Don't Listen to Me: A Lightweight, Low-Latency Model for Own-Voice Cancellation in Far-Field Speech Enhancement
Pith reviewed 2026-06-26 06:47 UTC · model grok-4.3
The pith
Own-voice cancellation removes an enrolled speaker from far-field mixtures at 2 ms latency while keeping other speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Own-voice cancellation removes a target enrolled speaker from a noisy multi-speaker mixture while preserving any remaining speech. Framed as the complement of target speaker extraction, the task is solved by conditioning a time-domain model on a short enrollment utterance. The model achieves only 2 ms algorithmic latency, and replacing the ConvTasNet-based auxiliary network with a linear RNN encoder improves both signal-to-distortion ratio and predicted MOS while reducing compute.
What carries the argument
Conditioning a time-domain masker on a short enrollment utterance to isolate and cancel only the enrolled speaker.
If this is right
- OVC functions as a practical low-latency enhancement objective for far-field denoising.
- The Mamba-MinGRU masker offers a lighter alternative that matches or exceeds TD-SpeakerBeam performance.
- Linear RNN encoder replacement improves both objective metrics and perceptual quality scores.
- The approach directly mitigates own-voice artifacts caused by device round-trip latency.
Where Pith is reading between the lines
- Devices could stream processed audio without the user's voice creating an unnatural echo.
- The same conditioning technique might extend to selective enhancement of only non-enrolled voices.
- Real-time implementation on embedded hardware would confirm whether the reported 2 ms latency holds under actual acoustic conditions.
Load-bearing premise
Conditioning on a short enrollment utterance suffices to isolate and remove only the target speaker without harming other speech.
What would settle it
A controlled test in which the model either removes non-enrolled speakers or leaves the enrolled speaker audible after processing.
Figures


read the original abstract
We introduce own-voice cancellation (OVC): removing a target (enrolled) speaker from a noisy multi-speaker mixture while preserving any remaining speech. Framed as the complement of target speaker extraction, OVC addresses latency-induced own-voice artifacts that arise when a far-field device streams enhanced audio back to the user, as the round-trip time easily exceeds the perceptual threshold for own-voice distortion. We condition a time-domain model with only 2 ms algorithmic latency on a short enrollment utterance and benchmark TD-SpeakerBeam alongside a lighter Mamba-MinGRU masker built from Mamba blocks with MinGRU temporal mixing. Replacing the ConvTasNet-based auxiliary network with a linear RNN encoder improves both signal-to-distortion ratio and predicted MOS while reducing compute. Results establish OVC as a practical, low-latency enhancement objective for far-field denoising.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces own-voice cancellation (OVC) as the complement of target-speaker extraction: conditioning a 2 ms latency time-domain masker on a short enrollment utterance to remove only the enrolled speaker from a noisy multi-speaker mixture while preserving all other speech. It benchmarks TD-SpeakerBeam against a lighter Mamba-MinGRU architecture, shows that swapping the auxiliary network for a linear RNN encoder improves SDR and predicted MOS while lowering compute, and concludes that OVC is a practical objective for far-field devices whose round-trip latency would otherwise distort the user's own voice.
Significance. If the selective-cancellation claim is substantiated, the work supplies a concrete, low-latency formulation that directly addresses a perceptual artifact in streaming far-field enhancement. The replacement of the ConvTasNet auxiliary network by a linear RNN and the introduction of the Mamba-MinGRU masker are concrete engineering contributions that could be adopted in resource-constrained devices.
major comments (2)
- [Abstract, §3] Abstract and §3 (model description): the central claim requires that the enrollment-conditioned masker nulls only the target speaker without attenuating non-target speech. No separate quantitative evidence (target-speaker energy reduction, non-target SI-SDR, or speaker-specific PESQ) is referenced; aggregate SDR/MOS gains alone do not confirm selectivity, especially given known variance of short-utterance embeddings in far-field overlap.
- [§4] §4 (experiments): the manuscript reports SDR and MOS improvements after replacing the auxiliary network, yet supplies neither dataset statistics (number of speakers, enrollment length distribution, SNR range) nor ablation isolating the contribution of the linear RNN versus the Mamba blocks. Without these, the performance delta cannot be attributed to the claimed architectural change.
minor comments (2)
- [§3] Notation for the enrollment embedding and its concatenation or similarity mechanism with the masker input should be defined explicitly (e.g., an equation in §3) rather than left to the TD-SpeakerBeam reference.
