JOMP: Jointly-Optimized Mixed-Precision Quantization Across Neural Video Coding Frameworks and Buffering Strategies
Pith reviewed 2026-06-27 05:43 UTC · model grok-4.3
The pith
JOMP makes bit widths learnable variables so neural video codecs can train end-to-end in mixed-precision integer arithmetic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
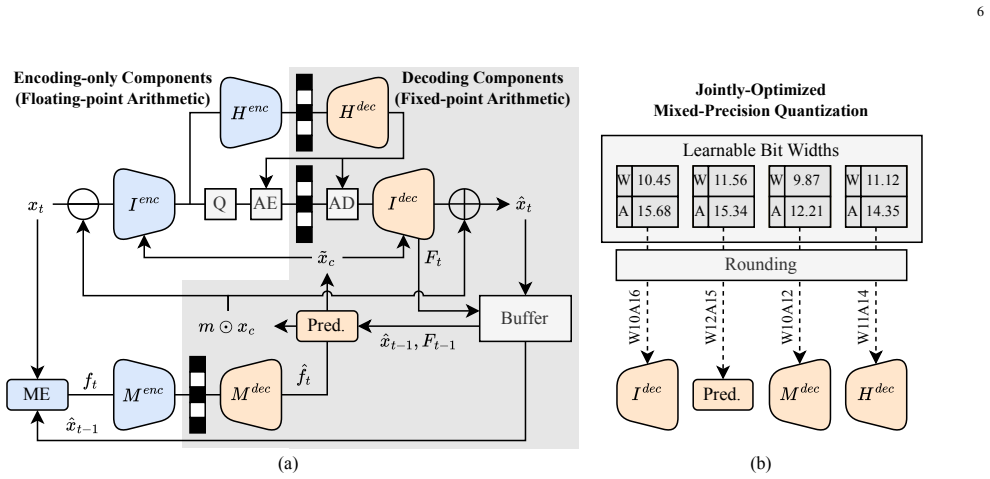
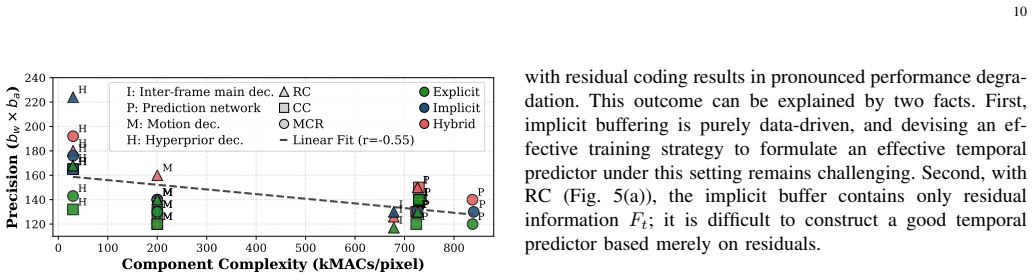
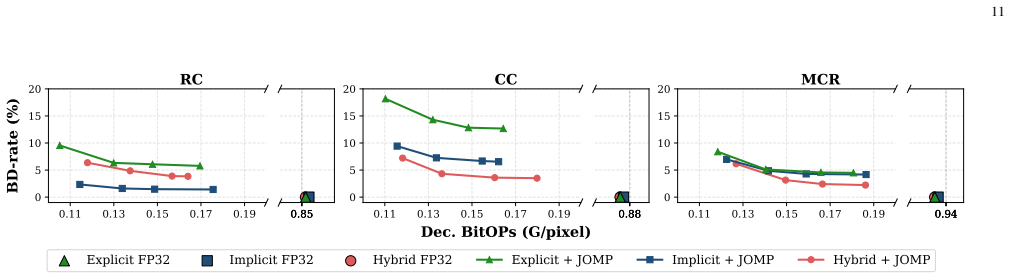
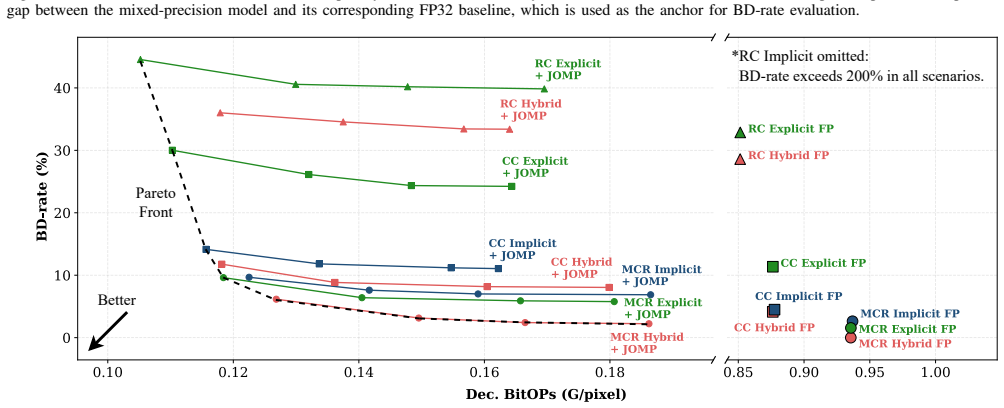
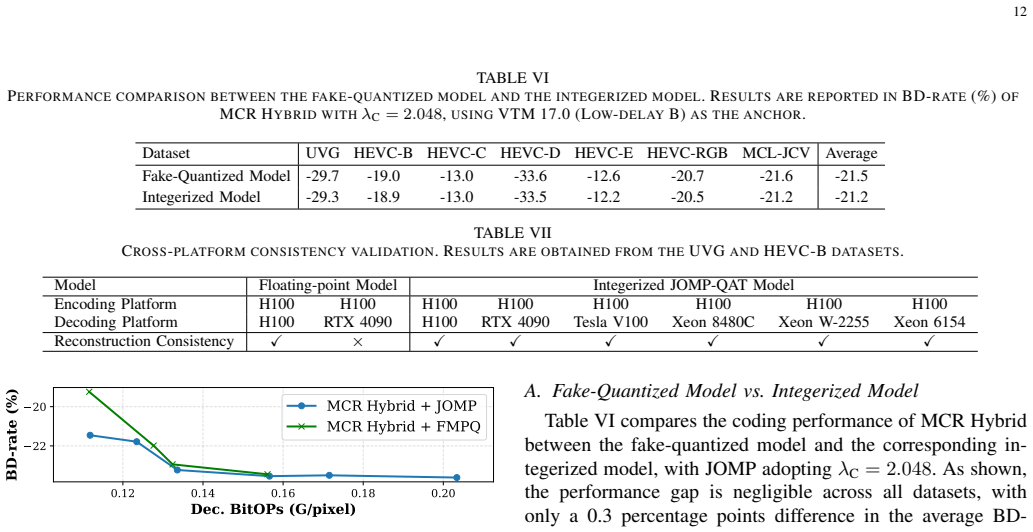
By treating both quantization parameters and bit widths as learnable variables, JOMP performs end-to-end mixed-precision optimization for neural video codecs. This produces integer implementations whose rate-distortion performance is comparable to DCVC-FM while reducing bit operations by 87.6 percent. The same framework also supplies a complete integerization pipeline that guarantees deterministic decoding.
What carries the argument
The JOMP framework, in which quantization parameters and bit widths are optimized jointly as learnable variables during training.
If this is right
- Different codec modules can run at different precision levels while the overall rate-distortion-complexity optimum is found automatically.
- A single training procedure works across multiple neural video coding frameworks and temporal buffering strategies.
- Integer neural video codecs become feasible with deterministic decoding and no floating-point arithmetic at inference time.
- Bit-operation count can be reduced by 87.6 percent while rate-distortion performance stays comparable to the strongest floating-point baseline.
Where Pith is reading between the lines
- The same joint-optimization idea could be tested on other neural compression domains such as image or point-cloud coding.
- Hardware designers could use the learned precision maps to allocate specialized low-precision arithmetic units inside video codecs.
- The method may reduce the need for separate quantization-aware training pipelines when new buffering strategies are introduced.
- If the learned bit widths prove stable across datasets, future codec standards could publish precision maps instead of full floating-point weights.
Load-bearing premise
Making bit widths learnable during training produces stable mixed-precision assignments that generalize across frameworks without post-training retuning.
What would settle it
A controlled test in which the learned bit-width assignments from JOMP require extensive per-framework retraining or post-processing to reach the reported rate-distortion performance.
