As We May Search
Pith reviewed 2026-06-30 07:23 UTC · model grok-4.3
The pith
Local-first information retrieval keeps sensitive personal documents on user devices while matching cloud search quality up to one million items.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
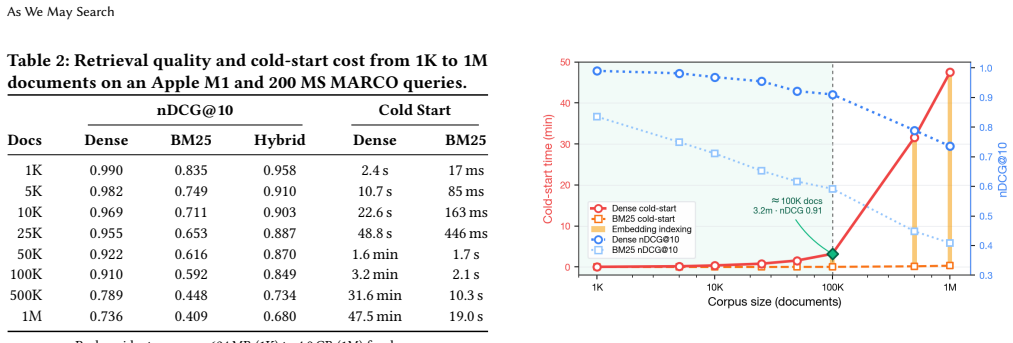
Local-first IR places indexes, models, and inference on the user's device with remote services treated as optional; across consumer hardware and five benchmarks, dense retrieval and hybrid methods preserve retrieval quality at scale while a local 7B model delivers answer quality close to cloud baselines, making the binding constraint the scope of documents that can be indexed locally rather than search performance.
What carries the argument
The local-first IR design philosophy that keeps indexes, models, and inference on user devices, organized by a framework of privacy/control, capability, and accessibility.
If this is right
- Dense retrieval on consumer hardware sustains more than 91 percent of nDCG@10 quality up to 100,000 documents.
- Approximate HNSW indexes extend usable collections to one million documents with roughly 2 percent quality loss.
- A 7 billion parameter local language model produces answer quality within 4 points of a cloud baseline.
- The decisive limit shifts from retrieval effectiveness to the breadth of documents that can be processed and stored locally.
- Architectures can be compared along the three axes of privacy and control, capability, and accessibility.
Where Pith is reading between the lines
- If local indexes prove reliable on real user collections, personal search tools could move away from cloud dependency without requiring new hardware.
- The scope-quality tradeoff suggests that hybrid local-cloud systems might be designed where only a small verified subset of documents ever leaves the device.
- Testing latency under typical mobile storage constraints would clarify whether the reported quality numbers translate to acceptable daily use.
Load-bearing premise
The five benchmarks and consumer-hardware test setups are representative of real personal document collections and that nDCG together with answer-quality scores adequately reflect practical usability including latency and resource limits.
What would settle it
Measure end-to-end answer quality and latency when the same dense retrieval plus 7B local model pipeline is run on an actual user's collection of 100,000 personal documents instead of the five public benchmarks.
Figures

read the original abstract
The sensitive information in personal documents, legal files, and medical records is among the most valuable things to search, yet current retrieval-augmented generation systems still require sending content to remote servers. We propose local-first IR, a design philosophy where indexes, models, and inference reside on user devices, treating remote services as optional. This paper makes four contributions: (1) a framework organizing retrieval architectures along three dimensions: privacy and control, capability, and accessibility, (2) experiments on consumer hardware across five benchmarks, scaling from 1K to 1M documents with dense retrieval, BM25, and hybrid fusion. Dense retrieval keeps over 91% nDCG@10 up to 100K documents, with approximate HNSW indexes extending this to 1M with only 2% quality loss; a 7B local language model reaches within 4 points of a cloud baseline on answer quality, (3) competing perspectives for and against local-first IR, informed by experimental evidence, and (4) a research agenda identifying open problems. The real tradeoff is scope rather than quality: what matters is what you can search, not how well you can search it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'local-first IR' as a design philosophy for retrieval-augmented generation systems that keep indexes, models, and inference on user devices to prioritize privacy and control, treating remote services as optional. It contributes (1) a three-dimensional framework for retrieval architectures (privacy/control, capability, accessibility), (2) scaling experiments on consumer hardware across five benchmarks from 1K to 1M documents comparing dense retrieval, BM25, and hybrid methods (reporting >91% nDCG@10 retention to 100K documents, 2% loss at 1M with HNSW, and a 7B local LM within 4 points of cloud baselines on answer quality), (3) balanced perspectives on local-first IR informed by the results, and (4) an open research agenda. The core argument is that the primary tradeoff is scope rather than retrieval quality.
