Affordance-Based Hierarchical Reinforcement Learning for Quadruped Pedipulation
Pith reviewed 2026-06-27 21:31 UTC · model grok-4.3
The pith
A three-level hierarchical RL framework lets quadruped robots autonomously select poses and interaction points for object manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
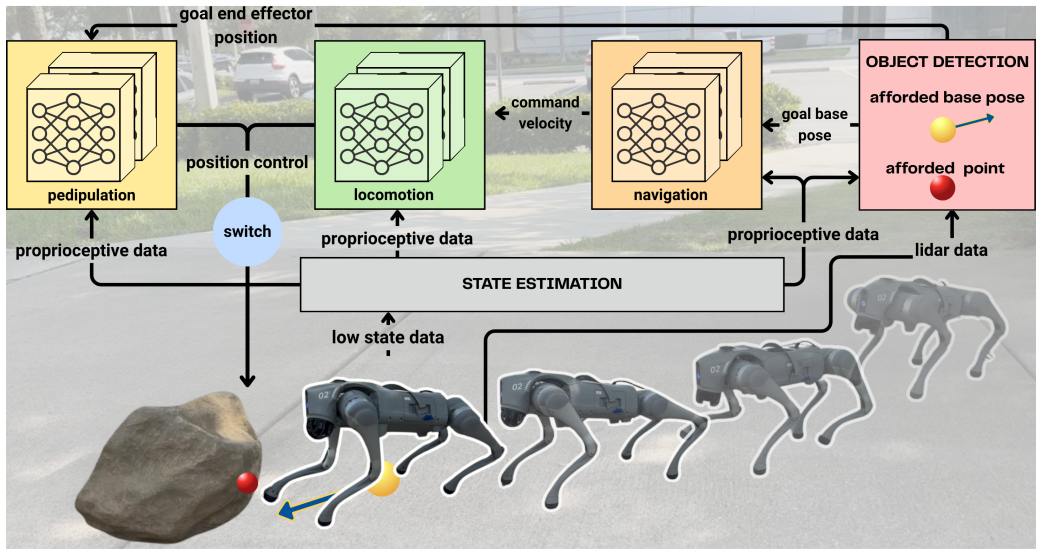
The proposed three-level hierarchical reinforcement learning framework utilizes pose affordances to guide the navigation policy, while the navigation policy drives the locomotion policy; the pedipulation policy is guided by interaction-point affordances, enabling object-centric pose alignment of the quadruped robot and effective end-effector manipulation planning. Trained in the IsaacSim ecosystem, the framework allows autonomous identification of candidate poses based on their affordance and successful execution of object manipulation tasks in both simulation and real-world settings without human guidance.
What carries the argument
Three-level hierarchical RL framework that couples pose affordances to navigation and interaction-point affordances to pedipulation.
If this is right
- Autonomous selection of both robot base poses and object interaction points removes the need for pre-designed high-level trajectories.
- Object-centric alignment enables effective end-effector planning during manipulation.
- The same framework produces successful real-world task execution after simulation-only training across an object-interaction dataset.
Where Pith is reading between the lines
- The same affordance hierarchy might scale to bipeds or wheeled platforms if the pose and interaction affordance predictors are retrained for their kinematics.
- Adding online vision-based affordance updates could allow the robot to react to moved or deformed objects without retraining.
- Extending the hierarchy to multi-object scenes would test whether affordance competition can be resolved without additional arbitration layers.
Load-bearing premise
Affordance models and policies trained in simulation transfer to real hardware with sufficient fidelity for successful task execution across the tested scenarios.
What would settle it
A controlled real-world trial in which the robot consistently fails to complete the same manipulation tasks that succeed at high rates in simulation would falsify the transfer claim.
Figures



read the original abstract
The object manipulation capabilities of quadruped robots is an open research challenge. While previous studies have focused on low-level policy learning, task execution still relies on expert-designed high-level trajectories. Autonomous selection of both an affordable interaction point on the target object and an affordable robot base pose removes the need for pre-designed trajectories. This study proposes a three-level hierarchical reinforcement learning (RL) framework that utilizes pose affordances to guide the navigation policy, while the navigation policy drives the locomotion policy. In addition, the pedipulation policy is guided by interaction-point affordances, enabling object-centric pose alignment of the quadruped robot and effective end-effector manipulation planning. We train the proposed framework in the IsaacSim ecosystem and evaluate it in both simulation and real-world settings. We investigate the effectiveness of pose affordance across multiple scenarios in simulation while various object interaction tasks are validated on real-world setting forming an object-interaction dataset. The results show that the proposed framework can autonomously identify candidate poses based on their affordance and successfully execute object manipulation tasks in the real world without human guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-level hierarchical reinforcement learning framework for quadruped pedipulation that trains pose-affordance and interaction-point affordance models plus navigation, locomotion, and pedipulation policies entirely in IsaacSim; the affordances are used to autonomously select base poses and interaction points, enabling object manipulation tasks that are claimed to succeed in real-world hardware without human guidance or pre-designed trajectories.