Figures



read the original abstract
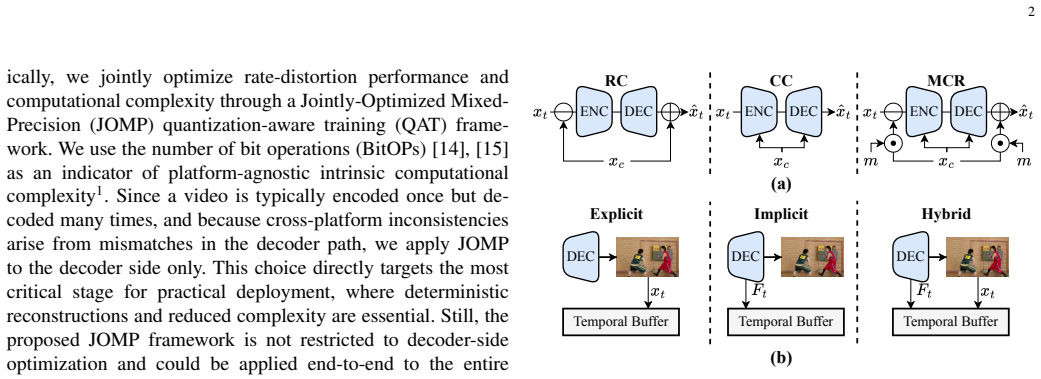
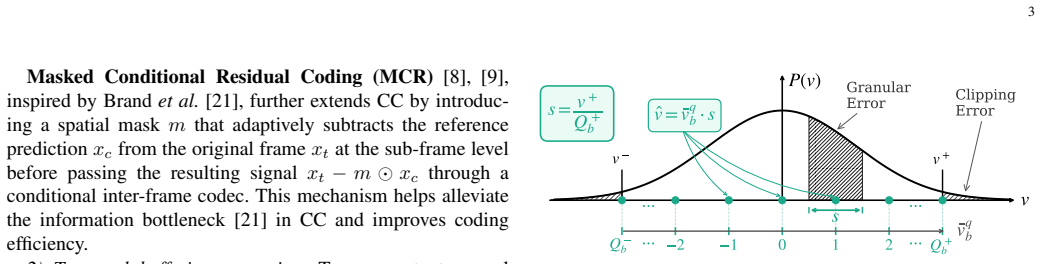
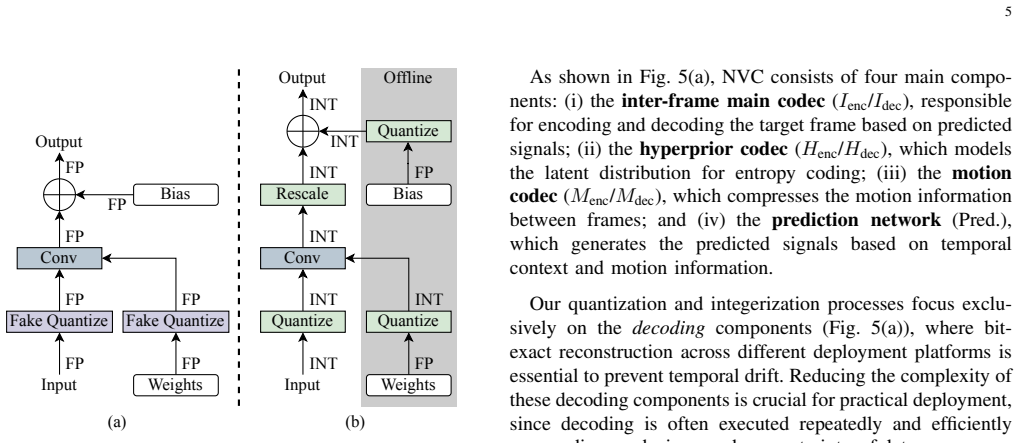
Variational autoencoder-based neural video coding has demonstrated impressive rate-distortion performance. However, its adoption in real-world applications remains hindered by challenges, such as prohibitively high computational complexity and limited cross-platform interoperability. These issues are often overlooked, as most neural video codecs rely on floating-point arithmetic to fully explore their rate-distortion potential. Practical deployment, however, requires integer-based implementations. Converting floating-point implementations into integer-based networks is non-trivial, since it involves quantizing inter-dependent coding components, whose sensitivity to precision may vary across codec designs. This paper introduces a Jointly-Optimized Mixed-Precision (JOMP) framework, in which both quantization parameters and bit widths are treated as learnable variables during training. This enables different codec modules to operate at varying precision levels, thereby jointly optimizing the rate-distortion-complexity trade-off. To the best of our knowledge, JOMP is the first mixed-precision quantization framework for neural video codecs. Its effectiveness is validated through a systematic investigation of quantization across different coding frameworks and temporal buffering strategies. Our study marks the first attempt to a unified understanding of the combined effects of modern coding frameworks and temporal buffering strategies, with the aim of informing future development of neural video codecs from a practicality perspective. In addition, we develop a complete integerization pipeline to achieve deterministic decoding. Overall, when applied to our best-performing model, JOMP enables end-to-end mixed-precision learning for integer neural video codecs, achieving rate-distortion performance comparable to that of the state-of-the-art DCVC-FM while reducing bit operations by 87.6%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce JOMP, the first mixed-precision quantization framework for neural video codecs, in which both quantization parameters and bit widths are treated as learnable variables during end-to-end training. It validates effectiveness via a systematic investigation across coding frameworks and temporal buffering strategies, develops a complete integerization pipeline for deterministic decoding, and reports that application to the best-performing model yields RD performance comparable to DCVC-FM while reducing bit operations by 87.6%.
