Estimating Association Between Paired Outcomes in Clustered Data with Informative Subgroup Size
Pith reviewed 2026-05-22 10:12 UTC · model grok-4.3
The pith
Three weighted estimating approaches adjust marginal association estimates for paired outcomes when cluster or subgroup size is informative.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose three weighted estimating approaches for marginal association between paired outcomes in clustered data. The weights are derived from within-cluster resampling arguments and extend inverse cluster-size and subgroup-size weighting to paired outcome categories. We also modify an existing ISS testing procedure by utilizing Stouffer's method to reduce computational burden.
What carries the argument
Weights derived from within-cluster resampling arguments that extend inverse cluster-size and subgroup-size weighting to paired outcome categories.
If this is right
- Pair-based weighting reduces bias when association arises through unit-level dependence and subgroup composition is informative.
- Typical inverse-cluster weighting remains more stable when the association is primarily carried by latent cluster-level structure.
- The modified testing procedure using Stouffer's method lowers computational burden for detecting informative subgroup size.
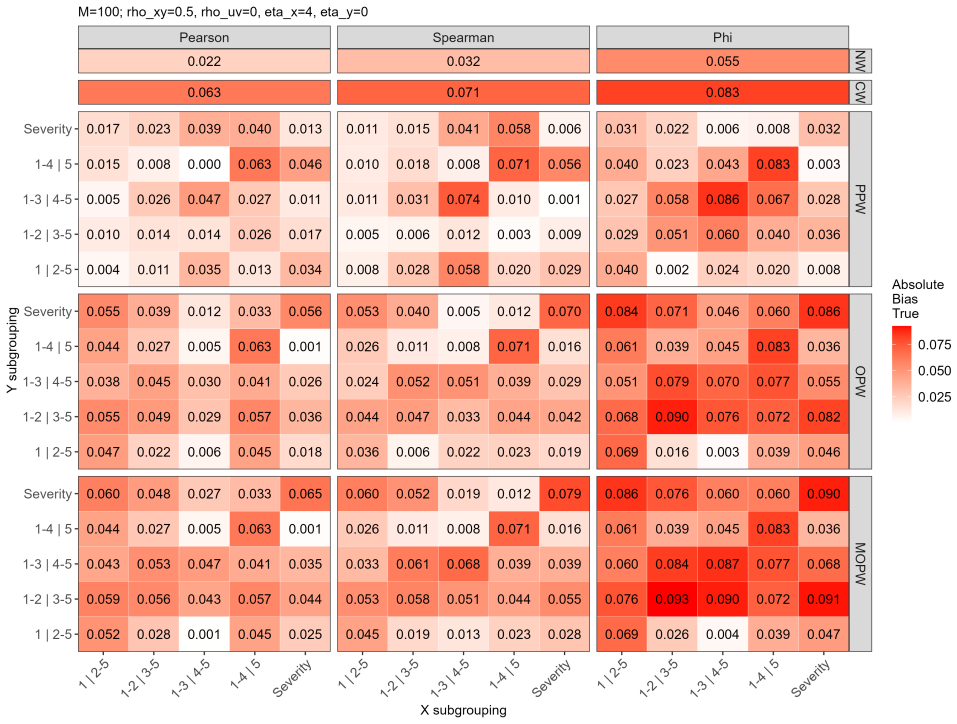
- In NHANES oral-health data, filled-surface outcomes show stronger evidence of informative subgroup size and greater sensitivity to pair-based weighting than decayed-surface outcomes.
Where Pith is reading between the lines
- Analysts may need to compare results across weighting schemes to assess how sensitive conclusions are to the assumed source of association.
- The resampling-weight approach could be adapted to settings with more than two outcomes per cluster or with time-to-event paired data.
- In fields that routinely analyze clustered pairs, such as dentistry or ophthalmology, routine reporting of both unweighted and weighted estimates would clarify robustness to informative size.
Load-bearing premise
The within-cluster resampling arguments yield weights that correctly adjust marginal association estimates for informative subgroup size across different sources of association without introducing bias from the weighting itself.
What would settle it
A simulation in which the true source of association (unit-level dependence versus latent cluster-level structure) is known in advance and the weighted estimators are checked for bias under controlled informative subgroup sizes.
