DNSMOS-C: Improving End-to-end Speech Quality Models via Contrastive Learning
Pith reviewed 2026-06-26 03:13 UTC · model grok-4.3
The pith
DNSMOS-C adds a MOS-guided triplet contrastive loss to intermediate embeddings in an end-to-end speech quality model, improving correlations and out-of-domain generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
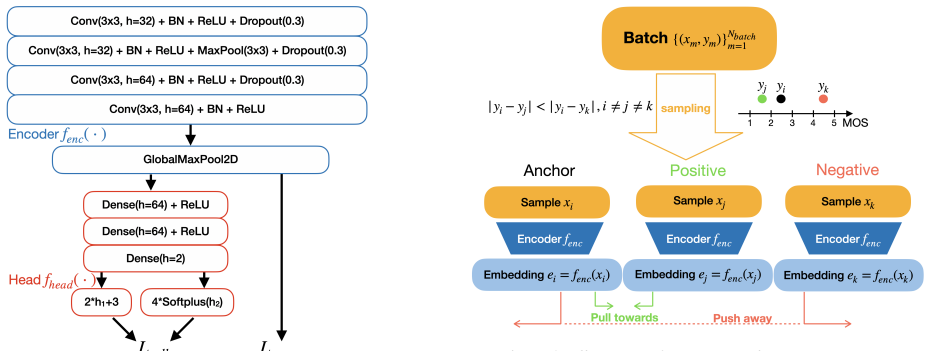
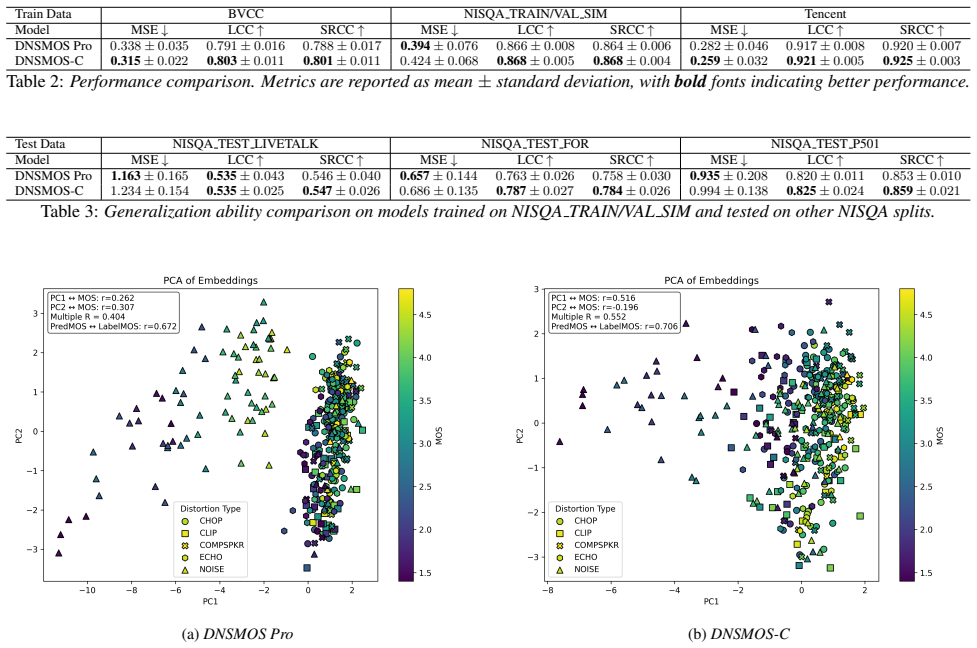
DNSMOS-C extends the DNSMOS Pro framework by integrating a MOS-guided triplet-based contrastive loss applied directly to intermediate embeddings. This joint supervision produces speech representations that exhibit an emergent low-dimensional quality ordering while preserving the efficiency of the original end-to-end regression model. Experiments across multiple datasets confirm higher correlation metrics than DNSMOS Pro together with stronger generalization on challenging out-of-domain test sets.
What carries the argument
MOS-guided triplet-based contrastive loss applied directly to intermediate embeddings
If this is right
- Correlation metrics with human MOS ratings increase compared with the baseline DNSMOS Pro model.
- Generalization improves on out-of-domain test sets without changes to model size or inference cost.
- Latent representations develop an emergent low-dimensional ordering aligned with perceptual quality.
- Training stability increases and interpretability of the embeddings improves as a direct result of the ordering.
- The entire model remains a single unified end-to-end network without multi-stage training or external SSL encoders.
