NEURON-Fabric: Architecture-Runtime Co-Design for Controlled Low-Bit Gradient Communication
Pith reviewed 2026-06-25 19:43 UTC · model grok-4.3
The pith
Profile-guided runtime control of low-bit gradients preserves accuracy and cuts communication in distributed training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
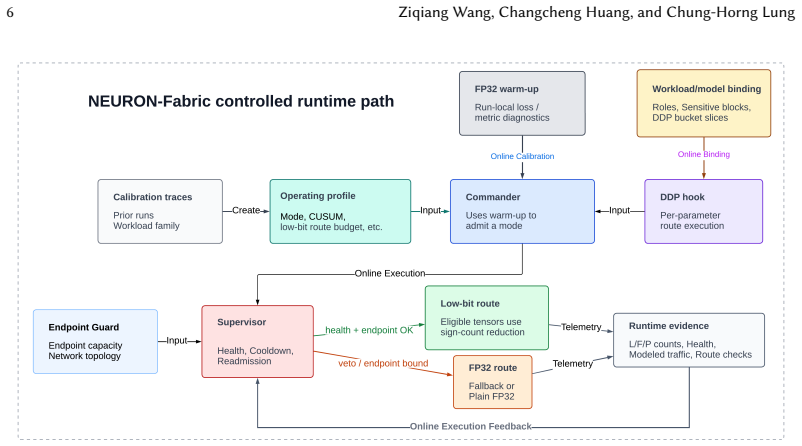
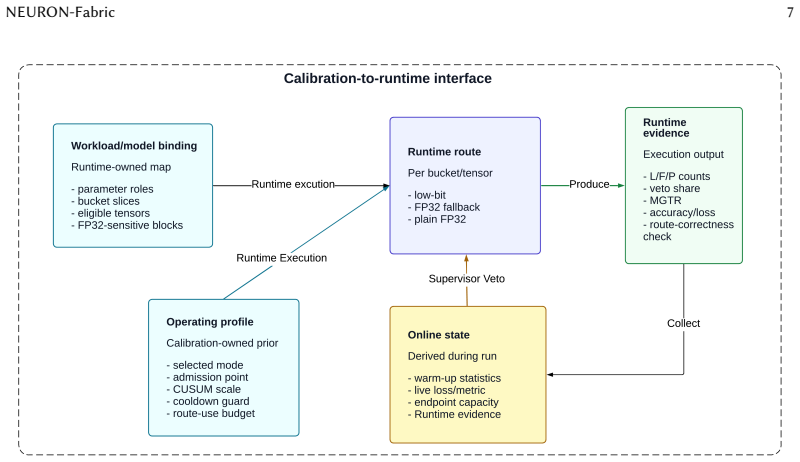
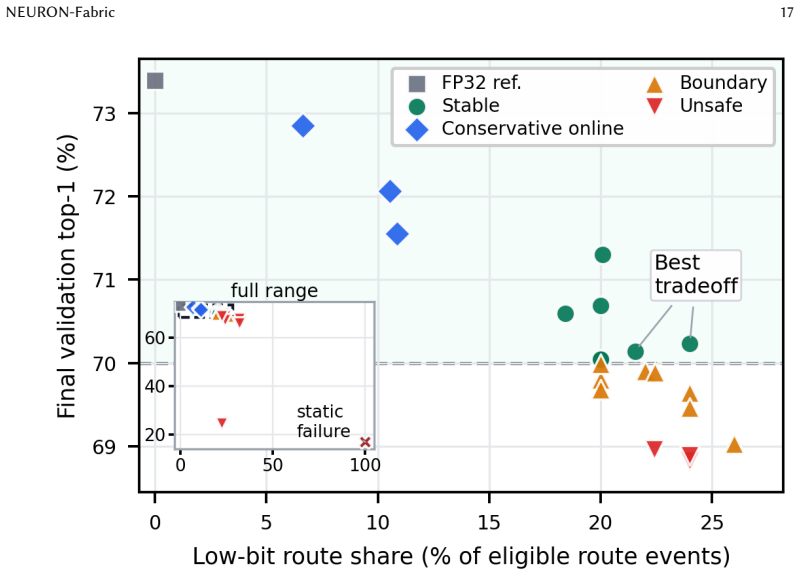
The central claim is that NEURON-Fabric, by using calibrated operating profiles, model-aware runtime bindings, online training-health monitoring, and reducer-capacity checks, can admit low-bit aggregation only when safe, falling back to FP32 otherwise. This architecture-runtime co-design preserves model semantics and demonstrates accuracy preservation near full-precision while reducing modeled traffic across vision, Transformer, and language model workloads, in contrast to static low-bit methods that can destabilize training.
