A Bayesian Approach for Nonignorable Dropout in Bivariate Longitudinal Models
Pith reviewed 2026-06-25 20:15 UTC · model grok-4.3
The pith
A Bayesian nonparametric model jointly handles nonignorable dropout for each of two longitudinal outcomes while allowing sensitivity analysis on the missingness assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a flexible nonparametric Bayesian specification for the observed bivariate longitudinal responses, combined with identifying restrictions that condition on the observed dropout indicators and on chosen sensitivity parameters, permits joint modeling of the two dropout processes and supports exploration of nonignorable missingness through alternative priors on the sensitivity parameters.
What carries the argument
Joint Bayesian nonparametric model for the observed data together with identifying restrictions conditional on dropout indicators and sensitivity parameters.
If this is right
- Different dropout times for the two response types can be accommodated without forcing a common dropout process.
- Skewness and point masses in the data are captured without parametric assumptions on the outcome distributions.
- Multiple nonignorable missingness scenarios can be examined by varying the priors placed on the sensitivity parameters.
- The approach supplies cost-effectiveness estimates that incorporate uncertainty arising from the dropout mechanism.
Where Pith is reading between the lines
- The same structure could be used to handle trivariate or higher-dimensional longitudinal outcomes if the identifying restrictions are extended accordingly.
- Policy conclusions drawn from cost-effectiveness trials may shift when the sensitivity parameters are allowed to differ across treatment arms.
