DeSRPA: Decoupled Speech Role-Playing Agent via Inference-Time Intervention
Pith reviewed 2026-06-26 23:21 UTC · model grok-4.3
The pith
DeSRPA creates speech role-playing agents by steering frozen models at inference time with separate cognitive and expressive control vectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
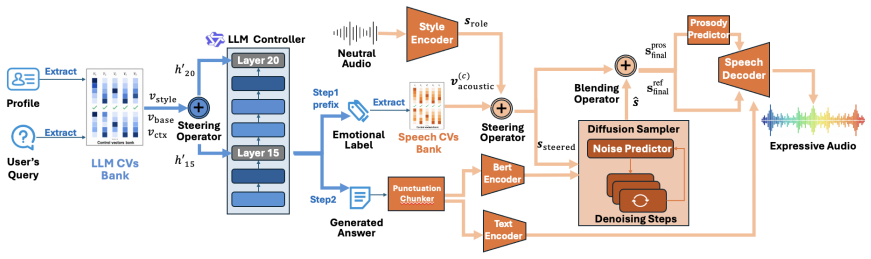
DeSRPA is an agentic framework that applies inference-time intervention via a dual-level control vector mechanism—Internal Cognitive Steering and External Expressive Rendering—on frozen backbones to synchronize cognitive reasoning with paralinguistic expression in speech role-playing, eliminating reliance on role-specific data and the modality alignment tax of end-to-end fine-tuning.
What carries the argument
dual-level control vector mechanism (Internal Cognitive Steering for cognitive alignment and External Expressive Rendering for voice output)
If this is right
- DeSRPA outperforms end-to-end fine-tuned baselines in personality and emotional consistency on the SpeechRole and OmniCharacter benchmarks.
- The method achieves speech naturalness that narrows the gap with proprietary systems such as GPT-4o Audio.
- The approach remains fully scalable and requires no additional training or role-specific data.
- Intrinsic reasoning capabilities of the underlying language models are preserved because no fine-tuning occurs.
Where Pith is reading between the lines
- The same inference-time steering pattern could be tested on other multimodal tasks where fine-tuning currently creates alignment costs between modalities.
- Control vectors might be precomputed once per character and swapped instantly, enabling rapid deployment across many roles on the same backbone.
- Because the two vectors operate independently, future work could optimize the cognitive vector and the expressive vector on separate datasets without retraining the whole system.
Load-bearing premise
Applying separate cognitive and expressive control vectors at inference time on frozen models can keep personality and emotional consistency aligned without any role-specific training data.
What would settle it
If DeSRPA is evaluated on a fresh set of characters never encountered during pretraining and its personality-consistency scores fall below those of a standard end-to-end fine-tuned model on the same set, the generalization claim would be refuted.
Figures
read the original abstract
While Large Language Models (LLMs) have revolutionized text-based role-playing, creating immersive Speech Role-Playing Agents (SRPAs) requires a seamless bridge between cognitive reasoning and paralinguistic nuances. Current SRPAs primarily rely on end-to-end (E2E) fine-tuning. However, this paradigm suffers from poor generalization to unseen characters due to its reliance on role-specific data, while imposing a "modality alignment tax" that degrades intrinsic LLM reasoning capabilities. We propose DeSRPA, an agentic framework for character role play via inference-time intervention on frozen backbones. DeSRPA employs a dual-level control vector mechanism, Internal Cognitive Steering and External Expressive Rendering, to synchronize "mind" and "voice". Experiments on SpeechRole and OmniCharacter benchmarks demonstrate that DeSRPA significantly outperforms E2E baselines in personality and emotional consistency. It achieves high speech naturalness, narrowing the gap with proprietary models like GPT-4o Audio, while remaining a scalable and training-free paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeSRPA, an agentic framework for speech role-playing agents that applies inference-time intervention on frozen backbones using a dual-level control vector mechanism (Internal Cognitive Steering and External Expressive Rendering) to decouple and synchronize cognitive reasoning with paralinguistic expression. It claims this training-free approach outperforms end-to-end fine-tuned baselines on the SpeechRole and OmniCharacter benchmarks in personality and emotional consistency while achieving high speech naturalness that narrows the gap to proprietary models such as GPT-4o Audio.
Significance. If the empirical claims hold and the method is shown to be truly independent of role-specific data, the result would be significant: it offers a scalable, training-free paradigm that avoids the generalization limitations and modality-alignment costs of E2E fine-tuning, potentially enabling more robust SRPAs that preserve intrinsic LLM reasoning capabilities.
major comments (2)
- [Method] Method section (control-vector construction): the procedure for deriving or computing the Internal Cognitive Steering and External Expressive Rendering vectors is not specified. This detail is load-bearing for the central claim that the framework operates purely via inference-time intervention on frozen backbones without role-specific data or training; any implicit per-role processing would collapse the claimed generalization advantage over E2E baselines.