- [Figures] Figure captions and axis labels should state the exact enrollment duration used at test time and whether enrollment is clean or noisy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (model description): the central claim requires that the enrollment-conditioned masker nulls only the target speaker without attenuating non-target speech. No separate quantitative evidence (target-speaker energy reduction, non-target SI-SDR, or speaker-specific PESQ) is referenced; aggregate SDR/MOS gains alone do not confirm selectivity, especially given known variance of short-utterance embeddings in far-field overlap.
Authors: We agree that demonstrating selectivity is essential to substantiate the OVC claim. While the aggregate SDR and MOS results are consistent with selective cancellation of the enrolled speaker, they do not directly isolate target-speaker attenuation from non-target preservation. In the revised manuscript we will add target-speaker energy reduction and non-target SI-SDR metrics to provide explicit quantitative support for the selectivity of the enrollment-conditioned masker. revision: yes
-
Referee: [§4] §4 (experiments): the manuscript reports SDR and MOS improvements after replacing the auxiliary network, yet supplies neither dataset statistics (number of speakers, enrollment length distribution, SNR range) nor ablation isolating the contribution of the linear RNN versus the Mamba blocks. Without these, the performance delta cannot be attributed to the claimed architectural change.
Authors: We accept that the experimental reporting is incomplete. The revised version will include full dataset statistics (speaker count, enrollment length distribution, SNR ranges) and a dedicated ablation that isolates the linear RNN encoder from the original ConvTasNet auxiliary network as well as the contribution of the Mamba blocks. revision: yes
Circularity Check
No significant circularity; empirical model evaluation without load-bearing derivations
full rationale
The paper introduces own-voice cancellation as a new task and reports empirical results from training and benchmarking time-domain models (TD-SpeakerBeam and Mamba-MinGRU) conditioned on enrollment utterances. No equations, first-principles derivations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described content. Claims rest on experimental metrics (SDR, MOS) against external benchmarks rather than any reduction to inputs by construction. This is the common case of a self-contained applied ML paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A particularly challenging scenario arises when a far-field device, such as a table-top microphone, captures, enhances, and streams audio back to the user
Introduction The problem of enhancing speech degraded by environmen- tal noise, interfering speakers, or reverberant effects has been widely studied and remains a common obstacle in many real- world applications such as telecommunications, smart speakers, and conferencing devices. A particularly challenging scenario arises when a far-field device, such as...
-
[2]
Related work A substantial body of work has focused on developing neu- ral network architectures for speech enhancement and separa- tion [8, 9, 10, 4, 11]. Notable contributions include TasNet [8] and ConvTasNet [9], with ConvTasNet frequently serving as a baseline for evaluating new methods [4]. arXiv:2606.23332v1 [eess.AS] 22 Jun 2026 The perceptual imp...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
base" and
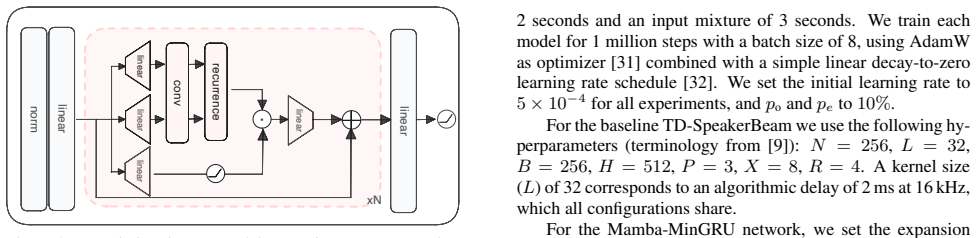
Methods Given an input mixturey=x s +P i̸=s xi +ncontaining a target speakers(the own-voice), other speaker(s)i, and a noise signaln, the goal is to recover ¯y= P i̸=s xi. Following [14], we train the network using at most one other speaker. 3.1. Dataset We train on a dynamically mixed dataset using LibriSpeech [21] in WHAM! noise [22], as in [16] (althou...