Significance. If the central claims hold under rigorous validation, the work would meaningfully advance practical deployment of neural video codecs by addressing high computational complexity through mixed-precision integer arithmetic. The systematic cross-framework and cross-buffering study could provide a unified perspective on practicality considerations, and the integerization pipeline represents a concrete contribution toward reproducible integer implementations.
major comments (2)
- [Abstract] Abstract: the central claim of RD performance comparable to DCVC-FM with an 87.6% bit-operation reduction is presented without experimental details, baselines, variance across seeds, or ablation results on the joint optimization; this directly prevents assessment of whether the learnable bit-width procedure produces stable and generalizable assignments as required by the weakest assumption.
- [§3] Training procedure (assumed §3): no description is given of the relaxation technique for bit-width variables (e.g., straight-through estimator or Gumbel-softmax), auxiliary losses, or monitoring for collapse/variance, which is load-bearing for the assertion that end-to-end training directly yields usable mixed-precision integer codecs without post-training retuning.
minor comments (1)
- [Introduction] The novelty statement that JOMP is the first mixed-precision framework for neural video codecs would benefit from an explicit comparison table against prior mixed-precision methods applied to other neural codecs or vision models.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of RD performance comparable to DCVC-FM with an 87.6% bit-operation reduction is presented without experimental details, baselines, variance across seeds, or ablation results on the joint optimization; this directly prevents assessment of whether the learnable bit-width procedure produces stable and generalizable assignments as required by the weakest assumption.
Authors: We acknowledge that the abstract presents the central claim at a high level without sufficient supporting details. In the revised manuscript, we will expand the abstract to include brief references to the experimental setup (including the DCVC-FM baseline), the sections reporting variance across seeds, and the ablation studies on joint optimization. This will enable readers to more readily assess the stability and generalizability of the learnable bit-width assignments. revision: yes
-
Referee: [§3] Training procedure (assumed §3): no description is given of the relaxation technique for bit-width variables (e.g., straight-through estimator or Gumbel-softmax), auxiliary losses, or monitoring for collapse/variance, which is load-bearing for the assertion that end-to-end training directly yields usable mixed-precision integer codecs without post-training retuning.
Authors: We agree that the manuscript lacks an explicit description of the relaxation technique and related training details for the bit-width variables. In the revised version, we will expand the training procedure section to describe the specific relaxation method used, any auxiliary losses, and the monitoring procedures employed to detect collapse or excessive variance. This addition will strengthen the support for the end-to-end training claim. revision: yes
Circularity Check
No circularity: JOMP is an empirical training procedure with independent results
full rationale
The paper introduces JOMP as a method treating quantization parameters and bit widths as learnable variables in end-to-end training for integer neural video codecs. It reports empirical outcomes (RD parity to DCVC-FM, 87.6% bit-op reduction) from systematic experiments across frameworks and buffering strategies. No derivation, equation, or claim reduces by construction to fitted inputs or self-citations; the central results are outputs of the described optimization, not tautological renamings or forced predictions. Self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantization operations can be made differentiable so that bit widths become trainable parameters via backpropagation.
Reference graph
Works this paper leans on
-
[1]
Deep contextual video compression,
J. Li, B. Li, and Y . Lu, “Deep contextual video compression,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 18 114–18 125
2021
-
[2]
Canf- vc: Conditional augmented normalizing flows for video compression,
