The Modified Egger Intercept Tests for Detecting Horizontal Pleiotropy in Two-Sample Summary-Data Mendelian Randomization
Pith reviewed 2026-06-29 10:36 UTC · model grok-4.3
The pith
A bias-corrected Egger intercept test, combined across allele codings, controls type I error and gains power for detecting horizontal pleiotropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
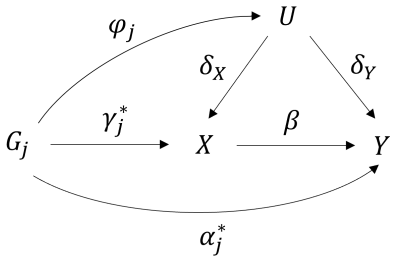
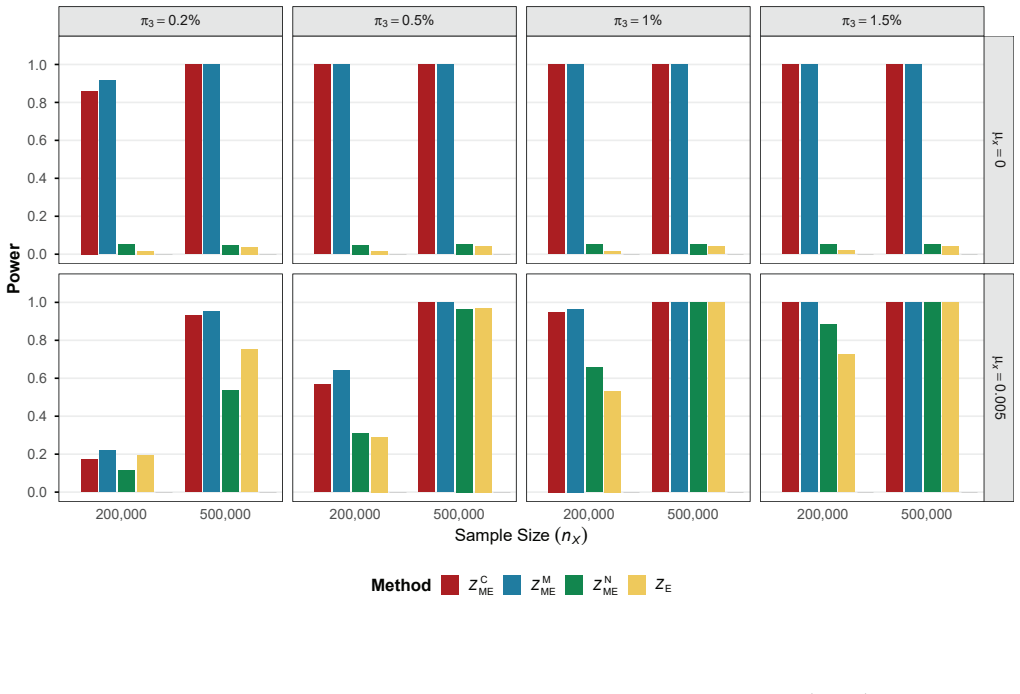
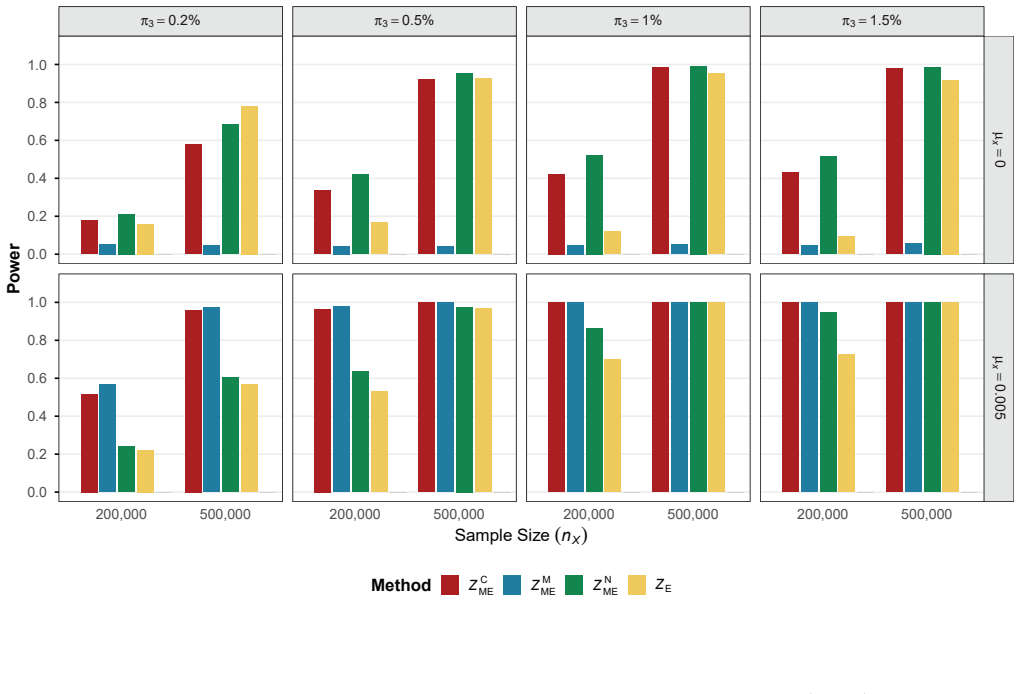
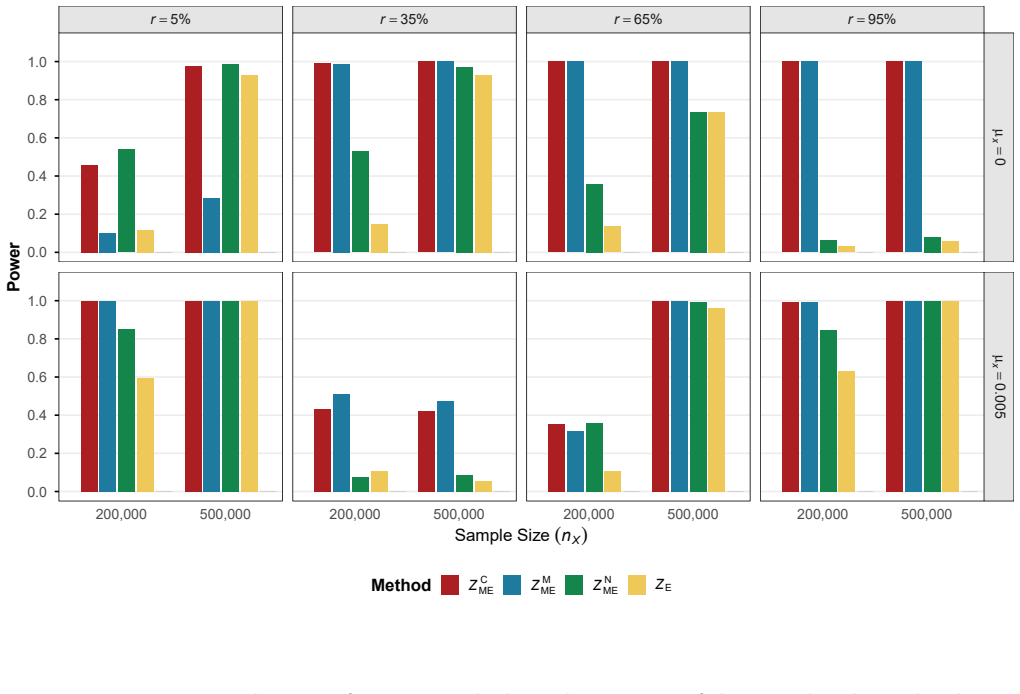
The modified Egger intercept (MEI) test employs a bias-corrected estimator of the intercept obtained from the rerandomized IVW estimator under the null of no directional or correlated pleiotropy. The paper establishes the asymptotic properties of this test and shows that its power is sensitive to SNP orientation. Combining the MEI statistics computed under two specific allele coding schemes produces a single test that exhibits improved type I error control and higher power relative to the conventional EI test, as confirmed by both simulation studies and real data examples.
