INSPIRE: Intent-aware Neural Sponsored Product Retrieval for E-commerce
Pith reviewed 2026-06-26 06:11 UTC · model grok-4.3
The pith
INSPIRE embeds structured intent attributes into biencoder representations to improve matching of short grocery queries to sponsored products.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
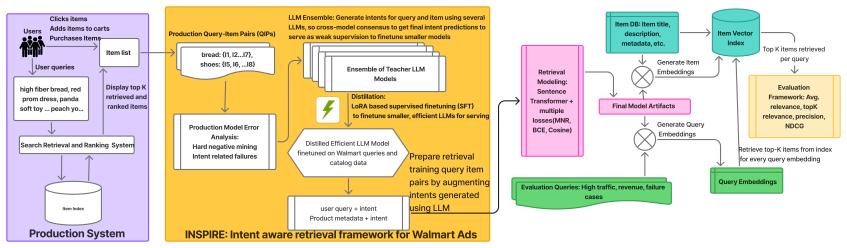
INSPIRE represents intent as a set of structured, multi-dimensional attributes derived from both user queries and product content and incorporates predicted intents into query and product representations within a biencoder, enabling more precise matching between queries and sponsored products.
What carries the argument
Intent-augmented biencoder that fuses predicted structured attributes (explicit like brand and implicit like dietary constraints) into dense representations of queries and products.
If this is right
- Queries underspecifying preferences such as cuisine type or size variant will retrieve products explicitly designed for those intents more often.
- Advertisers can rely on product metadata to target implicit preferences without requiring longer queries.
- The same retrieval stack handles both explicit signals like brand and implicit ones like dietary constraints in one representation.
- Distillation keeps inference cost low while still using LLM-quality intent signals at serving time.
Where Pith is reading between the lines
- The method could be applied to non-grocery categories where product metadata already encodes variant or preference information.
- If the intent attributes prove stable across query reformulations, they might reduce the need for separate query expansion modules.
- Advertiser bidding systems might eventually price impressions according to how well a product's intent profile matches the predicted query intent.
Load-bearing premise
The structured intent labels produced by the LLM from product titles and descriptions are accurate enough that distilling them into the retrieval model measurably beats a plain biencoder baseline.
What would settle it
An A/B test or offline evaluation on Walmart grocery search traffic showing no statistically significant lift in retrieval metrics such as NDCG@10 or sponsored click-through rate when intent attributes are added versus the non-intent biencoder.
Figures
read the original abstract
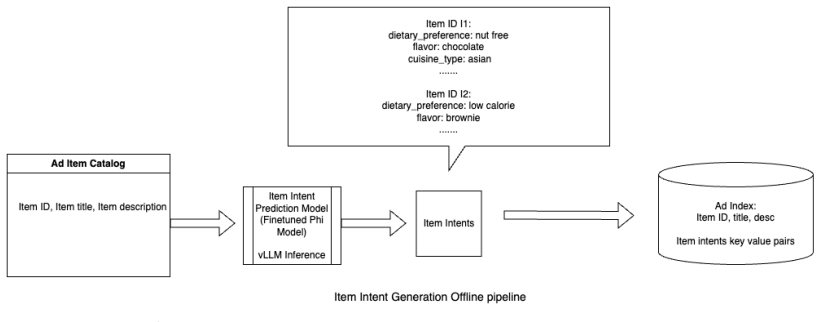
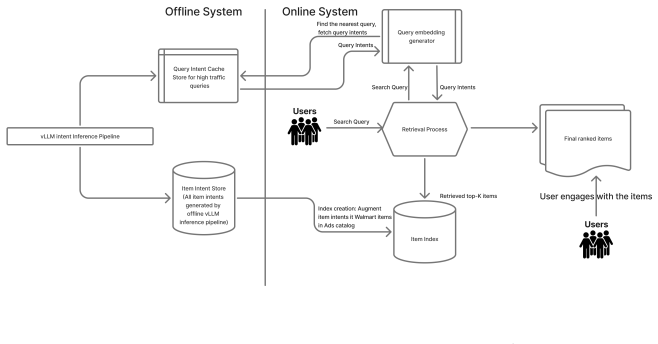
Walmart holds the largest share of the U.S. ecommerce grocery market, where food and beverage categories generate some of the highest search traffic and, consequently, drive a substantial portion of sponsored search revenue. At this scale, even small mismatches between user intent and retrieved products can lead to losses in both user engagement and monetization. Yet, understanding user intent in grocery search is inherently challenging. Queries are typically short, ambiguous, and highly diverse, often underspecifying critical preferences. From the advertisers perspective, many products are explicitly designed to target specific intents such as dietary preferences or size variants and must be surfaced at the right moment to be effective. Thus, we propose INSPIRE (Intent aware Neural Sponsored Product Retrieval for Ecommerce), an intent aware retrieval framework for sponsored search that leverages structured intent signals to better align user queries with relevant food and beverage products. INSPIRE represents intent as a set of structured, multi dimensional attributes derived from both user queries and product content, capturing explicit signals (e.g., brand, flavor) as well as implicit preferences (e.g., dietary constraints, cuisine types) that are often not directly expressed in queries. We