Y .-H. Ho, C.-P. Chang, P.-Y . Chen, A. Gnutti, and W.-H. Peng, “Canf- vc: Conditional augmented normalizing flows for video compression,” inEuropean Conference on Computer Vision, 2022, pp. 207–223
2022
-
[3]
Temporal context min- ing for learned video compression,
X. Sheng, J. Li, B. Li, L. Li, D. Liu, and Y . Lu, “Temporal context min- ing for learned video compression,”IEEE Transactions on Multimedia, vol. 25, pp. 7311–7322, 2023
2023
-
[4]
Hybrid spatial-temporal entropy modelling for neural video compression,
J. Li, B. Li, and Y . Lu, “Hybrid spatial-temporal entropy modelling for neural video compression,” inProceedings of the 30th ACM Interna- tional Conference on Multimedia (ACM MM), 2022, pp. 1503–1511
2022
-
[5]
Neural video compression with diverse contexts,
J. Li, B. Li, and Y . Lu, “Neural video compression with diverse contexts,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22 616–22 626
2023
-
[6]
Neural video compression with feature modulation,
J. Li, B. Li, and Y . Lu, “Neural video compression with feature modulation,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 26 099–26 108
2024
-
[7]
Towards practical real-time neural video compression,
Z. Jia, B. Li, J. Li, W. Xie, L. Qi, H. Li, and Y . Lu, “Towards practical real-time neural video compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 12 543–12 552
2025
-
[8]
Maskcrt: Masked conditional residual transformer for learned video compression,
Y .-H. Chen, H.-S. Xie, C.-W. Chen, Z.-L. Gao, M. Benjak, W.-H. Peng, and J. Ostermann, “Maskcrt: Masked conditional residual transformer for learned video compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 11 980–11 992, 2024
2024
-
[9]
Hytip: Hybrid temporal information propagation for masked conditional residual video coding,
Y .-H. Chen, Y .-C. Yao, K.-W. Ho, C.-H. Wu, H.-T. Phung, M. Benjak, J. Ostermann, and W.-H. Peng, “Hytip: Hybrid temporal information propagation for masked conditional residual video coding,” in2025 IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 17 889–17 898
2025
-
[10]
Fliqs: One- shot mixed-precision floating-point and integer quantization search,
J. Dotzel, G. Wu, A. Li, M. Umar, Y . Ni, M. S. Abdelfattah, Z. Zhang, L. Cheng, M. G. Dixon, N. P. Jouppi, Q. V . Le, and S. Li, “Fliqs: One- shot mixed-precision floating-point and integer quantization search,” inProceedings of the Third International Conference on Automated Machine Learning, ser. Proceedings of Machine Learning Research, vol
-
[11]
6/1–6/26
PMLR, 2024, pp. 6/1–6/26
2024
-
[12]
Ten lessons from three genera- tions shaped google’s tpuv4i : Industrial product,
N. P. Jouppi, D. Hyun Yoon, M. Ashcraft, M. Gottscho, T. B. Jablin, G. Kurian, J. Laudon, S. Li, P. Ma, X. Ma, T. Norrie, N. Patil, S. Prasad, C. Young, Z. Zhou, and D. Patterson, “Ten lessons from three genera- tions shaped google’s tpuv4i : Industrial product,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021, pp. 1–14
2021
-
[13]
1.1 computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” in2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2014, pp. 10–14
2014
-
[14]
Mobilenvc: Real-time 1080p neural video compression on a mobile device,
T. van Rozendaal, T. Singhal, H. Le, G. Sautiere, A. Said, K. Buska, A. Raha, D. Kalatzis, H. Mehta, F. Mayer, L. Zhang, M. Nagel, and A. Wiggers, “Mobilenvc: Real-time 1080p neural video compression on a mobile device,” in2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 4311–4321
2024
-
[15]
Mixed-precision post- training quantization for learned image compression,
J. Yu, S. Mai, P. Zhang, Y . Jiang, and J. Cheng, “Mixed-precision post- training quantization for learned image compression,”IEEE Internet of Things Journal, vol. 12, no. 16, pp. 34 392–34 405, 2025
2025
-
[16]
Fracbits: Mixed precision quantization via frac- tional bit-widths,
L. Yang and Q. Jin, “Fracbits: Mixed precision quantization via frac- tional bit-widths,” inAAAI Conference on Artificial Intelligence, 2020
2020
-
[17]
Dvc: An end-to-end deep video compression framework,
G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “Dvc: An end-to-end deep video compression framework,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10 998–11 007
2019
-
[18]
M-lvc: Multiple frames prediction for learned video compression,
J. Lin, D. Liu, H. Li, and F. Wu, “M-lvc: Multiple frames prediction for learned video compression,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3543– 3551