What carries the argument
The bias-corrected Egger intercept estimator constructed from the rerandomized IVW estimator, which removes the effects of measurement error and winner's curse under the null.
If this is right
- The MEI test supplies a more trustworthy check on whether the IVW causal estimator is biased by pleiotropy.
- Combining results across the two allele coding schemes stabilizes detection power regardless of arbitrary SNP orientation.
- The test can replace the standard EI procedure in routine two-sample summary-data MR analyses.
- Under realistic conditions without pleiotropy the combined test preserves correct type I error rates.
Where Pith is reading between the lines
- Previous MR findings that relied on the uncorrected EI test may warrant re-examination with the modified version.
- The same bias-correction idea could be applied to other intercept-based or regression-based sensitivity analyses in summary-data MR.
- Routine reporting of both allele coding schemes might become standard practice to avoid orientation-dependent power loss.
Load-bearing premise
The rerandomized IVW estimator supplies an accurate bias correction for the Egger intercept when no directional or correlated pleiotropy is present.
What would settle it
A simulation under the null hypothesis of no pleiotropy in which the combined MEI test rejects at a rate materially above the nominal significance level after the rerandomized IVW correction is applied.
Figures
read the original abstract
The Egger intercept (EI) test is a widely used tool to detect horizontal pleiotropy in two-sample summary-data Mendelian randomization. A significant EI test suggests that either the average pleiotropic effect differs from zero (i.e., directional pleiotropy) or the InSIDE (Instrument Strength Independent of Direct Effect) assumption is violated (i.e., correlated pleiotropy) or both. As such, the EI test provides an assessment of the validity of the instrumental variable assumptions, with a non-zero EI indicating that the commonly used inverse-variance weighted (IVW) estimator will be biased. However, the EI test may exhibit inaccurate type one error rates due to biased estimation in Egger regression caused by the measurement error and winner's curse. In this article, we propose a modified EI (MEI) test based on a bias-corrected EI estimator under the null hypothesis of no directional or correlated pleiotropy, leveraging the recently developed rerandomized IVW estimator. We then prove the asymptotic properties of the MEI test under realistic conditions. Like the EI test, we find that the power of the MEI test is also affected by the orientation of SNPs. To enhance the robustness of power, we further combine the MEI test statistics obtained under two specific allele coding schemes. Both simulation and real data studies show that the combined test outperforms the EI test in terms of type one error control and power.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a modified Egger intercept (MEI) test for detecting horizontal pleiotropy (directional or correlated) in two-sample summary-data Mendelian randomization. It constructs a bias-corrected EI estimator using the rerandomized IVW estimator to mitigate measurement-error and winner's-curse bias under the null of no directional or correlated pleiotropy, proves asymptotic properties of the resulting test, and combines MEI statistics across two allele-coding orientations to improve power robustness. Simulations and real-data applications are reported to show superior type-I error control and power relative to the standard EI test.
Significance. If the asymptotic derivations are correct and the finite-sample bias correction is reliable under realistic instrument selection, the MEI and combined tests would offer a more trustworthy diagnostic for IV validity than the existing EI test, with direct implications for downstream causal-effect estimation in MR. The explicit asymptotic proofs and the orientation-robust combination are concrete strengths that distinguish the contribution.
major comments (2)
- [Abstract; §3 (asymptotic properties)] The central claim that the MEI (and combined) test controls type I error at nominal levels rests on the rerandomized IVW supplying an unbiased correction for the EI estimator's finite-sample bias. The manuscript states that asymptotics hold under realistic conditions, but does not demonstrate that the rerandomization procedure replicates the exact winner's-curse mechanism induced by selecting the strongest SNPs from a finite discovery GWAS; residual bias would invalidate the type-I guarantee even when InSIDE holds.
- [Simulation section (referenced in abstract)] Simulations are invoked to support superior type-I control and power, yet the design details (instrument selection threshold, discovery-sample size, correlation structure between pleiotropy and strength) are not shown to match the data-generating process that produces the winner's-curse bias the correction is intended to remove. Without this match, the reported performance gains cannot be taken as evidence that the correction works under the conditions where the EI test is known to fail.
minor comments (2)
- The precise definition of the two allele-coding schemes used for the combined test should be stated explicitly (e.g., reference allele choice relative to the exposure or outcome GWAS) so that readers can reproduce the orientation-robust procedure.