develop a weakly supervised intent learning pipeline, where a large language model serves as a teacher to generate structured intent annotations from product titles and descriptions. We then distill these annotations by using them to finetune a lightweight student LLM model through LoRA based supervised finetuning that predicts intent attributes. We then introduce an intent augmented dense retrieval framework, where predicted intents are incorporated into query and product representations within a biencoder, enabling more precise matching between queries and sponsored products.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes INSPIRE, an intent-aware neural retrieval framework for sponsored product search in e-commerce grocery. It represents intent as structured multi-dimensional attributes (brand, flavor, dietary constraints, cuisine types) derived from queries and product content; uses an LLM teacher to generate weakly supervised annotations from titles/descriptions; distills them via LoRA fine-tuning into a student model; and augments a biencoder with the predicted intents for query and product embeddings to enable more precise matching.
Significance. If the empirical claims hold, the framework could meaningfully improve retrieval precision for short, ambiguous grocery queries by capturing both explicit and implicit preferences, with potential gains in user engagement and sponsored revenue at scale. The combination of LLM-based weak supervision, LoRA distillation, and intent-augmented dense retrieval is a plausible direction for handling underspecified intents in vertical search.
major comments (2)
- [Abstract] Abstract (and manuscript as a whole): the central claim that the intent-augmented biencoder enables more precise matching is unsupported because the text supplies no experimental results, ablation studies, metrics (e.g., NDCG, recall@K), baselines, or error analysis whatsoever.
- [Abstract] Abstract: the pipeline relies on the assumption that LLM-generated intent annotations are sufficiently accurate and additive, yet no human agreement metrics, quality validation, or controlled ablation isolating the intent component (while holding the biencoder fixed) is reported; this directly undermines the weakest assumption identified in the stress-test note.
Simulated Author's Rebuttal
We thank the referee for the review and for identifying the absence of empirical support in the current manuscript. We agree that the claims require experimental validation and will revise the paper to include the requested evaluations, metrics, and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract (and manuscript as a whole): the central claim that the intent-augmented biencoder enables more precise matching is unsupported because the text supplies no experimental results, ablation studies, metrics (e.g., NDCG, recall@K), baselines, or error analysis whatsoever.
Authors: We acknowledge that the manuscript as submitted contains no experimental results, ablations, quantitative metrics, baselines, or error analysis. The current version is limited to a framework description. In the revised manuscript we will add a full experimental section reporting NDCG, recall@K, and other standard retrieval metrics, multiple baselines, ablations that isolate the intent-augmentation component, and error analysis. revision: yes
-
Referee: [Abstract] Abstract: the pipeline relies on the assumption that LLM-generated intent annotations are sufficiently accurate and additive, yet no human agreement metrics, quality validation, or controlled ablation isolating the intent component (while holding the biencoder fixed) is reported; this directly undermines the weakest assumption identified in the stress-test note.