What carries the argument
NEURON-Fabric, the profile-guided runtime system using calibration, monitoring, and capacity checks to control low-bit vs full-precision gradient aggregation routes.
If this is right
- Static low-bit communication can collapse training accuracy.
- Profile-guided control preserves accuracy near full-precision references or calibrated targets.
- Reduces modeled gradient-communication traffic in the evaluated settings.
- The same routing and fallback mechanisms work across model families and multi-node deployments.
- Reducer-side measurements identify when compact aggregation reduces cost and when fallback is needed.
Where Pith is reading between the lines
- The co-design approach could be applied to other communication optimizations in distributed systems.
- Hardware accelerators might benefit from built-in support for such dynamic precision decisions.
- Validation on a wider range of workloads would strengthen the generality claims.
- The method suggests potential for automated profile generation in future systems.
Load-bearing premise
The assumption that calibrated operating profiles combined with online training-health monitoring and reducer-capacity checks can reliably identify safe low-bit opportunities without post-hoc tuning that affects the central accuracy claims.
What would settle it
A test run on a workload where the profile-guided system selects low-bit routes but training accuracy falls substantially below the full-precision reference despite the monitoring.
Figures
read the original abstract
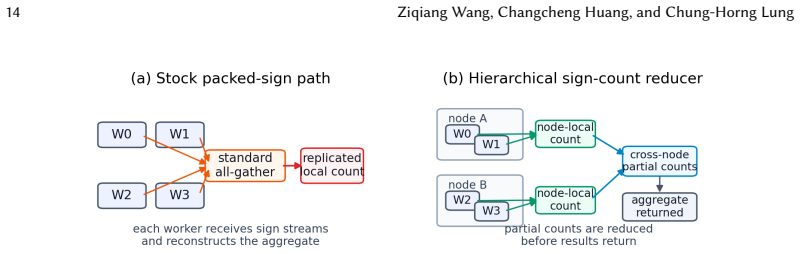
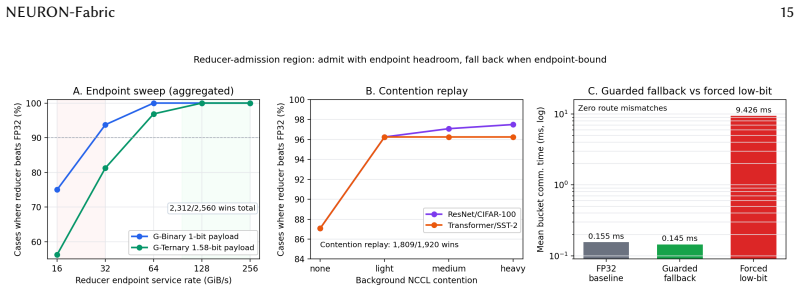
Large-scale neural-network training repeatedly aggregates gradients across devices, making communication a central cost in distributed learning. Low-bit gradient aggregation can reduce this cost, but applying it as a static replacement for full-precision communication can destabilize training because safe precision depends on training phase, model structure, runtime bucketization, and the communication substrate. This paper presents NEURON-Fabric, a profile-guided runtime system for controlled low-bit gradient communication. NEURON-Fabric uses calibrated operating profiles, model-aware runtime bindings, online training-health monitoring, and reducer-capacity checks to decide when low-bit aggregation should be admitted, when execution should fall back to FP32, and which model regions are eligible for each route. The runtime preserves model semantics inside mixed DDP buckets and treats reducer admission as an architecture-runtime co-design problem rather than as a standalone compression operator. Across vision, Transformer, and autoregressive language-model workloads, NEURON-Fabric validates the path from calibration to distributed communication-hook execution. Static low-bit communication can collapse training accuracy, while profile-guided control preserves accuracy near full-precision references or calibrated targets and reduces modeled gradient-communication traffic in the evaluated settings. Transformer and billion-parameter language-model checks show that the same routing and fallback mechanisms execute across model families and multi-node deployments. Reducer-side replay and reducer-path measurements identify when compact sign-count aggregation is expected to reduce communication cost and when endpoint capacity should trigger fallback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents NEURON-Fabric, a profile-guided runtime system for architecture-runtime co-design of controlled low-bit gradient communication in distributed training. It employs calibrated operating profiles, model-aware bindings, online training-health monitoring, and reducer-capacity checks to decide when to admit low-bit aggregation, when to fall back to FP32, and which model regions are eligible. The central claim is that static low-bit communication can collapse training accuracy while profile-guided control preserves accuracy near full-precision references and reduces modeled gradient-communication traffic across vision, Transformer, and autoregressive language-model workloads, with the same mechanisms executing across model families and multi-node deployments.
