Preference Optimization Drives Monoculture in LLM Prediction Markets
Pith reviewed 2026-06-26 02:43 UTC · model grok-4.3
The pith
Direct Preference Optimization causes LLM agents to converge on similar predictions, collapsing prediction market diversity to the power of roughly one forecaster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
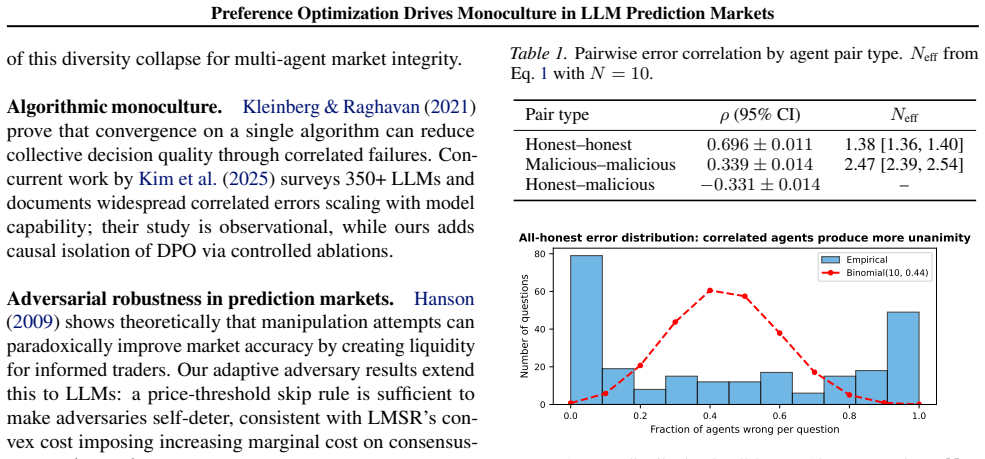
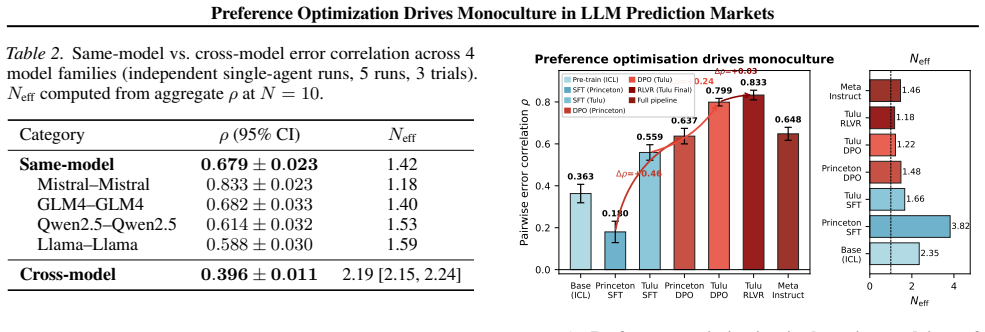
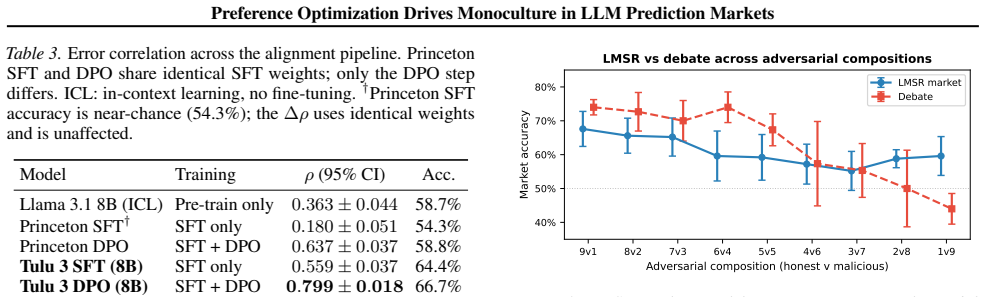
LLM agents fine-tuned with Direct Preference Optimization share a convergent output distribution, producing pairwise error correlations of ρ = 0.70 and reducing ten agents to the effective forecasting power of ≈1.4 independent forecasters Neff. This is not a scaling problem: Neff remains flat from N=5 to N=40, and the 10-agent market (67.6%) fails to match a single standalone agent (70.2%). Two controlled ablations isolate preference optimization as the causal driver, replicated across labs and scales (Δρ = +0.24 to +0.46 on identical-SFT controls at 8B and 70B). Among mitigations tested, cross-model diversity achieves the largest correlation reduction (ρ from 0.68 to 0.40).
