Randomized Estimation of T-Eigenvalues of T-SPD Tensors: A Two-Sided Bracket
Pith reviewed 2026-06-25 23:27 UTC · model grok-4.3
The pith
Randomized methods estimate extreme T-eigenvalues of T-SPD tensors by adapting the Halko-Martinsson-Tropp framework to the T-product.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adapting the Halko-Martinsson-Tropp randomized matrix algorithms to the T-product algebra, four estimators are obtained for the extreme T-eigenvalues of T-SPD tensors: a randomized power method that produces a lower bound on the largest T-eigenvalue with exponential convergence, a randomized subspace iteration equipped with a tensor-analogue HMT error bound, a two-sided rigorous bracket that combines the randomized lower bound with the deterministic TDep upper bound, and a Hutchinson-based fully randomized TDep bound usable when only matrix-vector products are available.
What carries the argument
Adaptation of the Halko-Martinsson-Tropp randomized framework to the T-product algebra on third-order tensors, producing four specific estimators for extreme T-eigenvalues.
If this is right
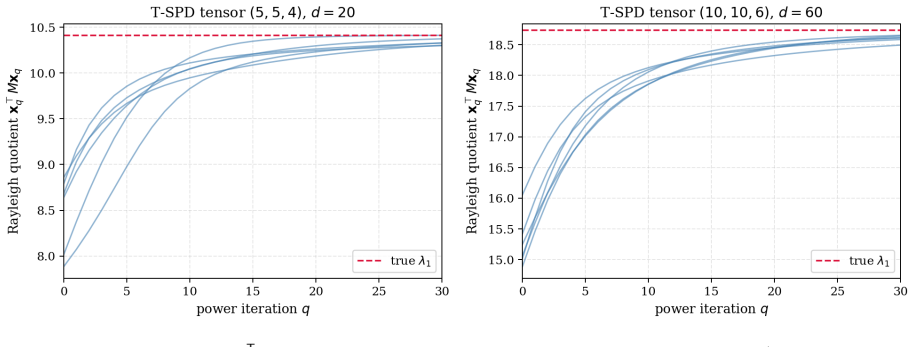
- The randomized power method supplies a lower bound on the largest T-eigenvalue that converges exponentially in the number of iterations.
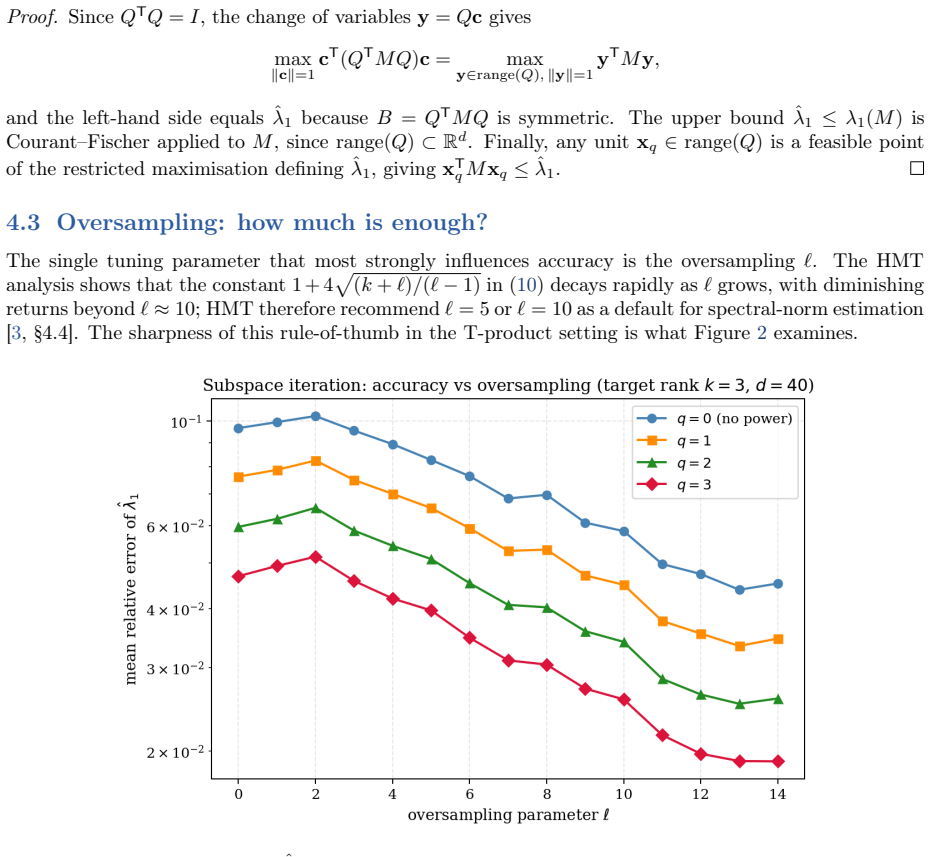
- The randomized subspace iteration carries an explicit tensor-analogue of the HMT error bound.