-
[4]
When comparing task objectives, OVC and TSE appear comparably difficult (cf
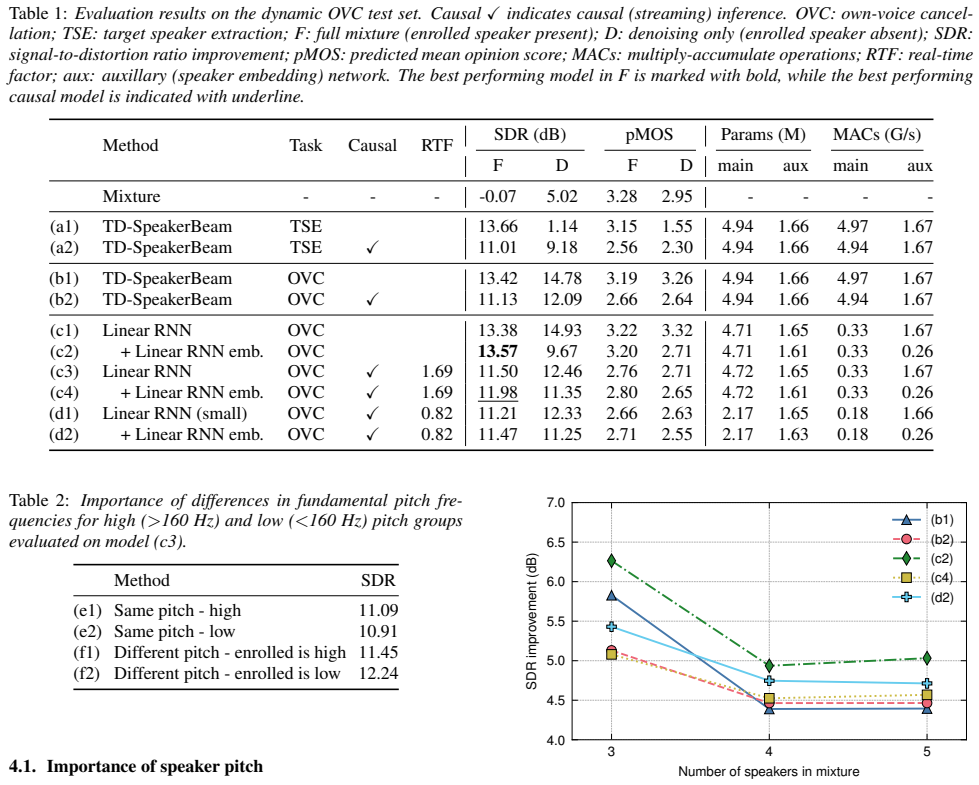
Results and discussion Our main results are shown in Table 1. When comparing task objectives, OVC and TSE appear comparably difficult (cf. (a1) vs. (b1)), with both achieving∼13 dB SDR in the full mixture condition (F). Moving to a causal setting incurs a moderate drop in SDR for both tasks (cf. (a1) vs. (a2) and (b1) vs. (b2)). Replacing the TD-SpeakerBe...
-
[5]
Conclusion We have introduced own-voice cancellation as a practical ob- jective for far-field streamed denoising, showing that methods from target speaker extraction can effectively remove an en- rolled speaker from a noisy mixture. The proposed Mamba- MinGRU architecture matches the performance of ConvTasNet- based baselines at a fraction of the compute,...
-
[6]
AI tools were used solely for grammar correction
Generative AI Use Disclosure In accordance with ISCA policy, generative AI tools were not used as co-authors, nor to develop the source code. AI tools were used solely for grammar correction
-
[7]
Tolerable hearing aid delays. I. Estimation of limits imposed by the auditory path alone using simulated hearing losses,
M. A. Stone and B. C. Moore, “Tolerable hearing aid delays. I. Estimation of limits imposed by the auditory path alone using simulated hearing losses,”Ear and Hearing, vol. 20, no. 3, pp. 182–192, 1999
1999
-
[8]
Disturbance caused by varying prop- agation delay in non-occluding hearing aid fittings,
J. Groth and M. Birkmose, “Disturbance caused by varying prop- agation delay in non-occluding hearing aid fittings,”International Journal of Audiology, vol. 43, no. 10, pp. 594–599, 2004
2004
-
[9]
Tolerable hearing-aid delays: IV. Effects on subjective disturbance during speech production by hearing-impaired subjects,
M. A. Stone and B. C. J. Moore, “Tolerable hearing-aid delays: IV. Effects on subjective disturbance during speech production by hearing-impaired subjects,”Ear and Hearing, vol. 26, no. 2, pp. 225–235, 2005
2005
-
[10]
Separate and Re- construct: Asymmetric Encoder-Decoder for Speech Separation,
U.-H. Shin, S. Lee, T. Kim, and H.-M. Park, “Separate and Re- construct: Asymmetric Encoder-Decoder for Speech Separation,” 2024, arXiv:2406.05983 [eess.AS]
-
[11]
SepMamba: State-space models for speaker separation using Mamba,
T. H. Avenstrup, B. Elek, I. L. Mádi, A. B. Schin, M. Mørup, B. S. Jensen, and K. F. Olsen, “SepMamba: State-space models for speaker separation using Mamba,” 2024, arXiv:2410.20997 [cs.SD]
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-Time Sequence Modeling with Selective State Spaces,” 2024, arXiv:2312.00752 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
L. Feng, F. Tung, M. O. Ahmed, Y . Bengio, and H. Hajimir- sadeghi, “Were RNNs All We Needed?” 2024, arXiv:2410.01201 [cs]
-
[14]
TaSNet: Time-Domain Audio Separa- tion Network for Real-Time, Single-Channel Speech Separation,
Y . Luo and N. Mesgarani, “TaSNet: Time-Domain Audio Separa- tion Network for Real-Time, Single-Channel Speech Separation,” in2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 2018, pp. 696–700
2018
-
[15]
Conv-TasNet: Surpassing Ideal Time-Frequency Magni- tude Masking for Speech Separation,
