Latency Prediction for LLM Inference on NPU Systems
Pith reviewed 2026-06-26 22:39 UTC · model grok-4.3
The pith
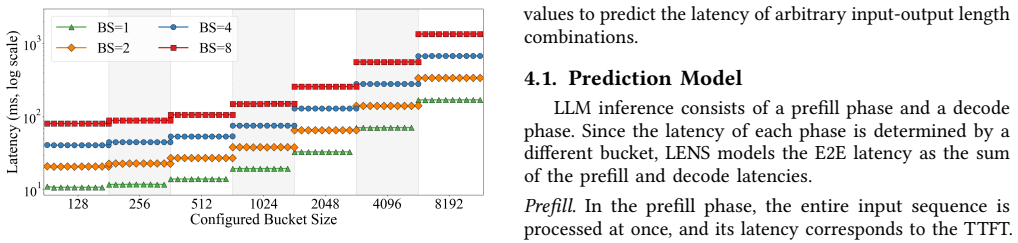
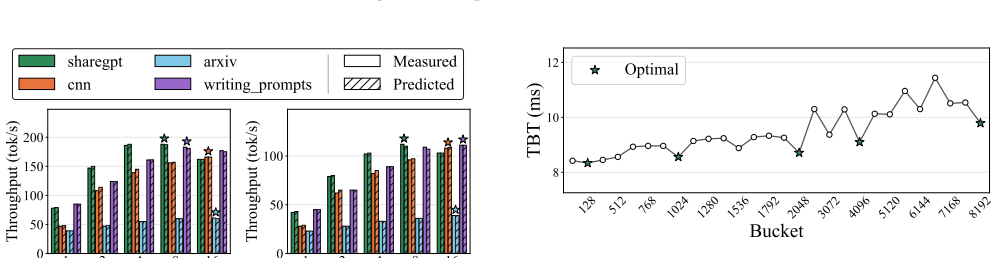
LENS predicts NPU inference latency from two end-to-end measurements per bucket.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
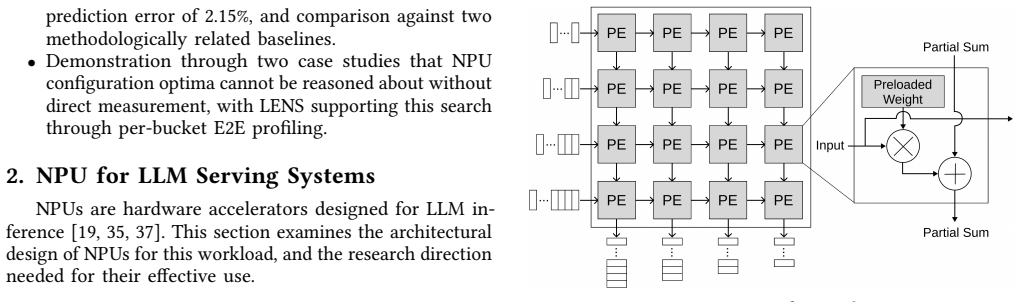
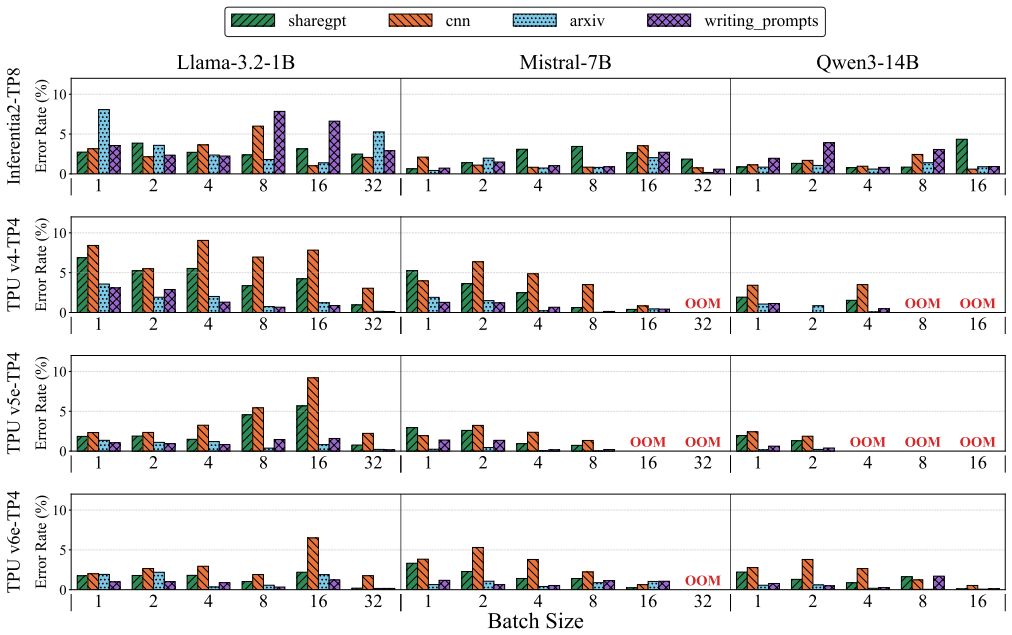
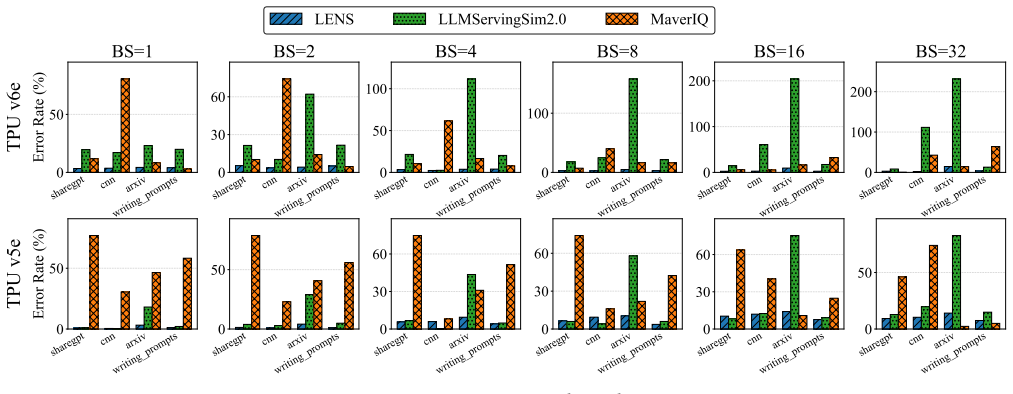
LENS is a latency estimator that predicts NPU inference latency without information on the microarchitecture or compiler, and captures the non-linear latency induced by bucketing. LENS profiles each bucket with two end-to-end measurements and composes the results to predict latency for arbitrary input-output length combinations, achieving a mean prediction error of 2.15 percent across NPUs from multiple vendors, several LLMs, and diverse workloads.
What carries the argument
The LENS estimator, which profiles each bucket with two end-to-end measurements and composes those results for any input-output length pair.
If this is right
- Designers can explore large spaces of parallelization strategies, batching techniques, and scheduling policies without exhaustive measurements.
- The same two-measurement approach applies across NPUs from different vendors and multiple LLMs.
- Non-linear bucketing effects are captured without separate modeling of each internal optimization.
- Prediction remains usable for diverse workloads once the per-bucket profiles are collected.
Where Pith is reading between the lines
- The composition technique could extend to other hidden-hardware accelerators where only end-to-end runs are observable.
- Embedding LENS inside an auto-tuning loop would cut the number of trial runs needed to select batch and parallel settings.
- The method might be adapted to forecast energy use or throughput by collecting the same two measurements under power or rate metrics.
Load-bearing premise
Latency for arbitrary input-output length combinations can be accurately composed from only two end-to-end measurements per bucket despite unknown microarchitecture, compiler optimizations, and bucketing effects.
What would settle it
Run a new input-output length combination on one of the tested NPUs, compute the LENS prediction from its two-measurement profiles, and check whether the absolute error exceeds a few percent on average.