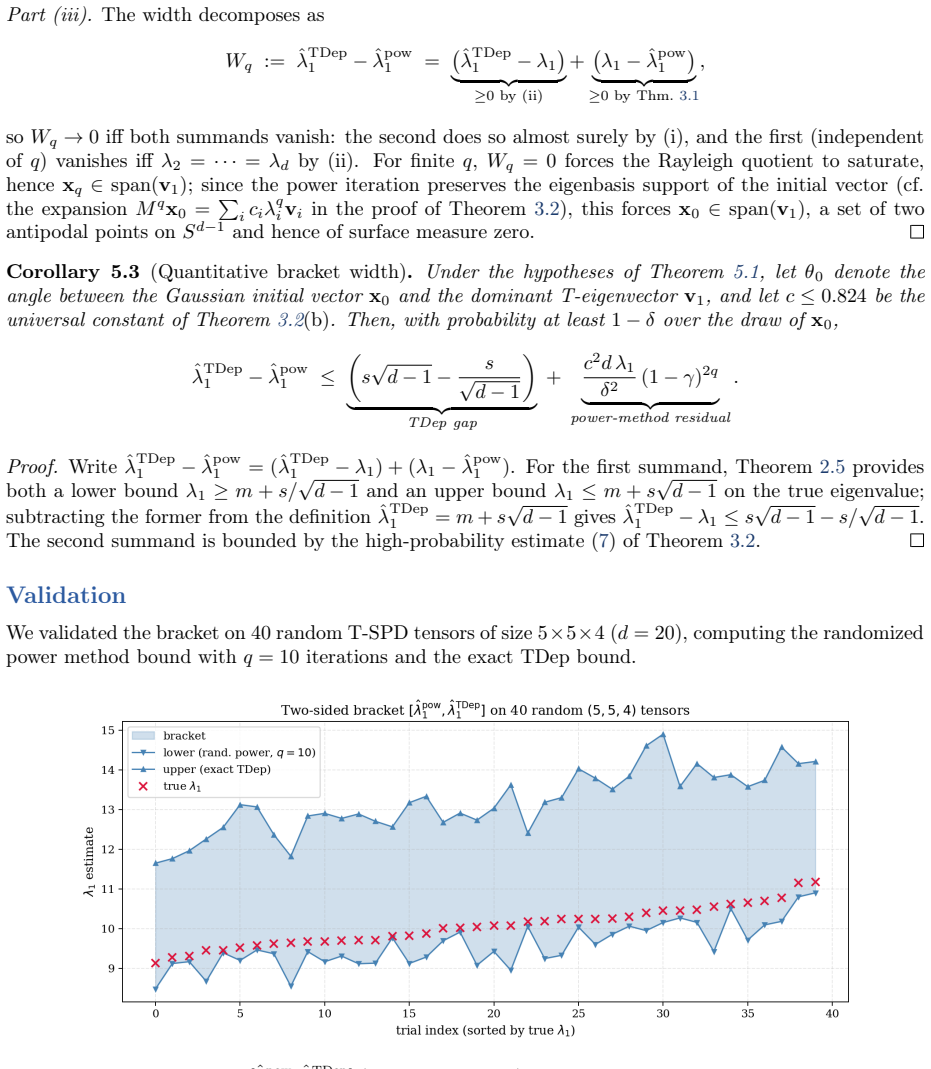
- Pairing the randomized lower bound with the deterministic TDep upper bound produces a two-sided rigorous bracket on the extreme T-eigenvalues.