Where Pith is reading between the lines
- The same contrastive supervision pattern could be tested on other regression targets in audio, such as intelligibility or speaker similarity, to check whether quality-like orderings emerge.
- The low-dimensional quality axis observed in the latent space might allow dimensionality reduction or linear probes for quick quality estimation in resource-constrained settings.
- Because the method avoids separate pre-training stages, it opens a route for contrastive regularization inside any supervised audio regression pipeline that already produces embeddings.
Load-bearing premise
Adding the contrastive loss to the embeddings will organize the latent space by perceptual quality without degrading the primary MOS regression task.
What would settle it
A new out-of-domain test set where DNSMOS-C shows no improvement in Pearson or Spearman correlation with human MOS scores, or where t-SNE visualizations of the embeddings fail to display a monotonic quality ordering.
Figures
read the original abstract
We introduce DNSMOS-C, a compact end-to-end speech quality assessment model that extends the DNSMOS Pro framework by integrating a MOS-guided triplet-based contrastive loss. Applied directly to the intermediate embeddings, this contrastive supervision encourages the latent space to be better organized with respect to perceptual quality while preserving the simplicity and efficiency of DNSMOS Pro. Unlike prior methods that depend on large pre-trained self-supervised learning (SSL) encoders and multi-stage training, DNSMOS-C jointly learns speech representations and MOS regression within a single, unified framework. Experiments on multiple datasets show that DNSMOS-C consistently improves correlation metrics over DNSMOS Pro and achieves better generalization on challenging out-of-domain test sets. Furthermore, latent space analyses indicate that our approach learns representations that exhibit an emergent low-dimensional quality ordering, which enhances interpretability and improves training stability. These findings demonstrate that MOS-guided contrastive learning enables more robust and accurate quality predictions without incurring additional computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DNSMOS-C, extending DNSMOS Pro with a MOS-guided triplet-based contrastive loss applied directly to intermediate embeddings. It claims this single-stage approach organizes the latent space by perceptual quality, yielding improved correlation metrics over DNSMOS Pro, better generalization on out-of-domain test sets, and an emergent low-dimensional quality ordering that aids interpretability and training stability, all without extra computational overhead or reliance on large SSL encoders.
Significance. If the reported gains in correlation, OOD generalization, and latent-space organization hold under rigorous verification, the work would demonstrate a practical route to improving compact end-to-end speech quality models via auxiliary contrastive supervision, offering efficiency and interpretability advantages over multi-stage SSL-based alternatives.
major comments (1)
- [Abstract] Abstract: the claims of consistent correlation improvements, better OOD generalization, and emergent quality ordering are stated without any numerical results, error bars, dataset identifiers, ablation details, or verification steps, preventing assessment of whether the central empirical claims are supported.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The single major comment concerns the level of detail in the abstract. We address this point below and agree that a modest revision to the abstract will improve readability without altering the paper's contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of consistent correlation improvements, better OOD generalization, and emergent quality ordering are stated without any numerical results, error bars, dataset identifiers, ablation details, or verification steps, preventing assessment of whether the central empirical claims are supported.
Authors: We agree that the abstract is written at a high level and does not include quantitative values. The full manuscript (Sections 4 and 5) supplies the requested details: PCC/SRCC improvements with standard deviations across multiple runs, explicit dataset names (e.g., DNS-2020, NISQA, out-of-domain sets), ablation tables comparing the contrastive loss, and verification via embedding visualizations and stability metrics. To address the concern directly, we will revise the abstract to incorporate the most salient numerical results (e.g., average PCC gain and the primary OOD test set) while remaining within typical length constraints. Ablation and verification steps are inherently paper-body content and will remain there. revision: yes
Circularity Check
No significant circularity; empirical validation only
full rationale
The paper introduces DNSMOS-C by extending DNSMOS Pro with a MOS-guided triplet contrastive loss applied to intermediate embeddings. All central claims (improved correlations, better OOD generalization, emergent quality ordering) are supported by experimental results on multiple datasets, ablations, and latent space visualizations rather than any mathematical derivation or prediction. No equations are presented that reduce outputs to inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The work is self-contained as an empirical architecture modification whose performance is externally falsifiable on held-out test sets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
quality manifold,
Introduction Accurate and automatic speech quality assessment (SQA) plays a critical role in developing and monitoring modern audio tech- nologies, ranging from streaming services to generative speech models. Traditionally, subjective evaluations such as mean opinion scores (MOS) provide the gold standard for quality as- sessment, but they are time-consum...