Figures

read the original abstract
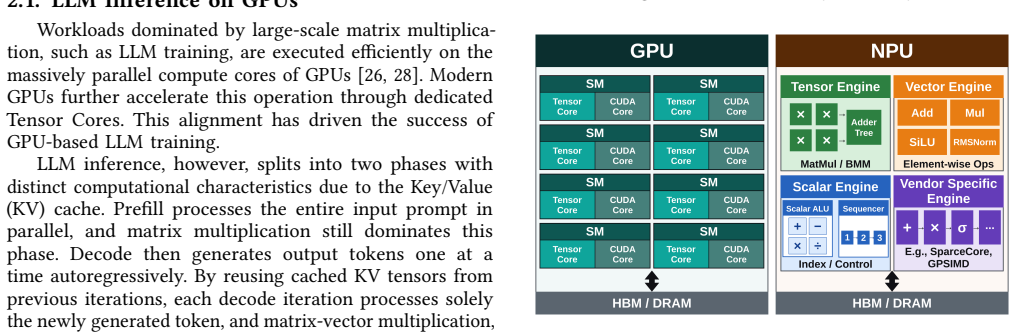
Deploying Large Language Models (LLMs) requires exploring a large configuration space spanning parallelization strategies, batching techniques, and scheduling policies. Exhaustive measurement across this space is impractical, making latency prediction essential for system optimization. While NPUs have emerged as accelerators designed for LLM inference, no prediction methodology has been established for them. Specifically, applying prior work to LLM inference latency prediction on NPUs faces three challenges: undisclosed microarchitecture of commercial NPUs, unpredictable compiler optimizations, and latency non-linearity induced by bucketing. We present LENS, a latency estimator that predicts NPU inference latency without information on the microarchitecture or compiler, and captures the non-linear latency induced by bucketing. LENS profiles each bucket with two end-to-end (E2E) measurements and composes the results to predict latency for arbitrary input-output length combinations. We validate LENS across NPUs from multiple vendors, several LLMs, and diverse workloads, achieving a mean prediction error of 2.15\%. We further compare LENS against two methodologically related baselines, confirming the validity of its approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LENS, a latency prediction method for LLM inference on NPUs. It profiles each bucket using two end-to-end measurements and composes the results to estimate latency for arbitrary input-output length combinations, without requiring microarchitecture or compiler details. The approach is validated across multiple NPUs, LLMs, and workloads, reporting a mean prediction error of 2.15% and outperforming two related baselines.
Significance. If the composition rule is shown to be robust, the result would be significant for practical LLM system optimization on NPUs, as it reduces exhaustive measurement needs while addressing undisclosed hardware and bucketing non-linearities through a purely measurement-driven method that avoids parameter fitting or internal model assumptions.
major comments (2)
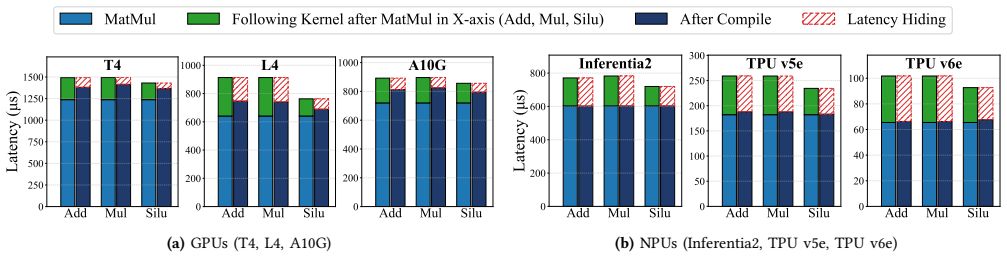
- [Abstract] Abstract and method description: the central claim that latency for arbitrary I/O pairs inside a bucket can be obtained by composing two profiled E2E runs rests on an unstated functional form. No derivation or ablation demonstrates that two samples suffice when bucketing may interact with attention tiling, KV-cache allocation, or compiler fusion to produce higher-order non-linearities.