What carries the argument
Direct Preference Optimization (DPO) as the mechanism that drives convergent output distributions across LLM agents, measured through pairwise error correlations and effective forecaster count Neff.
If this is right
- Prediction markets populated by DPO-tuned LLMs will exhibit lower accuracy than the sum of their individual capabilities due to shared errors.
- Scaling the number of DPO agents from 5 to 40 produces no gain in effective independent forecasts.
- A market of ten DPO agents underperforms one standalone agent on the same forecasting task.
- Cross-model diversity reduces error correlation more effectively than other tested mitigations.
Where Pith is reading between the lines
- Alignment methods that optimize for human preference may systematically reduce output diversity across decision-making tasks beyond forecasting.
- Markets or ensembles relying on LLMs may require deliberate injection of training heterogeneity to restore error independence.
- The observed monoculture could extend to other multi-agent LLM systems where participants draw from similar post-training pipelines.
Load-bearing premise
The ablations successfully isolate preference optimization as the sole causal driver of the observed correlations rather than other correlated factors in model training or task selection.
What would settle it
An experiment in which DPO-tuned models on the same tasks but with varied base architectures or prompt distributions show pairwise error correlations below 0.3 would falsify the convergence claim.
Figures

read the original abstract
Prediction markets rest on the independence of participant errors. As LLM agents become active traders on platforms like Kalshi and Polymarket, we ask: does this independence hold when the crowd is composed of LLMs? We find it does not. LLM agents fine-tuned with Direct Preference Optimization (DPO) share a convergent output distribution, producing pairwise error correlations of $\rho = 0.70$ and reducing ten agents to the effective forecasting power of ${\approx}1.4$ independent forecasters $N_{\text{eff}}$. This is not a scaling problem: $N_{\text{eff}}$ remains flat from $N=5$ to $N=40$, and the 10-agent market (67.6%) fails to match a single standalone agent (70.2%). Two controlled ablations isolate preference optimization as the causal driver, replicated across labs and scales ($\Delta\rho = +0.24$ to $+0.46$ on identical-SFT controls at 8B and 70B). Among mitigations tested, cross-model diversity achieves the largest correlation reduction ($\rho$ from 0.68 to 0.40). As LLMs become more aligned, markets built from them become more monocultural.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Direct Preference Optimization (DPO) induces convergent output distributions among LLM agents, leading to high pairwise error correlations (ρ=0.70) in prediction markets. This reduces ten agents to the effective power of ≈1.4 independent forecasters (N_eff), with N_eff flat from N=5 to N=40 and a 10-agent market accuracy of 67.6% underperforming a single agent at 70.2%. Two controlled ablations on identical-SFT controls at 8B and 70B scales are presented as isolating DPO as the causal driver (Δρ=+0.24 to +0.46), with cross-model diversity as the strongest mitigation (ρ reduced to 0.40).
Significance. If the central causal claim holds, the result identifies a concrete downside of preference optimization for collective intelligence tasks, with direct relevance to LLM deployment on platforms like Polymarket. The replication across scales and the finding that scaling fails to restore independence are notable empirical contributions. The controlled ablations, if fully isolated, provide a falsifiable test of the mechanism.
major comments (2)
- [Ablations and controls] Ablations (abstract and results): The claim that the two controlled ablations isolate DPO as the sole causal driver of Δρ=+0.24 to +0.46 requires explicit confirmation that SFT and DPO variants differ only in the preference step. Details on shared base model, identical SFT data/epochs, post-SFT updates, and preference datasets must be provided; any unmentioned differences would undermine the isolation and allow alternative explanations for the correlation increase.
- [Results on effective forecasters] N_eff and accuracy comparisons (abstract): The load-bearing claims that N_eff remains flat from N=5 to N=40 and that the 10-agent market (67.6%) underperforms a single agent (70.2%) require the exact definition/formula for N_eff, the underlying error correlation matrix, and statistical significance or error bars; without these, the reduction to ≈1.4 effective forecasters cannot be verified as robust.
minor comments (2)
- [Methods] The manuscript should include a dedicated methods section with model versions, training hyperparameters, dataset sources, and exact inference settings to allow replication of the reported ρ and N_eff values.