- The method suggests a route for sensitivity analysis in other settings where dropout times differ across multiple correlated endpoints.
Load-bearing premise
The distribution of the missing data can be partially identified through restrictions that depend on the dropout indicators and on the chosen values of the sensitivity parameters.
What would settle it
Collect a new trial dataset in which all participants complete every scheduled assessment and then compare the model's posterior predictions for the would-be missing values (under each prior on the sensitivity parameters) against the actually observed values.
Figures
read the original abstract
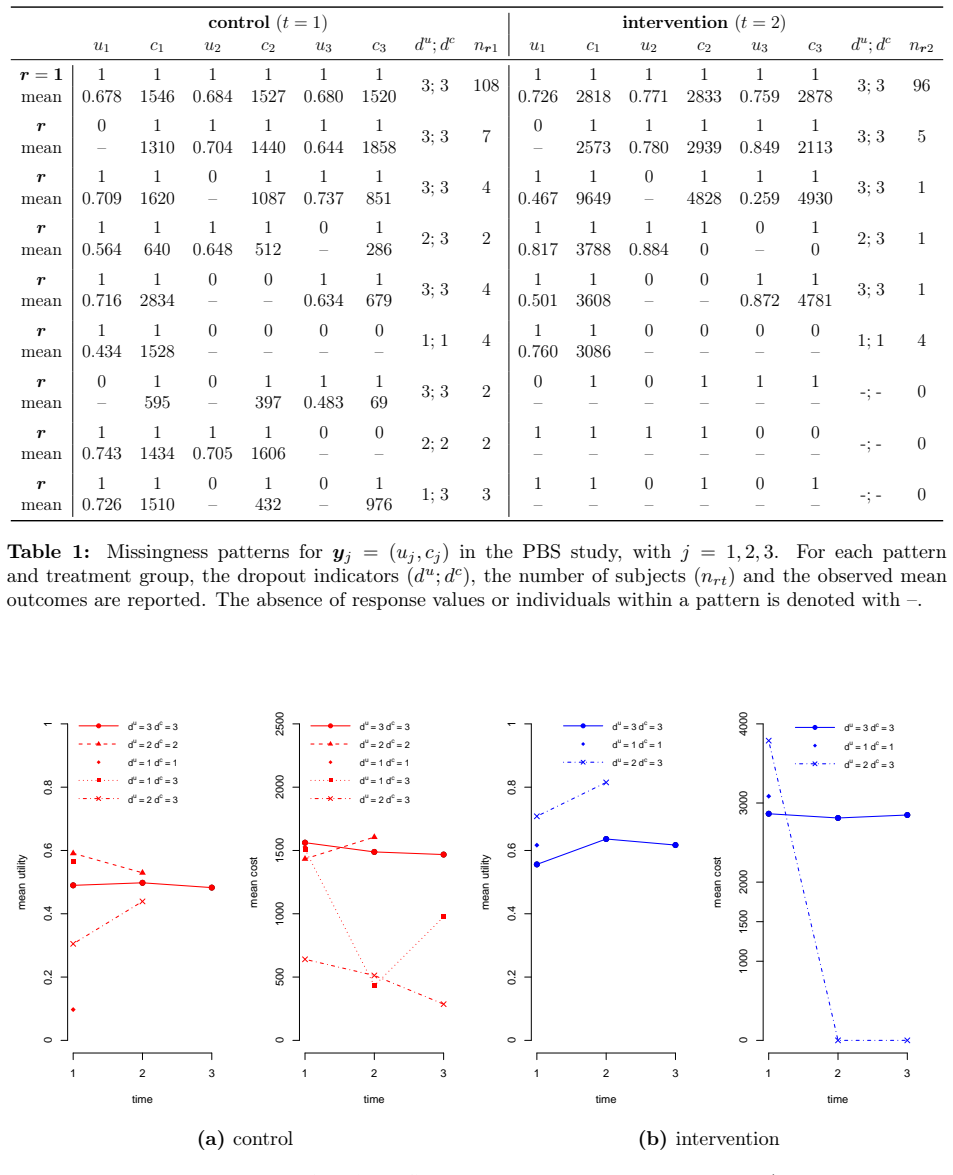
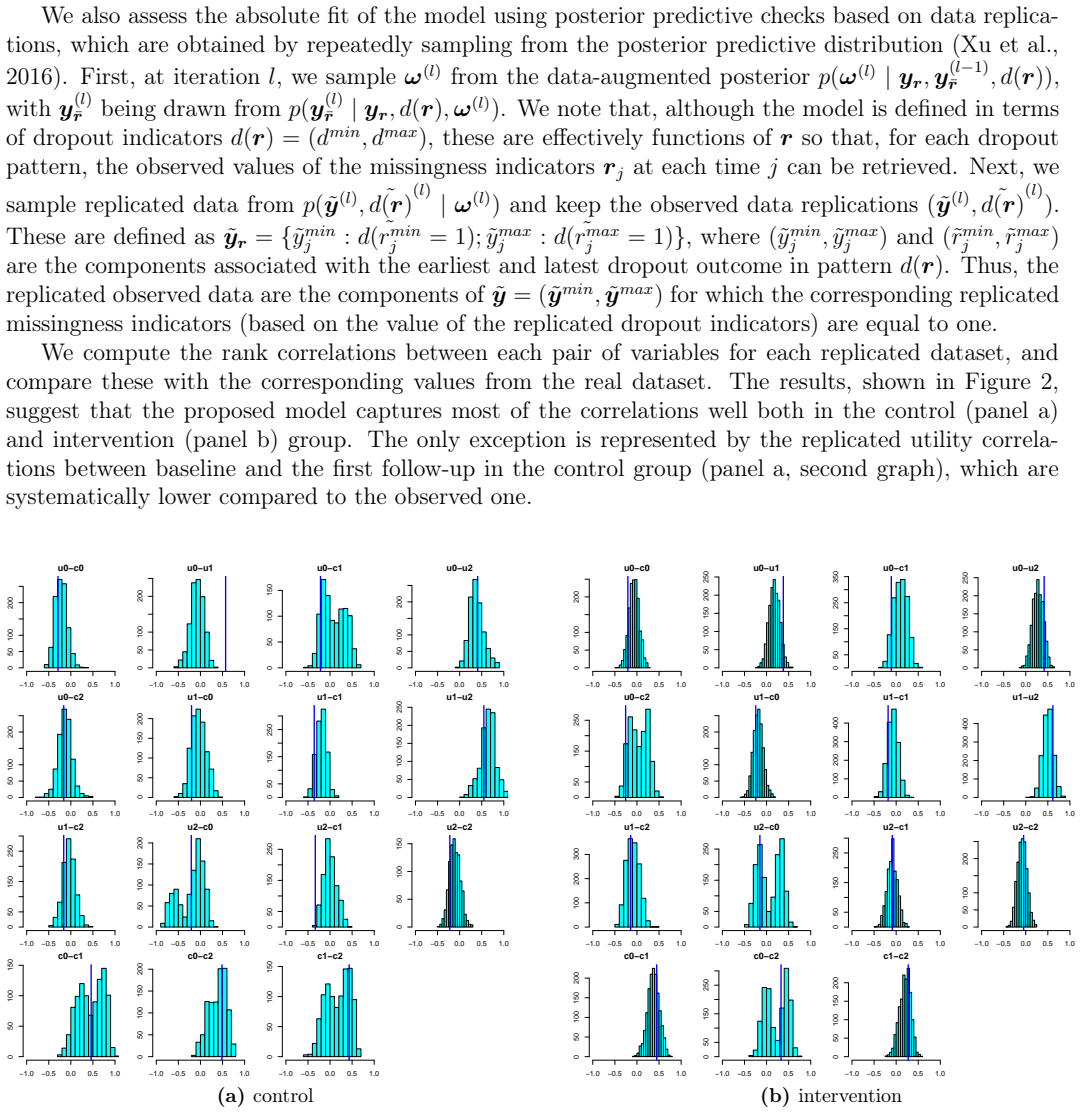
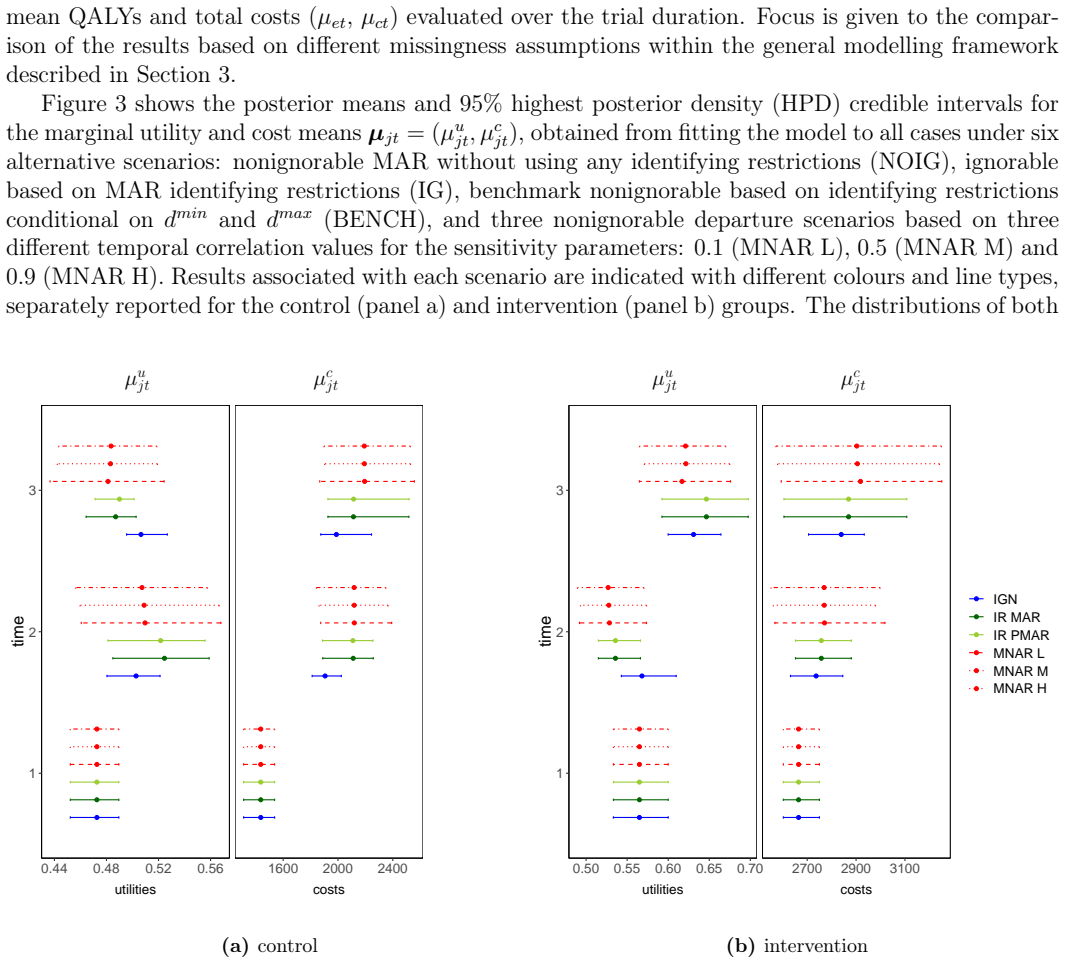
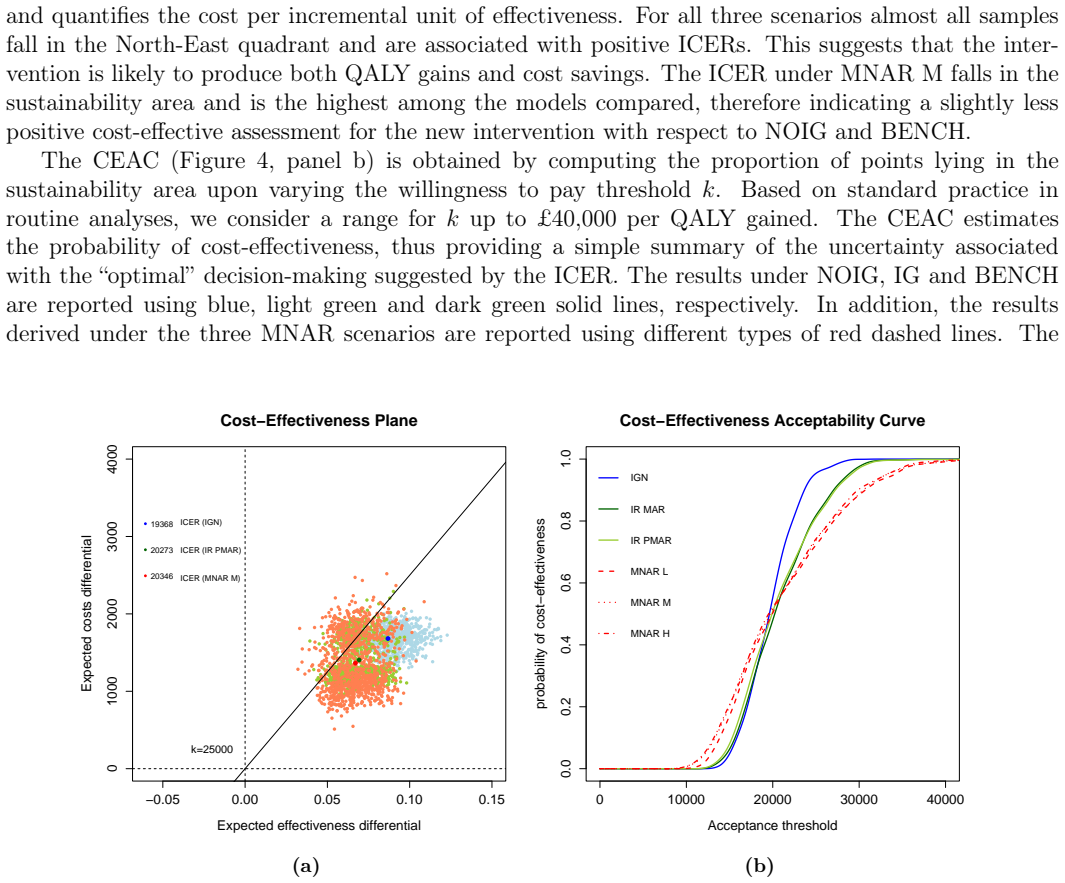
Longitudinal data collected in clinical trials are almost always incomplete due to some of the participants dropping out from the study during the planned follow-up. A common strategy to handle nonresponse expresses missingness in terms of a dropout process, which is jointly analysed with the outcome process to facilitate the formulation of the missingness assumptions. However, when the outcome is multivariate, the identification of the dropout process becomes problematic, especially when individuals have different dropout times for each type of response, and sensitivity analysis is difficult. The modelling task may be also be complicated by data complexities (e.g. skewness and spikes) which are difficult to capture through standard parametric methods. An example of this analysis framework occurs in trial-based