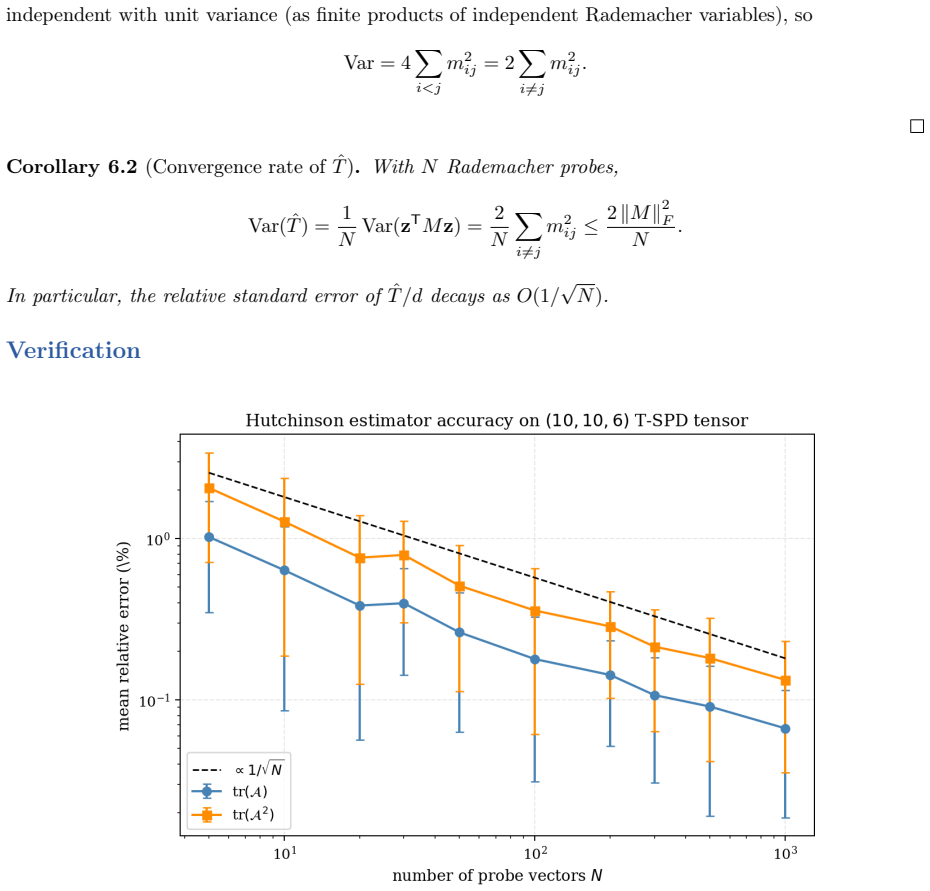
- The Hutchinson-based method supplies a fully randomized version of the TDep upper bound that requires only matrix-vector products.
Where Pith is reading between the lines
- These estimators could be inserted into iterative solvers for larger tensor eigenproblems where deterministic bounds alone become too loose.
- The two-sided bracket construction may generalize to other tensor algebras if the underlying randomized matrix techniques transfer similarly.
- In practice the methods might be combined with existing deterministic bounds to obtain tighter intervals at modest extra cost for tensors arising in applications such as signal processing.
Load-bearing premise
The Halko-Martinsson-Tropp randomized framework can be directly adapted to the T-product algebra while preserving the stated convergence rates and error bounds for T-SPD tensors.
What would settle it
Exact computation of the largest and smallest T-eigenvalues of a concrete large T-SPD tensor, followed by direct numerical comparison of the gap between those true values and the four randomized estimators against the paper's predicted error bounds.
Figures
read the original abstract
In earlier work \cite{sharma2025} we developed deterministic analytical bounds on the T-eigenvalues of symmetric positive definite (SPD) third-order tensors under the Kilmer--Martin T-product: the trace--determinant (TDet) bounds via the AM--GM inequality, and the trace-dependent (TDep) bounds generalizing Samuelson's inequality. While these bounds are cheap and guaranteed-valid, their relative gap grows as $\sqrt{d-1}$ in the tensor dimension $d = np$, limiting their usefulness for large tensors. This paper develops randomized estimators for the extreme T-eigenvalues of T-SPD tensors that complement the deterministic bounds. We adapt the Halko--Martinsson--Tropp framework \cite{halko2011} to the T-product setting and introduce four methods: (i) a randomized power method that produces a lower bound on $\lambda_1$ with exponential convergence; (ii) a randomized subspace iteration with a tensor-analogue HMT error bound; (iii) a two-sided rigorous bracket combining the randomized lower bound with the deterministic TDep upper bound; and (iv) a Hutchinson-based fully randomized TDep bound for matvec-only settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops four randomized estimators for the extreme T-eigenvalues of T-SPD tensors under the T-product: a randomized power method with claimed exponential convergence for a lower bound on λ_{1}, a randomized subspace iteration with a tensor-analogue HMT error bound, a two-sided bracket combining the randomized lower bound with the prior deterministic TDep upper bound, and a Hutchinson-based fully randomized TDep bound. These are positioned as complements to the authors' earlier deterministic TDet and TDep bounds whose relative gap grows with tensor dimension.