Authors: We agree that the quality and additive value of the LLM-generated annotations must be demonstrated rather than assumed. The submitted manuscript provides no human agreement figures, annotation quality checks, or controlled ablations that hold the biencoder fixed. The revision will include inter-annotator agreement statistics, manual quality validation of a sample of LLM annotations, and an ablation that isolates the intent signals while keeping the underlying biencoder unchanged. revision: yes
Circularity Check
No circularity: purely architectural description with no derivations or self-referential predictions
full rationale
The paper presents a system pipeline (LLM teacher annotation of product titles/descriptions → LoRA distillation to student model → intent-augmented biencoder) at the level of framework design and implementation choices. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the provided text. The central claims rest on empirical performance improvements rather than any mathematical reduction to inputs by construction. This is the expected non-finding for a retrieval-system paper without a derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Acharya, A
K. Acharya, A. Velasquez, H. H. Song, A survey on symbolic knowledge distillation of large language models, IEEE Transactions on Artificial Intelligence 5 (2024) 5928–5948
2024
-
[2]
G. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural network, arXiv preprint arXiv:1503.02531 (2015)
Pith/arXiv arXiv 2015
-
[3]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, et al., Lora: Low-rank adaptation of large language models., Iclr 1 (2022) 3
2022
-
[4]
Broder, A taxonomy of web search, in: ACM Sigir forum, volume 36, ACM New York, NY, USA, 2002, pp
A. Broder, A taxonomy of web search, in: ACM Sigir forum, volume 36, ACM New York, NY, USA, 2002, pp. 3–10
2002
-
[5]
H. Cao, D. Jiang, J. Pei, Q. He, Z. Liao, E. Chen, H. Li, Context-aware query suggestion by mining click-through and session data, in: Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, 2008, pp. 875–883
2008
-
[6]
Chuklin, I
A. Chuklin, I. Markov, M. De Rijke, Click models for web search, Springer Nature, 2022
2022
-
[7]
Joachims, A
T. Joachims, A. Swaminathan, T. Schnabel, Unbiased learning-to-rank with biased feedback, in: Proceedings of the tenth ACM international conference on web search and data mining, 2017, pp. 781–789
2017
-
[8]
S. Desai, M. O. F. Rokon, J. N. Acharya, I. Shah, H. Yao, U. Porwal, K.-c. Lee, Unified supervision for walmarts sponsored search retrieval via joint semantic relevance and behavioral engagement modeling, arXiv preprint arXiv:2604.07930 (2026)
Pith/arXiv arXiv 2026
-
[9]
J. Zhao, H. Chen, D. Yin, A dynamic product-aware learning model for e-commerce query intent understanding, in: Proceedings of the 28th ACM International Conference on Information and Knowledge Management, 2019, pp. 1843–1852
2019
-
[10]
Ahmadvand, S
A. Ahmadvand, S. Kallumadi, F. Javed, E. Agichtein, Jointmap: joint query intent understanding for modeling intent hierarchies in e-commerce search, in: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2020, pp. 1509–1512
2020
-
[11]
S. Manchanda, M. Sharma, G. Karypis, Intent term selection and refinement in e-commerce queries, arXiv preprint arXiv:1908.08564 (2019)
arXiv 1908
-
[12]
K. I. Diamantaras, M. Salampasis, A. Katsalis, K. Christantonis, Predicting shopping intent of e-commerce users using lstm recurrent neural networks., in: DATA, 2021, pp. 252–259
2021
-
[13]
Y. Qiu, C. Zhao, H. Zhang, J. Zhuo, T. Li, X. Zhang, S. Wang, S. Xu, B. Long, W.-Y. Yang, Pre-training tasks for user intent detection and embedding retrieval in e-commerce search, in: Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 4424–4428
2022
-