- Table or figure captions for the real-data applications should list the exact number of instruments retained after clumping and the discovery-sample sizes, to allow assessment of how close the settings are to the finite-sample regime where bias correction is most needed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the conditions under which the proposed MEI test provides reliable type I error control. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract; §3 (asymptotic properties)] The central claim that the MEI (and combined) test controls type I error at nominal levels rests on the rerandomized IVW supplying an unbiased correction for the EI estimator's finite-sample bias. The manuscript states that asymptotics hold under realistic conditions, but does not demonstrate that the rerandomization procedure replicates the exact winner's-curse mechanism induced by selecting the strongest SNPs from a finite discovery GWAS; residual bias would invalidate the type-I guarantee even when InSIDE holds.
Authors: The rerandomized IVW estimator is constructed precisely to replicate the finite-sample selection bias arising from choosing the strongest instruments in a discovery GWAS, by resampling the summary statistics conditional on the observed selection event. Section 3 derives the asymptotic normality of the bias-corrected MEI estimator under the null (InSIDE holding with no directional or correlated pleiotropy) and shows that the correction term converges to the exact bias induced by this selection mechanism. We will add an expanded paragraph in §2.2 and §3 explicitly linking the rerandomization steps to the winner's-curse distribution and stating the regularity conditions under which the replication holds. revision: yes
-
Referee: [Simulation section (referenced in abstract)] Simulations are invoked to support superior type-I control and power, yet the design details (instrument selection threshold, discovery-sample size, correlation structure between pleiotropy and strength) are not shown to match the data-generating process that produces the winner's-curse bias the correction is intended to remove. Without this match, the reported performance gains cannot be taken as evidence that the correction works under the conditions where the EI test is known to fail.
Authors: The simulation design in §4 uses selection thresholds (p < 5×10^{-8}) and discovery-sample sizes (N_disc = 10^5–5×10^5) that induce the same order of winner's-curse bias as typical two-sample MR applications, with the correlation between instrument strength and pleiotropy set to zero under the null. To make the match explicit, we will insert a new subsection 4.1 that tabulates the simulation parameters against the theoretical DGP, reports the realized bias of the uncorrected EI estimator, and adds sensitivity analyses varying the selection threshold and discovery-sample size to confirm that type I error remains controlled only when the rerandomized correction is applied. revision: yes
Circularity Check
No significant circularity; derivation relies on external bias correction and independent evaluation
full rationale
The paper proposes the MEI test by applying a bias correction drawn from the rerandomized IVW estimator (described as recently developed and external to this work), states and proves asymptotic properties under the null, and evaluates type I error and power via separate simulation studies and real-data applications. No equation reduces a claimed prediction or result to a quantity fitted from the same data used to define the test statistic, and no load-bearing premise rests solely on a self-citation chain. The central performance claims are therefore not equivalent to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The rerandomized IVW estimator provides an appropriate bias correction for the Egger intercept under the null of no directional or correlated pleiotropy