——, “Conv-TasNet: Surpassing Ideal Time-Frequency Magni- tude Masking for Speech Separation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019
2019
-
[16]
Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech sepa- ration,
Y . Luo, Z. Chen, and T. Yoshioka, “Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech sepa- ration,” 2020, arXiv:1910.06379 [eess.AS]
-
[17]
TF-Locoformer: Transformer with Local Modeling by Convolution for Speech Separation and Enhancement,
K. Saijo, G. Wichern, F. G. Germain, Z. Pan, and J. L. Roux, “TF-Locoformer: Transformer with Local Modeling by Convolution for Speech Separation and Enhancement,” 2024, arXiv:2408.03440 [eess.AS]
-
[18]
Tolerable hearing aid delays. II. Estimation of limits imposed during speech production,
M. A. Stone and B. C. J. Moore, “Tolerable hearing aid delays. II. Estimation of limits imposed during speech production,”Ear and Hearing, vol. 23, no. 4, pp. 325–338, 2002
2002
-
[19]
Improving Speaker Discrimination of Target Speech Extraction With Time-Domain Speakerbeam,
M. Delcroix, T. Ochiai, K. Zmolikova, K. Kinoshita, N. Tawara, T. Nakatani, and S. Araki, “Improving Speaker Discrimination of Target Speech Extraction With Time-Domain Speakerbeam,” in 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020, pp. 691– 695
2020
-
[20]
Listen only to me! How well can target speech ex- traction handle false alarms?
M. Delcroix, K. Kinoshita, T. Ochiai, K. Zmolikova, H. Sato, and T. Nakatani, “Listen only to me! How well can target speech ex- traction handle false alarms?” 2022, arXiv:2204.04811 [eess.AS]
-
[21]
TEA-PSE: Tencent-Ethereal-Audio-Lab Personal- ized Speech Enhancement System for ICASSP 2022 DNS Chal- lenge,
Y . Ju, W. Rao, X. Yan, Y . Fu, S. Lv, L. Cheng, Y . Wang, L. Xie, and S. Shang, “TEA-PSE: Tencent-Ethereal-Audio-Lab Personal- ized Speech Enhancement System for ICASSP 2022 DNS Chal- lenge,” in2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, Singapore, 2022, pp. 9291–9295
2022
-
[22]
H. Sato, T. Moriya, M. Mimura, S. Horiguchi, T. Ochiai, T. Ashihara, A. Ando, K. Shinayama, and M. Delcroix, “SpeakerBeam-SS: Real-time Target Speaker Extraction with Lightweight Conv-TasNet and State Space Modeling,” 2024, arXiv:2407.01857 [eess.AS]
-
[23]
Target Speech Extraction with Pre-trained Self- supervised Learning Models,
J. Peng, M. Delcroix, T. Ochiai, O. Plchot, S. Araki, and J. Cernocky, “Target Speech Extraction with Pre-trained Self- supervised Learning Models,” 2024, arXiv:2402.13199
-
[24]
Diagonal State Spaces are as Effective as Structured State Spaces,
A. Gupta, A. Gu, and J. Berant, “Diagonal State Spaces are as Effective as Structured State Spaces,” 2022, arXiv:2203.14343 [cs.LG]
-
[25]
ICASSP 2023 Acoustic Echo Cancellation Challenge,
R. Cutler, A. Saabas, T. Pärnamaa, M. Purin, E. Indenbom, N.-C. Ristea, J. Gužvin, H. Gamper, S. Braun, and R. Aichner, “ICASSP 2023 Acoustic Echo Cancellation Challenge,”IEEE Open Journal of Signal Processing, vol. 5, pp. 675–685, 2024
2023
-
[26]
A Progressive Neural Network for Acoustic Echo Can- cellation,
Z. Chen, X. Xia, S. Sun, Z. Wang, C. Chen, G. Xie, P. Zhang, and Y . Xiao, “A Progressive Neural Network for Acoustic Echo Can- cellation,” in2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023, pp. 1–2