[14]
J. Guo, Y. Fan, Q. Ai, W. B. Croft, A deep relevance matching model for ad-hoc retrieval, in: Proceed- ings of the 25th ACM international on conference on information and knowledge management, 2016, pp. 55–64
2016
-
[15]
Xiong, Z
C. Xiong, Z. Dai, J. Callan, Z. Liu, R. Power, End-to-end neural ad-hoc ranking with kernel pooling, in: Proceedings of the 40th International ACM SIGIR conference on research and development in information retrieval, 2017, pp. 55–64
2017
-
[16]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, in: Advances in neural information processing systems, 2017, pp. 5998–6008
2017
-
[17]
Reimers, I
N. Reimers, I. Gurevych, Sentence-bert: Sentence embeddings using siamese bert-networks, in: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 3982–3992
2019
-
[18]
Xiong, et al., Approximate nearest neighbor negative contrastive learning for dense text retrieval, in: ICLR, 2021
L. Xiong, et al., Approximate nearest neighbor negative contrastive learning for dense text retrieval, in: ICLR, 2021
2021
-
[19]
Karpukhin, B
V. Karpukhin, B. Oguz, S. Min, et al., Dense passage retrieval for open-domain question answering, in: EMNLP, 2020
2020
-
[20]
Qu, et al., Rocketqa: An optimized training approach to dense passage retrieval, in: NAACL, 2021
Y. Qu, et al., Rocketqa: An optimized training approach to dense passage retrieval, in: NAACL, 2021
2021
-
[21]
Khattab, M
O. Khattab, M. Zaharia, Colbert: Efficient and effective passage search via contextualized late interaction, in: SIGIR, 2020
2020
-
[22]
X. Liu, W. Guo, H. Gao, B. Long, Deep search query intent understanding, arXiv preprint arXiv:2008.06759 (2020)
arXiv 2008
-
[23]
V. Sanh, L. Debut, J. Chaumond, T. Wolf, Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, arXiv preprint arXiv:1910.01108 (2019)
Pith/arXiv arXiv 1910
-
[24]
Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, H. Hajishirzi, Self-instruct: Aligning language models with self-generated instructions, in: Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), 2023, pp. 13484–13508
2023
-
[25]
DeepMind, Gemma: Open models based on gemini research, arXiv preprint arXiv:2403.08295 (2024)
G. DeepMind, Gemma: Open models based on gemini research, arXiv preprint arXiv:2403.08295 (2024)
Pith/arXiv arXiv 2024
-
[26]
H. Touvron, et al., Llama: Open and efficient foundation language models, arXiv preprint arXiv:2302.13971 (2023)
Pith/arXiv arXiv 2023
-
[27]
Bai, et al., Qwen technical report, arXiv preprint arXiv:2309.16609 (2023)
J. Bai, et al., Qwen technical report, arXiv preprint arXiv:2309.16609 (2023)
Pith/arXiv arXiv 2023
-
[28]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al., Gpt-4 technical report, arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[29]
A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V. Chaud- hary, C. Chen, et al., Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras, arXiv preprint arXiv:2503.01743 (2025)
Pith/arXiv arXiv 2025
-
[30]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., Training language models to follow instructions with human feedback, Advances in neural information processing systems 35 (2022) 27730–27744
2022
-
[31]
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, M. Zhou, Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers, Advances in neural information processing systems 33 (2020) 5776–5788
2020
-
[32]
T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Fun- towicz, et al., Huggingface’s transformers: State-of-the-art natural language processing, arXiv preprint arXiv:1910.03771 (2019)
Pith/arXiv arXiv 1910
-
[33]
Johnson, M
J. Johnson, M. Douze, H. Jégou, Billion-scale similarity search with gpus, IEEE transactions on big data 7 (2019) 535–547
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.