- [Validation] Validation section: the reported 2.15% mean error is presented without error bars, the number of held-out test points per bucket, or residual plots versus number of profiling samples, so it is impossible to verify whether the two-measurement composition generalizes or merely interpolates the profiled points.
minor comments (2)
- [Method] Notation for the composition operator is introduced without an explicit equation or pseudocode, making the exact arithmetic of the two-measurement rule difficult to reproduce.
- [Evaluation] Table captions for baseline comparisons do not state whether the same two-measurement budget was enforced on the baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying the methodological assumptions and strengthening the empirical validation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim that latency for arbitrary I/O pairs inside a bucket can be obtained by composing two profiled E2E runs rests on an unstated functional form. No derivation or ablation demonstrates that two samples suffice when bucketing may interact with attention tiling, KV-cache allocation, or compiler fusion to produce higher-order non-linearities.
Authors: The composition rule in LENS is an empirical measurement-driven procedure that profiles the bucket boundaries with two E2E runs to capture the dominant non-linear step induced by bucketing, then applies a piecewise composition for interior points. Because commercial NPU microarchitectures and compilers are undisclosed, a first-principles derivation is not feasible; instead, the approach relies on the observation that bucketing non-linearities dominate over higher-order effects in practice. Our multi-vendor, multi-model validation (mean error 2.15 %) provides empirical support that two samples suffice for the workloads examined. We will add an explicit description of the composition function together with an ablation on the number of profiling samples per bucket. revision: partial
-
Referee: [Validation] Validation section: the reported 2.15% mean error is presented without error bars, the number of held-out test points per bucket, or residual plots versus number of profiling samples, so it is impossible to verify whether the two-measurement composition generalizes or merely interpolates the profiled points.
Authors: We agree that the current presentation lacks the statistical detail needed to assess generalization. In the revised manuscript we will report the number of held-out points per bucket, include error bars on all mean-error figures, and add residual plots against both sequence length and number of profiling samples to demonstrate that the two-measurement rule generalizes rather than merely interpolates. revision: yes
Circularity Check
No significant circularity; method is measurement-driven
full rationale
The paper's central claim rests on profiling each bucket with two E2E measurements followed by an explicit composition step to obtain predictions for arbitrary lengths. No equations are shown that define the target latency in terms of fitted parameters by construction, no self-citations bear the load of the composition rule, and no ansatz or uniqueness theorem is imported from prior author work. Validation against external workloads and baselines is presented as independent evidence, so the derivation chain does not reduce to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latency for arbitrary input-output lengths can be composed from two profiled E2E measurements per bucket
Reference graph
Works this paper leans on
-
[1]
ShareGPT_Vicuna_unfiltered,
“ShareGPT_Vicuna_unfiltered, ” https://huggingface.co/datasets/ anon8231489123/ShareGPT_Vicuna_unfiltered, 2023, filtered and cleaned version of the ShareGPT dataset originally collected by RyokoAI
2023
-
[2]
Vidur: A large-scale simulation framework for llm inference,
A. Agrawal, N. Kedia, J. Mohan, A. Panwar, N. Kwatra, B. S. Gulavani, R. Ramjee, and A. Tumanov, “Vidur: A large-scale simulation framework for llm inference, ” inProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. D. Sa, Eds., vol. 6, 2024, pp. 351–366. [Online]. Available: https://proceedings.mlsys.org/paper_files/paper/2024/f...