-
[2]
Method 2.1. Problem formulation A MOS-labeled speech quality dataset consists of pairwise sam- ples(x, y), wherexdenotes a speech clip andyits correspond- ing MOS. We denote the dataset asD={(x n yn)}N n=1, where Nis the total number of speech clips in the dataset. The goal of an SQA model is to design a regression func- tionf θθθ(x)with parametersθ θθtha...
Pith/arXiv arXiv 2026
-
[3]
quality manifold
Experiments We implement DNSMOS-C 1 and train it on several datasets, comparing its performance against the baseline DNSMOS Pro. 1Code and checkpoints will be available athttps://github. com/Hope-Liang/DNSMOS-C. Dataset Usage Language # Samples Ratings/Clip Audio Source BVCC [18] train/val/test en 4974/1066/1066 8 Synthetic from TTS and VC systems Tencent...
2000
-
[4]
Conclusions In this work, we introduced DNSMOS-C, a novel end-to- end speech quality model that successfully integrates MOS- guided contrastive learning into the DNSMOS Pro framework. Our core contribution is a new methodology that adapts the SCOREQ triplet loss for an efficient, single-stage training pipeline, avoiding the need for pre-trained models or ...
-
[5]
The computations were enabled by re- sources provided by Chalmers e-Commons at Chalmers
Acknowledgement The research is supported by funding from Digital Futures Cen- ter, European Defence Fund REACT II project, and partially supported by the Wallenberg AI, Autonomous Systems and Software Program (W ASP) funded by the Knut and Alice Wal- lenberg Foundation. The computations were enabled by re- sources provided by Chalmers e-Commons at Chalmers
-
[6]
The authors carefully reviewed and edited all AI-generated sugges- tions and assume full responsibility for the final content of the paper
Use of Generative AI Disclosure During the preparation of this manuscript, the authors used Gemini by Google to polish the language, correct grammati- cal errors, and improve the overall readability of the text. The authors carefully reviewed and edited all AI-generated sugges- tions and assume full responsibility for the final content of the paper
-
[7]
Generaliza- tion ability of mos prediction networks,
E. Cooper, W.-C. Huang, T. Toda, and J. Yamagishi, “Generaliza- tion ability of mos prediction networks,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8442–8446
2022
-
[8]
Utmos: Utokyo-sarulab system for voicemos challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,” inProc. Interspeech 2022, 09 2022, pp. 4521– 4525
2022
-
[9]
X. Liang, F. Cumlin, V . Ungureanu, C. KA Reddy, C. Sch ¨uldt, and S. Chatterjee, “Selection of layers from self-supervised learn- ing models for predicting mean-opinion-score of speech,”arXiv preprint arXiv:2508.08962, 2025
arXiv 2025
-
[10]
Multivariate probabilistic assessment of speech quality,
F. Cumlin, X. Liang, V . Ungureanu, C. K. Reddy, C. Sch¨uldt, and S. Chatterjee, “Multivariate probabilistic assessment of speech quality,” inProc. Interspeech 2025, 2025
2025
-
[11]
Enabling auditory large language models for automatic speech quality evaluation,
S. Wang, W. Yu, Y . Yang, C. Tang, Y . Li, J. Zhuang, X. Chen, X. Tian, J. Zhang, G. Sunet al., “Enabling auditory large language models for automatic speech quality evaluation,” inICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[12]
MOSNet: Deep learning-based ob- jective assessment for voice conversion,
C.-C. Lo, S.-W. Fu, W.-C. Huang, X. Wang, J. Yamagishi, Y . Tsao, and H.-m. Wang, “MOSNet: Deep learning-based ob- jective assessment for voice conversion,” inInterspeech 2019, 09 2019, pp. 1541–1545
2019
-
[13]
Deepmos: Deep posterior mean-opinion-score of speech,
X. Liang, F. Cumlin, C. Sch ¨uldt, and S. Chatterjee, “Deepmos: Deep posterior mean-opinion-score of speech,” inInterspeech
-
[14]
NISQA: A deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets,” inInterspeech
-
[15]
LDNet: Unified listener dependent modeling in MOS prediction for syn- thetic speech,
W.-C. Huang, E. Cooper, J. Yamagishi, and T. Toda, “LDNet: Unified listener dependent modeling in MOS prediction for syn- thetic speech,” inICASSP 2022 - 2022 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), 2022
2022
-
[16]
DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise sup- pressors,
C. Reddy, V . Gopal, and R. Cutler, “DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise sup- pressors,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, June 6-11, 2021, 06 2021
2021
-
[17]
Dnsmos pro: A reduced-size dnn for probabilistic mos of speech,
F. Cumlin, X. Liang, V . Ungureanu, C. KA Reddy, C. Sch¨uldt, and S. Chatterjee, “Dnsmos pro: A reduced-size dnn for probabilistic mos of speech,” inProc. Interspeech 2024, 2024, pp. 4818–4822
2024
-
[18]
Generalization ability of end-to-end non-intrusive speech quality models,
F. Cumlin, X. Liang, and S. Chatterjee, “Generalization ability of end-to-end non-intrusive speech quality models,” in2024 IEEE 21st India Council International Conference (INDICON), 2024, pp. 1–5
2024
-
[19]
In defense of the triplet loss for person re-identification,
A. Hermans, L. Beyer, and B. Leibe, “In defense of the triplet loss for person re-identification,”arXiv preprint arXiv:1703.07737, 2017
Pith/arXiv arXiv 2017
-
[20]
Learning contrastive embedding in low-dimensional space,
S. Chen, C. Gong, J. Li, J. Yang, G. Niu, and M. Sugiyama, “Learning contrastive embedding in low-dimensional space,”Ad- vances in Neural Information Processing Systems, vol. 35, pp. 6345–6357, 2022
2022
-
[21]
Improving perceptual audio aesthetic assessment via triplet loss and self-supervised embeddings,
D. A. Wisnu, R. E. Zezario, S. Rini, H.-M. Wang, and Y . Tsao, “Improving perceptual audio aesthetic assessment via triplet loss and self-supervised embeddings,”arXiv preprint arXiv:2509.03292, 2025
arXiv 2025
-
[22]
Scoreq: Speech qual- ity assessment with contrastive regression,
A. Ragano, J. Skoglund, and A. Hines, “Scoreq: Speech qual- ity assessment with contrastive regression,”Advances in Neural Information Processing Systems, vol. 37, pp. 105 702–105 729, 2024
2024
-
[23]
Deepmos-b: Deep posterior mean-opinion-score using beta distribution,
X. Liang, F. Cumlin, V . Ungureanu, C. K. Reddy, C. Sch¨uldt, and S. Chatterjee, “Deepmos-b: Deep posterior mean-opinion-score using beta distribution,” in2024 32nd European Signal Process- ing Conference (EUSIPCO). IEEE, 2024, pp. 416–420
2024
-
[24]
W.-C. Huang, E. Cooper, Y . Tsao, H.-M. Wang, T. Toda, and J. Yamagishi, “The voicemos challenge 2022,”arXiv preprint arXiv:2203.11389, 2022
arXiv 2022
-
[25]
Conferencingspeech 2022 challenge: Non-intrusive objective speech quality assessment (nisqa) challenge for online conferencing applications,
G. Yi, W. Xiao, Y . Xiao, B. Naderi, S. Moller, W. Wardah, G. Mit- tag, R. Cutler, Z. Zhang, D. S. Williamson, F. Chen, F. Yang, and S. Shang, “Conferencingspeech 2022 challenge: Non-intrusive objective speech quality assessment (nisqa) challenge for online conferencing applications,” inInterspeech, 2022
2022
-
[26]
Tcd-voip, a research database of degraded speech for assessing quality in voip applications,
N. Harte, E. Gillen, and A. Hines, “Tcd-voip, a research database of degraded speech for assessing quality in voip applications,” in 2015 Seventh International Workshop on Quality of Multimedia Experience (QoMEX). IEEE, 2015, pp. 1–6
2015
-
[27]
Impairments are clustered in latents of deep neu- ral network-based speech quality models,
F. Cumlin, X. Liang, V . Ungureanu, C. K. Reddy, C. Sch¨uldt, and S. Chatterjee, “Impairments are clustered in latents of deep neu- ral network-based speech quality models,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[28]
Esc: Dataset for environmental sound classifica- tion,
K. J. Piczak, “Esc: Dataset for environmental sound classifica- tion,” inProceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 1015–1018
2015
-
[29]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,”arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[30]
Notes on the history of correlation,
K. Pearson, “Notes on the history of correlation,”Biometrika, vol. 13, no. 1, pp. 25–45, 1920
1920
-
[31]
The proof and measurement of association be- tween two things,
C. Spearman, “The proof and measurement of association be- tween two things,”The American journal of psychology, vol. 100, no. 3/4, pp. 441–471, 1987
1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.