- [Results] Error bars or confidence intervals are missing from the reported correlations, accuracies, and Δρ values; these should be added to all quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the clarity of our causal claims and quantitative results. We address each major point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Ablations and controls] Ablations (abstract and results): The claim that the two controlled ablations isolate DPO as the sole causal driver of Δρ=+0.24 to +0.46 requires explicit confirmation that SFT and DPO variants differ only in the preference step. Details on shared base model, identical SFT data/epochs, post-SFT updates, and preference datasets must be provided; any unmentioned differences would undermine the isolation and allow alternative explanations for the correlation increase.
Authors: We agree that full isolation requires explicit documentation. The revised manuscript will add a dedicated 'Experimental Controls' subsection (and expand the Methods) confirming: (i) identical base models for each SFT/DPO pair, (ii) identical SFT datasets and training epochs, (iii) no post-SFT parameter updates prior to DPO, and (iv) identical preference datasets for the DPO stage. These controls were already used in the reported runs; we will now surface them explicitly so readers can verify that only the preference-optimization step differs. revision: yes
-
Referee: [Results on effective forecasters] N_eff and accuracy comparisons (abstract): The load-bearing claims that N_eff remains flat from N=5 to N=40 and that the 10-agent market (67.6%) underperforms a single agent (70.2%) require the exact definition/formula for N_eff, the underlying error correlation matrix, and statistical significance or error bars; without these, the reduction to ≈1.4 effective forecasters cannot be verified as robust.
Authors: We will add the exact formula N_eff = N / (1 + (N-1)ρ_avg) to the Methods, where ρ_avg is the mean pairwise error correlation across agents. The full correlation matrix (and per-N matrices) will be provided in an appendix. Accuracy figures will be reported with standard errors computed over multiple random seeds, and we will include a statistical comparison (paired t-test or bootstrap) between the 10-agent ensemble accuracy and the single-agent baseline. These additions will allow direct verification of the reported N_eff ≈ 1.4 and the flat scaling behavior. revision: yes
Circularity Check
No circularity: empirical measurements of correlations and Neff
full rationale
The paper reports direct experimental results on pairwise error correlations (ρ) and effective independent forecasters (Neff) from LLM agent outputs on prediction tasks. These quantities are computed from observed model predictions rather than derived via equations that reduce to fitted parameters or self-referential definitions. Ablations are presented as experimental controls isolating DPO effects, with no load-bearing steps that invoke self-citation chains, uniqueness theorems, or ansatzes smuggled from prior work. The central claims rest on falsifiable empirical data (e.g., 10-agent market accuracy vs. single agent) that do not collapse by construction to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Information Systems Frontiers , volume=
Combinatorial information market design , author=. Information Systems Frontiers , volume=
-
[2]
The Journal of Prediction Markets , volume=
Logarithmic market scoring rules for modular combinatorial information aggregation , author=. The Journal of Prediction Markets , volume=
-
[3]
2004 , publisher=
The Wisdom of Crowds , author=. 2004 , publisher=
2004
-
[4]
Nature , volume=
Vox populi , author=. Nature , volume=
-
[5]
Advances in Neural Information Processing Systems , year=
Self-refine: Iterative refinement with self-feedback , author=. Advances in Neural Information Processing Systems , year=
-
[6]
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle=
-
[7]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R , journal=
-
[8]
Meng, Yu and Xia, Mengzhou and Chen, Danqi , booktitle=
-
[9]
Advances in Neural Information Processing Systems , year=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2305.14325 , year=
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. arXiv preprint arXiv:2305.14325 , year=
-
[12]
arXiv preprint arXiv:2305.19118 , year=
Encouraging Divergent Thinking in Large Language Models through Debate , author=. arXiv preprint arXiv:2305.19118 , year=
-
[13]
Nature , volume=