Significance. If the empirical claims hold under broader conditions, the work supplies concrete evidence that high-quality dense retrieval and answer generation are feasible on consumer hardware at personal-collection scales, which could accelerate development of privacy-preserving IR tools. The organizing framework is a useful conceptual contribution, and the scaling results directly address a key practical question in local RAG systems.
minor comments (3)
- [Experiments] The experimental claims in the abstract (and presumably § on experiments) report specific numeric thresholds (91% nDCG@10, 2% loss, 4-point gap) without accompanying error bars, confidence intervals, or statistical tests; adding these would strengthen verifiability of the central feasibility result.
- [Experiments] Hardware specifications, exact benchmark identities, latency/resource measurements, and details on how the five benchmarks map to typical personal document collections are not provided in the abstract or claim summary; these omissions limit assessment of the weakest assumption identified in the review.
- [Framework] The framework in contribution (1) is described at a high level; a table or diagram explicitly mapping existing systems onto the three dimensions would improve clarity and allow readers to situate the local-first position.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, significance assessment, and recommendation of minor revision. The report does not enumerate any specific major comments under the MAJOR COMMENTS heading, so we have no individual points to rebut or revise at this stage. We are pleased that the empirical results on consumer hardware and the three-dimensional framework are viewed as potentially impactful.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a design philosophy for local-first IR supported by empirical scaling experiments on five benchmarks (nDCG@10 retention with dense retrieval, HNSW, BM25, hybrid fusion, and 7B local LLM answer quality). These are direct measurements on consumer hardware rather than algebraic derivations or predictions. The organizing framework along privacy/capability/accessibility dimensions and the research agenda are descriptive and organizational. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the claims. The central results stand as independent empirical observations without reduction to prior inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauff- mann, et al. 2024. Phi-4 technical report.arXiv preprint arXiv:2412.08905(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Parker Addison, Minh-Tuan H Nguyen, Tomislav Medan, Jinali Shah, Moham- mad T Manzari, Brendan McElrone, Laksh Lalwani, Aboli More, Smita Sharma, Holger R Roth, et al. 2024. C-fedrag: A confidential federated retrieval-augmented generation system.arXiv preprint arXiv:2412.13163(2024)
-
[3]
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guil- herme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíček, Agustín Pi- queres Lajarín, Vaibhav Srivastav, et al. 2025. SmolLM2: When Smol Goes Big– Data-Centric Training of a Small Language Model.arXiv preprint arXiv:2502.02737 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
David G Andersen, Jason Franklin, Michael Kaminsky, Amar Phanishayee, Lawrence Tan, and Vijay Vasudevan. 2009. FAWN: A fast array of wimpy nodes. InProceedings of the ACM SIGOPS 22nd symposium on Operating systems princi- ples. 1–14
2009
-
[5]
Apple Inc. 2024. Apple Intelligence Foundation Language Models. https://machinelearning.apple.com/research/apple-intelligence-foundation- language-models
2024
-
[6]
Apple Inc. 2024. Private Cloud Compute: A New Frontier for AI Privacy in the Cloud. https://security.apple.com/blog/private-cloud-compute/
2024
- [7]
-
[8]
Vannevar Bush et al. 1945. As we may think.The atlantic monthly176, 1 (1945), 101–108
1945
-
[9]
Charles LA Clarke, Gordon V Cormack, Jimmy Lin, and Adam Roegiest. 2017. Ten Blue Links on Mars. (2017), 273–281
2017
-
[10]
Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. 758–759
2009
-
[11]
Edward Cutrell, Daniel Robbins, Susan Dumais, and Raman Sarin. 2006. Fast, flexible filtering with phlat. InProceedings of the SIGCHI conference on Human Factors in computing systems. 261–270
2006
-
[12]
Jesse David Dinneen, Charles-Antoine Julien, and Ilja Frissen. 2019. The scale and structure of personal file collections. InProceedings of the 2019 CHI conference on human factors in computing systems. 1–12