2020
-
[19]
Neural video coding using multiscale motion compensation and spatiotemporal context model,
H. Liu, M. Lu, Z. Ma, F. Wang, Z. Xie, X. Cao, and Y . Wang, “Neural video coding using multiscale motion compensation and spatiotemporal context model,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 8, pp. 3182–3196, 2021
2021
-
[20]
Scale-space flow for end-to-end optimized video compres- sion,
E. Agustsson, D. Minnen, N. Johnston, J. Ball ´e, S. J. Hwang, and G. Toderici, “Scale-space flow for end-to-end optimized video compres- sion,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8500–8509
2020
-
[21]
Fvc: A new framework towards deep video compression in feature space,
Z. Hu, G. Lu, and D. Xu, “Fvc: A new framework towards deep video compression in feature space,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 1502–1511
2021
-
[22]
Conditional residual coding: A remedy for bottleneck problems in conditional inter frame coding,
F. Brand, J. Seiler, and A. Kaup, “Conditional residual coding: A remedy for bottleneck problems in conditional inter frame coding,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 6445–6459, 2024
2024
-
[23]
A white paper on neural network quantization,
M. Nagel, M. Fournarakis, R. A. Amjad, Y . Bondarenko, M. van Baalen, and T. Blankevoort, “A white paper on neural network quantization,” arXiv preprint arXiv:2106.08295, 2021
Pith/arXiv arXiv 2021
-
[24]
An overview of the jpeg ai learning-based image coding standard,
S. Esenlik, Y . Wu, Z. Zhang, Y .-K. Wang, K. Zhang, L. Zhang, J. Ascenso, and S. Liu, “An overview of the jpeg ai learning-based image coding standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 2, pp. 2520–2537, 2026
2026
-
[25]
Fpx-nic: An fpga- accelerated 4k ultra-high-definition neural video coding system,
C. Jia, X. Hang, S. Wang, Y . Wu, S. Ma, and W. Gao, “Fpx-nic: An fpga- accelerated 4k ultra-high-definition neural video coding system,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 9, pp. 6385–6399, 2022
2022
-
[26]
Device interop- erability for learned image compression with weights and activations quantization,
E. Koyuncu, T. Solovyev, E. Alshina, and A. Kaup, “Device interop- erability for learned image compression with weights and activations quantization,” in2022 Picture Coding Symposium (PCS). IEEE, 2022, pp. 151–155
2022
-
[27]
Q-lic: Quantizing learned image compres- sion with channel splitting,
H. Sun, L. Yu, and J. Katto, “Q-lic: Quantizing learned image compres- sion with channel splitting,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 4, pp. 3798–3811, 2025
2025
-
[28]
Flexible mixed precision quantization for learned image compression,
M. A. Faisal Hossain, Z. Duan, and F. Zhu, “Flexible mixed precision quantization for learned image compression,” in2024 IEEE Interna- tional Conference on Multimedia and Expo (ICME), 2024, pp. 1–8
2024
-
[29]
Mobilecodec: neural inter-frame video compression on mobile devices,
H. Le, L. Zhang, A. Said, G. Sautiere, Y . Yang, P. Shrestha, F. Yin, R. Pourreza, and A. Wiggers, “Mobilecodec: neural inter-frame video compression on mobile devices,” inProceedings of the 13th ACM Multimedia Systems Conference, 2022, pp. 324–330
2022
-
[30]
Integer networks for data compression with latent-variable models,
J. Ball ´e, N. Johnston, and D. Minnen, “Integer networks for data compression with latent-variable models,” inInternational Conference on Learning Representations, 2019
2019
-
[31]
Quantized decoder in learned image compression for deterministic reconstruction,
E. Koyuncu, T. Solovyev, J. Sauer, E. Alshina, and A. Kaup, “Quantized decoder in learned image compression for deterministic reconstruction,” in2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 3985–3989
2024
-
[32]
Cross-platform neural video coding: A case study,
R. Conceic ¸˜ao, M. Porto, W.-H. Peng, and L. Agostini, “Cross-platform neural video coding: A case study,” in2025 IEEE International Sympo- sium on Circuits and Systems (ISCAS), 2025, pp. 1–5
2025
-
[33]
C3: High-performance and low-complexity neural compression from a single image or video,
H. Kim, M. Bauer, L. Theis, J. R. Schwarz, and E. Dupont, “C3: High-performance and low-complexity neural compression from a single image or video,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 9347–9358
2024
-
[34]
Hinerv: Video compression with hierarchical encoding-based neural representation,