economic evaluations, where a longitudinal bivariate response, formed by suitably-defined measures of effectiveness and costs, is analysed to inform policymakers about the cost-effectiveness of alternative interventions. We present a novel Bayesian nonparametric approach to handle a missing bivariate longitudinal outcome by jointly modelling the dropout process associated with each type of response while also taking into account the complexities of the data. We specify a flexible nonparametric model for the observed data and partially identify the distribution of the missing data with identifying restrictions conditional on the dropout indicators and sensitivity parameters. We explore alternative nonignorable scenarios through different priors for the sensitivity parameters. Our approach is motivated by, and applied to, data from a trial assessing the cost-effectiveness of a new treatment for intellectual disability and challenging behaviour.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Bayesian nonparametric approach to handle nonignorable dropout in bivariate longitudinal data (e.g., effectiveness and cost measures in clinical trials). It jointly models the two dropout processes, specifies a flexible nonparametric model for the observed data, and partially identifies the missing data distribution using identifying restrictions that condition on the dropout indicators and sensitivity parameters, with alternative nonignorable scenarios explored via priors on those parameters. The method is motivated by and applied to trial data on treatment for intellectual disability and challenging behaviour.
Significance. If the partial identification strategy is valid, the work provides a flexible, nonparametric framework for sensitivity analysis under nonignorable missingness in bivariate longitudinal settings with possibly differing dropout times per response. This addresses a practical gap in trial-based economic evaluations where standard parametric models struggle with skewness, spikes, and multivariate dropout, potentially leading to more robust cost-effectiveness inferences.
major comments (2)
- [Abstract / identifying restrictions] Abstract and modeling section on identifying restrictions: the claim that the distribution of the missing bivariate outcomes is partially identified via restrictions conditional on the two dropout indicators and sensitivity parameters does not address the case (explicitly noted in the abstract) where individuals drop out at different times for each response. When dropout times differ, the required conditional distribution of the unobserved outcomes given observed history and the pair of dropout indicators may involve cross-response dependence not captured by the nonparametric model fitted only to observed data; varying priors on the sensitivity parameters would then fail to correctly bound bias in the cost-effectiveness parameters.
- [Joint dropout model] Section describing the joint dropout model: no derivation or explicit factorization is provided showing how the bivariate dropout process is specified when the two responses have misaligned observation times, which is load-bearing for the claim that the approach jointly models both dropout processes while remaining computationally tractable.
minor comments (2)
- [Abstract] Abstract contains a repeated word: 'The modelling task may be also be complicated'.