- [Experiments] Experiments section: no quantitative metrics, baseline implementations, statistical significance tests, or ablation results are supplied to support the assertions of significant outperformance in personality/emotional consistency or the narrowing of the naturalness gap to GPT-4o Audio. Without these, the empirical support for the dual-vector mechanism cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: the phrase 'significantly outperforms' is used without any accompanying numbers or effect sizes; a brief quantitative summary would strengthen the abstract.
- [Method] Notation: the terms 'Internal Cognitive Steering control vector' and 'External Expressive Rendering control vector' are introduced without an explicit equation or pseudocode definition on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that both the method details and experimental evidence require substantial clarification and will revise the manuscript accordingly to strengthen the submission.
read point-by-point responses
-
Referee: [Method] Method section (control-vector construction): the procedure for deriving or computing the Internal Cognitive Steering and External Expressive Rendering vectors is not specified. This detail is load-bearing for the central claim that the framework operates purely via inference-time intervention on frozen backbones without role-specific data or training; any implicit per-role processing would collapse the claimed generalization advantage over E2E baselines.
Authors: We agree the construction procedure must be made explicit. The revised Method section will include a dedicated subsection specifying that both vectors are computed at inference time solely from frozen backbone activations triggered by generic, role-independent prompts. No role-specific data or training is used at any stage; the vectors are derived once from broad cognitive and expressive templates and then applied uniformly. This addition will directly substantiate the training-free and generalization claims. revision: yes
-
Referee: [Experiments] Experiments section: no quantitative metrics, baseline implementations, statistical significance tests, or ablation results are supplied to support the assertions of significant outperformance in personality/emotional consistency or the narrowing of the naturalness gap to GPT-4o Audio. Without these, the empirical support for the dual-vector mechanism cannot be evaluated.
Authors: The current manuscript indeed presents only high-level claims without supporting numbers or controls. We will expand the Experiments section to report concrete metrics (e.g., personality consistency scores, emotional alignment, naturalness MOS), full baseline implementations, statistical significance tests, and ablations isolating each control vector. These additions will allow direct evaluation of the dual-level mechanism's contribution. revision: yes
Circularity Check
No circularity; derivation self-contained on external benchmarks
full rationale
The provided abstract and description contain no equations, parameter-fitting steps, or self-citations that reduce any claimed result to its own inputs by construction. DeSRPA is presented as an inference-time method on frozen backbones, with performance claims resting on comparisons to E2E baselines on SpeechRole and OmniCharacter benchmarks rather than any definitional equivalence or load-bearing self-reference. No control-vector construction procedure is detailed here, but the absence of any quoted reduction (e.g., a prediction that is the fit itself) means the central claims do not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Internal Cognitive Steering control vector
no independent evidence
-
External Expressive Rendering control vector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
generalization trap
Introduction Recent advancements in Large Language Models (LLMs) have revolutionized the development of Role-Playing Agents (RPAs), enabling them to simulate diverse personas with im- pressive linguistic fidelity [1, 2]. However, text-based inter- actions often lack the paralinguistic nuances, such as timbre, prosody, and emotion that are essential for tr...
-
[2]
DeSRPA: Decoupled Speech Role-Playing Agent via Inference-Time Intervention
Related Work While LLM-based Role-Playing Agents like RoleLLM [2] and CharacterGLM [7] achieve high linguistic fidelity, cas- caded LLM-TTS pipelines introducesemantic-acoustic mis- alignment[8]. The intermediate textual bottleneck drops essen- tial emotional reasoning, preventing TTS from rendering par- alinguistic nuances. Furthermore, existing systems ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Instead of updat- ing weights, it injects disentangledPersonality VectorsandLan- guage Feature Vectorsinto the inference stream
Methodology As illustrated in Fig 1, the proposed framework bridges the gap between cognitive reasoning and acoustic expression via a dual- level control mechanism that operates on two frozen backbones: Internal Cognitive Steering:DeSRPA utilizes a frozen LLM, Qwen3-4B [13], as the cognitive brain. Instead of updat- ing weights, it injects disentangledPer...
-
[4]
Experiment 4.1. Experimental Settings To evaluate character fidelity under both plot-based and open- domain interaction scenarios, we utilize two distinct datasets. SpeechRole-Data test split [4] serves as our primary bench mark for plot-based evaluation, where queries have verifiable answers anchored to established source material. We curate a subset of ...