Significance. If the calibration and decision mechanisms can be shown to be robust and general, the work would be significant for large-scale distributed training by offering a practical, adaptive approach to reducing communication costs without post-hoc accuracy loss. The treatment of reducer admission as a co-design problem rather than an isolated compression operator, along with support for mixed DDP buckets and reducer-side replay measurements, addresses a real systems bottleneck in a way that could influence future runtime designs for billion-parameter models.
major comments (1)
- [Abstract] Abstract: The accuracy-preservation claim rests on the use of calibrated operating profiles combined with online health monitoring and reducer-capacity checks to identify safe low-bit opportunities. However, the manuscript supplies no information on how these profiles are constructed (what statistics, which training phases, tolerance thresholds, or number of runs), how they are validated, or any sensitivity analysis. This leaves the central mechanism for avoiding accuracy collapse unverified and makes it impossible to determine whether the reported preservation of accuracy is robust or dependent on post-hoc fitting to the evaluated settings.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for highlighting the need for greater transparency around the calibration process. The comment identifies a genuine gap in the current manuscript regarding the construction, validation, and sensitivity of operating profiles. We will revise the paper to supply these details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The accuracy-preservation claim rests on the use of calibrated operating profiles combined with online health monitoring and reducer-capacity checks to identify safe low-bit opportunities. However, the manuscript supplies no information on how these profiles are constructed (what statistics, which training phases, tolerance thresholds, or number of runs), how they are validated, or any sensitivity analysis. This leaves the central mechanism for avoiding accuracy collapse unverified and makes it impossible to determine whether the reported preservation of accuracy is robust or dependent on post-hoc fitting to the evaluated settings.
Authors: We agree that the manuscript currently provides insufficient detail on profile construction and validation. In the revised version we will add a new subsection (likely Section 4.2) that specifies: (1) the exact statistics collected during calibration (per-layer gradient norm distributions, variance, and sign-bit error rates), (2) the training phases used (first 5–10 epochs plus periodic re-calibration points), (3) the tolerance thresholds applied to accuracy deviation (e.g., <0.5% top-1 drop relative to FP32 baseline), and (4) the number of independent calibration runs (three per workload). We will also describe the validation procedure (held-out validation sets and cross-model transfer checks) and include a sensitivity analysis varying each threshold by ±20%. These additions will allow readers to assess robustness independently of the specific evaluated settings. revision: yes
Circularity Check
No circularity: system description with no derivation chain or fitted predictions
full rationale
The manuscript is a system paper describing NEURON-Fabric, a profile-guided runtime for deciding low-bit gradient aggregation. No equations, parameters fitted to data subsets, or mathematical derivations are presented whose outputs reduce to their inputs by construction. Claims rest on empirical validation across workloads rather than any self-referential step. The calibration procedure is described at a high level but is not part of a derivation that loops back on itself; any verification gaps are correctness issues, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng
Martin Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. TensorFlow: A System for...