Significance. If the real-world results hold with adequate quantitative support, the work would advance autonomous legged manipulation by demonstrating that affordance-guided HRL can remove reliance on expert high-level trajectories. The formation of a real-world object-interaction dataset and the explicit separation of pose selection from low-level control are concrete contributions that could be built upon.
major comments (2)
- [Abstract] Abstract: the central claim of successful real-world execution without human guidance is stated, yet the abstract (and available text) supplies no quantitative metrics, success rates, error bars, baseline comparisons, or training-stability statistics; this absence makes it impossible to assess whether the affordance models and policies actually deliver the asserted performance.
- [Abstract] Abstract / training description: all components (pose-affordance model, interaction-point affordance model, and the three-level HRL stack) are trained in simulation and asserted to transfer directly to hardware for contact-rich pedipulation; the manuscript gives no indication of domain randomization, actuator modeling, or hardware-specific calibration, which are load-bearing for the sim-to-real claim given the sensitivity of quadruped contact dynamics.
minor comments (1)
- [Abstract] Abstract: the acronym 'HRL' and the term 'pedipulation' appear without an initial definition or expansion, which reduces immediate readability for a broad robotics audience.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to better present the quantitative support for our claims and the sim-to-real aspects of the work. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of successful real-world execution without human guidance is stated, yet the abstract (and available text) supplies no quantitative metrics, success rates, error bars, baseline comparisons, or training-stability statistics; this absence makes it impossible to assess whether the affordance models and policies actually deliver the asserted performance.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will update the abstract to report success rates on the real-world object-interaction dataset, along with relevant simulation metrics, error bars, and references to the baseline comparisons and training-stability statistics already present in the main text. revision: yes
-
Referee: [Abstract] Abstract / training description: all components (pose-affordance model, interaction-point affordance model, and the three-level HRL stack) are trained in simulation and asserted to transfer directly to hardware for contact-rich pedipulation; the manuscript gives no indication of domain randomization, actuator modeling, or hardware-specific calibration, which are load-bearing for the sim-to-real claim given the sensitivity of quadruped contact dynamics.
Authors: The referee is correct that the current manuscript does not describe the sim-to-real transfer techniques. We will add an explicit subsection detailing the domain randomization, actuator modeling, and hardware calibration procedures used in IsaacSim that enabled the observed real-world transfer. revision: yes
Circularity Check
No significant circularity; empirical RL framework is self-contained
full rationale
The paper describes a three-level hierarchical RL framework that trains affordance models and policies in IsaacSim for quadruped pedipulation tasks, then evaluates transfer to real hardware. No equations, derivations, or first-principles results are presented that reduce any claimed prediction to its own inputs by construction. The central claims rest on empirical training success and real-world task execution rather than self-definitional fits, fitted-input predictions, or load-bearing self-citations. Any internal citations would be incidental and not required to close the argument, satisfying the condition for a self-contained empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mars curiosity rover mobility trends during the first 7 years,
A. Rankin, M. Maimone, J. Biesiadecki, N. Patel, D. Levine, and O. Toupet, “Mars curiosity rover mobility trends during the first 7 years,” Journal of Field Robotics, vol. 38, no. 5, pp. 759–800, 2021
2021
-
[2]
