infinite-horizon global objective is only approximate. In the revision we will replace the direct unbiasedness statement with the explicit bias bound from the new lemma referenced above, making the dependence on H and κ transparent. We will also add a short discussion of the conditions under which the bias vanishes (e.g., as H, κ → ∞). If the referee can provide a concrete counter-example under the stated truncation, we would be grateful for the details so that we may address it directly in the text. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a distributed zeroth-order policy gradient method for networked MARL using human preference feedback on spatiotemporally truncated (H-horizon, κ-hop) trajectories. The central theoretical claim is convergence to an ε-stationary point of the infinite-horizon average discounted return, with polynomial sample complexity. This result is presented as following from standard zeroth-order analysis once local gradient estimates are obtained from the preference feedback. The unbiasedness of those local estimates is stated as a modeling assumption tied to the truncation mechanism rather than derived by redefining the target objective in terms of the estimator itself. No equations reduce the claimed stationary point or sample bound to a fitted parameter or self-referential definition, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The derivation therefore remains self-contained relative to its explicit assumptions and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard technical assumptions required for policy gradient convergence in infinite-horizon discounted settings (e.g., bounded returns, smoothness of policies) hold.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We further rigorously establish that the proposed algorithm converges to an ε-stationary point with polynomial sample complexity.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
spatiotemporally truncated trajectories... H-horizon trajectory pairs aggregated over each agent's κ-hop neighborhood
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dai, P., Yu, W., Wen, G., & Baldi, S. (2020). Distributed reinforcement learning algorithm for dynamic economic dispatch with unknown generation cost functions. IEEE Transactions on Industrial Informatics, 16(4), 2258-2267
work page 2020
-
[2]
Li, F., Qin, J., & Zheng, W. (2020). Distributed Q -learning-based online optimization algorithm for unit commitment and dispatch in smart grid. IEEE Transactions on Cybernetics, 50(9), 4146-4156
work page 2020
-
[3]
Dai, P., Yu, W., & Chen, D. (2022). Distributed Q-learning algorithm for dynamic resource allocation with unknown objective functions and application to microgrid. IEEE Transactions on Cybernetics, 52(11), 12340-12350
work page 2022
-
[4]
Chu, T., Wang, J., Codec\` a , L., & Li, Z. (2020). Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Transactions on Intelligent Transportation Systems, 21(3), 1086-1095
work page 2020
-
[5]
Wang, X., Ke, L., Qiao, Z., & Chai, X. (2021). Large-scale traffic signal control using a novel multiagent reinforcement learning. IEEE Transactions on Cybernetics, 51(1), 174-187
work page 2021
-
[6]
Dai, P., Yu, W., Wang, H., & Jiang, J. (2024). Applications in traffic signal control: a distributed policy gradient decomposition algorithm. IEEE Transactions on Industrial Informatics, 20(2), 2762-2775
work page 2024
-
[7]
Tan, J., Liang, Y.-C., Zhang, L., & Feng, G. (2021). Deep reinforcement learning for joint channel selection and power control in D2D networks. IEEE Transactions on Wireless Communications, 20(2), 1363-1378
work page 2021
-
[8]
Meng, F., Chen, P., Wu, L., & Cheng, J. (2020). Power allocation in multiuser cellular networks: Deep reinforcement learning approaches. IEEE Transactions on Wireless Communications, 19(10), 6255-6267
work page 2020
-
[9]
Afsar, M. M., Crump, T., & Far, B. (2022) Reinforcement learning based recommender systems: a survey. ACM Computing Surveys, 55(7), 1-38
work page 2022
-
[10]
Lin, Y., Liu, Y., Lin, F., Zou, L., Wu, P., & Zeng, W. (2024). A survey on reinforcement learning for recommender systems. IEEE Transactions on Neural Networks and Learning Systems, 35(10), 13164-13184
work page 2024
-
[11]
Sutton, R. S., & Barto, A. G. (1998). Reinforcement Learning: An Introduction. Cambridge, MA, USA: MIT Press
