ICBCBench: An Industry Consortium Benchmark for Financial Deep Research
Pith reviewed 2026-06-26 22:24 UTC · model grok-4.3
The pith
ICBCBench introduces a dual-track evaluation that measures both verifiable accuracy and expert-aligned report quality for financial deep research agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
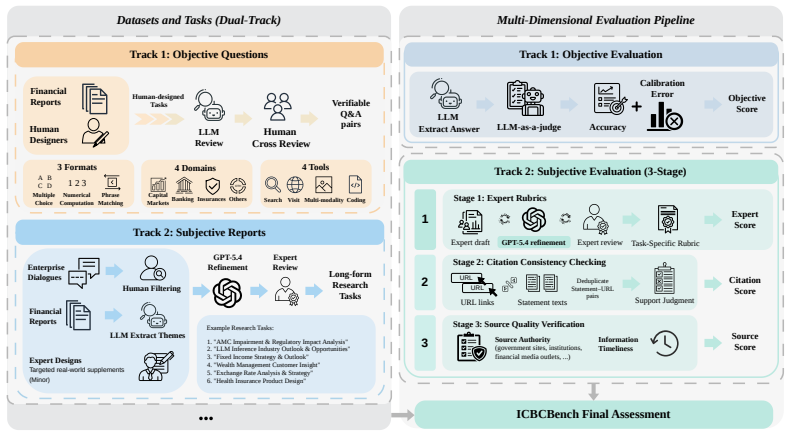
ICBCBench adopts a dual-track paradigm that pairs objective tasks having verifiable answers with subjective long-form report evaluation, allowing joint measurement of retrieval-reasoning accuracy and end-to-end report quality along the dimensions of expert alignment, citation consistency, and source quality, with experiments confirming substantial performance gaps in state-of-the-art systems.
What carries the argument
The dual-track paradigm that integrates objective tasks with verifiable answers and subjective long-form report evaluation.
If this is right
- Current deep research agents and large language models exhibit measurable shortfalls in complex financial reasoning and factual grounding.
- End-to-end report quality remains below the level required for direct use in professional financial workflows.
- Progress toward industry-level performance will require targeted improvements in both retrieval accuracy and report-generation fidelity.
- The benchmark supplies a shared reference point that future agent development can be measured against.
Where Pith is reading between the lines
- The same dual-track structure could be adapted to other knowledge-intensive domains that combine data retrieval with narrative synthesis.
- Widespread adoption might shift evaluation focus from single-answer accuracy toward full workflow simulation in regulated industries.
- If expert consistency proves lower than assumed, the benchmark would need repeated calibration rounds with new cohorts.
Load-bearing premise
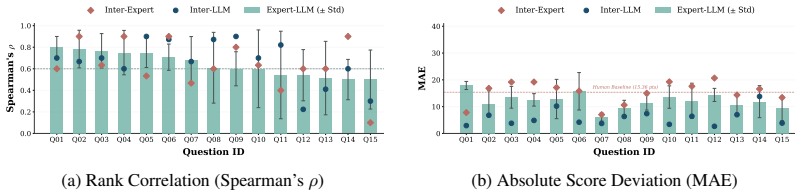
Expert judgments collected from the 50-plus participants accurately represent consistent, industry-standard requirements for financial research quality.
What would settle it
A controlled study in which independent financial analysts rate the same agent outputs without access to the benchmark rubric and produce markedly different rankings or quality scores.
