M2Note: Continual Evolution of Vision Language Models via Mistake Notebook Learning
Pith reviewed 2026-07-02 03:27 UTC · model grok-4.3
The pith
Vision language models improve by turning past mistakes into reusable subject-guidance notes retrieved at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
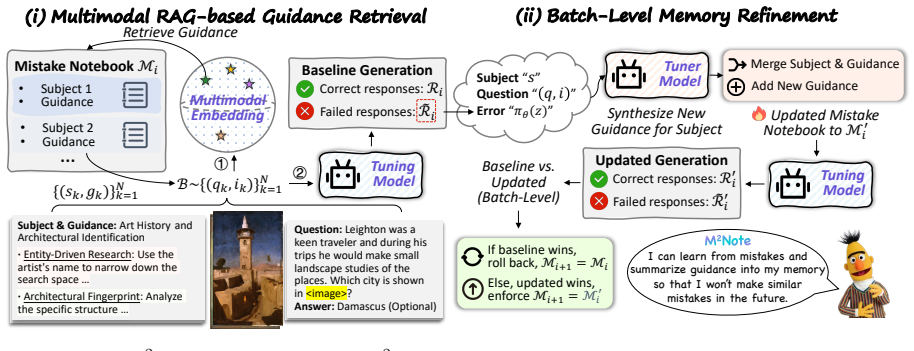
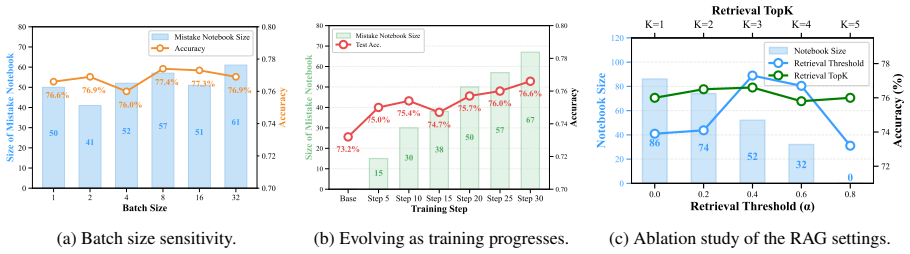
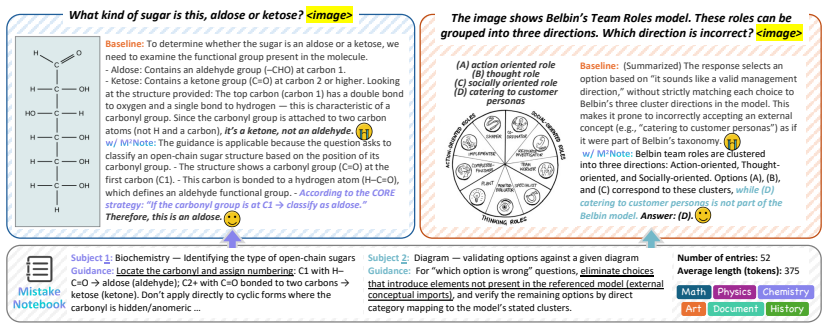
M2Note transforms failed trajectories into subject-guidance notes that summarize the underlying domain and concept while supplying actionable verification steps; these notes are stored in an editable memory and retrieved via multimodal RAG to append to the model context, steering reasoning away from previously observed pitfalls, with batch-level post-verification committing edits only when they improve performance on the same batch.
What carries the argument
The mistake notebook storing subject-guidance notes derived from failed trajectories, retrieved by multimodal RAG to guide future inference.
If this is right
- Consistent accuracy gains appear across six multimodal reasoning benchmarks and multiple model backbones.
- The method uses far fewer samples and lower compute than supervised fine-tuning or reinforcement learning.
- Performance gains remain additive when combined with Chain-of-Thought prompting.
- Capability transfer occurs from stronger supervisor models to weaker solvers without updating weights.
Where Pith is reading between the lines
- Over many tasks the notebook could grow into a durable external memory that accumulates domain-specific checks for long-running agents.
- The same note format might be applied to pure language or other modality models if failure traces can be parsed into subject-guidance pairs.
- Rollback verification could be extended to streaming data streams to guard against gradual degradation in deployed systems.
Load-bearing premise
The notes extracted from failures are accurate, non-conflicting, and retrievable in a form that reliably steers reasoning without introducing new errors.
What would settle it
Running the base VLM with and without the retrieved notes on a fresh multimodal reasoning benchmark and finding no accuracy gain or an accuracy drop when the notes are present.