Figures
read the original abstract
Informative cluster size (ICS) and informative subgroup size (ISS) can distort marginal association estimates when the number of observed units, or their distribution across outcome-defined categories, is related to the outcomes under study. This issue is especially relevant for paired outcomes, where the observed association can depend on cluster size, paired-category composition, and the process by which units become available for analysis. We propose three weighted estimating approaches for marginal association between paired outcomes in clustered data. The weights are derived from within-cluster resampling arguments and extend inverse cluster-size and subgroup-size weighting to paired outcome categories. We also modify an existing ISS testing procedure by utilizing Stouffer's method to reduce computational burden. To evaluate the methods, we develop a simulator for clustered paired outcomes that separates unit-level association, latent cluster-level association, and outcome-dependent retention. Simulations show that pair-based weighting can reduce bias when association arises through unit-level dependence and subgroup composition is informative, but can attenuate association carried by latent cluster-level structure. Typical inverse-cluster weighting remains more stable when the association is primarily cluster-level. Application to NHANES oral-health data shows small positive periodontal and caries associations overall, with filled-surface outcomes showing stronger ISS evidence and greater sensitivity to pair-based weighting than decayed-surface outcomes. These results indicate that marginal association under ICS and ISS should be interpreted in relation to the source of association, observed-unit structure, and assumptions used to choose the weighting scheme.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes three weighted estimating approaches for marginal association between paired outcomes in clustered data subject to informative cluster size (ICS) and informative subgroup size (ISS). Weights are derived from within-cluster resampling arguments and extend inverse cluster-size and subgroup-size weighting to paired outcome categories. A modified ISS testing procedure using Stouffer's method is also presented. Simulations separate unit-level association, latent cluster-level association, and outcome-dependent retention, showing pair-based weighting reduces bias under unit-level dependence with informative subgroup composition but attenuates association carried by latent cluster-level structure. Typical inverse-cluster weighting is more stable for cluster-level association. The methods are applied to NHANES oral-health data, showing small positive periodontal and caries associations with greater sensitivity to pair-based weighting for filled-surface outcomes.
Significance. If the performance claims hold, the work offers practical guidance for marginal association estimation in clustered paired data where ICS or ISS may distort estimates. The simulation design that isolates different sources of association is a clear strength, as it demonstrates when pair-based versus cluster-based weighting is preferable. The NHANES application illustrates real-world relevance in oral-health epidemiology. These contributions could help practitioners interpret marginal associations conditional on the suspected mechanism of association and observed-unit structure.
major comments (2)
- [§2] §2 (Weighted estimating approaches): The central claim that the within-cluster resampling weights correctly adjust marginal association estimates for ISS without introducing bias from the weighting itself is load-bearing. Simulations show attenuation under latent cluster-level association, which raises the question whether the target marginal parameter is preserved across mechanisms; an explicit derivation or statement of the estimand under each data-generating process would resolve whether the attenuation reflects bias or a change in the target.
- [Simulation study] Simulation study section: While the separation of unit-level versus cluster-level association sources is useful, the reported results do not include the true marginal association value under each simulation scenario. Without this benchmark, it is difficult to determine whether the observed attenuation under cluster-level structure indicates a problem with the weighting scheme or simply a correctly estimated but different marginal quantity.
minor comments (3)
- [Abstract] Abstract: The statement that pair-based weighting 'can attenuate association carried by latent cluster-level structure' is important but would benefit from a brief parenthetical note on the magnitude of attenuation observed in simulations.
- [Methods] Methods: Notation for the three weighting schemes could be introduced with a small illustrative table showing how inverse cluster-size and pair-based weights differ for a simple 2x2 paired outcome table.
- [Data application] Data application: Reporting the distribution of cluster sizes and the proportion of informative subgroups in the NHANES sample would help readers assess the practical relevance of the ISS findings.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of our work. The suggestions to clarify the target estimands and to report true marginal association values in the simulations are helpful for strengthening the interpretation of our results. We address each major comment below and have revised the manuscript to incorporate these clarifications.
read point-by-point responses
-
Referee: [§2] §2 (Weighted estimating approaches): The central claim that the within-cluster resampling weights correctly adjust marginal association estimates for ISS without introducing bias from the weighting itself is load-bearing. Simulations show attenuation under latent cluster-level association, which raises the question whether the target marginal parameter is preserved across mechanisms; an explicit derivation or statement of the estimand under each data-generating process would resolve whether the attenuation reflects bias or a change in the target.
Authors: We agree that an explicit statement of the estimand under each mechanism strengthens the manuscript. In the revised version, we have added a dedicated paragraph in Section 2 deriving the target marginal association parameter for the unit-level and latent cluster-level data-generating processes. Under unit-level dependence with informative subgroup size, the pair-based weights target the marginal association conditional on the realized subgroup composition, which is the natural parameter when association operates at the unit level. Under latent cluster-level association, the population marginal incorporates between-cluster variation; pair-based weighting then correctly targets a within-subgroup marginal that is attenuated relative to the unconditional quantity. This distinction shows that the observed attenuation is a consequence of targeting a different but well-defined estimand rather than bias induced by the weighting procedure itself. revision: yes
-
Referee: [Simulation study] Simulation study section: While the separation of unit-level versus cluster-level association sources is useful, the reported results do not include the true marginal association value under each simulation scenario. Without this benchmark, it is difficult to determine whether the observed attenuation under cluster-level structure indicates a problem with the weighting scheme or simply a correctly estimated but different marginal quantity.