Figures

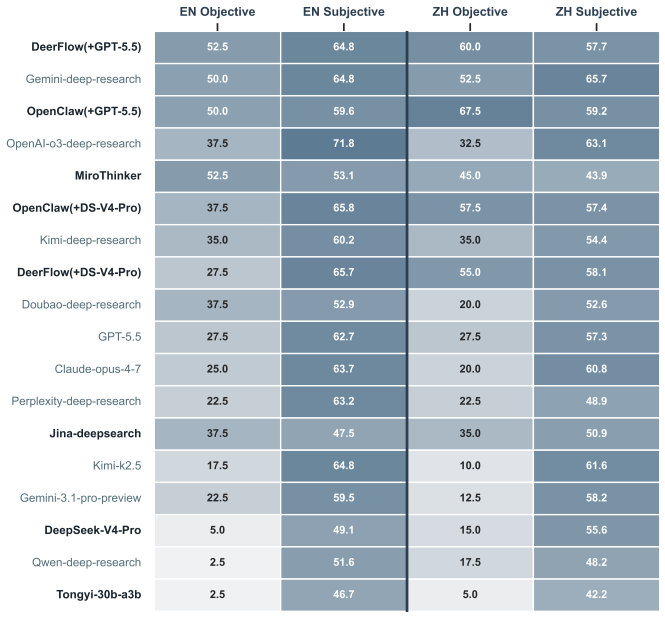
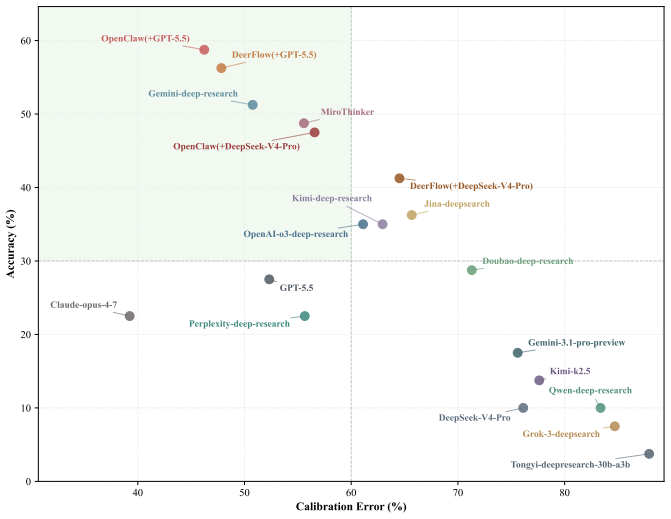





read the original abstract
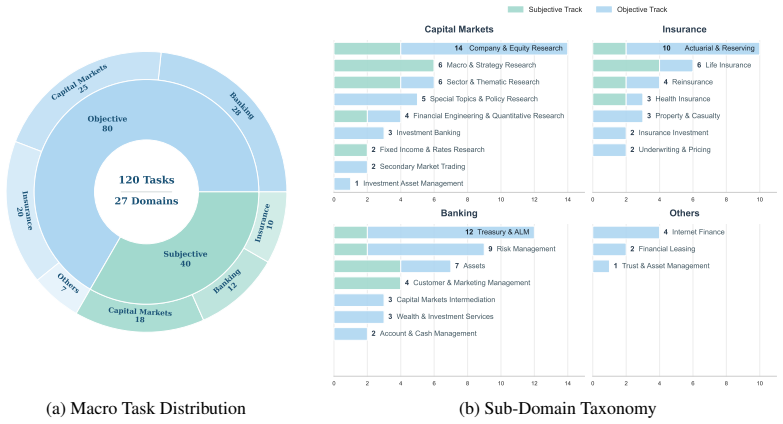
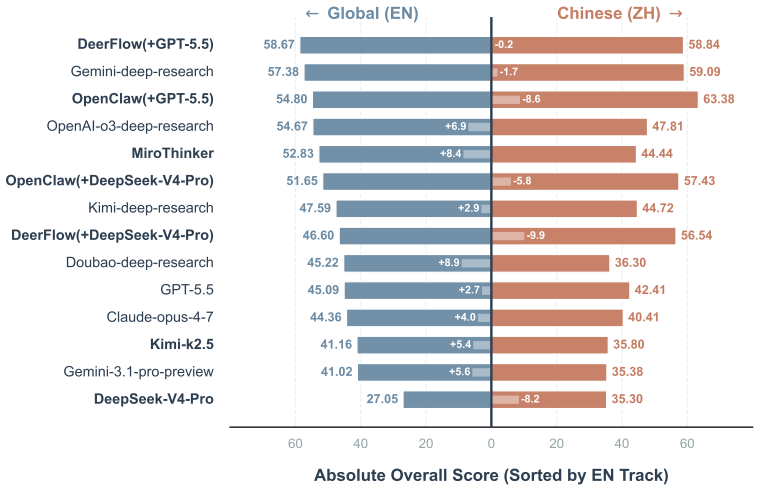
With the rapid advancement of Deep Research Agents in knowledge-intensive domains such as finance, establishing reliable and domain-aligned evaluation standards remains a critical challenge. Existing benchmarks focus on either closed-ended question answering or open-ended report evaluation, failing to jointly capture retrieval-reasoning accuracy and end-to-end research quality required in real-world workflows. We introduce ICBCBench, a consortium-driven benchmark for financial deep research, developed in collaboration with domain experts from a broad range of financial institutions and academia, involving over 50 experts across more than 40 organizations. It adopts a dual-track paradigm integrating objective tasks with verifiable answers and subjective long-form report evaluation, enabling complementary assessment of retrieval-reasoning accuracy and end-to-end report quality in terms of expert alignment, citation consistency, and source quality. Experiments on state-of-the-art DRAs and large language models reveal substantial gaps in complex reasoning, factual grounding, and report quality, highlighting the challenges of achieving industry-level performance. Our dataset and evaluation framework are available at https://github.com/DeepFin-Intelligence/ICBCBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ICBCBench, a consortium-driven benchmark for financial deep research developed with over 50 experts from more than 40 organizations. It proposes a dual-track evaluation paradigm that combines objective tasks with verifiable answers and subjective long-form report assessment along dimensions of expert alignment, citation consistency, and source quality. Experiments on state-of-the-art Deep Research Agents and large language models are reported to demonstrate substantial gaps in complex reasoning, factual grounding, and report quality relative to industry standards. The dataset and framework are released at a public GitHub repository.