- domain assumption Asymptotic properties of the MEI test hold under realistic conditions
Reference graph
Works this paper leans on
-
[1]
Accili, D., Deng, Z., and Liu, Q. (2025). Insulin resistance in type 2 diabetes mellitus. Nature Reviews Endocrinology 21, 413--426
2025
-
[2]
V., Mustelin, L., Kalimeri, M., Kettunen, J., Jokelainen, J., Auvinen, J., et al
Ahola-Olli, A. V., Mustelin, L., Kalimeri, M., Kettunen, J., Jokelainen, J., Auvinen, J., et al. (2019). Circulating metabolites and the risk of type 2 diabetes: a prospective study of 11,896 young adults from four Finnish cohorts. Diabetologia 62, 2298--2309
2019
-
[3]
Boehm, F. J. and Zhou, X. (2022). Statistical methods for Mendelian randomization in genome-wide association studies: a review. Computational and Structural Biotechnology Journal 20, 2338--2351
2022
-
[4]
Bowden, J., Del Greco M, F., Minelli, C., Davey Smith, G., Sheehan, N., and Thompson, J. (2017). A framework for the investigation of pleiotropy in two-sample summary data Mendelian randomization. Statistics in Medicine 36, 1783--1802
2017
-
[5]
A., and Thompson, J
Bowden, J., Del Greco M, F., Minelli, C., Davey Smith, G., Sheehan, N. A., and Thompson, J. R. (2016). Assessing the suitability of summary data for two-sample Mendelian randomization analyses using MR-Egger regression: the role of I^2 statistic. International Journal of Epidemiology 45, 1961--1974
2016
-
[6]
and Holmes, M
Bowden, J. and Holmes, M. V. (2019). Meta-analysis and Mendelian randomization: a review. Research Synthesis Methods 10, 486--496
2019
-
[7]
Burgess, S., Butterworth, A., and Thompson, S. G. (2013). Mendelian randomization analysis with multiple genetic variants using summarized data. Genetic Epidemiology 37, 658--665
2013
-
[8]
A., Timpson, N
Burgess, S., Scott, R. A., Timpson, N. J., Davey Smith, G., Thompson, S. G., and EPIC-InterAct Consortium (2015). Using published data in Mendelian randomization: a blueprint for efficient identification of causal risk factors. European Journal of Epidemiology 30, 543--552
2015
-
[9]
and Thompson, S
Burgess, S. and Thompson, S. G. (2017). Interpreting findings from Mendelian randomization using the MR-Egger method. European Journal of Epidemiology 32, 377--389
2017
-
[10]
and Ebrahim, S
Davey Smith, G. and Ebrahim, S. (2004). Mendelian randomization: prospects, potentials, and limitations. International Journal of Epidemiology 33, 30--42
2004
-
[11]
M., von Hinke Kessler Scholder, S., Farbmacher, H., Burgess, S., Windmeijer, F., and Davey Smith, G
Davies, N. M., von Hinke Kessler Scholder, S., Farbmacher, H., Burgess, S., Windmeijer, F., and Davey Smith, G. (2015). The many weak instruments problem and Mendelian randomization. Statistics in Medicine 34, 454--468
2015
-
[12]
and Sheehan, N
Didelez, V. and Sheehan, N. (2007). Mendelian randomization as an instrumental variable approach to causal inference. Statistical Methods in Medical Research 16, 309--330
2007
-
[13]
and Burgess, S
Gkatzionis, A. and Burgess, S. (2019). Contextualizing selection bias in Mendelian randomization: how bad is it likely to be? International Journal of Epidemiology 48, 691--701
2019
-
[14]
H., Haberland, V., Baird, D., et al
Hemani, G., Zheng, J., Elsworth, B., Wade, K. H., Haberland, V., Baird, D., et al. (2018). The MR-Base platform supports systematic causal inference across the human phenome. eLife 7, e34408
2018
-
[15]
R., Neumiller, J
Kalyani, R. R., Neumiller, J. J., Maruthur, N. M., and Wexler, D. J. (2025). Diagnosis and treatment of type 2 diabetes in adults: a review. Journal of the American Medical Association 334, 984--1002
2025
-
[16]
I., Karjalainen, J., Palta, P., Sipilä, T
Kurki, M. I., Karjalainen, J., Palta, P., Sipilä, T. P., Kristiansson, K., Donner, K. M., et al. (2023). Finngen provides genetic insights from a well-phenotyped isolated population. Nature 613, 508--518
2023
-
[17]
and Swanson, S