Figures


read the original abstract
Vision Language Models (VLMs) have demonstrated remarkable capabilities in multimodal reasoning tasks, yet they still suffer from recurring failures, such as skipping key visual checks, misapplying domain rules, and hallucinating unsupported concepts. Most existing solutions rely on supervised fine-tuning (SFT) and reinforcement learning (RL), which are expensive to iterate and can be brittle under distribution shift. To this end, we propose Multimodal Mistake Notebook Learning (M2Note), a training-free continual evolution framework that externalizes learning into an editable memory. M2Note transforms failed trajectories into compact subject-guidance notes: the subject summarizes the underlying domain and concept, while the guidance provides actionable verification steps that can be reused in future inference. At test time, M2Note retrieves relevant notes via multimodal retrieval-augmented generation (RAG) and appends them to the model context, steering reasoning away from previously observed pitfalls. To stabilize continual evolution, we adopt batch-level post-verification with rollback, which commits notebook edits only if they improve performance on the same batch, reducing noisy updates and preventing regressions. M2Note supports both self-evolving, where the same VLM acts as solver and supervisor, and cross-model evolving, where a stronger supervisor guides a weaker solver, enabling capability transfer without weight updates. Experiments on six multimodal reasoning benchmarks show consistent improvements across domains and backbones, while achieving strong cost and sample efficiency and remaining complementary to Chain-of-Thought (CoT) prompting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes M2Note, a training-free continual evolution framework for Vision Language Models that externalizes learning from failed trajectories into an editable external 'mistake notebook' consisting of subject-guidance notes. These notes are generated to summarize domain concepts and provide verification steps, then retrieved at inference via multimodal RAG to augment the context and avoid past errors. Stabilization uses batch-level post-verification with rollback, committing edits only when they improve performance on the generating batch. The method supports both self-evolving and cross-model setups. Experiments are claimed to show consistent improvements on six multimodal reasoning benchmarks across domains and backbones, with cost/sample efficiency and complementarity to CoT prompting.
Significance. If the performance claims and generalization of the notes hold under scrutiny, the approach would represent a practical, low-cost alternative to SFT/RL for addressing recurring VLM failures in multimodal reasoning, enabling continual improvement via external memory without weight updates. It could complement prompting methods and facilitate capability transfer between models.
major comments (2)
- [Abstract] Abstract (method description): The batch-level post-verification commits notebook edits only if they improve performance on the identical batch used to generate the notes. This implicitly assumes in-batch gains transfer to unseen queries without introducing conflicts or noise upon multimodal RAG retrieval, yet the description provides no cross-batch validation, held-out testing, or analysis of note conflicts to support the claim that it 'reduces noisy updates and prevents regressions.'
- [Abstract] Abstract: The central claim of 'consistent improvements across domains and backbones' on six benchmarks, along with cost/sample efficiency, is asserted without any quantitative results, baseline comparisons, ablation studies, statistical tests, or experimental protocol details. This renders the primary empirical contribution unevaluable and prevents assessment of whether the notes reliably steer reasoning without new errors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below with clarifications from the full manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (method description): The batch-level post-verification commits notebook edits only if they improve performance on the identical batch used to generate the notes. This implicitly assumes in-batch gains transfer to unseen queries without introducing conflicts or noise upon multimodal RAG retrieval, yet the description provides no cross-batch validation, held-out testing, or analysis of note conflicts to support the claim that it 'reduces noisy updates and prevents regressions.'
Authors: The abstract description is intentionally concise. The full manuscript (Section 3.3 and 4.2) details the batch-level post-verification mechanism and includes held-out testing across batches plus analysis of note conflicts during multimodal RAG retrieval, showing that in-batch gains transfer without introducing regressions or noise. To make this explicit in the abstract, we will add a brief clause referencing the validation approach. revision: yes
-
Referee: [Abstract] Abstract: The central claim of 'consistent improvements across domains and backbones' on six benchmarks, along with cost/sample efficiency, is asserted without any quantitative results, baseline comparisons, ablation studies, statistical tests, or experimental protocol details. This renders the primary empirical contribution unevaluable and prevents assessment of whether the notes reliably steer reasoning without new errors.