Significance. If the central claims hold after addressing the issues below, ICBCBench would offer a useful industry-aligned evaluation resource that jointly assesses retrieval-reasoning accuracy and end-to-end report quality, addressing a gap left by existing closed-ended or purely open-ended benchmarks. The scale of expert involvement (50+ experts, 40+ organizations) and the public release of the dataset constitute concrete strengths for reproducibility and potential adoption in the financial AI community.
major comments (2)
- [Abstract and Experiments section] Abstract and Experiments section: The central claim that experiments reveal 'substantial gaps' in complex reasoning, factual grounding, and report quality rests primarily on the subjective track's expert judgments, yet the manuscript reports no inter-rater agreement metrics (Cohen's kappa, Fleiss' kappa, or ICC) for the 50+ experts' ratings. This is load-bearing because without quantitative evidence of rating consistency or a documented disagreement-resolution protocol, observed differences between models could be driven by rater variance rather than genuine capability gaps.
- [Evaluation Methodology section] Evaluation Methodology section: The dual-track design is presented as accurately reflecting real-world financial research workflows due to expert involvement, but no validation study, comparison against actual industry report standards, or sensitivity analysis of the three subjective metrics (expert alignment, citation consistency, source quality) is provided to support this assumption.
minor comments (2)
- [Abstract] The abstract would benefit from inclusion of at least one quantitative result (e.g., average scores or gap magnitudes with error bars) to allow readers to gauge the scale of the reported gaps without reading the full experiments section.
- Dataset statistics (number of objective tasks, number of reports evaluated, distribution across financial sub-domains) should be summarized in a table early in the paper for context.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each of the major comments below and outline the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The central claim that experiments reveal 'substantial gaps' in complex reasoning, factual grounding, and report quality rests primarily on the subjective track's expert judgments, yet the manuscript reports no inter-rater agreement metrics (Cohen's kappa, Fleiss' kappa, or ICC) for the 50+ experts' ratings. This is load-bearing because without quantitative evidence of rating consistency or a documented disagreement-resolution protocol, observed differences between models could be driven by rater variance rather than genuine capability gaps.
Authors: We agree that reporting inter-rater agreement is important for validating the subjective evaluations. In the revised manuscript, we will include Fleiss' kappa scores calculated across the expert raters for the subjective metrics. We will also add a description of the protocol used to resolve disagreements among experts. This addition will provide the necessary quantitative support for the reliability of our findings and address the concern about potential rater variance. revision: yes
-
Referee: [Evaluation Methodology section] The dual-track design is presented as accurately reflecting real-world financial research workflows due to expert involvement, but no validation study, comparison against actual industry report standards, or sensitivity analysis of the three subjective metrics (expert alignment, citation consistency, source quality) is provided to support this assumption.
Authors: We acknowledge the value of additional validation. While a comprehensive new validation study against industry standards is beyond the immediate scope, we will perform and report a sensitivity analysis on the three subjective metrics to assess their robustness. We will also expand the methodology section with more details on how the metrics were developed through iterative consultations with the consortium experts, providing stronger justification for their relevance to real-world workflows. revision: partial
Circularity Check
No significant circularity; benchmark introduction is self-contained
full rationale
The paper presents ICBCBench as a new consortium-driven dual-track benchmark (objective verifiable tasks plus subjective expert report evaluation) and reports experimental gaps on existing DRAs/LLMs. No derivation chain, equations, fitted parameters, or predictions are described that reduce by construction to the authors' own inputs or prior self-citations. The evaluation metrics (expert alignment, citation consistency, source quality) are defined externally via the 50+ experts and do not loop back to self-referential definitions. This is a standard benchmark paper whose central claims rest on new data collection rather than any self-definitional or fitted-input reduction.