Reinforcement learning and sim-to-real transfer of reorientation and landing control for quadruped robots on asteroids,
J. Qi, H. Gao, H. Su, M. Huo, H. Yu, and Z. Deng, “Reinforcement learning and sim-to-real transfer of reorientation and landing control for quadruped robots on asteroids,”IEEE Transactions on Industrial Electronics, vol. 71, no. 11, pp. 14 392–14 400, 2024
2024
-
[3]
Reinforcement learning for collabo- rative quadrupedal manipulation of a payload over challenging terrain,
Y . Ji, B. Zhang, and K. Sreenath, “Reinforcement learning for collabo- rative quadrupedal manipulation of a payload over challenging terrain,” in2021 IEEE 17th International Conference on Automation Science and Engineering (CASE). IEEE, 2021, pp. 899–904
2021
-
[4]
Learning advanced locomotion for quadrupedal robots: A distributed multi-agent reinforcement learning framework with riemannian motion policies,
Y . Wang, R. Sagawa, and Y . Yoshiyasu, “Learning advanced locomotion for quadrupedal robots: A distributed multi-agent reinforcement learning framework with riemannian motion policies,”Robotics, vol. 13, no. 6, p. 86, 2024
2024
-
[5]
Learning whole-body manipulation for quadrupedal robot,
S. Jeon, M. Jung, S. Choi, B. Kim, and J. Hwangbo, “Learning whole-body manipulation for quadrupedal robot,”IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 699–706, 2023
2023
-
[6]
Deep whole-body control: learning a unified policy for manipulation and locomotion,
Z. Fu, X. Cheng, and D. Pathak, “Deep whole-body control: learning a unified policy for manipulation and locomotion,” inConference on Robot Learning. PMLR, 2023, pp. 138–149
2023
-
[7]
Learning whole-body loco-manipulation for omni-directional task space pose tracking with a wheeled-quadrupedal-manipulator,
K. Jiang, Z. Fu, J. Guo, W. Zhang, and H. Chen, “Learning whole-body loco-manipulation for omni-directional task space pose tracking with a wheeled-quadrupedal-manipulator,”IEEE Robotics and Automation Letters, vol. 10, no. 2, pp. 1481–1488, 2024
2024
-
[8]
Mlm: Learning multi-task loco-manipulation whole-body control for quadruped robot with arm,
X. Liu, B. Ma, C. Qi, Y . Ding, N. Xu, G. Zhang, P. Chen, K. Liu, Z. Jia, C. Guanet al., “Mlm: Learning multi-task loco-manipulation whole-body control for quadruped robot with arm,”IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 81–88, 2025
2025
-
[9]
Perceptive pedipulation with local obstacle avoidance,
J. Stolle, P. Arm, M. Mittal, and M. Hutter, “Perceptive pedipulation with local obstacle avoidance,” in2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids). IEEE, 2024, pp. 157– 164
2024
-
[10]
Legs as manipulator: Pushing quadrupedal agility beyond locomotion,
X. Cheng, A. Kumar, and D. Pathak, “Legs as manipulator: Pushing quadrupedal agility beyond locomotion,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 5106–5112
2023
-
[11]
Pedipulate: Enabling manipulation skills using a quadruped robot’s leg,
P. Arm, M. Mittal, H. Kolvenbach, and M. Hutter, “Pedipulate: Enabling manipulation skills using a quadruped robot’s leg,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5717–5723
2024
-
[12]
Towards obstacle-aided locomotion: Robot mobility and ter- rain manipulation through leg-ground interactions,
H. Hu, “Towards obstacle-aided locomotion: Robot mobility and ter- rain manipulation through leg-ground interactions,” Ph.D. dissertation, University of Southern California, 2026
2026
-
[13]
Learning rock pushability on rough planetary terrain,
T. Girgin, E. Girgin, and C. Kilic, “Learning rock pushability on rough planetary terrain,”arXiv preprint arXiv:2505.09833, 2025
arXiv 2025
-
[14]
Object play by adult animals,
S. L. Hall, “Object play by adult animals,”Animal play: Evolutionary, comparative, and ecological perspectives, pp. 45–60, 1998
1998
-
[15]
Scientific exploration of chal- lenging planetary analog environments with a team of legged robots,
P. Arm, G. Waibel, J. Preisig, T. Tuna, R. Zhou, V . Bickel, G. Ligeza, T. Miki, F. Kehl, H. Kolvenbachet al., “Scientific exploration of chal- lenging planetary analog environments with a team of legged robots,” Science robotics, vol. 8, no. 80, p. eade9548, 2023
2023
-
[16]
Circus anymal: A quadruped learning dexter- ous manipulation with its limbs,