-
[5]
By injecting dual-level control vectors into frozen LLM and StyleTTS 2 [6] backbones, DeSRPA tightly aligns cognitive personae with acoustic ex- pression
Conclusion We propose DeSRPA, a method for high-fidelity character adap- tation via lightweight inference-time intervention that bypasses resource-intensive E2E fine-tuning. By injecting dual-level control vectors into frozen LLM and StyleTTS 2 [6] backbones, DeSRPA tightly aligns cognitive personae with acoustic ex- pression. Experiments demonstrate that...
-
[6]
Acknowledgments This work was supported by JSPS KAKENHI JP25K00161
-
[7]
All arguments, analysis, and conclusions are my own
Generative AI Use Disclosure Generative AI tools were used only for language polishing, grammar correction, and improving the clarity of this work. All arguments, analysis, and conclusions are my own. AI-generated suggestions were reviewed and edited before inclusion
-
[8]
Crab: A novel configurable role-playing LLM with assessing benchmark,
K. He, Y . Huang, W. Wang, D. Ran, D. Shenget al., “Crab: A novel configurable role-playing LLM with assessing benchmark,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, vol. 1, Vienna, Austria, Jul. 2025, pp. 15 030–15 052
2025
-
[9]
RoleLLM: Benchmarking, eliciting, and enhancing role-playing abilities of large language models,
N. Wang, Z. Peng, H. Que, J. Liu, W. Zhouet al., “RoleLLM: Benchmarking, eliciting, and enhancing role-playing abilities of large language models,” inFindings of the Association for Com- putational Linguistics: ACL 2024, Bangkok, Thailand, Aug. 2024, pp. 14 743–14 777
2024
-
[10]
Benchmarking contextual and paralinguistic reasoning in speech-LLMs: A case study with in-the-wild data,
Q. Wang, H. B. Sailor, T. Liu, W. Zhang, M. Huzaifah et al., “Benchmarking contextual and paralinguistic reasoning in speech-LLMs: A case study with in-the-wild data,” inFindings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, Nov. 2025, pp. 14 133–14 148
2025
-
[11]
SpeechRole: A large-scale dataset and benchmark for evaluating speech role- playing agents,
C. Jiang, J. Sun, Y . Cao, J. Zhuang, H. Liet al., “SpeechRole: A large-scale dataset and benchmark for evaluating speech role- playing agents,”Computing Research Repository, arXiv Preprint, arXiv:2508.02013, Aug 2025
-
[12]
Om- niCharacter: Towards immersive role-playing agents with seam- less speech–language personality interaction,
H. Zhang, R. Luo, X. Liu, Y . Wu, T.-E. Lin, and P. Zeng, “Om- niCharacter: Towards immersive role-playing agents with seam- less speech–language personality interaction,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, Vienna, Austria, Jul. 2025, pp. 26 318–26 331
2025
-
[13]
Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,
Y . A. Li, C. Han, V . Raghavan, G. Mischler, and N. Mesgarani, “Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36, 2023, pp. 19 594–19 621
2023
-
[14]
Character- GLM: Customizing social characters with large language mod- els,
J. Zhou, Z. Chen, D. Wan, B. Wen, Y . Songet al., “Character- GLM: Customizing social characters with large language mod- els,” inProceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing: Industry Track, Miami, FL, USA, Nov. 2024, pp. 1457–1476
2024
-
[15]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,”Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 15 757–15 773, Dec. 2023
2023
-
[16]
V oxRole: A comprehensive benchmark for evaluating speech-based role- playing agents,
W. Wu, L. Cao, X. Wu, Z. Lin, R. Niuet al., “V oxRole: A comprehensive benchmark for evaluating speech-based role- playing agents,”Computing Research Repository, arXiv Preprint, arXiv:2509.03940, Sep. 2025
-
[17]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guoet al., “Representa- tion engineering: A top-down approach to AI transparency,”Com- puting Research Repository, arXiv Preprint,arXiv:2310.01405, Mar 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Emo- sphere++: Emotion-controllable zero-shot text-to-speech via emotion-adaptive spherical vector,
D.-H. Cho, H.-S. Oh, S.-B. Kim, and S.-W. Lee, “Emo- sphere++: Emotion-controllable zero-shot text-to-speech via emotion-adaptive spherical vector,”IEEE Transactions on Affec- tive Computing, vol. 16, no. 3, p. 2365–2380, Jul. 2025
2025
-
[19]
T. Xie, S. Yang, C. Li, D. Yu, and L. Liu, “Emosteer- tts: Fine-grained and training-free emotion-controllable text-to- speech via activation steering,”Computing Research Repository, arXiv Preprint,arXiv:2508.03543, Aug 2025
-
[20]
A. Yang, A. Li, B. Yang, B. Zhang, B. Huiet al., “Qwen3 tech- nical report,”Computing Research Repository, arXiv Preprint, arXiv:2505.09388, May,2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
SAE- SSV: Supervised steering in sparse representation spaces for re- liable control of language models,
Z. He, M. Jin, B. Shen, A. Payani, Y . Zhang, and M. Du, “SAE- SSV: Supervised steering in sparse representation spaces for re- liable control of language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, Suzhou, Jiangsu, China, Nov. 2025, pp. 2207–2236
2025
-
[22]
Beyond english-centric llms: What language do multilingual language models think in?