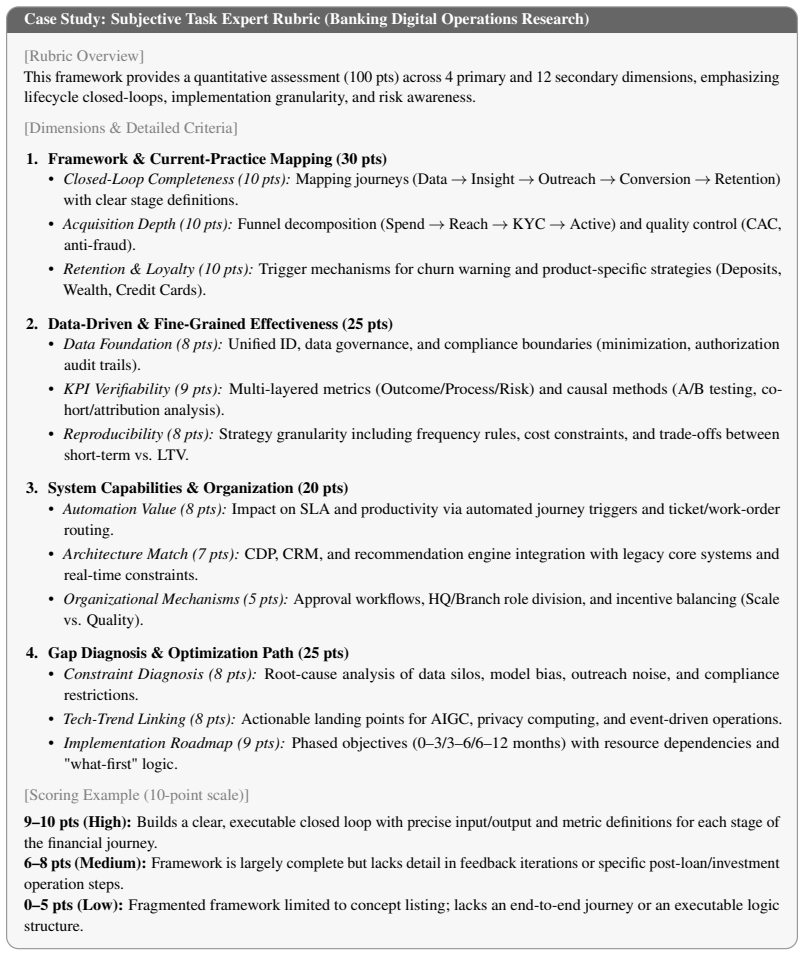
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert consensus from over 50 specialists across 40 organizations provides reliable ground truth for subjective report quality, citation consistency, and source quality.
Reference graph
Works this paper leans on
-
[1]
Amirhossein Abaskohi, Tianyi Chen, Miguel Muñoz-Mármol, Curtis Fox, Amrutha Varshini Ramesh, Étienne Marcotte, Xing Han Lù, Nicolas Chapados, Spandana Gella, Peter West, Giuseppe Carenini, Christopher Pal, Alexandre Drouin, and Issam H. Laradji. Drbench: A realistic benchmark for enterprise deep research, 2026. URL https://arxiv.org/abs/ 2510.00172
-
[2]
Introducing claude opus 4.7, 2026
Anthropic. Introducing claude opus 4.7, 2026. URL https://www.anthropic.com/news/ claude-opus-4-7. Accessed: 2026-03-13
2026
-
[3]
Association of chartered certified accountants (acca).https://www.accaglobal.com/gb/en.html, 2026
Association of Chartered Certified Accountants. Association of chartered certified accountants (acca).https://www.accaglobal.com/gb/en.html, 2026. Accessed: 2026-05-15
2026
-
[4]
Deerflow: An open-source superagent harness for deep research and task automa- tion, 2026
ByteDance. Deerflow: An open-source superagent harness for deep research and task automa- tion, 2026. URLhttps://github.com/bytedance/deer-flow. Accessed: 2026-03-13
2026
-
[5]
Doubao chat, 2026
ByteDance. Doubao chat, 2026. URL https://www.doubao.com/chat/. Accessed: 2026- 03-13
2026
-
[6]
Cfa institute
CFA Institute. Cfa institute. https://www.cfainstitute.org/, 2026. Accessed: 2026-05- 15
2026
-
[7]
Chinese institute of certified public accoun- tants.https://www.cicpa.org.cn/introcicpa/, 2026
Chinese Institute of Certified Public Accountants. Chinese institute of certified public accoun- tants.https://www.cicpa.org.cn/introcicpa/, 2026. Accessed: 2026-05-15
2026
-
[8]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[9]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents.ArXiv, abs/2506.11763, 2025. URLhttps://api.semanticscholar.org/CorpusID:279391682
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Try deep research and our new experimental model in gemini, your ai as- sistant
Google. Try deep research and our new experimental model in gemini, your ai as- sistant. https://blog.google/products-and-platforms/products/gemini/google- gemini-deep-research/, 2024. Accessed: 2026-03-13
2024
-
[11]
A new era of intelligence with gemini 3, 2025