2016
-
[2]
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. 2017. QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding. InAdvances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc., Red Hook, NY, USA, 1709–1720. https://papers.nips.cc/paper/6768-qsgd-communication-efficient- sgd-via-gradient-quant...
2017
-
[3]
Anonymous Author(s). 2026. NEURON-Fabric: Controlled Low-Bit Gradient Aggregation. Prior conference version under submission
2026
-
[4]
Tal Ben-Nun and Torsten Hoefler. 2019. Demystifying Parallel and Distributed Deep Learning: An In-Depth Concur- rency Analysis.Comput. Surveys52, 4, Article 65 (2019), 43 pages. https://doi.org/10.1145/3320060
-
[5]
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Moham- mad Aflah Khan, Shivanshu Purohit, Usvsn Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. 2023. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. InProceedings of the 40th Intern...
2023
-
[6]
Compute Express Link Consortium. 2022. Compute Express Link Specification, Revision 3.0. https:// computeexpresslink.org/resource/cxl-3-0-specification-august-2022-white-paper/
2022
-
[7]
Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. 2015. BinaryConnect: Training Deep Neural Networks with Binary Weights during Propagations. InAdvances in Neural Information Processing Systems, Vol. 28. Curran Associates, Inc., Red Hook, NY, USA, 3123–3131. https://papers.neurips.cc/paper/5647-binaryconnect-training-deep- neural-networks-with-b...
2015
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computa...
-
[9]
Nadeen Gebara, Manya Ghobadi, and Paolo Costa. 2021. In-network Aggregation for Shared Machine Learning Clusters. InProceedings of Machine Learning and Systems, Vol. 3. MLSys, San Jose, CA, USA, 829–844. https://proceedings.mlsys. org/paper_files/paper/2021/hash/5c6614ea3b58bfdc092981678c2c2a88-Abstract.html
2021
-
[10]
Richard L. Graham, Devendar Bureddy, Pak Lui, Hal Rosenstock, Gilad Shainer, Gil Bloch, Dror Goldenerg, Mike Dubman, Sasha Kotchubievsky, Vladimir Koushnir, Lion Levi, Alex Margolin, Tamir Ronen, Alexander Shpiner, Oded Wertheim, and Eitan Zahavi. 2016. Scalable Hierarchical Aggregation Protocol (SHArP): A Hardware Architecture for Efficient Data Reductio...
2016
-
[11]
Shin, Yibo Zhu, Myeongjae Jeon, Junjie Qian, Hongqiang Liu, and Chuanxiong Guo
Juncheng Gu, Mosharaf Chowdhury, Kang G. Shin, Yibo Zhu, Myeongjae Jeon, Junjie Qian, Hongqiang Liu, and Chuanxiong Guo. 2019. Tiresias: A GPU Cluster Manager for Distributed Deep Learning. In16th USENIX Symposium on Networked Systems Design and Implementation. USENIX Association, Boston, MA, USA, 485–500. https://www. usenix.org/conference/nsdi19/presentation/gu
2019
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, Las Vegas, NV, USA, 770–778. https://doi.org/10.1109/CVPR.2016.90
-
[13]
Stich, and Martin Jaggi
Sai Praneeth Karimireddy, Quentin Rebjock, Sebastian U. Stich, and Martin Jaggi. 2019. Error Feedback Fixes SignSGD and Other Gradient Compression Schemes. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97). PMLR, Long Beach, CA, USA, 3252–3261. https://proceedings.mlr. press/v97/kari...