C. Zhong, F. Cheng, Q. Liu, J. Jiang, Z. Wan, C. Chu, Y . Murawaki, and S. Kurohashi, “Beyond english-centric llms: What language do multilingual language models think in?” 2024. [Online]. Available: https://arxiv.org/abs/2408.10811
-
[23]
Personality Vector: Modu- lating personality of large language models by model merging,
S. Sun, S. Y . Baek, and J. H. Kim, “Personality Vector: Modu- lating personality of large language models by model merging,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Suzhou, Jiangsu, China, Nov. 2025, pp. 24 656–24 677
2025
-
[24]
Facet-level persona control by trait-activated routing with contrastive sae for role- playing llms,
W. Tang, Z. Wan, T. Komamizu, and I. Ide, “Facet-level persona control by trait-activated routing with contrastive sae for role- playing llms,”Computing Research Repository, arXiv Preprint, arXiv:2602.19157, 2026
-
[25]
A personality trait-based interac- tionist model of job performance,
R. P. Tett and D. D. Burnett, “A personality trait-based interac- tionist model of job performance,”Journal of Applied Psychology, vol. 88, no. 3, pp. 500–517, 2003
2003
-
[26]
Emotional voice conver- sion: Theory, databases and ESD,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Emotional voice conver- sion: Theory, databases and ESD,”Speech Communication, vol. 137, pp. 1–18, 2022
2022
-
[27]
CREMA-D: Crowd-Sourced Emotional Multi- modal Actors Dataset,
H. Cao, D. G. Cooper, M. K. Keutmann, R. C. Gur, A. Nenkova, and R. Verma, “CREMA-D: Crowd-Sourced Emotional Multi- modal Actors Dataset,”IEEE Transactions on Affective Comput- ing, vol. 5, no. 4, pp. 377–390, 2014
2014
-
[28]
Emo2Vec: Learning generalized emotion representation by multi-task train- ing,
P. Xu, A. Madotto, C.-S. Wu, J. H. Park, and P. Fung, “Emo2Vec: Learning generalized emotion representation by multi-task train- ing,” inProceedings of the 9th Workshop on Computational Ap- proaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, Oct. 2018, pp. 292–298
2018
-
[29]
Cross-speaker emotion disentangling and transfer for end-to-end speech synthe- sis,
T. Li, X. Wang, Q. Xie, Z. Wang, and L. Xie, “Cross-speaker emotion disentangling and transfer for end-to-end speech synthe- sis,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 30, p. 1448–1460, Apr. 2022
2022
-
[30]
J. Xu, Z. Guo, J. He, H. Hu, T. Heet al., “Qwen2.5-omni tech- nical report,”Computing Research Repository, arXiv Preprint, arXiv:2503.20215, Mar. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
LLaMA- omni 2: LLM-based real-time spoken chatbot with autoregressive streaming speech synthesis,
Q. Fang, Y . Zhou, S. Guo, S. Zhang, and Y . Feng, “LLaMA- omni 2: LLM-based real-time spoken chatbot with autoregressive streaming speech synthesis,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, vol. 1, Vienna, Austria, Jul. 2025, pp. 18 617–18 629
2025
-
[32]
J. Xu, Z. Guo, J. He, H. Hu, T. Heet al., “Gpt-4o sys- tem card,”Computing Research Repository, arXiv Preprint, arXiv:2410.21276, Oct. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Alibaba cloud documentation,
Alibaba Cloud, “Alibaba cloud documentation,” https://www. alibabacloud.com/, 2026, accessed: 2026-02-22
2026
-
[34]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdevaet al., “Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next genera- tion agentic capabilities,”Computing Research Repository, arXiv Preprint,arXiv:2507.06261, Jul. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Wavlm: Large-scale self-supervised pre-training for full stack speech pro- cessing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liuet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech pro- cessing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, p. 1505–1518, Oct. 2022
2022
-
[36]
emotion2vec: Self-supervised pre-training for speech emotion representation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gaoet al., “emotion2vec: Self-supervised pre-training for speech emotion representation,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 15 747–15 760. [Online]. Available: http...
2024
-
[37]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhaoet al., “Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training,” 2025. [Online]. Available: https://arxiv.org/abs/ 2505.17589
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.