- [Notation] Notation for the sensitivity parameters and the nonparametric components should be introduced with explicit definitions and distinguished from standard MNAR parameters in the literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of our approach to nonignorable dropout in bivariate longitudinal settings. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract / identifying restrictions] Abstract and modeling section on identifying restrictions: the claim that the distribution of the missing bivariate outcomes is partially identified via restrictions conditional on the two dropout indicators and sensitivity parameters does not address the case (explicitly noted in the abstract) where individuals drop out at different times for each response. When dropout times differ, the required conditional distribution of the unobserved outcomes given observed history and the pair of dropout indicators may involve cross-response dependence not captured by the nonparametric model fitted only to observed data; varying priors on the sensitivity parameters would then fail to correctly bound bias in the cost-effectiveness parameters.
Authors: We appreciate the referee's point on the challenges posed by misaligned dropout times. Our nonparametric model for the observed data is specified jointly across both responses, capturing dependence up to the last observed time for each. The identifying restrictions are formulated conditionally on the pair of dropout indicators to permit the sensitivity parameters to encode cross-response associations in the unobserved data. That said, we acknowledge that the original manuscript did not provide a sufficiently explicit derivation showing how this conditional distribution preserves or bounds the relevant dependence when observation times differ. We will revise the modeling section to include this derivation and clarify how the sensitivity analysis correctly informs bounds on bias for the cost-effectiveness parameters. revision: yes
-
Referee: [Joint dropout model] Section describing the joint dropout model: no derivation or explicit factorization is provided showing how the bivariate dropout process is specified when the two responses have misaligned observation times, which is load-bearing for the claim that the approach jointly models both dropout processes while remaining computationally tractable.
Authors: We agree that an explicit factorization of the bivariate dropout process under misaligned observation times is necessary to substantiate the claim of joint modeling and computational tractability. Although the model construction relies on a joint specification that factors through the observed data likelihood and appropriate priors for the dropout indicators, the manuscript did not include the full derivation. In the revision we will add this factorization, along with details on how the joint process is implemented in the MCMC algorithm to maintain tractability. revision: yes
Circularity Check
No circularity: nonparametric observed-data model and sensitivity-parameter restrictions are introduced as independent modeling choices
full rationale
The paper defines a joint nonparametric model on the observed bivariate longitudinal data and then applies standard partial-identification restrictions that condition on the observed dropout indicators plus user-specified sensitivity parameters. No equation reduces a target quantity to a fitted parameter by construction, no prediction is obtained by refitting a subset of the same data, and no load-bearing premise rests on a self-citation whose content is itself unverified. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- sensitivity parameters
axioms (1)
- domain assumption Identifying restrictions conditional on the dropout indicators and sensitivity parameters suffice to partially identify the missing data distribution
Reference graph
Works this paper leans on
-
[1]
2014 , publisher=
Economic evaluation in clinical trials , author=. 2014 , publisher=
2014
-
[2]
R package version , volume=
RStan: the R interface to Stan , author=. R package version , volume=
-
[3]
Applied Mathematics Letters , volume=
A topological proof of Sklar’s theorem , author=. Applied Mathematics Letters , volume=. 2013 , publisher=
2013
-
[4]
Journal of Machine Learning Research , volume=
Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory , author=. Journal of Machine Learning Research , volume=
-
[5]
Statistics and computing , volume=
Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC , author=. Statistics and computing , volume=. 2017 , publisher=
2017
-
[6]
Journal of the royal statistical society: Series b (statistical methodology) , volume=
Bayesian measures of model complexity and fit , author=. Journal of the royal statistical society: Series b (statistical methodology) , volume=. 2002 , publisher=
2002
-
[7]
Statistics and computing , volume=
Understanding predictive information criteria for Bayesian models , author=. Statistics and computing , volume=. 2014 , publisher=
2014
-
[8]
Statistical Analysis with Missing Data, Second Edition , publisher=
Little. Statistical Analysis with Missing Data, Second Edition , publisher=. 2002 , address=
2002
-
[9]
Statistica Sinica , pages=
Modeling covariance matrices in terms of standard deviations and correlations, with application to shrinkage , author=. Statistica Sinica , pages=. 2000 , publisher=