H. M. Kwan, G. Gao, F. Zhang, A. Gower, and D. Bull, “Hinerv: Video compression with hierarchical encoding-based neural representation,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 72 692–72 704
2023
-
[35]
Mixed precision dnns: All you need is a good parametrization,
S. Uhlich, L. Mauch, F. Cardinaux, K. Yoshiyama, J. A. Garcia, S. Tiedemann, T. Kemp, and A. Nakamura, “Mixed precision dnns: All you need is a good parametrization,” inInternational Conference on Learning Representations, 2020
2020
-
[36]
Sdq: Stochastic differentiable quantization with mixed precision,
X. Huang, Z. Shen, S. Li, Z. Liu, X. Hu, J. Wicaksana, E. P. Xing, and K.-T. Cheng, “Sdq: Stochastic differentiable quantization with mixed precision,” inProceedings of the 39th International Conference on Machine Learning, vol. 162, 2022, pp. 9295–9309
2022
-
[37]
Differentiable dynamic quantization with mixed precision and adaptive resolution,
Z. Zhang, W. Shao, J. Gu, X. Wang, and P. Luo, “Differentiable dynamic quantization with mixed precision and adaptive resolution,” in 14 Proceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol. 139. PMLR, 18–24 Jul 2021, pp. 12 546–12 556
2021
-
[38]
Estimating or propagating gradients through stochastic neurons for conditional computation,
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,”arXiv preprint arXiv:1308.3432, 2013
Pith/arXiv arXiv 2013
-
[39]
Video enhance- ment with task-oriented flow,
T. Xue, B. Chen, J. Wu, D. Wei, and W. T. Freeman, “Video enhance- ment with task-oriented flow,”International Journal of Computer Vision, vol. 127, no. 8, pp. 1106–1125, 2019
2019
-
[40]
Bvi-dvc: A training database for deep video compression,
D. Ma, F. Zhang, and D. R. Bull, “Bvi-dvc: A training database for deep video compression,”IEEE Transactions on Multimedia, vol. 24, pp. 3847–3858, 2022
2022
-
[41]
Working practices using objective metrics for evaluation of video cod- ing efficiency experiments,
“Working practices using objective metrics for evaluation of video cod- ing efficiency experiments,” July 2020, iSO/IEC TR 23002-8, ISO/IEC JTC 1
2020
-
[42]
Uvg dataset: 50/120fps 4k sequences for video codec analysis and development,
A. Mercat, M. Viitanen, and J. Vanne, “Uvg dataset: 50/120fps 4k sequences for video codec analysis and development,” inProceedings of the 11th ACM Multimedia Systems Conference, 2020, p. 297–302
2020
-
[43]
MCL-JCV: a jnd-based h. 264/avc video quality assessment dataset,
H. Wang, W. Gan, S. Hu, J. Y . Lin, L. Jin, L. Song, P. Wang, I. Katsavounidis, A. Aaron, and C.-C. J. Kuo, “MCL-JCV: a jnd-based h. 264/avc video quality assessment dataset,” inIEEE International Conference on Image Processing (ICIP), 2016, pp. 1509–1513
2016
-
[44]
Common test conditions and software reference configurations,
F. Bossenet al., “Common test conditions and software reference configurations,” 2013, jCTVC-L1100
2013
-
[45]
Common test conditions and software reference configurations for hevc range extensions,
D. Flynnet al., “Common test conditions and software reference configurations for hevc range extensions,” 2013, jCTVC-N1006
2013
-
[46]
A configurable floating-point multiple-precision processing element for hpc and ai converged computing,
W. Mao, K. Li, Q. Cheng, L. Dai, B. Li, X. Xie, H. Li, L. Lin, and H. Yu, “A configurable floating-point multiple-precision processing element for hpc and ai converged computing,”IEEE Transactions on Very Large Scale Integration Systems, vol. 30, no. 2, pp. 213–226, 2022
2022
-
[47]
Less is more: Exploiting the standard compiler optimization levels for better performance and energy consumption,
K. Georgiou, C. Blackmore, S. Xavier-de Souza, and K. Eder, “Less is more: Exploiting the standard compiler optimization levels for better performance and energy consumption,” inProceedings of the 21st Inter- national Workshop on Software and Compilers for Embedded Systems, New York, NY , USA, 2018, p. 35–42. Yu-Hsiang Linreceived his B.S. degree in ap- p...
2018
-
[48]
Peng is a Fellow of the Higher Education Academy (FHEA), and a Fellow of the IEEE
Dr. Peng is a Fellow of the Higher Education Academy (FHEA), and a Fellow of the IEEE. 15 JOMP: Jointly-Optimized Mixed-Precision Quantization Across Neural Video Coding Frameworks and Buffering Strategies Supplementary Material X. DERIVATION OFGRADIENTS This section provides the detailed derivation of the gradients used in the optimization framework. Dur...