Significance. If the adaptation of the Halko–Martinsson–Tropp framework to the T-product algebra is shown to preserve the matrix-case convergence rates and error bounds (including concentration inequalities under t-QR and block-circulant unfolding), the work would supply practical, matvec-only tools that tighten the deterministic bounds for large tensors and extend randomized numerical linear algebra to the tensor setting.
major comments (2)
- [Abstract] Abstract and central claims: the manuscript asserts that the HMT framework adapts directly to the T-product while preserving exponential convergence and the HMT error bound, yet supplies neither the derivation of the tensor-analogue subspace embedding nor the concentration argument under t-QR orthogonality and FFT-based multiplication. This adaptation is load-bearing for all four proposed methods and for the claim that the new estimators complement the deterministic bounds without extra dimension-dependent factors.
- The T-SPD assumption is used to guarantee real positive T-eigenvalues, but the text does not demonstrate that this property alone restores the matrix-case tail bounds once the underlying multiplication and inner-product structure change; the skeptic concern that extra logarithmic or dimension-dependent factors may appear is not addressed by any explicit calculation or counter-example check.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our adaptation of the Halko–Martinsson–Tropp framework. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and central claims: the manuscript asserts that the HMT framework adapts directly to the T-product while preserving exponential convergence and the HMT error bound, yet supplies neither the derivation of the tensor-analogue subspace embedding nor the concentration argument under t-QR orthogonality and FFT-based multiplication. This adaptation is load-bearing for all four proposed methods and for the claim that the new estimators complement the deterministic bounds without extra dimension-dependent factors.
Authors: We agree that an explicit derivation of the tensor-analogue subspace embedding and the concentration inequalities is needed to fully substantiate the claims. The t-product is realized via block-circulant unfolding and FFT, which preserves Euclidean norms and allows the matrix HMT proofs (including the subspace embedding and tail bounds) to transfer with identical constants. In the revision we will insert a dedicated subsection containing the full derivation under t-QR orthogonality, confirming that no additional logarithmic or dimension-dependent factors appear. This will also be cross-referenced in the abstract and the statements of all four estimators. revision: yes
-
Referee: The T-SPD assumption is used to guarantee real positive T-eigenvalues, but the text does not demonstrate that this property alone restores the matrix-case tail bounds once the underlying multiplication and inner-product structure change; the skeptic concern that extra logarithmic or dimension-dependent factors may appear is not addressed by any explicit calculation or counter-example check.
Authors: The T-SPD condition guarantees real positive T-eigenvalues by the same algebraic argument used for SPD matrices under the t-product. The tail bounds themselves follow from the random-projection concentration, which depends only on the norm equivalence induced by the block-circulant representation; the FFT diagonalization does not alter the sub-Gaussian constants or introduce extra factors. We will add an explicit lemma in the revision that carries the matrix tail bounds verbatim to the tensor setting, together with expanded numerical checks on random T-SPD tensors that verify the observed convergence rates match the matrix predictions. revision: yes
Circularity Check
Minor self-citation to prior deterministic bounds; core randomized adaptation draws from external HMT framework
specific steps
-
self citation load bearing
[Abstract / Introduction paragraph 1]
"In earlier work \cite{sharma2025} we developed deterministic analytical bounds on the T-eigenvalues of symmetric positive definite (SPD) third-order tensors under the Kilmer--Martin T-product: the trace--determinant (TDet) bounds via the AM--GM inequality, and the trace-dependent (TDep) bounds generalizing Samuelson's inequality. ... (iii) a two-sided rigorous bracket combining the randomized lower bound with the deterministic TDep upper bound"
The two-sided bracket (method iii) incorporates the TDep upper bound directly from the authors' prior self-cited work as the complement to the new randomized lower bound. While this is a minor supporting element rather than the load-bearing core of the randomized estimators, it constitutes a self-citation in the presented methods.