2000
-
[10]
The Analysis of Longitudinal Ordinal Data with Non-random Drop-Out , journal=
Molenberghs, G and Kenward, M and Lesaffre, E , year=. The Analysis of Longitudinal Ordinal Data with Non-random Drop-Out , journal=
-
[11]
Statistics in Medicine , volume=
Baio. Statistics in Medicine , volume=. 2014 , title=
2014
-
[12]
and Stevens, JW
O'Hagan, A. and Stevens, JW. , year=. A Framework for Cost-Effectiveness Analysis from Clinical Trial Data , journal=
-
[13]
and Radice, R
Gomes, M. and Radice, R. and Camarena Brenes, J. and Marra, G. , year=. Copula selection models for non‐Gaussian outcomes that are missing not at random , journal=
-
[14]
Biometrics , volume=
Reparameterizing the pattern mixture model for sensitivity analyses under informative dropout , author=. Biometrics , volume=. 2000 , publisher=
2000
-
[15]
2008 , publisher=
Missing data in longitudinal studies: Strategies for Bayesian modeling and sensitivity analysis , author=. 2008 , publisher=
2008
-
[16]
Journal of the American Statistical Association , volume=
Bayesian methods for nonignorable dropout in joint models in smoking cessation studies , author=. Journal of the American Statistical Association , volume=. 2016 , publisher=
2016
-
[17]
Journal of the American Statistical Association , volume=
A flexible Bayesian approach to monotone missing data in longitudinal studies with nonignorable missingness with application to an acute schizophrenia clinical trial , author=. Journal of the American Statistical Association , volume=. 2015 , publisher=
2015
-
[18]
Statistical Science , volume=
Bayesian approaches for missing not at random outcome data: The role of identifying restrictions , author=. Statistical Science , volume=. 2018 , publisher=
2018
-
[19]
Biometrics , volume=
A note on MAR, identifying restrictions, model comparison, and sensitivity analysis in pattern mixture models with and without covariates for incomplete data , author=. Biometrics , volume=. 2011 , publisher=
2011
-
[20]
Journal of statistical software , volume=
Stan: A probabilistic programming language , author=. Journal of statistical software , volume=. 2017 , publisher=
2017
-
[21]
Statistics in medicine , volume=
A note on posterior predictive checks to assess model fit for incomplete data , author=. Statistics in medicine , volume=. 2016 , publisher=
2016
-
[22]
Biometrika , volume=
Joint mean-covariance models with applications to longitudinal data: Unconstrained parameterisation , author=. Biometrika , volume=. 1999 , publisher=
1999
-
[23]
Biometrika , volume=
Bayesian analysis of covariance matrices and dynamic models for longitudinal data , author=. Biometrika , volume=. 2002 , publisher=
2002
-
[24]
Advances in Neural Information Processing Systems , pages=
The infinite Gaussian mixture model , author=. Advances in Neural Information Processing Systems , pages=. 2000 , publisher=
2000
-
[25]
2008 , publisher=
Bayesian nonparametric analysis of conditional distributions and inference for Poisson point processes , author=. 2008 , publisher=
2008
-
[26]
Journal of the american statistical association , volume=
Bayesian density estimation and inference using mixtures , author=. Journal of the american statistical association , volume=. 1995 , publisher=
1995
-
[27]
Journal of the american statistical association , volume=
Bayes factors , author=. Journal of the american statistical association , volume=. 1995 , publisher=
1995
-
[28]
Journal of the American Statistical Association , volume=
Markov chain Monte Carlo methods for computing Bayes factors: A comparative review , author=. Journal of the American Statistical Association , volume=. 2001 , publisher=
2001
-
[29]
Journal of the American Statistical Association , volume=
A predictive approach to model selection , author=. Journal of the American Statistical Association , volume=. 1979 , publisher=
1979
-
[30]
2012 , publisher=
Monte Carlo methods in Bayesian computation , author=. 2012 , publisher=
2012
-
[31]
Journal of Machine Learning Research , volume=
A widely applicable Bayesian information criterion , author=. Journal of Machine Learning Research , volume=
-
[32]
Journal of the American statistical Association , volume=
The calculation of posterior distributions by data augmentation , author=. Journal of the American statistical Association , volume=. 1987 , publisher=
1987
-
[33]
Journal of the American statistical Association , volume=
A Monte Carlo implementation of the EM algorithm and the poor man's data augmentation algorithms , author=. Journal of the American statistical Association , volume=. 1990 , publisher=
1990
-
[34]
Biometrika , volume=
A multiple-imputation Metropolis version of the EM algorithm , author=. Biometrika , volume=. 2003 , publisher=
2003
-
[35]
JAWRA Journal of the American Water Resources Association , volume=
SOME SIMPLE MODELS FOR CONTINUOUS VARIATE TIME SERIES 1 , author=. JAWRA Journal of the American Water Resources Association , volume=. 1985 , publisher=
1985
-
[36]
and Webster, R
Bailey, JV. and Webster, R. and Hunter, R. and Griffin, M. and Freemantle N. and Rait, G. and Estcourt, C. and Michie, S. and Anderson, J. and Stephenson, J. and Gerressu, M. and Sinag Ang, C. and Murray, E. , year=. The Men's Safer Sex project: intervention development and feasibility randomised controlled trial of an interactive digital intervention to ...