Google. A new era of intelligence with gemini 3, 2025. URL https://blog.google/ products-and-platforms/products/gemini/gemini-3/. Accessed: 2026-03-13
2025
-
[12]
Gemini 3.1 pro model card.https://deepmind.google/models/model- cards/gemini-3-1-pro/, 2025
Google DeepMind. Gemini 3.1 pro model card.https://deepmind.google/models/model- cards/gemini-3-1-pro/, 2025. Accessed: 2026-03-19. 11
2025
-
[13]
Nikita Gupta, Riju Chatterjee, Lukas Haas, Connie Tao, Andrew Wang, Chang Liu, Hidekazu Oiwa, Elena Gribovskaya, Jan Ackermann, John Blitzer, Sasha Goldshtein, and Dipanjan Das. Deepsearchqa: Bridging the comprehensiveness gap for deep research agents.ArXiv, abs/2601.20975, 2026. URLhttps://api.semanticscholar.org/CorpusID:283897826
-
[14]
Deer: A benchmark for evaluating deep research agents on expert report generation, 2026
Janghoon Han, Heegyu Kim, Changho Lee, Dahm Lee, Min Hyung Park, Hosung Song, Stanley Jungkyu Choi, Moontae Lee, and Honglak Lee. Deer: A benchmark for evaluating deep research agents on expert report generation, 2026. URL https://arxiv.org/abs/ 2512.17776
-
[15]
Liang Hu, Jianpeng Jiao, Jiashuo Liu, Yanle Ren, Zhoufutu Wen, Kaiyuan Zhang, Xuanliang Zhang, Xiang Gao, Tianci He, Fei Hu, Yali Liao, Zaiyuan Wang, Chenghao Yang, Qianyu Yang, Mingren Yin, Zhiyuan Zeng, Ge Zhang, Xinyi Zhang, Xiying Zhao, Zhenwei Zhu, Hongseok Namkoong, Wenhao Huang, and Yuwen Tang. Finsearchcomp: Towards a realistic, expert-level evalu...
-
[16]
Mmdeepresearch-bench: A benchmark for multimodal deep research agents, 2026
Peizhou Huang, Zixuan Zhong, Zhongwei Wan, Donghao Zhou, Samiul Alam, Xin Wang, Zexin Li, Zhihao Dou, Li Zhu, Jing Xiong, Chaofan Tao, Yan Xu, Dimitrios Dimitriadis, Tuo Zhang, and Mi Zhang. Mmdeepresearch-bench: A benchmark for multimodal deep research agents, 2026. URLhttps://arxiv.org/abs/2601.12346
-
[17]
Song Jin, Shuqi Li, Shukun Zhang, and Rui Yan. Finrpt: Dataset, evaluation system and llm-based multi-agent framework for equity research report generation.ArXiv, abs/2511.07322,
-
[18]
URLhttps://api.semanticscholar.org/CorpusID:282911316
-
[19]
Jina deepsearch, 2025
Jina AI. Jina deepsearch, 2025. URLhttps://jina.ai/deepsearch/. Accessed: 2026-03- 13
2025
-
[20]
Xiangyu Li, Xuan Yao, Guohao Qi, Fengbin Zhu, Kelvin J.L. Koa, Xiang Yao Ng, Ziyang Liu, Xingyu Ni, Chang Liu, Yonghui Yang, Yang Zhang, Wenjie Wang, Fuli Feng, Chao Wang, Huanbo Luan, Xiaofen Xing, Xiangmin Xu, Tat-Seng Chua, and Ke wei Huang. Findeepforecast: A live multi-agent system for benchmarking deep research agents in financial forecasting.ArXiv,...
