CVA6-RT: an Open-Source Time-Predictable RV64 Processor for Mixed-Criticality Systems
Pith reviewed 2026-06-26 01:00 UTC · model grok-4.3
The pith
CVA6-RT adds TLB locks, scratchpad caches and hardware context stacking to the CVA6 core for 12-cycle interrupt latency in real-time use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
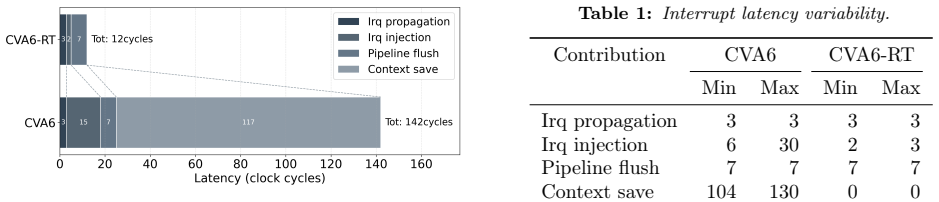
CVA6-RT implements the rv64gch ISA and features advanced support for real-time execution, including TLB partitioning and locking for predictable address translation, a dynamically reconfigurable scratchpad mode in the L1 caches for deterministic memory access, and low-latency interrupt handling via an enhanced interrupt controller combined with hardware-assisted context stacking. With real-time features enabled, CVA6-RT achieves an interrupt latency of 12 cycles, comparable to that of simpler Arm Cortex-M microcontrollers, and 10x lower than the baseline CVA6 core.
What carries the argument
The set of micro-architectural extensions consisting of TLB partitioning and locking, dynamically reconfigurable scratchpad L1 caches, and an enhanced interrupt controller with hardware-assisted context stacking.
If this is right
- Worst-case execution times for critical tasks become bounded even with complex memory systems active.
- Interrupt response on a 64-bit open-source core reaches speeds typical of simpler microcontrollers.
- The processor supports mode switching between high-performance and deterministic operation.
- Open-source RISC-V cores gain practical use in systems that previously required proprietary real-time hardware.
Where Pith is reading between the lines
- The scratchpad reconfiguration might allow runtime allocation of deterministic memory regions to the most critical tasks.
- Comparable extensions could be explored on other open RISC-V cores to close the predictability gap with commercial parts.
- Full-system tests with actual mixed-criticality applications would be needed to confirm the reported bounds hold end-to-end.
Load-bearing premise
The added hardware features will bound worst-case execution latency and reduce timing variability in actual mixed-criticality workloads without introducing new sources of unpredictability or unacceptable overhead.
What would settle it
Running the processor with real-time features enabled on representative mixed-criticality benchmarks and measuring an interrupt latency above 12 cycles or higher timing variability than the baseline.
Figures

read the original abstract
This work presents CVA6-RT, a real-time micro-architectural extension of the CVA6 core to bound worst-case latency and reduce task's timing execution variability. CVA6-RT implements the rv64gch ISA and features advanced support for real-time execution, including TLB partitioning and locking for predictable address translation, a dynamically reconfigurable scratchpad mode in the L1 caches for deterministic memory access, and low-latency interrupt handling via an enhanced interrupt controller combined with hardware-assisted context stacking. With real-time features enabled, CVA6-RT achieves an interrupt latency of 12 cycles, comparable to that of simpler Arm Cortex-M microcontrollers, and 10x lower than the baseline CVA6 core.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents CVA6-RT, a real-time micro-architectural extension of the open-source CVA6 RV64 core implementing the rv64gch ISA. It adds TLB partitioning and locking for predictable address translation, a dynamically reconfigurable scratchpad mode in the L1 caches for deterministic memory access, and an enhanced interrupt controller with hardware-assisted context stacking. The central quantitative claim is that, with real-time features enabled, CVA6-RT achieves an interrupt latency of 12 cycles—comparable to simpler Arm Cortex-M microcontrollers and 10x lower than the baseline CVA6 core—for use in mixed-criticality systems.
