When Should Forecasting Models Be Re-Specified? A Cost-Sensitive Trigger for Adaptive Model-Form Updating
Pith reviewed 2026-06-27 22:40 UTC · model grok-4.3
The pith
A cost-sensitive trigger based on specification debt decides when to re-specify a forecasting model's form.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
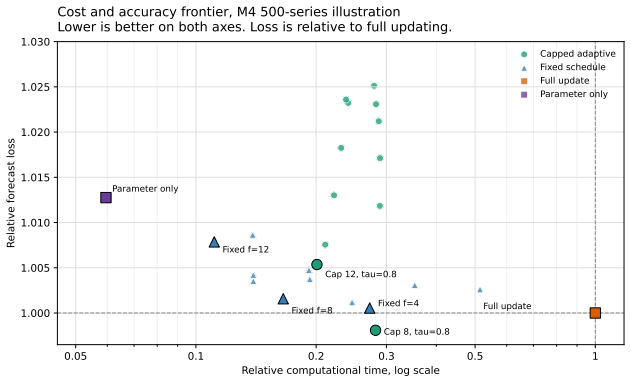
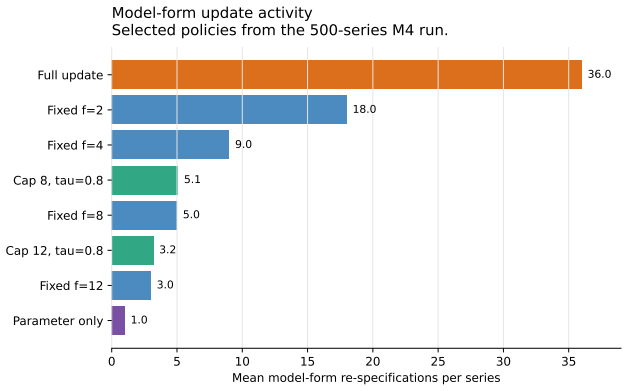
In a closed discrete model space the trigger reduces to a threshold on the negative log posterior probability of the deployed specification. In open production settings the same decision rule can be run with predictive score gaps, stacking weights, or calibrated monitoring diagnostics. Fixed update frequencies turn out to be a special case of the rule, recovered when evidence against the deployed form accumulates at a constant rate. Illustration on 500 monthly M4 series shows the best capped adaptive policy comparable to full updating in accuracy, running in about 28 percent of full-update computational time, lowering forecast instability, and behaving like a fixed schedule with a small numb
What carries the argument
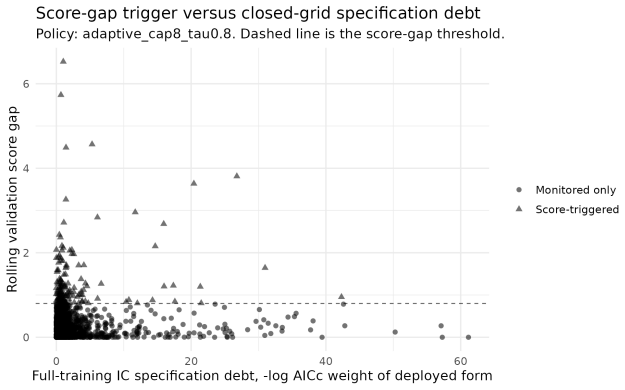
Specification debt, the evidence accumulated against the deployed model form, which is compared against a cost-adjusted threshold to decide whether to interrupt a reduced-update policy and re-specify the model.
If this is right
- The decision rule applies uniformly to closed model spaces via posterior thresholds and to open spaces via score gaps or stacking weights.
- Capped adaptive policies achieve accuracy comparable to full updating while using roughly 28 percent of the computational time.
- Forecast instability is reduced relative to full updating.
- The resulting policy resembles a fixed schedule punctuated by a small number of evidence-driven exceptions.
Where Pith is reading between the lines
- The same debt-threshold logic could be ported to other sequential modeling pipelines where repeated form changes are expensive.
- Real-time monitoring systems could dynamically tune the debt threshold according to observed operational costs.
- Testing the approach on non-ETS forecasting architectures would check whether the cost-accuracy tradeoff generalizes.