A solution to the single-question crowd wisdom problem , author=. Nature , volume=
-
[14]
arXiv preprint arXiv:2207.05221 , year=
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[15]
Lambert, Nathan and Morrison, Jacob and Pyatkin, Valentina and Huang, Shengyi and Ivison, Hamish and others , howpublished=
-
[16]
Bell System Technical Journal , volume=
A New Interpretation of Information Rate , author=. Bell System Technical Journal , volume=
-
[17]
Zephyr: Direct Distillation of
Tunstall, Lewis and Beeching, Edward and Lambert, Nathan and Rajani, Nazneen and Rasul, Kashif and Belkada, Younes and Huang, Shengyi and von Werra, Leandro and Fourrier, Cl. Zephyr: Direct Distillation of. arXiv preprint arXiv:2310.16944 , year=
-
[18]
Cui, Ganqu and Yuan, Lifan and Ding, Ning and Yao, Guanming and He, Bingxiang and Zhu, Wei and Ni, Yuan and Xie, Guotong and Xie, Ruobing and Lin, Yankai and others , journal=
-
[19]
arXiv preprint arXiv:2407.21783 , year=
The. arXiv preprint arXiv:2407.21783 , year=
-
[20]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[21]
Reference-free Monolithic Preference Optimization with
Hong, Jiwoo and Lee, Noah and Thorne, James , journal=. Reference-free Monolithic Preference Optimization with
-
[22]
Chen, Jialin and Yang, Shuo and Liu, Ao and Liu, Xingyu , journal=. Can
-
[23]
1965 , publisher=
Survey Sampling , author=. 1965 , publisher=
1965
-
[24]
Kirk, Hannah R and Vidgen, Bertie and R. Understanding the Effects of. arXiv preprint arXiv:2309.02301 , year=
-
[25]
Journal of Economic Perspectives , volume=
Prediction Markets , author=. Journal of Economic Perspectives , volume=
-
[26]
Science , volume=
The Promise of Prediction Markets , author=. Science , volume=
-
[27]
International Journal of Forecasting , volume=
Prediction Market Accuracy in the Long Run , author=. International Journal of Forecasting , volume=
-
[28]
Journal of Political Economy , volume=
A Theory of Fads, Fashion, Custom, and Cultural Change as Informational Cascades , author=. Journal of Political Economy , volume=
-
[29]
The Quarterly Journal of Economics , volume=
A Simple Model of Herd Behavior , author=. The Quarterly Journal of Economics , volume=
-
[30]
Proceedings of the National Academy of Sciences , volume=
Algorithmic Monoculture and Social Welfare , author=. Proceedings of the National Academy of Sciences , volume=
-
[31]
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and others , journal=
-
[32]
arXiv preprint arXiv:2406.04692 , year=
Mixture-of-Agents Enhances Large Language Model Capabilities , author=. arXiv preprint arXiv:2406.04692 , year=
-
[33]
Chan, Chi-Min and Chen, Weize and Su, Yusheng and Yu, Jianxuan and Xue, Wei and Zhang, Shanghang and Fu, Jie and Liu, Zhiyuan , booktitle=
-
[34]
International Conference on Machine Learning , year=
Scaling Laws for Reward Model Overoptimization , author=. International Conference on Machine Learning , year=
-
[35]
arXiv preprint arXiv:2307.15217 , year=
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author=. arXiv preprint arXiv:2307.15217 , year=
-
[36]
Shumailov, Ilia and Shumilo, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin , journal=
-
[37]
arXiv preprint arXiv:2108.07258 , year=
On the Opportunities and Risks of Foundation Models , author=. arXiv preprint arXiv:2108.07258 , year=
-
[38]
Advances in Neural Information Processing Systems , year=
Neural Network Ensembles, Cross Validation, and Active Learning , author=. Advances in Neural Information Processing Systems , year=
-
[39]
Advances in Neural Information Processing Systems , year=
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , author=. Advances in Neural Information Processing Systems , year=
-
[40]
arXiv preprint arXiv:2402.18563 , year=
Approaching Human-Level Forecasting with Language Models , author=. arXiv preprint arXiv:2402.18563 , year=
-
[41]
Wisdom of the Silicon Crowd:
Schoenegger, Philipp and Park, Peter S and Karger, Ezra and Tetlock, Philip E , journal=. Wisdom of the Silicon Crowd:
-
[42]
Journal of Economic Behavior & Organization , volume=
Information Aggregation and Manipulation in an Experimental Market , author=. Journal of Economic Behavior & Organization , volume=
-
[43]
International Conference on Machine Learning , year=
Correlated Errors in Large Language Models , author=. International Conference on Machine Learning , year=
-
[44]
Economica , volume=
A Manipulator Can Aid Prediction Market Accuracy , author=. Economica , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.