Significance. If the performance claims are substantiated, the work would be significant for delivering an open-source, time-predictable RISC-V processor suitable for safety-critical and mixed-criticality applications. The specific 10x reduction in interrupt latency and the combination of features for bounding worst-case latency represent a practical contribution to the field of predictable hardware.
major comments (2)
- [Abstract] Abstract: The claim of a 12-cycle interrupt latency is presented without any measurement methodology, benchmarks, error analysis, or verification approach. This prevents assessment of whether the data support the central performance claim.
- [Micro-architectural extensions] The descriptions of TLB partitioning/locking, dynamically reconfigurable scratchpad L1 caches, and the enhanced interrupt controller do not include analysis demonstrating that these extensions bound worst-case execution latency and reduce timing variability without introducing new sources of unpredictability or unacceptable overhead in mixed-criticality workloads.
minor comments (2)
- The abstract and introduction would benefit from explicit cross-references to the sections containing the evaluation methodology and results that support the 12-cycle latency figure.
- Consider clarifying the exact configuration of the baseline CVA6 used for the 10x comparison (e.g., cache sizes, pipeline details) to allow direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a 12-cycle interrupt latency is presented without any measurement methodology, benchmarks, error analysis, or verification approach. This prevents assessment of whether the data support the central performance claim.
Authors: We agree that the abstract would benefit from additional context. The full manuscript details the measurement approach in the evaluation section, using cycle-accurate RTL simulation, targeted interrupt-injection benchmarks, and trace-based verification. We will revise the abstract to concisely reference the simulation environment and benchmark methodology supporting the 12-cycle figure. revision: yes
-
Referee: [Micro-architectural extensions] The descriptions of TLB partitioning/locking, dynamically reconfigurable scratchpad L1 caches, and the enhanced interrupt controller do not include analysis demonstrating that these extensions bound worst-case execution latency and reduce timing variability without introducing new sources of unpredictability or unacceptable overhead in mixed-criticality workloads.
Authors: The manuscript includes design rationale and initial quantitative results on reduced variability. We acknowledge, however, that a more explicit analysis of worst-case latency bounding, potential new unpredictability sources, and overhead under mixed-criticality workloads is needed. We will add a dedicated subsection with this analysis and supporting experiments in the revised version. revision: yes
Circularity Check
No significant circularity detected
full rationale
The document is a hardware design description of micro-architectural extensions to CVA6. It presents implementation features (TLB partitioning, scratchpad caches, interrupt controller) and states measured results such as 12-cycle interrupt latency. No equations, parameter fitting, predictions derived from inputs, or self-citation chains appear in the provided abstract or described content. The central claims rest on engineering implementation and benchmarking rather than any derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Survey on Cache Management Mecha- nisms for Real-Time Embedded Systems
G. Gracioli et al. “A Survey on Cache Management Mecha- nisms for Real-Time Embedded Systems”. In:ACM Com- put. Surv. 48.2 (2015)
2015
-
[2]
Stellar Automotive Microcontrollers
STMicroelectronics. Stellar Automotive Microcontrollers. 2023
2023
-
[3]
A Beginner’s Guide on Interrupt Latency of the Arm Cortex-M processors
ARM Limited. A Beginner’s Guide on Interrupt Latency of the Arm Cortex-M processors . 2016
2016
-
[4]
The Cost of Application-Class Processing: Energy and Performance Analysis of a Linux- Ready 1.7-GHz 64-Bit RISC-V Core in 22-nm FDSOI Technology
F. Zaruba and L. Benini. “The Cost of Application-Class Processing: Energy and Performance Analysis of a Linux- Ready 1.7-GHz 64-Bit RISC-V Core in 22-nm FDSOI Technology”. In:IEEE Transactions on Very Large Scale Integration (VLSI) Systems 27.11 (2019). 2 RISC-V Summit Europe, Bologna, 8-12th June 2026
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.