-
[21]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[23]
Kimi researcher: End-to-end rl training for deep research agents, 2025
Moonshot AI. Kimi researcher: End-to-end rl training for deep research agents, 2025. URL https://moonshotai.github.io/Kimi-Researcher/. Accessed: 2026-03-13
2025
-
[24]
Introducing deep research
OpenAI. Introducing deep research. https://openai.com/index/introducing-deep- research/, 2024. Accessed: 2026-03-13
2024
-
[25]
Introducing gpt-5.4
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/ ,
-
[26]
Accessed: 2026-03-19
2026
-
[27]
o3-deep-research model, 2025
OpenAI. o3-deep-research model, 2025. URL https://platform.openai.com/docs/ models/o3-deep-research. OpenAI API documentation, accessed 2026-04-18
2025
-
[28]
Introducing gpt-5.5, 2026
OpenAI. Introducing gpt-5.5, 2026. URL https://openai.com/index/introducing-gpt- 5-5/. Accessed: 2026-04-24
2026
-
[29]
Openclaw: Open-source autonomous ai agent framework, 2026
OpenClaw. Openclaw: Open-source autonomous ai agent framework, 2026. URL https: //github.com/openclaw/openclaw. Accessed: 2026-03-13
2026
-
[30]
Introducing perplexity deep research
Perplexity AI. Introducing perplexity deep research. https://www.perplexity.ai/hub/ blog/introducing-perplexity-deep-research, 2025. Accessed: 2026-03-13. 12
2025
-
[31]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Qwen deepresearch: When inspiration becomes its own execution, 2025
Qwen Team. Qwen deepresearch: When inspiration becomes its own execution, 2025. URL https://qwen.ai/blog?id=qwen-deepresearch. Accessed: 2026-03-13
2025
-
[33]
Balwani, Denis Peskoff, Marcos Ayestaran, Sean M
Manasi Sharma, Chen Bo Calvin Zhang, Chaithanya Bandi, Clinton Wang, Ankit Aich, Huy Nghiem, Tahseen Rabbani, Ye Htet, Brian Jang, Sumana Basu, Aishwarya H. Balwani, Denis Peskoff, Marcos Ayestaran, Sean M. Hendryx, Brad Kenstler, and Bing Liu. Researchrubrics: A benchmark of prompts and rubrics for evaluating deep research agents.ArXiv, abs/2511.07685,
-
[34]
URLhttps://api.semanticscholar.org/CorpusID:282921678
-
[35]
Finresearchbench: A logic tree based agent-as-a-judge evaluation framework for financial research agents.Proceedings of the 6th ACM International Conference on AI in Finance, 2025
Rui Sun, Zuo Bai, Wentao Zhang, Yuxiang Zhang, Li Zhao, Shangxue Sun, and Zhengwen Qiu. Finresearchbench: A logic tree based agent-as-a-judge evaluation framework for financial research agents.Proceedings of the 6th ACM International Conference on AI in Finance, 2025. URLhttps://api.semanticscholar.org/CorpusID:280416955
2025
-
[36]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
MiroMind Team, Song Bai, Lidong Bing, Carson Chen, Guanzheng Chen, Yuntao Chen, Zhe Chen, Ziyi Chen, Jifeng Dai, Xuan Dong, et al. Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling.arXiv preprint arXiv:2511.11793, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Tongyi DeepResearch Technical Report
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, et al. Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Deepresearch arena: The first exam of llms’ research abilities via seminar-grounded tasks, 2025
Haiyuan Wan, Chen Yang, Junchi Yu, Meiqi Tu, Jiaxuan Lu, Di Yu, Jianbao Cao, Ben Gao, Jiaqing Xie, Aoran Wang, Wenlong Zhang, Philip Torr, and Dongzhan Zhou. Deepresearch arena: The first exam of llms’ research abilities via seminar-grounded tasks, 2025. URL https://arxiv.org/abs/2509.01396
-
[40]
LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Jiayu Wang, Yifei Ming, Riya Dulepet, Qinglin Chen, Austin Xu, Zixuan Ke, Frederic Sala, Aws Albarghouthi, Caiming Xiong, and Shafiq Joty. Liveresearchbench: A live benchmark for user-centric deep research in the wild, 2025. URLhttps://arxiv.org/abs/2510.14240
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeff Han, Isa Fulford, Hyung Won Chung, Alexandre Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.ArXiv, abs/2504.12516, 2025. URL https: //api.semanticscholar.org/CorpusID:277857238
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Grok 3 beta — the age of reasoning agents, 2025
xAI. Grok 3 beta — the age of reasoning agents, 2025. URL https://x.ai/news/grok-3. Accessed: 2026-03-13
2025
-
[43]
Yang Yao, Yixu Wang, Yuxuan Zhang, Yi Lu, Tianle Gu, Lingyu Li, Dingyi Zhao, Kem- ing Wu, Haozhe Wang, Ping Nie, Yan Teng, and Yingchun Wang. Dr. bench: A mul- tidimensional evaluation for deep research agents, from answers to reports. 2025. URL https://api.semanticscholar.org/CorpusID:281725033
2025
-
[44]
Miroeval: Benchmarking multimodal deep research agents in process and outcome, 2026
Fangda Ye, Yuxin Hu, Pengxiang Zhu, Yibo Li, Ziqi Jin, Yao Xiao, Yibo Wang, Lei Wang, Zhen Zhang, Lu Wang, Yue Deng, Bin Wang, Yifan Zhang, Liangcai Su, Xinyu Wang, He Zhao, Chen Wei, Qiang Ren, Bryan Hooi, An Bo, Shuicheng Yan, and Lidong Bing. Miroeval: Benchmarking multimodal deep research agents in process and outcome, 2026. URL https: //arxiv.org/abs...
