TASR: Training-Free Adaptive Stopping for Iterative Retrieval
Pith reviewed 2026-06-27 05:12 UTC · model grok-4.3
The pith
TASR stops iterative retrieval when the model repeats its answer and the logit margin exceeds 0.25, keeping 94.8 percent of fixed-k accuracy at 62.6 percent of the calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
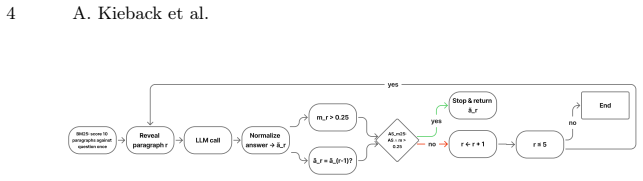
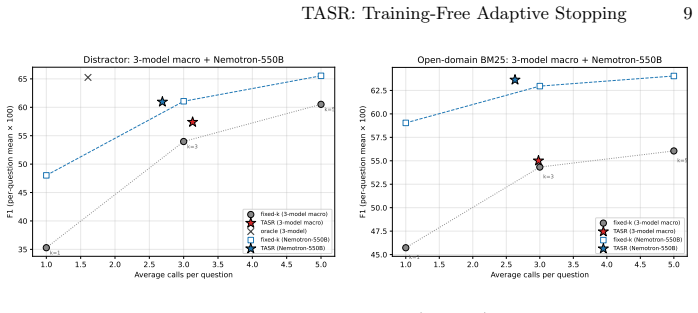
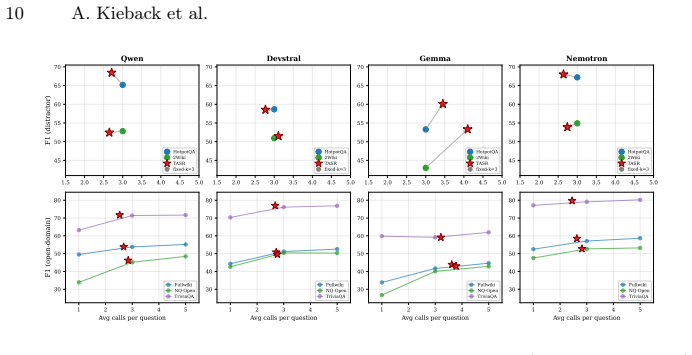
TASR is a one-line predicate that fires when the model repeats its previous-round normalized answer and the isotonically calibrated logit margin exceeds 0.25. On a 3-model by 2-dataset distractor grid it retains 94.8 percent of fixed-k=5 macro F1 at 62.6 percent of its calls and exceeds fixed-k=3 by 3.42 F1 points. The same fixed rule, with calibration locked from the distractor split, produces 55.01 F1 at 2.98 calls versus 54.33 at 3.00 for fixed-k=3 on nine open-domain BM25 cells, generalizes to nine dense-retrieval cells across two retriever families, and holds on eight cells of a Nemotron-3-Ultra-550B production model, with zero significant regressions in any extension.
What carries the argument
The TASR stopping predicate: answer repetition combined with a fixed 0.25 threshold on the isotonically calibrated logit margin.
Load-bearing premise
The single fixed threshold of 0.25 chosen on one canonical cell will remain near-optimal without retuning when the underlying model, retriever family, or corpus distribution changes.
What would settle it
A new model-retriever pair on which TASR produces a statistically significant drop in macro F1 relative to fixed-k=5 while using the locked 0.25 threshold.