Labrecque, J. and Swanson, S. A. (2018). Understanding the assumptions underlying instrumental variable analyses: a brief review of falsification strategies and related tools. Current Epidemiology Reports 5, 214--220
2018
-
[18]
Lin, Z., Deng, Y., and Pan, W. (2021). Combining the strengths of inverse-variance weighting and Egger regression in Mendelian randomization using a mixture of regressions model. PLoS Genetics 17, e1009922
2021
-
[19]
B., Semiz, S., van Dijk, K
Liu, J., van Klinken, J. B., Semiz, S., van Dijk, K. W., Verhoeven, A., Hankemeier, T., et al. (2017). A Mendelian randomization study of metabolite profiles, fasting glucose, and type 2 diabetes. Diabetes 66, 2915--2926
2017
-
[20]
Ma, X., Wang, J., and Wu, C. (2023). Breaking the winner’s curse in Mendelian randomization: rerandomized inverse variance weighted estimator. The Annals of Statistics 51, 211--232
2023
-
[21]
G., Leyden, G
Richardson, T. G., Leyden, G. M., Wang, Q., Bell, J. A., Elsworth, B., Davey Smith, G., et al. (2022). Characterising metabolomic signatures of lipid-modifying therapies through drug target Mendelian randomisation. PLoS Biology 20, e3001547
2022
-
[22]
M., Holmes, M
Sanderson, E., Glymour, M. M., Holmes, M. V., Kang, H., Morrison, J., Munaf \`o , M. R., et al. (2022). Mendelian randomization. Nature Reviews Methods Primers 2, 6
2022
-
[23]
Slob, E. A. W., Groenen, P. J. F., Thurik, A. R., and Rietveld, C. A. (2017). A note on the use of Egger regression in Mendelian randomization studies. International Journal of Epidemiology 46, 2094--2097
2017
-
[24]
H., Purcell, S
Solovieff, N., Cotsapas, C., Lee, P. H., Purcell, S. M., and Smoller, J. W. (2013). Pleiotropy in complex traits: challenges and strategies. Nature Reviews Genetics 14, 483--495
2013
-
[25]
Su, Y., Xu, S., Ma, Y., Yin, P., Hao, X., Zhou, J., et al. (2024). A modified debiased inverse-variance weighted estimator in two-sample summary-data Mendelian randomization. Statistics in Medicine 43, 5484--5496
2024
-
[26]
Verbanck, M., Chen, C.-Y., Neale, B., and Do, R. (2018). Detection of widespread horizontal pleiotropy in causal relationships inferred from Mendelian randomization between complex traits and diseases. Nature Genetics 50, 693--698
2018
-
[27]
and Alberding, S
Wang, K. and Alberding, S. Y. (2024). Powerful test of heterogeneity in two-sample summary-data Mendelian randomization. Statistics in Medicine 43, 5791--5802
2024
-
[28]
Xie, Z., Zhang, W., Wang, J., and Wu, C. (2026). Winner’s curse free robust Mendelian randomization with summary data. Journal of the American Statistical Association pages 1--13
2026
-
[29]
K., and Liu, Z
Xu, S., Wang, P., Fung, W. K., and Liu, Z. (2023). A novel penalized inverse-variance weighted estimator for Mendelian randomization with applications to COVID-19 outcomes. Biometrics 79, 2184--2195
2023
-
[30]
Xue, H., Shen, X., and Pan, W. (2021). Constrained maximum likelihood-based Mendelian randomization robust to both correlated and uncorrelated pleiotropic effects. The American Journal of Human Genetics 108, 1251--1269
2021
-
[31]
Yavorska, O. O. and Burgess, S. (2017). MendelianRandomization : an R package for performing Mendelian randomization analyses using summarized data. International Journal of Epidemiology 46, 1734--1739
2017
-
[32]
Ye, T., Shao, J., and Kang, H. (2021). Debiased inverse-variance weighted estimator in two-sample summary-data Mendelian randomization. The Annals of Statistics 49, 2079--2100
2021
-
[33]
Zhao, Q., Wang, J., Hemani, G., Bowden, J., and Small, D. S. (2020). Statistical inference in two-sample summary-data Mendelian randomization using robust adjusted profile score. The Annals of Statistics 48, 1742--1769
2020
-
[34]
Ma, X., Wang, J. & Wu, C. (2023). Breaking the winner’s curse in Mendelian randomization: Rerandomized inverse variance weighted estimator. The Annals of Statistics 51 , 211--232
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.