-
[37]
arXiv preprint arXiv:2002.04706 , year=
Bayesian Nonparametric Cost-Effectiveness Analyses: Causal Estimation and Adaptive Subgroup Discovery , author=. arXiv preprint arXiv:2002.04706 , year=
arXiv 2002
-
[38]
Statistics in medicine , volume=
Bayesian models for cost-effectiveness analysis in the presence of structural zero costs , author=. Statistics in medicine , volume=. 2014 , publisher=
2014
-
[39]
and Hawkins, N
Manca, A. and Hawkins, N. and Sculpher, MJ. , year=. Estimating mean QALYs in trial-based cost-effectiveness analysis: the importance of controlling for baseline utility , journal=
-
[40]
and Nixon, RM
Thompson, SG. and Nixon, RM. , year=. How Sensitive Are Cost-Effectiveness Analyses to Choice of Parametric Distributions? , journal=
-
[41]
and Dawid, AP
Baio, G. and Dawid, AP. , year=. Probabilistic sensitivity analysis in health economics , journal=
-
[42]
and Sculpher, M
Claxton, K. and Sculpher, M. and McCabe, C. and Briggs, A. and Hakehurst, R. and Buxton, M. and Brazier, J. and O'Hagan, T. , year=. Probabilistic sensitivity analysis for NICE technology assessment: not an optional extra , journal=
-
[43]
and van Mastrigt, GAPG
van Asselt, ADI. and van Mastrigt, GAPG. and Dirksen, CD. and Arntz, A. and Severens, JL. and Kessels, AGH. , year=. How to Deal with Cost Differences at Baseline , journal=
-
[44]
Briggs, A. , year=. A Bayesian approach to stochastic cost-effectiveness analysis , journal=
-
[45]
and Mullahy, J
Stinnett, AA. and Mullahy, J. , year=. A New Framework for the Analysis of Uncertainty in Cost-Effectiveness Analysis , journal=
-
[46]
and Martin, S
Claxton, K. and Martin, S. and Soares, M. and Rice, N. and Spackman, E. and Hinde, S. and Devlin, N. and Smith, PC. and Sculpher, M. , year=. Methods for the estimation of the National Institute for Health and Care Excellence cost-effectiveness threshold , journal=
-
[47]
and Al, MJ
van Hout, BA. and Al, MJ. and Gordon, GS. and Rutten, FFH. and Kuntz, KM. , year=. Costs, Effects and C/E-Ratios Alongside a Clinical Trial , journal=
-
[48]
2013 , address=
NICE , title=. 2013 , address=
2013
-
[49]
and Schulpher, MJ
Drummond, MF. and Schulpher, MJ. and Claxton, K. and Stoddart, GL. and Torrance, GW. , title=. 2005 , address=
2005
-
[50]
and Assmann, SE
Pocock, SJ. and Assmann, SE. and Enos, LE. and Kasten, LE. , year=. Subgroup analysis, covariate adjustment and baseline comparisons in clinical trial reporting: current practice and problems , journal=
-
[51]
and Shah, KK
Devlin, NJ. and Shah, KK. and Feng, Y. and Mulhern, B. and van Hout, B. , year=. Valuing health‐related quality of life: An EQ‐5D‐5L value set for England , journal=
-
[52]
and Neuhauser, M
Puth, MT. and Neuhauser, M. and Ruxton, GD. , year=. On the variety of methods for calculating confidence intervals by bootstrapping , journal=
-
[53]
Hesterberg, TC. , year=. What Teachers Should Know About the Bootstrap: Resampling in the Undergraduate Statistics Curriculum , journal=
-
[54]
Sensitivity Analysis for Not-at-Random Missing Data in Trial-Based Cost-Effectiveness Analysis: A Tutorial , journal=
Leurent, B and Gomes, M and Faria, R and Morris, S and Grieve, R and Carpenter, JR , year=. Sensitivity Analysis for Not-at-Random Missing Data in Trial-Based Cost-Effectiveness Analysis: A Tutorial , journal=
-
[55]
Gabrio, A and Mason, AJ and Baio, G , year=. A full. Statistics in Medicine , volume=
-
[56]
Handling missing values in cost effectiveness analyses that use data from cluster randomized trials , journal=
Diaz-Ordaz, K and Kenward, MG and Grieve, R , year=. Handling missing values in cost effectiveness analyses that use data from cluster randomized trials , journal=
-
[57]
A Framework for Cost-Effectiveness Analysis from Clinical Trial Data , journal=
O'Hagan, A and Stevens, JW , year=. A Framework for Cost-Effectiveness Analysis from Clinical Trial Data , journal=
-
[58]
Regression Estimators for Generic Health-Related Quality of Life and Quality-Adjusted Life Years , journal=
Basu, A and Manca, A , year=. Regression Estimators for Generic Health-Related Quality of Life and Quality-Adjusted Life Years , journal=
-
[59]
Efron, B. , year=. Nonparametric standard errors and confidence intervals , journal=
-
[60]
Methods for incorporating covariate adjustment, subgroup analysis and between-centre differences into cost-effectiveness evaluations , journal=