Authors: Abstracts conventionally summarize rather than report full numbers. The complete manuscript (Sections 5 and 6) provides the requested details: tables with quantitative improvements on all six benchmarks across multiple backbones, baseline comparisons (including CoT), ablation studies on note components, statistical tests, full protocols, and evidence that retrieved notes improve reasoning without new errors. We will incorporate 1-2 key quantitative highlights into the abstract for better self-containment. revision: partial
Circularity Check
No circularity: method is training-free external memory with no fitted predictions or self-referential derivations
full rationale
The paper describes a training-free continual evolution framework that externalizes learning into an editable memory via subject-guidance notes and multimodal RAG retrieval, with batch-level post-verification for stabilization. No equations, fitted parameters, or quantitative predictions appear in the abstract or described method. The central claims rest on empirical experiments across benchmarks rather than any derivation chain that reduces to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The approach is self-contained as an algorithmic description without mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A diagram is worth a dozen images. InEuro- pean conference on computer vision, pages 235–251. Springer. 9 Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, and 1 others. 2020. Retrieval-augmented gen- eration for knowledge-intensive nlp tasks.Advan...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
Ahmed Nassar, Nikolaos Livathinos, Maksym Lysak, and Peter Staar
A survey of multimodal retrieval-augmented generation.arXiv preprint arXiv:2504.08748. Niklas Muennighoff, Zitong Yang, Weijia Shi, Xi- ang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. 2025. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Nat...
-
[3]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Prox- imal policy optimization algorithms.Preprint, arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Measuring multimodal mathematical reason- ing with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169. Qinsi Wang, Bo Liu, Tianyi Zhou, Jing Shi, Yueqian Lin, Yiran Chen, Hai Helen Li, Kun Wan, and Wentian Zhao. 2025a. Vision-zero: Scalable vlm self-improvement via strategic gamified self-play. Preprint, arXiv:2509.25541...
-
[5]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Large language models as optimizers. In The Twelfth International Conference on Learning Representations. Zhibo Yang, Jun Tang, Zhaohai Li, Pengfei Wang, Jian- qiang Wan, Humen Zhong, Xuejing Liu, Mingkun Yang, Peng Wang, Shuai Bai, and 1 others. 2025. Cc-ocr: A comprehensive and challenging ocr bench- mark for evaluating large multimodal models in lit- e...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Primary Domain (e.g., Combinatorics, Complex Analysis, Linear Algebra, Physics, Programming, Document Understanding)
-
[7]
Problem Type (e.g., counting with con- straints, roots of unity products, debugging API parameters, OCR table extraction)
-
[8]
Output only the finalized subject label(s)
Solution Method (e.g., stars and bars, polynomial/root identities, Hensel’s lemma, reproduce-minimize-fix) Examples of GOOD subjects (specific): ✓Complex Analysis: Evaluating products over roots of unity using polynomial eval- uation and complex identities ✓Document Understanding: Extracting ta- bles from scanned PDFs using layout detec- tion + OCR + row/...
2048
-
[9]
Does the current problem match the appli- cability conditions stated in the guidance?
-
[10]
Is the problem type and context similar to the examples in the guidance?
-
[11]
If the problem is totally different (e.g., combinatorics vs modulo arithmetic, complex numbers vs number theory), do NOT force-fit the guidance
-
[12]
Guid- ance Extraction
Only use guidance that is clearly relevant to the current problem. Gudience Subject: {subject} - {guidance} Before solving, review the guidance. State whether it is: applicable, partially applicable, or irrelevant. Use only applicable parts. Since the guidance introduced via multimodal RAG (Lewis et al., 2020; Mei et al., 2025) may not necessarily apply t...
2020
-
[13]
Derive the exact molecular formula (count all atoms)
-
[14]
For each element: available atoms ÷ re- quired per molecule⇒max molecules
-
[15]
The smallest quotient determines the max- imum yield (the limiting element)
-
[16]
Sanity-check: if quotients look inconsis- tent, recheck formula/inventory
-
[17]
BoundaryNot for non-stoichiometric set- tings (catalysis, equilibrium-limited yield) or inventories with impurities/intermediates not modeled
Confirm the final answer satisfies the lim- iting element’s requirement exactly. BoundaryNot for non-stoichiometric set- tings (catalysis, equilibrium-limited yield) or inventories with impurities/intermediates not modeled. 15 Note 4: Education TaskIdentify a classroom activity for literary analysis via role-play and multi-perspective retelling (media sim...
-
[18]
Build a conflict graph: exams = vertices; edges = shared students/resources
-
[19]
Color the graph (greedy or exact), enforc- ing all pairwise conflicts
-
[20]
Validate the schedule: no student may have two exams in the same slot/day
-
[21]
If violations occur, re-solve using back- tracking/constraint propagation
-
[22]
mistake- driven
Re-check feasibility against real-world rules (concurrency constraints). BoundaryNot for dynamic/time-dependent constraints beyond a static conflict graph, or when intra-day sequencing/rooms must be modeled. C Experimental Settings C.1 Implementation Details Our supervised training settings on MMMU (Yue et al., 2024) and MathVista (Lu et al., 2023) are as...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.