-
[45]
Lingfeng Zeng, Fangqi Lou, Zixuan Wang, Jiajie Xu, Jinyi Niu, Mengping Li, Yifan Dong, Qi Qi, Wei Zhang, Ziwei Yang, Jun Han, Ruilun Feng, Ruiqi Hu, Lejie Zhang, Zhengbo Feng, Yicheng Ren, Xin Guo, Zhaowei Liu, Dongpo Cheng, Weige Cai, and Liwen Zhang. Fingaia: A chinese benchmark for ai agents in real-world financial domain.ArXiv, abs/2507.17186, 2025. U...
-
[46]
Yu Zeng, Wenxuan Huang, Zhen Fang, Shuang Chen, Yufan Shen, Yishuo Cai, Xiaoman Wang, Zhenfei Yin, Lin Chen, Zehui Chen, Shiting Huang, Yiming Zhao, Xu Tang, Yao Hu, Philip Torr, Wanli Ouyang, and Shaosheng Cao. Vision-deepresearch benchmark: Rethinking visual and textual search for multimodal large language models, 2026. URL https://arxiv.org/ abs/2602.02185
-
[47]
Draco: a cross-domain bench- mark for deep research accuracy, completeness, and objectivity
Jia Zhong, Hao Zhang, Clare Southern, Jeremy Yang, Thomas Wang, Kooseung Jung, Shu Zhang, Denis Yarats, Johnny Ho, and Jerry Ma. Draco: a cross-domain bench- mark for deep research accuracy, completeness, and objectivity. 2026. URL https: //api.semanticscholar.org/CorpusID:285540278. 14 Table 3: Taxonomy of financial research domains in ICBCBench. Domains...
-
[48]
Net income increased substantially in the second quarter, while catastrophe losses in April and May were particularly notable
According to the operational fundamentals disclosed in the acquisition agreement, what is the all-time high figure of Assets under Administration (AuA) achieved by Allfunds on the eve of the acquisition (i.e., as of September 30, 2025)? (Provide the numerical value in trillion euros, rounded to one decimal place.) Ground Truth: Deutsche Börse; 1.7 [Exampl...
2025
-
[49]
Analyze how data-driven approaches, process automation, and refined management are applied in these contexts
Current Practices and Implementation:Systematically review current digital operation practices across key stages such as customer acquisition, activation, conversion, and retention. Analyze how data-driven approaches, process automation, and refined management are applied in these contexts
-
[50]
Effectiveness and Challenges:Evaluate the effectiveness of these digital operation practices in improving customer value, operational efficiency, and service experience, and identify the main constraints and challenges they face
-
[51]
Optimization Pathways and Future Directions:Considering technological advancements and evolving customer behavior, propose optimization directions and actionable pathways for future banking digital operation models from the perspectives of operational models, organizational mechanisms, and system capabilities. [Example 2: AI Chip Industry Transformation A...
-
[52]
Under current trends in inference demand, identify the technical bottlenecks that may arise at each stage and discuss potential future improvement directions
Technical Pipeline and Bottlenecks:From a technical perspective, conduct a comprehensive study of the full operational pipeline of current large-model inference services, including but not limited to model computation mechanisms, how hardware infrastructure performs the corresponding data processing, and storage/communication mechanisms. Under current tre...