2023
-
[27]
Lib- rispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Queensland, Aus- tralia, 2015, pp. 5206–5210
2015
-
[28]
WHAM!: Extending Speech Separation to Noisy Environments
G. Wichern, J. Antognini, M. Flynn, L. R. Zhu, E. Mc- Quinn, D. Crow, E. Manilow, and J. L. Roux, “WHAM!: Extending Speech Separation to Noisy Environments,” 2019, arXiv:1907.01160 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
arXiv preprint arXiv:2005.11262 , year=
J. Cosentino, M. Pariente, S. Cornell, A. Deleforge, and E. Vin- cent, “LibriMix: An Open-Source Dataset for Generalizable Speech Separation,” 2020, arXiv:2005.11262 [eess]
-
[30]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer Normalization,” 2016, arXiv:1607.06450 [stat]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning
S. Elfwing, E. Uchibe, and K. Doya, “Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforce- ment Learning,” 2017, arXiv:1702.03118 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Resurrecting recurrent neural networks for long sequences, 2023
A. Orvieto, S. L. Smith, A. Gu, A. Fernando, C. Gulcehre, R. Pas- canu, and S. De, “Resurrecting Recurrent Neural Networks for Long Sequences,” 2023, arXiv:2303.06349 [cs]
-
[33]
Hydra: Bidirectional State Space Models Through Generalized Matrix Mixers,
S. Hwang, A. Lahoti, T. Dao, and A. Gu, “Hydra: Bidirectional State Space Models Through Generalized Matrix Mixers,” 2024, arXiv:2407.09941 [cs]
-
[34]
Unsupervised Sound Separation Using Mixture Invariant Training,
S. Wisdom, E. Tzinis, H. Erdogan, R. J. Weiss, K. Wilson, and J. R. Hershey, “Unsupervised Sound Separation Using Mixture Invariant Training,” inAdvances in Neural Information Process- ing Systems, vol. 33. Vancouver, BC, Canada: Curran Associates, Inc., 2020, pp. 3846–3857
2020
-
[35]
SDR - half-baked or well done?
J. L. Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR - half-baked or well done?” 2018, arXiv:1811.02508 [cs.SD]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
B. Stahl and H. Gamper, “Distillation and Pruning for Scal- able Self-Supervised Representation-Based Speech Quality As- sessment,” 2025, arXiv:2502.05356 [eess.AS]
-
[37]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regular- ization,” 2019, arXiv:1711.05101 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[38]
Straight to Zero: Why Linearly Decaying the Learning Rate to Zero Works Best for LLMs,
S. Bergsma, N. Dey, G. Gosal, G. Gray, D. Soboleva, and J. Hes- tness, “Straight to Zero: Why Linearly Decaying the Learning Rate to Zero Works Best for LLMs,” 2025, arXiv:2502.15938 [cs.LG]
-
[39]
PYIN: A fundamental frequency esti- mator using probabilistic threshold distributions,
M. Mauch and S. Dixon, “PYIN: A fundamental frequency esti- mator using probabilistic threshold distributions,” in2014 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), Florence, Italy, 2014, pp. 659–663
2014
-
[40]
YIN, a fundamental fre- quency estimator for speech and music,
A. De Cheveigné and H. Kawahara, “YIN, a fundamental fre- quency estimator for speech and music,”The Journal of the Acoustical Society of America, vol. 111, no. 4, pp. 1917–1930, 2002
1917
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.