F. Shi, T. Homberger, J. Lee, T. Miki, M. Zhao, F. Farshidian, K. Okada, M. Inaba, and M. Hutter, “Circus anymal: A quadruped learning dexter- ous manipulation with its limbs,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 2316–2323
2021
-
[17]
M. Sombolestan and Q. Nguyen, “Hierarchical adaptive motion planning with nonlinear model predictive control for safety-critical collaborative loco-manipulation,”arXiv preprint arXiv:2411.10699, 2024
arXiv 2024
-
[18]
Manipulate-to-navigate: Reinforcement learning with visual affordances and manipulability priors,
Y . Zhang and J. Pajarinen, “Manipulate-to-navigate: Reinforcement learning with visual affordances and manipulability priors,”arXiv preprint arXiv:2508.13151, 2025
arXiv 2025
-
[19]
Hierarchical reinforcement learning for quadrupedal robots: Efficient object manipulation in constrained environments,
D. Azimi and R. Hoseinnezhad, “Hierarchical reinforcement learning for quadrupedal robots: Efficient object manipulation in constrained environments,”Sensors, vol. 25, no. 5, p. 1565, 2025
2025
-
[20]
Learning multi-agent loco-manipulation for long-horizon quadrupedal pushing,
Y . Feng, C. Hong, Y . Niu, S. Liu, Y . Yang, and D. Zhao, “Learning multi-agent loco-manipulation for long-horizon quadrupedal pushing,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 14 441–14 448
2025
-
[21]
Simultaneous locomotion and manipulation control of quadruped robots using reinforcement learning-based adaptive fractional-order sliding-mode control,
Y . Farid, “Simultaneous locomotion and manipulation control of quadruped robots using reinforcement learning-based adaptive fractional-order sliding-mode control,”Transactions of the Institute of Measurement and Control, vol. 45, no. 13, pp. 2459–2476, 2023
2023
-
[22]
Learning visual quadrupedal loco-manipulation from demonstrations,
Z. He, K. Lei, Y . Ze, K. Sreenath, Z. Li, and H. Xu, “Learning visual quadrupedal loco-manipulation from demonstrations,” in2024 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2024, pp. 9102–9109
2024
-
[23]
Bipedalism for quadrupedal robots: Versatile loco-manipulation through risk-adaptive reinforcement learning,
Y . Zhang, R. Corcodel, and D. Zhao, “Bipedalism for quadrupedal robots: Versatile loco-manipulation through risk-adaptive reinforcement learning,” in2025 IEEE-RAS 24th International Conference on Hu- manoid Robots (Humanoids). IEEE, 2025, pp. 736–743
2025
-
[24]
The theory of affordances,
J. J. Gibson, “The theory of affordances,”Hilldale, USA, vol. 1, no. 2, pp. 67–82, 1977
1977
-
[25]
Learning robotic locomotion affordances and photorealistic simulators from human- captured data,
A. Escontrela, J. Kerr, K. Stachowicz, and P. Abbeel, “Learning robotic locomotion affordances and photorealistic simulators from human- captured data,” inConference on Robot Learning. PMLR, 2025, pp. 5434–5445
2025
-
[26]
Aquro: A cat-like adaptive quadruped robot with novel bio-inspired capabilities,
A. A. Saputra, N. Takesue, K. Wada, A. J. Ijspeert, and N. Kubota, “Aquro: A cat-like adaptive quadruped robot with novel bio-inspired capabilities,”Frontiers in Robotics and AI, vol. 8, p. 562524, 2021
2021
-
[27]
Neuro-cognitive locomotion with dynamic attention on topological structure,
A. A. Saputra, J. Botzheim, and N. Kubota, “Neuro-cognitive locomotion with dynamic attention on topological structure,”Machines, vol. 11, no. 6, p. 619, 2023
2023
-
[28]
Non-prehensile robotic pushing strategies for sloped terrain and planetary surface conditions,
T. Girgin and C. Kilic, “Non-prehensile robotic pushing strategies for sloped terrain and planetary surface conditions,” inAIAA SCITECH 2026 F orum, 2026, p. 2245
2026
-
[29]
Prox- imal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[30]
Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning,
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano- Mu˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudinet al., “Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[31]
Ocelot: Odometry and contact estimation for legged robots,
E. Girgin and C. Kilic, “Ocelot: Odometry and contact estimation for legged robots,” 2026. [Online]. Available: https://arxiv.org/abs/2605. 21863
2026
-
[32]
Onnx runtime,
O. R. developers, “Onnx runtime,” https://onnxruntime.ai/, 2021, ver- sion: x.y.z
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.