Authors: We appreciate this point and have now included the analytically derived true marginal association values for each simulation scenario in the revised tables and accompanying text. These benchmarks confirm that, when association is generated at the unit level with informative subgroup composition, pair-based weighting recovers the true marginal with substantially lower bias. When association is generated at the latent cluster level, pair-based weighting estimates a different but correctly specified marginal (the average within-subgroup association), while standard inverse-cluster weighting recovers the unconditional marginal. The added values therefore demonstrate that the attenuation is not a defect in the weighting scheme but follows directly from the change in target parameter across mechanisms. revision: yes
Circularity Check
No significant circularity; weighting derivation is independent of target parameter
full rationale
The paper derives its three weighted estimating approaches from within-cluster resampling arguments that are presented as logically prior to and independent of the specific marginal association parameter being estimated. Simulations explicitly separate unit-level dependence, latent cluster-level association, and outcome-dependent retention to evaluate performance, providing an external benchmark rather than a self-referential loop. No equation or claim reduces a prediction or uniqueness result to a fitted input or self-citation by construction; the differential behavior under different association sources is reported as an empirical finding, not a tautology. The central claim therefore remains self-contained against the stated assumptions and simulation design.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Within-cluster resampling arguments extend to derive unbiased weights for paired outcome categories under informative subgroup size.
Reference graph
Works this paper leans on
-
[1]
Ying Huang and Brian Leroux. Informative cluster sizes for subcluster-level covariates and weighted generalized estimating equations.Biometrics, 67(3):843–851, 2011
work page 2011
-
[2]
Ming Wang, Maiying Kong, and Somnath Datta. Inference for marginal linear models for clustered longitudinal data with potentially informative cluster sizes.Statistical Methods in Medical Research, 20(4):347–367, 2011
work page 2011
-
[3]
Samuel Anyaso-Samuel, Somnath Datta, Eva Roos, and Jaakko Nevalainen. Can the unit size predict outcomes? testing for informativeness in three-level designs.Statistics in Medicine, 44(6):e70041, 2025
work page 2025
-
[4]
Elaine B Hoffman, Pranab K Sen, and Clarice R Weinberg. Within-cluster resampling. Biometrika, 88(4):1121–1134, 2001
work page 2001
-
[5]
Marginal analyses of clustered data when cluster size is informative.Biometrics, 59(1):36–42, 2003
John M Williamson, Somnath Datta, and Glen A Satten. Marginal analyses of clustered data when cluster size is informative.Biometrics, 59(1):36–42, 2003
work page 2003
-
[6]
Sandipan Dutta and Somnath Datta. A rank-sum test for clustered data when the number of subjects in a group within a cluster is informative.Biometrics, 72(2):432–440, 2016
work page 2016
-
[7]
Marginal association measures for clustered data.Statistics in medicine, 30(27):3181–3191, 2011
Douglas J Lorenz, Somnath Datta, and Susan J Harkema. Marginal association measures for clustered data.Statistics in medicine, 30(27):3181–3191, 2011
work page 2011
-
[8]
Douglas J Lorenz, Steven Levy, and Somnath Datta. Inferring marginal association with paired and unpaired clustered data.Statistical methods in medical research, 27(6):1806– 1817, 2018. 26
work page 2018
-
[9]
Shaun R Seaman, Menelaos Pavlou, and Andrew J Copas. Methods for observed-cluster inference when cluster size is informative: a review and clarifications.Biometrics, 70(2): 449–456, 2014
work page 2014
-
[10]
Robert Durand, Arezou Roufegarinejad, Fatiha Chandad, Pierre H Rompr´ e, Ren´ e Voyer, Bryan S Michalowicz, and Elham Emami. Dental caries are positively associated with periodontal disease severity.Clinical Oral Investigations, 23(10):3811–3819, 2019
work page 2019
-
[11]
Samuel Anyaso-Samuel and Somnath Datta. Testing for marginal covariate effect when the subgroup size induced by the covariate is informative.Statistical Methods in Medical Research, 33(7):1264–1277, 2024
work page 2024
-
[12]
Samuel A Stouffer, Edward A Suchman, Leland C DeVinney, Shirley A Star, and Robin M Williams Jr.The american soldier: Adjustment during army life.(studies in social psy- chology in world war ii), vol. 1. Princeton Univ. Press, 1949. 27
work page 1949
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.