2024
-
[3]
Taming throughput-latency tradeoff in llm inference with sarathi-serve,
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, A. Tumanov, and R. Ramjee, “Taming throughput-latency tradeoff in llm inference with sarathi-serve, ” inProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation, ser. OSDI’24. USA: USENIX Association, 2024
2024
-
[4]
AWS Inferentia2 architecture,
Amazon Web Services, “AWS Inferentia2 architecture, ” https://awsdocs-neuron.readthedocs-hosted.com/en/latest/general/ arch/neuron-hardware/inferentia2.html, 2024, accessed: 2026-05-15
2024
-
[5]
Expanding our use of Google Cloud TPUs and services,
Anthropic, “Expanding our use of Google Cloud TPUs and services, ” 2025, accessed: 2026-05-
2025
-
[6]
Available: https://www.anthropic.com/news/ expanding-our-use-of-google-cloud-tpus-and-services
[Online]. Available: https://www.anthropic.com/news/ expanding-our-use-of-google-cloud-tpus-and-services
-
[7]
Powering the next generation of AI development with AWS,
——, “Powering the next generation of AI development with AWS, ” 2025, accessed: 2026-05-15. [Online]. Available: https: //www.anthropic.com/news/anthropic-amazon-trainium
2025
-
[8]
Llmservingsim 2.0: A unified simulator for heterogeneous and disaggregated llm serving infrastructure,
J. Cho, H. Choi, G. Heo, and J. Park, “Llmservingsim 2.0: A unified simulator for heterogeneous and disaggregated llm serving infrastructure, ” 2026. [Online]. Available: https://arxiv.org/abs/2602. 23036
2026
-
[9]
A discourse-aware attention model for abstractive summarization of long documents,
A. Cohan, F. Dernoncourt, D. S. Kim, T. Bui, S. Kim, W. Chang, and N. Goharian, “A discourse-aware attention model for abstractive summarization of long documents, ” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), M. Walker, H. Ji, an...
2018
-
[10]
Flashattention: fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. Ré, “Flashattention: fast and memory-efficient exact attention with io-awareness, ” in Proceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY, USA: Curran Associates Inc., 2022
2022
-
[11]
Hierarchical neural story generation,
A. Fan, M. Lewis, and Y. Dauphin, “Hierarchical neural story generation, ” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), I. Gurevych and Y. Miyao, Eds. Melbourne, Australia: Association for Computational Linguistics, Jul. 2018, pp. 889–898. [Online]. Available: https://aclanthology.org/P18-1082/
2018
-
[12]
Mind the memory gap: Unveiling gpu bottlenecks in large-batch llm inference,
P. Garcia, F. Agullo, Y. Zhu, C. Wang, E. Lee, O. Tardieu, J. Torres, and J. Berral, “Mind the memory gap: Unveiling gpu bottlenecks in large-batch llm inference, ” 07 2025, pp. 277–287
2025
-
[13]
Cloud TPU v5e system architecture,
Google Cloud, “Cloud TPU v5e system architecture, ” https://cloud. google.com/tpu/docs/v5e, 2024, accessed: 2026-05-15
2024
-
[14]
Cloud TPU v6e (trillium) system architecture,
——, “Cloud TPU v6e (trillium) system architecture, ” https://cloud. google.com/tpu/docs/v6e, 2024, accessed: 2026-05-15
2024
-
[15]
Trillium TPU is GA,
——, “Trillium TPU is GA, ” 2024, accessed: 2026-05-15. [Online]. Available: https://cloud.google.com/blog/products/compute/ trillium-tpu-is-ga
2024
-
[16]
Onnxim: A fast, cycle-level multi-core npu simulator,
H. Ham, W. Yang, Y. Shin, O. Woo, G. Heo, S. Lee, J. Park, and G. Kim, “Onnxim: A fast, cycle-level multi-core npu simulator, ”IEEE Comput. Archit. Lett., vol. 23, no. 2, p. 219–222, Jul. 2024. [Online]. Available: https://doi.org/10.1109/LCA.2024.3484648
-
[17]
mNPUsim: Evaluating the effect of sharing resources in multi-core NPUs,
S. Hwang, S. Lee, J. Kim, H. Kim, and J. Huh, “mNPUsim: Evaluating the effect of sharing resources in multi-core NPUs, ” in2023 IEEE International Symposium on Workload Characterization (IISWC), 2023, pp. 167–179. [Online]. Available: https://doi.org/10.1109/IISWC59245. 2023.00018
-
[18]
Ragged paged attention: A high-performance and flexible llm inference kernel for tpu,
J. Jiang, Y. Chen, B. A. Hechtman, F. Zhang, and Y. Mu, “Ragged paged attention: A high-performance and flexible llm inference kernel for tpu, ” 2026. [Online]. Available: https://arxiv.org/abs/2604.15464
Pith/arXiv arXiv 2026
-
[19]
Ten lessons from three generations shaped google’s tpuv4i : Industrial product,
N. P. Jouppi, D. Hyun Yoon, M. Ashcraft, M. Gottscho, T. B. Jablin, G. Kurian, J. Laudon, S. Li, P. Ma, X. Ma, T. Norrie, N. Patil, S. Prasad, C. Young, Z. Zhou, and D. Patterson, “Ten lessons from three generations shaped google’s tpuv4i : Industrial product, ” in 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021, pp. 1–14
2021
-
[20]
N. P. Jouppi, G. Kurian, S. Li, P. Ma, R. Nagarajan, L. Nai, N. Patil, S. Subramanian, A. Swing, B. Towles, C. Young, X. Zhou, Z. Zhou, and D. Patterson, “TPU v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings, ” inProceedings of the 50th Annual International Symposium on Computer Architecture (ISCA), 2...