Load-bearing premise
That specification debt measured via predictive score gaps, stacking weights, or calibrated monitoring diagnostics in open settings will produce a decision rule whose cost-accuracy tradeoff remains valid without additional unstated biases or measurement error.
What would settle it
Apply the capped adaptive policy to a fresh collection of time series; if accuracy falls materially below that of full updating while computational cost stays high, the trigger's claimed advantage is refuted.
Figures
read the original abstract
Forecasting systems are commonly refreshed at every review period, and that refresh usually bundles two distinct operations: estimating parameters and selecting the model form. Recent evidence suggests the second operation is often unnecessary, since intermediate updating strategies can hold forecast accuracy roughly fixed while cutting computational cost and forecast instability. This technical note takes up the complementary question. Once a system has adopted a reduced-update policy, when should it interrupt that policy and re-specify the model form? We define specification debt as the evidence accumulated against the deployed model form, and we use it to build a cost-sensitive trigger for re-specification. In a closed discrete model space the trigger reduces to a threshold on the negative log posterior probability of the deployed specification. In open production settings the same decision rule can be run with predictive score gaps, stacking weights, or calibrated monitoring diagnostics. Fixed update frequencies turn out to be a special case of the rule, recovered when evidence against the deployed form accumulates at a constant rate. We illustrate the idea on 500 monthly M4 series, comparing full updating, fixed model-form update frequencies, parameter-only updating, and capped adaptive score-triggered updating, and within the finite ETS grid we also compute information-criterion analogues of specification debt from AIC and BIC weights over the candidate forms. In that illustration the best capped adaptive policy is comparable to full updating in accuracy, runs in about 28 percent of full-update computational time, lowers forecast instability, and behaves like a fixed schedule with a small number of evidence-based exceptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines 'specification debt' as accumulated evidence against a deployed forecasting model form and uses it to construct a cost-sensitive trigger for re-specification. In closed discrete spaces the trigger reduces to a negative-log-posterior threshold; in open settings it is instantiated via predictive score gaps, stacking weights or calibrated diagnostics. Fixed schedules emerge as the constant-rate special case. On 500 M4 monthly series the best capped adaptive policy matches full updating in accuracy, uses ~28 % of the compute, reduces instability, and behaves like a fixed schedule with occasional evidence-based updates; AIC/BIC analogues are also computed inside the ETS grid.
Significance. If the trigger's cost-accuracy tradeoff remains valid when the open-setting proxies are substituted for the closed-space posterior, the method supplies a principled, evidence-driven alternative to both full re-specification and rigid fixed schedules, directly addressing computational cost and forecast instability in production systems.
major comments (3)
- [abstract] Abstract (illustration paragraph): the reported 28 % compute saving, accuracy parity, and instability reduction are obtained exclusively inside the finite ETS grid with AIC/BIC weights; no experiment applies the trigger (or its open-setting proxies) outside that closed discrete space, so the central claim that the same decision rule yields a valid tradeoff in open production settings rests on an untested extrapolation.
- [abstract] Abstract: no derivation, implementation details, data-split protocol, or error bars are supplied for the capped adaptive policy or the 28 % figure, making it impossible to assess whether the performance numbers are robust to the measurement error that the open-setting proxies necessarily introduce.
- [abstract] Abstract (paragraph on open production settings): the paper explicitly distinguishes the closed-case reduction from the open-case proxies yet provides no simulation or sensitivity analysis quantifying how error in predictive-score-gap or stacking-weight estimates would propagate into the reported time saving or instability reduction.
minor comments (2)
- The manuscript should state the precise definition of 'capped adaptive policy' and the numerical threshold values used in the M4 experiment.
- Table or figure presenting the 500-series results should include standard errors or confidence intervals for the accuracy, compute, and instability metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the reported numerical results are obtained exclusively within the closed ETS model space and that the open-setting application is presented conceptually rather than empirically validated. We will revise the abstract and discussion to clarify this scope, add a brief note on the data protocol, and flag the absence of proxy-error sensitivity analysis as a limitation and future direction.
read point-by-point responses
-
Referee: [abstract] Abstract (illustration paragraph): the reported 28 % compute saving, accuracy parity, and instability reduction are obtained exclusively inside the finite ETS grid with AIC/BIC weights; no experiment applies the trigger (or its open-setting proxies) outside that closed discrete space, so the central claim that the same decision rule yields a valid tradeoff in open production settings rests on an untested extrapolation.