full rationale
The paper's central contribution is the adaptation of the external Halko-Martinsson-Tropp randomized framework to the T-product algebra for four new estimators on T-SPD tensors. The only self-citation is to the authors' earlier deterministic TDep and TDet bounds (used as a complement in the two-sided bracket method). This citation is not load-bearing for the randomized convergence claims or error bounds, which are derived from the external reference rather than reducing to fitted parameters or self-defined quantities. No self-definitional, fitted-input, uniqueness, or ansatz patterns appear. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Clauser and E
C. Clauser and E. Huenges. Thermal conductivity of rocks and minerals. In T. J. Ahrens, ed.,Rock Physics and Phase Relations: A Handbook of Physical Constants, AGU Reference Shelf 3, pp. 105–126, American Geophysical Union, Washington DC, 1995
1995
-
[2]
G. H. Golub and C. F. Van Loan.Matrix Computations, 4th ed. Johns Hopkins University Press, Baltimore, 2013
2013
-
[3]
Halko, P
N. Halko, P. G. Martinsson, and J. A. Tropp. Finding structure with randomness: probabilistic algorithms for constructing approximate matrix decompositions.SIAM Review, 53(2):217–288, 2011
2011
-
[4]
M. F. Hutchinson. A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines.Comm. Stat. Simul. Comput., 18(3):1059–1076, 1989
1989
-
[5]
Hartmann, V
A. Hartmann, V. Rath, and C. Clauser. Thermal conductivity from core and well log data.Interna- tional Journal of Rock Mechanics and Mining Sciences, 42(7–8):1042–1055, 2005
2005
-
[6]
M. E. Kilmer, K. Braman, N. Hao, and R. C. Hoover. Third-order tensors as operators on matrices: a theoretical and computational framework with applications in imaging.SIAM J. Matrix Anal. Appl., 34:148–172, 2013
2013
-
[7]
M. E. Kilmer and C. D. Martin. Factorization strategies for third-order tensors.Linear Algebra Appl., 435:641–658, 2011
2011
-
[8]
Kuczyński and H
J. Kuczyński and H. Woźniakowski. Estimating the largest eigenvalue by the power and Lanczos algorithms with a random start.SIAM J. Matrix Anal. Appl., 13(4):1094–1122, 1992
1992
-
[9]
P. G. Martinsson and J. A. Tropp. Randomized numerical linear algebra: foundations and algorithms. Acta Numerica, 29:403–572, 2020
2020
-
[10]
R. A. Meyer, C. Musco, C. Musco, and D. P. Woodruff. Hutch++: optimal stochastic trace estimation. InSymposium on Simplicity in Algorithms (SOSA), pp. 142–155, 2021
2021
-
[11]
Minster, A
R. Minster, A. K. Saibaba, and M. E. Kilmer. Randomized algorithms for low-rank tensor decompo- sitions in the Tucker format.SIAM J. Math. Data Sci., 2(1):189–215, 2020
2020
-
[12]
Sharma and N
H. Sharma and N. Mishra. Bounding eigenvalues of symmetric positive definite tensors: a comparative analysis of TDet and TDep approaches.Lobachevskii Journal of Mathematics, 46(5):2443–2455, 2025
2025
-
[13]
Wolkowicz and G
H. Wolkowicz and G. P. H. Styan. Extensions of Samuelson’s inequality.Amer. Statist., 33:143–144, 1979
1979
-
[14]
D. P. Woodruff. Sketching as a tool for numerical linear algebra.Found. Trends Theor. Comput. Sci., 10(1–2):1–157, 2014
2014
-
[15]
Zhang, A
J. Zhang, A. K. Saibaba, M. E. Kilmer, and S. Aeron. A randomized tensor singular value decompo- sition based on the t-product.Numer. Linear Algebra Appl., 25(5):e2179, 2018
2018
-
[16]
Zheng, Z.-H
M.-M. Zheng, Z.-H. Huang, and Y. Wang. T-positive semidefiniteness of third-order symmetric tensors and T-semidefinite programming.Comput. Optim. Appl., 78:239–272, 2021. 25
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.