-
[21]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Pattersonet al., “In-datacenter performance analysis of a tensor processing unit, ”SIGARCH Comput. Archit. News, vol. 45, no. 2, p. 1–12, Jun. 2017. [Online]. Available: https://doi.org/10.1145/3140659.3080246
-
[22]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention, ” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 611–626. [Online]. Available...
-
[23]
Forecasting gpu performance for deep learning training and inference,
S. Lee, A. Phanishayee, and D. Mahajan, “Forecasting gpu performance for deep learning training and inference, ” in Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. ACM, Mar. 2025, pp. 493–508. [Online]. Available: http://dx.doi.org/10.1145/3669940.3707265
-
[24]
Analyzing machine learning workloads using a detailed gpu simulator,
J. Lew, D. A. Shah, S. Pati, S. Cattell, M. Zhang, A. Sandhupatla, C. Ng, N. Goli, M. D. Sinclair, T. G. Rogers, and T. M. Aamodt, “Analyzing machine learning workloads using a detailed gpu simulator, ” in2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2019, pp. 151–152
2019
-
[25]
Path forward beyond simulators: Fast and accurate gpu execution time prediction for dnn workloads,
Y. Li, Y. Sun, and A. Jog, “Path forward beyond simulators: Fast and accurate gpu execution time prediction for dnn workloads, ” in Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 380–394. [Online]. Available: https://doi.org/10.1145/3613...
-
[26]
D. Liakopoulos, P. Sinha, T. Hu, M. Lee, and N. J. Yadwadkar, “Maveriq: Fingerprint-guided extrapolation and fragmentation- aware layering for intent-based llm serving, ” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25. New York, NY, USA: Association for Computing Machinery, 2025,...
-
[27]
Llama Team, AI @ Meta, “The llama 3 herd of models, ” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[28]
Abstractive text summarization using sequence- to-sequence RNNs and beyond,
R. Nallapati, B. Zhou, C. dos Santos, Ç. Gu ˙lçehre, and B. Xiang, “Abstractive text summarization using sequence- to-sequence RNNs and beyond, ” inProceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, S. Riezler and Y. Goldberg, Eds. Berlin, Germany: Association for Computational Linguistics, Aug. 2016, pp. 280–290. [Onlin...
2016
-
[29]
Efficient large-scale language model training on gpu clusters using megatron-lm
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia, “Efficient large-scale language model training on gpu clusters using megatron-lm, ” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and An...