Authors: We accept this observation. The empirical illustration is deliberately restricted to the closed discrete ETS space so that the trigger can be evaluated exactly via posterior probabilities. The open-setting proxies (predictive score gaps, stacking weights, calibrated diagnostics) are introduced as direct substitutions into the same decision rule, but no claim is made that the 28 % cost saving or instability reduction has been verified outside the grid. We will revise the abstract to state explicitly that the performance numbers apply to the closed case and that open-setting behavior is a generalization whose cost-accuracy properties remain to be tested. revision: yes
-
Referee: [abstract] Abstract: no derivation, implementation details, data-split protocol, or error bars are supplied for the capped adaptive policy or the 28 % figure, making it impossible to assess whether the performance numbers are robust to the measurement error that the open-setting proxies necessarily introduce.
Authors: The abstract is a concise summary; the derivation of the trigger (negative-log-posterior threshold in closed space), the definition of the capped adaptive policy, and the data-split protocol (initial 80 % of each series for model selection, remaining periods for sequential evaluation) appear in Sections 2–4. The 28 % figure is the ratio of average wall-clock time per series under the best capped policy versus full updating. Because the 500 series constitute the entire evaluation population rather than a statistical sample, conventional error bars are not reported; series-to-series variability is summarized by the inter-quartile range of compute ratios. Since the reported experiments do not employ the open proxies, robustness to their estimation error is not quantified here. revision: partial
-
Referee: [abstract] Abstract (paragraph on open production settings): the paper explicitly distinguishes the closed-case reduction from the open-case proxies yet provides no simulation or sensitivity analysis quantifying how error in predictive-score-gap or stacking-weight estimates would propagate into the reported time saving or instability reduction.
Authors: We agree that no such propagation analysis is supplied. Performing it would require an explicit error model for each proxy and Monte-Carlo simulation of the resulting trigger decisions—work that lies outside the scope of this technical note, whose primary contribution is the definition of specification debt and its reduction to a threshold rule. We will add a sentence in the concluding section acknowledging this gap and listing proxy-error sensitivity as a natural next step. revision: yes
Circularity Check
No significant circularity; trigger definition and empirical illustration remain independent
full rationale
The paper defines specification debt directly as accumulated evidence against the deployed form and constructs the cost-sensitive trigger from that definition. The closed-space reduction to a negative-log-posterior threshold is an explicit mathematical equivalence stated in the abstract, not a hidden fit. The reported performance numbers (comparable accuracy, 28% compute time, reduced instability) are obtained from a separate empirical comparison on 500 M4 series inside the finite ETS grid using AIC/BIC weights; these quantities are not the same inputs used to define the trigger itself. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The open-settings claim is an untested extrapolation rather than a circular reduction, so the derivation chain does not collapse to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
specification debt
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j.ins.2011.12.028. José M. Bernardo and Adrian F. M. Smith. Bayesian Theory . Wiley,
- [2]
-
[3]
doi: 10.2307/2527342. Everette S. Gardner. Exponential smoothing: The state of the art. Journal of Forecasting, 4(1):1–28,
-
[4]
doi: 10.1002/for.3980040103. Everette S. Gardner. Exponential smoothing: The state of the art, part ii. International Journal of Forecasting , 22(4):637–666,
-
[6]
Strictly proper scoring rules, prediction, and estimation