2019
-
[14]
2009.Learning Multiple Layers of Features from Tiny Images
Alex Krizhevsky. 2009.Learning Multiple Layers of Features from Tiny Images. Technical Report. University of Toronto. https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
2009
-
[15]
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. 2017. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization.Journal of Machine Learning Research18, 185 (2017), 1–52. https://www.jmlr.org/papers/v18/16-558.html
2017
-
[16]
Andersen, Jun Woo Park, Alexander J
Mu Li, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J. Shekita, and Bor-Yiing Su. 2014. Scaling Distributed Machine Learning with the Parameter Server. In11th USENIX Symposium on Operating Systems Design and Implementation. USENIX Association, Berkeley, CA, USA, 583–598. 28 Ziqiang Wang, Changcheng H...
2014
-
[17]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala. 2020. PyTorch Distributed: Experiences on Accelerating Data Parallel Training. Proceedings of the VLDB Endowment13, 12 (2020), 3005–3018. https://doi.org/10.14778/3415478.3415530
-
[18]
Yujun Lin, Song Han, Huizi Mao, Yu Wang, and William J. Dally. 2018. Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training. InInternational Conference on Learning Representations. OpenReview.net, Vancouver, BC, Canada, 14 pages. https://openreview.net/forum?id=SkhQHMW0W
2018
-
[19]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2017. Pointer Sentinel Mixture Models. In International Conference on Learning Representations. OpenReview.net, Toulon, France, 10 pages. https://openreview. net/forum?id=Byj72udxe
2017
-
[20]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. 2018. Mixed Precision Training. InInternational Conference on Learning Representations. OpenReview.net, Vancouver, BC, Canada, 11 pages. https://openreview.net/ forum?id=r1gs9JgRZ
2018
-
[21]
E. S. Page. 1954. Continuous Inspection Schemes.Biometrika41, 1–2 (1954), 100–115. https://doi.org/10.1093/biomet/ 41.1-2.100
-
[22]
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. 2013. On the Difficulty of Training Recurrent Neural Networks. InProceedings of the 30th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 28). PMLR, Atlanta, GA, USA, 1310–1318. https://proceedings.mlr.press/v28/pascanu13.html
2013
-
[23]
Yanghua Peng, Yixin Bao, Yangrui Chen, Chuan Wu, and Chuanxiong Guo. 2018. Optimus: An Efficient Dynamic Resource Scheduler for Deep Learning Clusters. InProceedings of the Thirteenth EuroSys Conference. Association for Computing Machinery, New York, NY, USA, 1–14. https://doi.org/10.1145/3190508.3190517
-
[24]
Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, and Chuanxiong Guo. 2019. A Generic Communication Scheduler for Distributed DNN Training Acceleration. InProceedings of the 27th ACM Symposium on Operating Systems Principles. Association for Computing Machinery, New York, NY, USA, 16–29. https://doi.org/10.1145/3341301.3359642
-
[25]
Lutz Prechelt. 1998. Early Stopping—But When? InNeural Networks: Tricks of the Trade. Lecture Notes in Computer Science, Vol. 1524. Springer, Berlin, Heidelberg, 55–69. https://doi.org/10.1007/3-540-49430-8_3
-
[26]
Ganger, and Eric P
Aurick Qiao, Sang Keun Choe, Suhas Jayaram Subramanya, Willie Neiswanger, Qirong Ho, Hao Zhang, Gregory R. Ganger, and Eric P. Xing. 2021. Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning. In 15th USENIX Symposium on Operating Systems Design and Implementation. USENIX Association, Virtual Event, 1–18. https://www.usenix.org/confe...