-
[53]
Industrial Impact and Competitive Landscape:For each major technological improvement direction, assess the industrial beneficiaries and adversely affected parties, including both directly impacted stakeholders and important indirectly affected stakeholders. Analyze the channels of impact, transmission speed, and potential competitive dynamics across indus...
-
[54]
• Acquisition Depth (10 pts):Funnel decomposition (Spend → Reach → KYC → Active) and quality control (CAC, anti-fraud)
Framework & Current-Practice Mapping (30 pts) • Closed-Loop Completeness (10 pts):Mapping journeys (Data → Insight → Outreach → Conversion → Retention) with clear stage definitions. • Acquisition Depth (10 pts):Funnel decomposition (Spend → Reach → KYC → Active) and quality control (CAC, anti-fraud). • Retention & Loyalty (10 pts):Trigger mechanisms for c...
-
[55]
• KPI Verifiability (9 pts):Multi-layered metrics (Outcome/Process/Risk) and causal methods (A/B testing, co- hort/attribution analysis)
Data-Driven & Fine-Grained Effectiveness (25 pts) • Data Foundation (8 pts):Unified ID, data governance, and compliance boundaries (minimization, authorization audit trails). • KPI Verifiability (9 pts):Multi-layered metrics (Outcome/Process/Risk) and causal methods (A/B testing, co- hort/attribution analysis). • Reproducibility (8 pts):Strategy granulari...
-
[56]
• Architecture Match (7 pts):CDP, CRM, and recommendation engine integration with legacy core systems and real-time constraints
System Capabilities & Organization (20 pts) •Automation Value (8 pts):Impact on SLA and productivity via automated journey triggers and ticket/work-order routing. • Architecture Match (7 pts):CDP, CRM, and recommendation engine integration with legacy core systems and real-time constraints. • Organizational Mechanisms (5 pts):Approval workflows, HQ/Branch...
-
[57]
what-first
Gap Diagnosis & Optimization Path (25 pts) • Constraint Diagnosis (8 pts):Root-cause analysis of data silos, model bias, outreach noise, and compliance restrictions. • Tech-Trend Linking (8 pts):Actionable landing points for AIGC, privacy computing, and event-driven operations. • Implementation Roadmap (9 pts):Phased objectives (0–3/3–6/6–12 months) with ...
-
[58]
Identify Citibank’s core competitive advantages
-
[59]
Analyze and assess Tesla’s key financial needs
-
[60]
extracted_final_answer
Design a targeted comprehensive corporate banking solution ... User Query {origin_query} Output Requirement • provide clear background context, • specify concrete analytical objectives, • introduce necessary constraints, • organize the task into well-defined sections. </user> Figure 11: Query refinement prompt used to transform raw user queries into struc...
-
[61]
mentioning a concept
Evidence-Driven: Every point awarded must be supported by specific data, factual citations, or complete logical chains found in the report. Merely "mentioning a concept" earns no points
-
[62]
Content lacking depth must be restricted to the middle or lowest scoring tiers
High-Score Threshold: Top-tier scores require the report content in that section to possess an extremely high information density and align perfectly with the grading criteria. Content lacking depth must be restricted to the middle or lowest scoring tiers
-
[63]
surface-level statements
Granularity Check: If the report merely provides broad descriptions of phenomena without structured breakdowns and substantive argumentation, it should be deemed as lacking support. You must differentiate between "surface-level statements" and "in-depth analysis" based on the grading criteria. ### Evaluation Process To ensure the objectivity and accuracy ...
-
[64]
Ensure the extracted content is closely related to the dimension and can objectively support your score
Extract Text: For each secondary dimension, first locate the corresponding text content in the full report, such as specific facts, data, or logical chains. Ensure the extracted content is closely related to the dimension and can objectively support your score
-
[65]
Point out specific areas in the report where there is a lack of evidence, logical gaps, or insufficient granularity
Identify Shortcomings: Objectively analyze whether the argumentation under that dimension forms a closed loop. Point out specific areas in the report where there is a lack of evidence, logical gaps, or insufficient granularity
-
[66]
Align with Tier: Strictly compare the extracted text content with the tier descriptions (e.g., 7-8 points, 4-6 points) under that dimension to determine which tier the report falls into
-
[67]
dimension_id
Precise Scoring: Within the determined tier range, assign a specific score based on the comprehensiveness of the evidence, and write a brief rationale for the points awarded or deducted. ### Grading Criteria {criteria_text} ### Research Report {report_text} ### Output Requirements Please directly output a valid JSON array containing the analysis and score...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.