-
[49]
Case 1:Q − b < u < Q + b : ˆv=⌊u⌉ ·s ∂ˆv ∂v+ =⌊u⌉ · ∂s ∂v+ +s· ∂⌊u⌉ ∂v+ =⌊u⌉ · ∂ ∂v+ v+ Q+ b +s· ∂ ∂v+ v· Q+ b v+ =⌊u⌉ · 1 Q+ b −s· v·Q + b (v+)2 = ⌊u⌉ Q+ b − u Q+ b = ⌊u⌉ −u Q+ b
-
[50]
Case 2:u≤Q − b : ˆv=Q− b ·s=Q − b · v+ Q+ b ∂ˆv ∂v+ = Q− b Q+ b
-
[51]
Gradient w.r.t
Case 3:u≥Q + b : ˆv=Q+ b ·s=Q + b · v+ Q+ b =v + ∂ˆv ∂v+ = 1 B. Gradient w.r.t. Continuous Bit Width ˜b
-
[52]
Case 1:Q − b < u < Q + b : ˆv=⌊u⌉ ·s ∂ˆv ∂˜b =⌊u⌉ · ∂s ∂˜b +s· ∂⌊u⌉ ∂˜b = (v−ˆv)× 2˜b−1 ln 2 Q+ b where ⌊u⌉ · ∂s ∂˜b =⌊u⌉ · ∂ ∂˜b v+ Q+ b =⌊u⌉ ·v + ·(−1)(Q + b )−2 · ∂Q+ b ∂˜b =⌊u⌉ · v+ Q+ b · −1 Q+ b · ∂Q+ b ∂˜b = −ˆv Q+ b · ∂Q+ b ∂˜b , s· ∂⌊u⌉ ∂˜b = v+ Q+ b · ∂ ∂˜b v· Q+ b v+ = v Q+ b · ∂Q+ b ∂˜b , and ∂Q+ b ∂˜b = 2 ˜b−1 ln 2
-
[53]
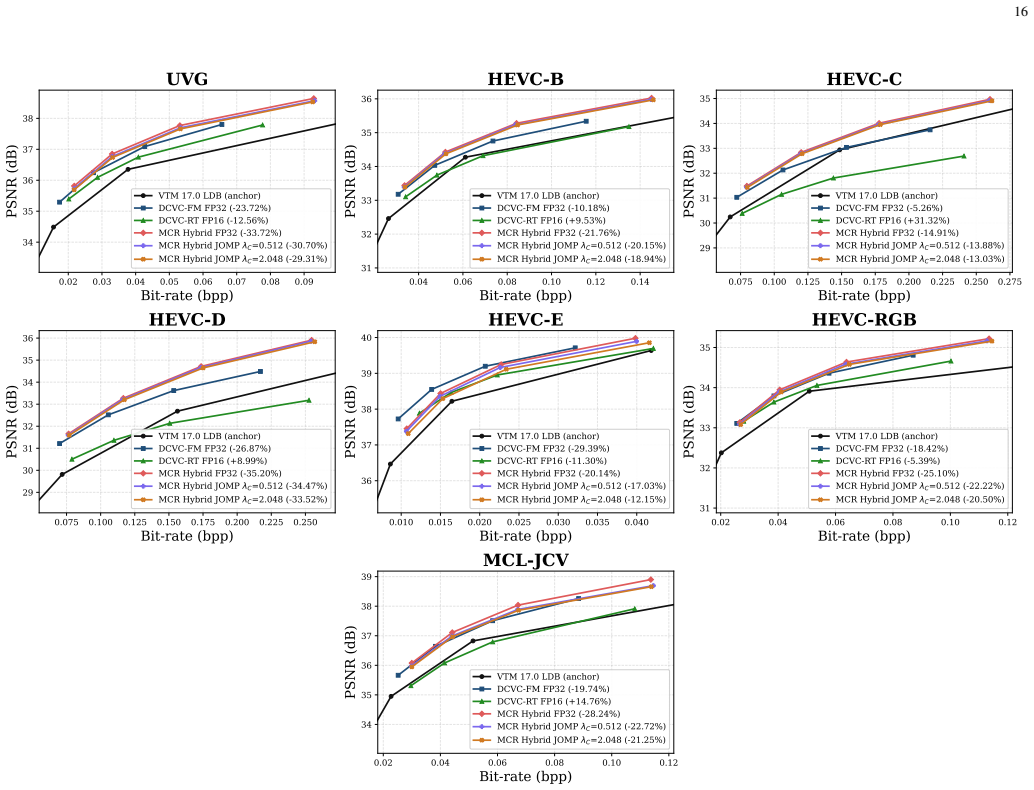
Case 2:u≤Q − b : ˆv=Q− b ·s=Q − b · v+ Q+ b ∂ˆv ∂˜b = ∂ ∂˜b v+ Q− b Q+ b =v + · Q+ b · ∂Q− b ∂˜b −Q − b · ∂Q+ b ∂˜b (Q+ b )2 =v + · Q+ b ·(−2 ˜b−1 ln 2)−Q − b ·(2 ˜b−1 ln 2) (Q+ b )2 =v + · (−Q+ b −Q − b )·2 ˜b−1 ln 2 (Q+ b )2 =v + · 2˜b−1 ln 2 (Q+ b )2 16 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 Bit-rate (bpp) 34 35 36 37 38PSNR (dB) UVG VTM 17.0 LDB (anc...
-
[54]
ADDITIONALRATE-DISTORTIONCURVES For completeness, Fig
Case 3:u≥Q + b : ˆv=Q+ b ·s=Q + b · v+ Q+ b =v + ∂ˆv ∂˜b = 0 XI. ADDITIONALRATE-DISTORTIONCURVES For completeness, Fig. 10 presents the full rate-distortion curves of the evaluated methods. XII. VISUALIZATION FORCROSS-PLATFORM CONSISTENCY Fig. 11 further provides a visual comparison using se- lected frames from theBasketballDrivesequence, showing the reco...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.