work page 1998
-
[12]
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., & Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533
work page 2015
-
[13]
Sha, X., Zhang, J., You, K., Zhang, K., & Ba s ar, T. (2022). Fully asynchronous policy evaluation in distributed reinforcement learning over networks. Automatica, 136, 110092
work page 2022
-
[14]
Christiano, P. F., Leike, J., Brown, T. B., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, pages 4302-4310
work page 2017
-
[15]
blue Wirth, C., Akrour, R., Neumann, G., & F\" u rnkranz, J. (2017). A survey of preference-based reinforcement learning methods. Journal of Machine Learning Research, 18(136), 1-46
work page 2017
-
[16]
Bengs, V., Busa-Fekete, R., Mesaoudi-Paul, A. El, & H\" u llermeier, E. (2021). Preference-based online learning with dueling bandits: a survey. Journal of Machine Learning Research, 22(7), 1-108
work page 2021
-
[17]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2023). Direct preference optimization: your language model is secretly a reward model. In Advances in Neural Information Processing Systems, pages 53728-53741
work page 2023
- [19]
-
[20]
Qu, G., Wierman, A., & Li, N. (2020). Scalable reinforcement learning of localized policies for multi-agent networked systems. In Proceedings of the Conference on Learning for Dynamics and Control, pages 256-266
work page 2020
-
[21]
Qu, G., Lin, Y., Wierman, A., & Li, N. (2020). Scalable multi-agent reinforcement learning for networked systems with average reward. In Advances in Neural Information Processing Systems, pages 2074-2086
work page 2020
-
[22]
C., Zang, W., Pinciroli, C., Li, Z
blue Huang. C., Zang, W., Pinciroli, C., Li, Z. J., Banerjee, T., Su, L., & Liu, R. (2024). Reactive multi-robot navigation in outdsoor environments through uncertainty-aware active learning of human preference landscape arXiv preprint arXiv:2409.16577
- [23]
-
[24]
blue Zhang, K., Yang, Z., Liu, H., Zhang, T., & Ba s ar, T. (2018). Fully decentralized multi-agent reinforcement learning with networked agents. In Proceedings of the International Conference on Machine Learning, pages 5872-5881
work page 2018
-
[25]
blue Dai, P., Mo, Y., Yu, W., & Ren, W. (2025). Distributed neural policy gradient algorithm for global convergence of networked multi-agent reinforcement learning. IEEE Transactions on Automatic Control, 70(11), 7109-7124
work page 2025
-
[26]
Sutton, R. S., McAllester, D. A., Singh, S. P., & Mansour, Y. (2000). Policy gradient methods for reinforcement learning with function approximation. In Advances in Neural Information Processing Systems, pages 1057-1063
work page 2000
-
[27]
Train, K. E. (2009). Discrete Choice Methods with Simulation. Cambridge, UK: Cambridge University Press
work page 2009
-
[28]
Greene, W. H. (2010). Modeling Ordered Choices: A Primer. New York, NY, USA: Cambridge University Press, 2010
work page 2010
- [29]
-
[30]
Lin, Y., Qu, G., Huang, L., & Wierman, A. (2021). Multi-agent reinforcement learning in stochastic networked systems. In Advances in Neural Information Processing Systems, pages 7825-7837
work page 2021
-
[31]
Zhou, Z., Chen, Z., Lin, Y., & Wierman, A. (2023). Convergence rates for localized actor-critic in networked markov potential games. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, pages 2563-2573
work page 2023
-
[32]
Zhang, R., Mei, J., Dai, B., Schuurmans, D., & Li, N. (2022). On the global convergence rates of decentralized softmax gradient play in markov potential games. In Advances in Neural Information Processing Systems, pages 1923-1935
work page 2022
-
[33]
Ying, D., Zhang, Y., Ding, Y., Koppel, A., & Lavaei, J. (2023). Scalable primal-dual actor-critic method for safe multi-agent rl with general utilities. In Advances in Neural Information Processing Systems, pages 36524-36539
work page 2023
-
[34]
Li, W., Liu, J., & Wei, K. (2025). -update: a class of policy update methods with policy convergence guarantee. In Proceedings of the International Conference on Learning Representations
work page 2025
- [35]
-
[36]
Rosenthal, H. P. (1970). On the subspaces of L_ p ( p>2 ) spanned by sequences of independent random variables. Israel Journal of Mathematics, 8(3), 273-303
work page 1970
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.