2019
-
[13]
Susan Dumais, Edward Cutrell, Jonathan J Cadiz, Gavin Jancke, Raman Sarin, and Daniel C Robbins. 2003. Stuff I’ve seen: a system for personal information retrieval and re-use. InProceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval. 72–79
2003
-
[14]
David Elsweiler and Ian Ruthven. 2007. Towards task-based personal information management evaluations. InProceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. 23–30
2007
-
[15]
Val Andrei Fajardo, David B. Emerson, Amandeep Singh, Veronica Chatrath, Marcelo Lotif, Ravi Theja, Alex Cheung, and Izuki Matsuba. 2025. FedRAG: A Framework for Fine-Tuning Retrieval-Augmented Generation Systems. (2025). arXiv:2506.09200 [cs.LG] https://arxiv.org/abs/2506.09200
-
[16]
2009.A fully homomorphic encryption scheme
Craig Gentry. 2009.A fully homomorphic encryption scheme. Stanford university
2009
-
[17]
Google. 2025. Google NotebookLM: AI Research Tool & Thinking Partner. https: //notebooklm.google/
2025
-
[18]
Google Chrome. 2024. Built-in AI in Chrome. https://developer.chrome.com/ docs/ai/built-in
2024
-
[19]
Google DeepMind. 2025. Gemma 3n: Next-Generation Edge Models. https: //ai.google.dev/gemma
2025
-
[20]
Gijs Hendriksen, Djoerd Hiemstra, and Arjen P de Vries. 2026. Open Web Indexes for Remote Querying. InEuropean Conference on Information Retrieval. Springer, 386–402
2026
-
[21]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [22]
-
[23]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE transactions on big data7, 3 (2019), 535–547
2019
-
[24]
2007.Personal information management
William P Jones and Jaime Teevan. 2007.Personal information management. Vol. 14. University of Washington Press Seattle
2007
-
[25]
Martin Kleppmann, Adam Wiggins, Peter Van Hardenberg, and Mark Mc- Granaghan. 2019. Local-first software: you own your data, in spite of the cloud. (2019), 154–178
2019
-
[26]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics7 (2019), 453–466
2019
-
[27]
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini: A Python toolkit for reproducible infor- mation retrieval research with sparse and dense representations. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 2356–2362
2021
-
[28]
Sasha Luccioni, Yacine Jernite, and Emma Strubell. 2024. Power hungry process- ing: Watts driving the cost of AI deployment?. InProceedings of the 2024 ACM conference on fairness, accountability, and transparency. 85–99
2024
-
[29]
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. 2018. Www’18 open challenge: financial opinion mining and question answering. InCompanion proceedings of the the web conference 2018. 1941–1942
2018
-
[30]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence42, 4 (2018), 824–836
2018
-
[31]
Antonio Mallia, Michal Siedlaczek, Joel Mackenzie, and Torsten Suel. 2019. PISA: Performant indexes and search for academia.Proceedings of the Open-Source IR Replicability Challenge(2019)
2019
-
[32]
MDN Web Docs. 2024. Origin Private File System. https://developer.mozilla.org/ en-US/docs/Web/API/File_System_API/Origin_private_file_system
2024
-
[33]
Meta AI. 2024. Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models. https://ai.meta.com/blog/llama-3-2-connect-2024-vision- edge-mobile-devices/
2024
-
[34]
Microsoft. [n. d.]. MiniLM (UniLM) README. https://github.com/microsoft/ unilm/blob/master/minilm/README.md. Accessed 2026-02-12
2026
-
[35]
Junki Mori, Kazuya Kakizaki, Taiki Miyagawa, and Jun Sakuma. 2025. Differen- tially Private Synthetic Text Generation for Retrieval-Augmented Generation (RAG).arXiv preprint arXiv:2510.06719(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
John Morris, Volodymyr Kuleshov, Vitaly Shmatikov, and Alexander M Rush
-
[37]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Text embeddings reveal (almost) as much as text. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 12448–12460
2023
-
[38]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. Ms marco: A human-generated machine reading comprehension dataset
2016
-
[39]
Patricia A Norberg, Daniel R Horne, and David A Horne. 2007. The privacy paradox: Personal information disclosure intentions versus behaviors.Journal of consumer affairs41, 1 (2007), 100–126
2007
-
[40]
OpenAI. 2024. Introducing ChatGPT search. https://openai.com/index/ introducing-chatgpt-search/