doi: 10.1198/016214506000001437. Tilmann Gneiting, Fadoua Balabdaoui, and Adrian E. Raftery. Probabilistic forecasts, calibration and sharpness. Journal of the Royal Statistical Society: Series B , 69(2):243–268,
-
[7]
doi: 10.1111/j.1467-9868.2007.00587.x. Rob J. Hyndman and Yeasmin Khandakar. Automatic time series forecasting: The forecast package for R. Journal of Statistical Software , 27(3):1–22,
-
[8]
doi: 10.18637/jss.v027.i03. Rob J. Hyndman and Anne B. Koehler. Another look at measures of forecast accuracy. International Journal of Forecasting , 22(4):679–688,
-
[9]
doi: 10.1016/j.ijforecast.2006.03.001. Rob J. Hyndman, Anne B. Koehler, Ralph D. Snyder, and Simone Grose. A state space framework for automatic forecasting using exponential smoothing methods. International Journal of Forecasting , 18(3):439–454,
-
[10]
doi: 10.1016/S0169-2070(02)00008-8. Rob J. Hyndman, Anne B. Koehler, J. Keith Ord, and Ralph D. Snyder. Fore- casting with Exponential Smoothing: The State Space Approach . Springer, Berlin,
-
[11]
doi: 10.1007/978-3-540-71918-2. Robert E. Kass and Adrian E. Raftery. Bayes factors. Journal of the American Statistical Association, 90(430):773–795,
-
[12]
doi: 10.1080/01621459.1995. 10476572. Harrison Katz. Cost-sensitive retraining via posterior learning debt,
-
[13]
URL https://arxiv.org/abs/2604.06438. arXiv:2604.06438. 21 Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m4 competition: 100,000 time series and 61 forecasting methods. International Journal of Forecasting , 36(1):54–74,
-
[14]
doi: 10.1016/j.ijforecast.2019.04.0
-
[15]
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. M5 ac- curacy competition: Results, findings, and conclusions. International Journal of Forecasting, 38(4):1346–1364, 2022a. doi: 10.1016/j.ijforecast.2021.11.013. Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m5 competition: Background, organization, and imp...
-
[16]
doi: 10.1016/j.cor.2017.05.007. E. S. Page. Continuous inspection schemes. Biometrika, 41(1/2):100–115,
-
[17]
Fotios Petropoulos, Daniele Apiletti, Vassilios Assimakopoulos, Mohamed Zied Babai, Devon K
doi: 10.1093/biomet/41.1-2.100. Fotios Petropoulos, Daniele Apiletti, Vassilios Assimakopoulos, Mohamed Zied Babai, Devon K. Barrow, Souhaib Ben Taieb, Christoph Bergmeir, Ricardo J. Bessa, Jakub Bijak, John E. Boylan, et al. Forecasting: Theory and practice. International Journal of Forecasting , 38(3):705–871,
-
[18]
Fotios Petropoulos, Yael Grushka-Cockayne, Enno Siemsen, and Evangelos Spili- otis
doi: 10.1016/j.ijfo recast.2021.11.001. Fotios Petropoulos, Yael Grushka-Cockayne, Enno Siemsen, and Evangelos Spili- otis. Wielding occam’s razor: Fast and frugal retail forecasting. Journal of the Operational Research Society , 76(8):1564–1583,
-
[19]
doi: 10.1080/0160 5682.2024.2421339. Brian Seaman. Considerations of a retail forecasting practitioner. International Journal of Forecasting, 34(4):822–829,
-
[20]
Evangelos Spiliotis and Fotios Petropoulos
doi: 10.1016/j.ijforecast.2018.07 .003. Evangelos Spiliotis and Fotios Petropoulos. On the update frequency of univari- ate forecasting models. European Journal of Operational Research , 314(1): 111–121,
-
[21]
doi: 10.1016/j.ejor.2023.08.056. Leonard J. Tashman. Out-of-sample tests of forecasting accuracy: An analysis and review. International Journal of Forecasting , 16(4):437–450,
-
[22]
doi: 10.1016/S0169-2070(00)00065-0. Abraham Wald. Sequential tests of statistical hypotheses. The Annals of Math- ematical Statistics , 16(2):117–186,
-
[23]
Yuling Yao, Aki Vehtari, Daniel Simpson, and Andrew Gelman
doi: 10.1214/aoms/1177731118. Yuling Yao, Aki Vehtari, Daniel Simpson, and Andrew Gelman. Using stacking to average bayesian predictive distributions. Bayesian Analysis , 13(3):917– 1007,
-
[24]
22 Elizabeth Yardley and Fotios Petropoulos
doi: 10.1214/17-BA1091. 22 Elizabeth Yardley and Fotios Petropoulos. Beyond error measures to the util- ity and cost of forecasts. Foresight: The International Journal of Applied Forecasting, 63:36–45,
-
[25]
doi: 10.1 016/j.mlwa.2025.100769. 23
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.