Nixon, RM and Thompson, SG , year=. Methods for incorporating covariate adjustment, subgroup analysis and between-centre differences into cost-effectiveness evaluations , journal=
-
[61]
and Wonderling, DE
Briggs, AH. and Wonderling, DE. and Mooney, CZ. , year=. Pulling cost-effectiveness analysis up by its bootstraps: a non-parametric approach to confidence interval estimation , journal=
-
[62]
and Heumann, C
Schomaker, M. and Heumann, C. , year=. Bootstrap inference when using multiple imputation , journal=
-
[63]
and van Buuren, S
Brand, J. and van Buuren, S. and le Cessie, S. and van den Hout, W. , year=. Combining multiple imputation and bootstrap in the analysis of cost-effectiveness trial data , journal=
-
[64]
Gelman, A. , year=. Prior distributions for variance parameters in hierarchical models , journal=
-
[65]
and Gray, AM
Briggs, AH. and Gray, AM. , year=. Handling uncertainty when performing economic evaluation of healthcare interventions , journal=
-
[66]
and Grieve, R
Gomes, R. and Grieve, R. and Nixon, R. and NG, ESW. and Carpenter, J. and Thompson, SG. , year=. METHODS FOR COVARIATE ADJUSTMENT IN COST-EFFECTIVENESS ANALYSIS THAT USE CLUSTER RANDOMISED TRIALS , journal=
-
[67]
and Ng, ESW
Gomes, R. and Ng, ESW. and Grieve, R. and Nixon, R. and NG, ESW. and Carpenter, J. and Thompson, SG. , year=. Developing Appropriate Methods for Cost-Effectiveness Analysis of Cluster Randomized Trials , journal=
-
[68]
and Grieve, R
Gomes, R. and Grieve, R. and Nixon, R. and Edmunds, WJ. , year=. Statistical Methods for Cost-Effectiveness Analyses That Use Data from Cluster Randomized Trials , journal=
-
[69]
and Nixon, R
Grieve, R. and Nixon, R. and Thompson, SG. and Normand, C. , year=. Using multilevel models for assessing the variability of multinational resource use and cost data , journal=
-
[70]
and Nixon, R
Grieve, R. and Nixon, R. and Simon, G. and Thompson, SG. , year=. Bayesian Hierarchical Models for Cost-Effectiveness Analyses that Use Data from Cluster Randomized Trials , journal=
-
[71]
and Briggs, AH
Willan, AR. and Briggs, AH. and Hock, JS. , year=. Regression methods for covariate adjustment and subgroup analysis for non-censored cost-effectiveness data , journal=
-
[72]
Senn, SJ. , year=. Covariate Imbalance and Random Allocation in Clinical Trials , journal=
-
[73]
and Schulz, KF
Moher, D. and Schulz, KF. and Altman, DG. , year=. The CONSORT statement: revised recommendations for improving the quality of reports of parallel-group randomised trials , journal=
-
[74]
Missing data in trial-based cost-effectiveness analysis: the current state of play , journal=
Noble, SM and Hollingworth, W and Tilling, K , year=. Missing data in trial-based cost-effectiveness analysis: the current state of play , journal=
-
[75]
Missing data in trial-based cost-effectiveness analysis: An incomplete journey , journal=
Leurent, B and Gomes, M and Carpenter, JR , year=. Missing data in trial-based cost-effectiveness analysis: An incomplete journey , journal=
-
[76]
Journal of the Royal Statistical Society: Series A (Statistics in Society) , volume=
A Bayesian parametric approach to handle missing longitudinal outcome data in trial-based health economic evaluations , author=. Journal of the Royal Statistical Society: Series A (Statistics in Society) , volume=. 2020 , publisher=
2020
-
[77]
Handling Missing Data in Within-Trial Cost-Effectiveness Analysis: A Review with Future Recommendations , journal=
Gabrio, A and Mason, AJ and Baio, G , year=. Handling Missing Data in Within-Trial Cost-Effectiveness Analysis: A Review with Future Recommendations , journal=
-
[78]
and Briggs, AH
Hoch, JS. and Briggs, AH. and Willan, AR. , year=. Something old, something new, something borrowed, something blue: a framework for the marriage of health econometrics and cost-effectiveness analysis , journal=
-
[79]
and Hernandez, MAN
Vazquez Polo, FJ. and Hernandez, MAN. and Lopez-Valcarcel, BG. , year=. Using covariates to reduce uncertainty in the economic evaluation of clinical trial data , journal=
-
[80]
and O'Hagan, A
Stevens, JW. and O'Hagan, A. and Miller, P. , year=. Case study in the Bayesian analysis of a cost-effectiveness trial in the evaluation of health care technologies: Depression , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.