2024
-
[41]
Kate Park. 2023. Samsung Bans Use of Generative AI Tools like ChatGPT after April Internal Data Leak.TechCrunch(2 May 2023). https://techcrunch.com/2023/05/02/samsung-bans-use-of-generative-ai- tools-like-chatgpt-after-april-internal-data-leak/
2023
-
[42]
Andrew Parry, Maik Fröbe, Harrisen Scells, Ferdinand Schlatt, Guglielmo Fag- gioli, Saber Zerhoudi, Sean MacAvaney, and Eugene Yang. 2025. Variations in relevance judgments and the shelf life of test collections. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3387–3397
2025
-
[43]
Priyanka Pathak, Matthew Thompson, and Saurabh Jha. 2025. Demystifying On-Device Intelligent Search Using RAG Architecture. Dell Technologies Info Hub (blog). https://infohub.delltechnologies.com/en-us/p/demystifying-on- device-intelligent-search-using-rag-architecture/
2025
- [44]
-
[45]
Ildikó Pilán, Pierre Lison, Lilja Øvrelid, Anthi Papadopoulou, David Sánchez, and Montserrat Batet. 2022. The text anonymization benchmark (tab): A dedi- cated corpus and evaluation framework for text anonymization.Computational Linguistics48, 4 (2022), 1053–1101
2022
- [46]
-
[47]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[48]
Kirk Roberts, Dina Demner-Fushman, Ellen M Voorhees, Steven Bedrick, and William R Hersh. 2022. Overview of the TREC 2022 Clinical Trials Track.. In TREC
2022
-
[49]
Stephen Edward Robertson, Steve Walker, Susan Jones, Micheline M Hancock- Beaulieu, Mike Gatford, et al. 1994. Okapi at TREC. (1994)
1994
-
[50]
Charlie F Ruan, Yucheng Qin, Xun Zhou, Ruihang Lai, Hongyi Jin, Yixin Dong, Bohan Hou, Meng-Shiun Yu, Yiyan Zhai, Sudeep Agarwal, et al . 2024. We- bLLM: A High-Performance In-Browser LLM Inference Engine.arXiv preprint arXiv:2412.15803(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Harrisen Scells, Shengyao Zhuang, and Guido Zuccon. 2022. Reduce, reuse, recy- cle: Green information retrieval research. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. As We May Search 2825–2837
2022
-
[52]
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. 2025. Zerosearch: Incentivize the search capability of llms without searching.arXiv preprint arXiv:2505.04588 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Jaime Teevan, Kevyn Collins-Thompson, Ryen W White, Susan T Dumais, and Yubin Kim. 2013. Slow search: Information retrieval without time constraints. In Proceedings of the symposium on human-computer interaction and information retrieval. 1–10
2013
-
[54]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[55]
Ellen Voorhees, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, William R Hersh, Kyle Lo, Kirk Roberts, Ian Soboroff, and Lucy Lu Wang. 2021. TREC-COVID: constructing a pandemic information retrieval test collection. 54, 1 (2021), 1–12
2021
-
[56]
W3C. 2023. WebGPU Specification. https://www.w3.org/TR/webgpu/
2023
- [57]
-
[58]
Qipeng Wang, Shiqi Jiang, Zhenpeng Chen, Xu Cao, Yuanchun Li, Aoyu Li, Yun Ma, Ting Cao, and Xuanzhe Liu. 2025. Anatomizing deep learning inference in web browsers.ACM Transactions on Software Engineering and Methodology34, 2, 1–43
2025
-
[59]
Zijie J Wang and Duen Horng Chau. 2024. MeMemo: on-device retrieval aug- mentation for private and personalized text generation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2765–2770
2024
-
[60]
Steve Whittaker. 2011. Personal information management: from information consumption to curation.Annual review of information science and technology 45, 1 (2011), 1
2011
- [61]
-
[62]
Shenglai Zeng, Jiankun Zhang, Pengfei He, Yiding Liu, Yue Xing, Han Xu, Jie Ren, Yi Chang, Shuaiqiang Wang, Dawei Yin, et al . 2024. The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag). (2024), 4505–4524
2024
-
[63]
Saber Zerhoudi and Michael Granitzer. 2024. Generative Agents Navigating Digital Libraries. InInternational Conference on Asian Digital Libraries. Springer, 171–188
2024
- [64]
-
[65]
Saber Zerhoudi, Michael Granitzer, Jörg Schlötterer, and Christin Seifert. 2021. Query change as a contextual Markov model for simulating user search behaviour. InProceedings of the 13th Annual Meeting of the Forum for Information Retrieval Evaluation. 43–51
2021
-
[66]
Justin Zobel. 1998. How reliable are the results of large-scale information retrieval experiments?. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval. 307–314
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.