-
[30]
Timeloop: A systematic approach to dnn accelerator evaluation,
A. Parashar, P. Raina, Y. S. Shao, Y.-H. Chen, V. A. Ying, A. Mukkara, R. Venkatesan, B. Khailany, S. W. Keckler, and J. Emer, “Timeloop: A systematic approach to dnn accelerator evaluation, ” in2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2019, pp. 304–315
2019
-
[31]
Realizing the amd exascale heterogeneous processor vision,
P. Patel, E. Choukse, C. Zhang, A. Shah, I. n. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative llm inference using phase splitting, ” inProceedings of the 51st Annual International Symposium on Computer Architecture, ser. ISCA ’24. IEEE Press, 2025, p. 118–132. [Online]. Available: https://doi.org/10.1109/ISCA59077.2024.00019
-
[32]
Forecasting llm inference performance via hardware-agnostic analytical modeling,
R. Patwari, A. Sirasao, and D. Das, “Forecasting llm inference performance via hardware-agnostic analytical modeling, ” 2025. [Online]. Available: https://arxiv.org/abs/2508.00904
arXiv 2025
-
[33]
Scale-sim v3: a modular cycle-accurate systolic accelerator simulator for end-to-end system analysis,
R. Raj, S. Banerjee, N. Chandra, Z. Wan, J. Tong, A. Samajdhar, and T. Krishna, “Scale-sim v3: a modular cycle-accurate systolic accelerator simulator for end-to-end system analysis, ” in2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2025, pp. 186–200
2025
-
[34]
Just-in-time compilation,
The JAX Authors, “Just-in-time compilation, ” https://docs.jax.dev/en/ latest/jit-compilation.html, accessed: 2026-05-19
2026
-
[35]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need, ” inAdvances in Neural Information Processing Systems, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. USA: Curran Associates, Inc., 2017. [Online]. Available: https...
2017
-
[36]
D. Xu, H. Zhang, L. Yang, R. Liu, G. Huang, M. Xu, and X. Liu, “Fast on-device llm inference with npus, ” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, ser. ASPLOS ’25. New York, NY, USA: Association for Computing Machinery, 2025, p. 445–462. [Online]. Available: ...
-
[37]
Pytorchsim: A comprehensive, fast, and accurate npu simulation framework,
W. Yang, Y. Shin, O. Woo, G. Park, H. Ham, J. Kang, J. Park, and G. Kim, “Pytorchsim: A comprehensive, fast, and accurate npu simulation framework, ” inProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’25. New York, NY, USA: Association for Computing Machinery, 2025, p. 1363–1380. [Online]. Available: https://doi.o...
-
[38]
Shadownpu: System and algorithm co-design for npu-centric on-device llm inference,
W. Yin, D. Xu, M. Xu, G. Huang, and X. Liu, “Shadownpu: System and algorithm co-design for npu-centric on-device llm inference, ”
-
[39]
Available: https://arxiv.org/abs/2508.16703
[Online]. Available: https://arxiv.org/abs/2508.16703
-
[40]
Habitat: A Runtime- Based computational performance predictor for deep neural network training,
G. X. Yu, Y. Gao, P. Golikov, and G. Pekhimenko, “Habitat: A Runtime- Based computational performance predictor for deep neural network training, ” in2021 USENIX Annual Technical Conference (USENIX ATC 21). USENIX Association, Jul. 2021, pp. 503–521. [Online]. Available: https://www.usenix.org/conference/atc21/presentation/yu
2021
-
[41]
Orca: A distributed serving system for Transformer-Based generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for Transformer-Based generative models, ” in16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). Carlsbad, CA: USENIX Association, Jul. 2022, pp. 521–538. [Online]. Available: https://www.usenix.org/conference/osdi22/presentation/yu
2022
-
[42]
Neptune: Advanced ML operator fusion for locality and parallelism on GPUs,
Y. Zhao, E. Johnson, P. Chatarasi, V. S. Adve, and S. Misailovic, “Neptune: Advanced ML operator fusion for locality and parallelism on GPUs, ”Proceedings of the ACM on Programming Languages, vol. 10, no. PLDI, 2026
2026
-
[43]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y. Zhong, S. Liu, J. Chen, J. Hu, Y. Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving, ” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). Santa Clara, CA: USENIX Association, Jul. 2024, pp. 193–210. [Online]. Available: https://www.usenix....
2024
-
[44]
Daydream: Accurately estimating the efficacy of optimizations for DNN training,
H. Zhu, A. Phanishayee, and G. Pekhimenko, “Daydream: Accurately estimating the efficacy of optimizations for DNN training, ” in 2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, Jul. 2020, pp. 337–352. [Online]. Available: https://www.usenix.org/conference/atc20/presentation/zhu-hongyu 12
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.