2021
-
[27]
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. 2016. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. InComputer Vision – ECCV 2016 (Lecture Notes in Computer Science, Vol. 9908). Springer, Cham, Switzerland, 525–542. https://doi.org/10.1007/978-3-319-46493-0_32
-
[28]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. InProceedings of the Workshop on Energy Efficient Machine Learning and Cognitive Computing. NeurIPS Workshop, Vancouver, BC, Canada, 5 pages
2019
-
[29]
Amedeo Sapio, Marco Canini, Chen-Yu Ho, Jacob Nelson, Panos Kalnis, Changhoon Kim, Arvind Krishnamurthy, Masoud Moshref, Dan R. K. Ports, and Peter Richtarik. 2021. Scaling Distributed Machine Learning with In-Network Aggregation. In18th USENIX Symposium on Networked Systems Design and Implementation. USENIX Association, Berkeley, CA, USA, 785–808. https:...
2021
-
[30]
Frank Seide, Hao Fu, Jasha Droppo, Gang Li, and Dong Yu. 2014. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs. InInterspeech. ISCA, Singapore, 1058–1062. https://doi.org/10. 21437/Interspeech.2014-274
2014
-
[31]
Manning, Andrew Y
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng, and Christopher Potts. 2013. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Seattle, WA, USA, 1631–...
2013
-
[32]
Suhas Jayaram Subramanya, Daiyaan Arfeen, Shouxu Lin, Aurick Qiao, Zhihao Jia, and Gregory R. Ganger. 2023. Sia: Heterogeneity-Aware, Goodput-Optimized ML-Cluster Scheduling. InProceedings of the 29th Symposium on Operating Systems Principles. Association for Computing Machinery, New York, NY, USA, 642–657. https://doi.org/10.1145/ 3600006.3613175
arXiv 2023
-
[33]
Thijs Vogels, Sai Praneeth Karimireddy, and Martin Jaggi. 2019. PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization. InAdvances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc., Red Hook, NY, USA, 14236–14245. https://papers.nips.cc/paper/9571-powersgd-practical-low-rank-gradient-compression- for-distri...
2019
-
[34]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. InInternational Conference on Learning Representations. OpenReview.net, New Orleans, LA, USA, 11 pages. https://openreview.net/forum?id=rJ4km2R5t7
2019
-
[35]
Guanhua Wang, Shivaram Venkataraman, Amar Phanishayee, Nikhil Devanur, Jorgen Thelin, and Ion Stoica
-
[36]
InProceedings of Machine Learning and Sys- tems, Vol
Blink: Fast and Generic Collectives for Distributed ML. InProceedings of Machine Learning and Sys- tems, Vol. 2. MLSys, Austin, TX, USA, 172–186. https://proceedings.mlsys.org/paper_files/paper/2020/hash/ cd3a9a55f7f3723133fa4a13628cdf03-Abstract.html
2020
-
[37]
Wei Wen, Cong Xu, Feng Yan, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. 2017. TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning. InAdvances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc., Red Hook, NY, USA, 1509–1519. https://papers.nips.cc/paper/6749-terngrad- ternary-gradients-to-reduce-co...
2017
-
[38]
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. 2018. Gandiva: Introspective Cluster Scheduling for Deep Learning. In13th USENIX Symposium on Operating Systems Design and Implementation. USENIX Association, Carlsbad, CA, USA, 59...
2018
-
[39]
Hao Zhang, Zeyu Zheng, Shizhen Xu, Wei Dai, Qirong Ho, Xiaodan Liang, Zhiting Hu, Jinliang Wei, Pengtao Xie, and Eric P. Xing. 2017. Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters. In2017 USENIX Annual Technical Conference. USENIX Association, Berkeley, CA, USA, 181–193. https://www.usenix.org/conference/at...
2017
-
[40]
Pengfei Zheng, Rui Pan, Tarannum Khan, Shivaram Venkataraman, and Aditya Akella. 2023. Shockwave: Fair and Efficient Cluster Scheduling for Dynamic Adaptation in Machine Learning. In20th USENIX Symposium on Networked Systems Design and Implementation. USENIX Association, Boston, MA, USA, 703–723. https://www.usenix.org/ conference/nsdi23/presentation/zheng
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.