Figures
read the original abstract
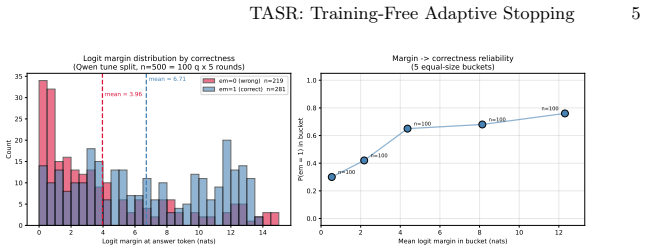
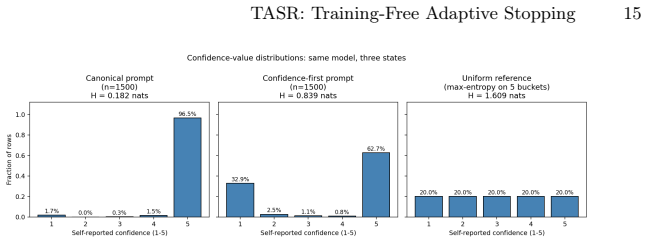
Iterative retrieval-augmented generation agents commonly overspend by continuing to retrieve after the model has converged on an answer, incurring calls that change neither the prediction nor the supporting evidence. Existing remedies learn a stopping policy from labeled trajectories, tying the decision to a trained component that requires retraining for each new model or task. We propose TASR (Training-Free Adaptive Stopping Rule), a one-line predicate that fires when the model repeats its previous-round normalized answer and the isotonically calibrated logit margin exceeds 0.25. No classifier or value head is learned; the threshold is fixed across all thirty-two (model, retriever, corpus) configurations we evaluate. On a 3-model x 2-dataset distractor grid, TASR retains 94.8% of fixed-k=5's macro F1 at 62.6% of its calls and exceeds fixed-k=3 by +3.42 F1. The pattern holds on nine open-domain BM25 cells (55.01 F1 at 2.98 calls vs. 54.33 at 3.00 for fixed-k=3) and, with calibration locked from the distractor split, on nine dense-retrieval cells across two retriever families, and on eight cells of a Nemotron-3-Ultra-550B production model, with zero significant regressions in any extension. The rule was selected from an exhaustive enumeration of 381 candidate stopping rules on the canonical selection cell, where no alternative Pareto-dominates it. A signal-quality analysis shows that verbalized 1-5 confidence collapses on RLHF-tuned models (96.5% of values equal 5, entropy 0.182 nats), while the logit margin achieves 40x better class-conditional separation, grounding the design in a measurable model pathology. TASR is an auditable, training-free Pareto baseline for adaptive stopping in iterative retrieval. Code is publicly available at https://github.com/JSBAICenter/TASR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TASR, a training-free adaptive stopping rule for iterative retrieval in RAG agents. TASR stops when the model repeats its prior normalized answer and the isotonically calibrated logit margin exceeds a fixed threshold of 0.25. The threshold is chosen via exhaustive search over 381 candidates on one canonical distractor-split cell and then locked; the rule is evaluated across a 3-model × 2-dataset grid plus 26 extension cells (BM25, two dense retriever families, Nemotron-3-Ultra-550B) with the claim that it retains 94.8 % of fixed-k=5 macro-F1 at 62.6 % of the calls, exceeds fixed-k=3 by +3.42 F1, and exhibits zero significant regressions. A signal-quality comparison shows the logit margin separates classes far better than verbalized confidence. Public code is provided.
Significance. If the central empirical claim holds, TASR supplies a simple, auditable, parameter-light baseline that removes the need to train a stopping classifier for each new model or retriever. The exhaustive enumeration on the selection cell, the independent extension-cell results, the public code, and the explicit comparison of logit-margin versus verbalized-confidence signal quality are concrete strengths that increase the result’s practical value for iterative retrieval systems.
major comments (2)
- [Abstract] Abstract: the reported F1 deltas and call reductions are given as point estimates with no per-cell variance, standard deviations, or error bars and no description of how many independent runs underlie each cell; this directly affects the reliability of the “zero significant regressions” claim across the 32 configurations.
- [Abstract] Abstract (stopping-rule definition): the isotonic calibration that produces the 0.25 threshold is stated to be locked from the distractor split, yet no details are supplied on calibration-set size, the isotonic regression procedure itself, or any out-of-sample validation performed on held-out cells; because the fixed-threshold claim is load-bearing for the training-free assertion, these procedural specifics are required.
minor comments (1)
- The manuscript would benefit from an explicit equation or pseudocode block that defines the full TASR predicate (repeat answer AND calibrated margin > 0.25) so that the one-line claim can be verified without reference to the GitHub repository.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical reporting and procedural transparency. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported F1 deltas and call reductions are given as point estimates with no per-cell variance, standard deviations, or error bars and no description of how many independent runs underlie each cell; this directly affects the reliability of the “zero significant regressions” claim across the 32 configurations.
Authors: We agree the lack of variance reporting weakens the strength of the zero-regression claim. All 32 configurations were executed as single deterministic runs with fixed seeds; retrieval and generation contained no stochastic sampling in the reported results. We will revise the abstract and experimental setup section to state this explicitly and note that the no-regression observation rests on direct point-estimate comparison rather than statistical testing. This is a clarification rather than new experiments. revision: partial
-
Referee: [Abstract] Abstract (stopping-rule definition): the isotonic calibration that produces the 0.25 threshold is stated to be locked from the distractor split, yet no details are supplied on calibration-set size, the isotonic regression procedure itself, or any out-of-sample validation performed on held-out cells; because the fixed-threshold claim is load-bearing for the training-free assertion, these procedural specifics are required.
Authors: The 0.25 threshold resulted from exhaustive enumeration of 381 candidates on the canonical distractor-split cell, after applying isotonic regression (scikit-learn IsotonicRegression) to the logit margins collected on that cell. The calibrated threshold was then frozen with no further adjustment on any held-out cell. We will add the exact calibration-set size (the full query count of the distractor split), the library call, and explicit confirmation of no out-of-sample retuning to the methods section. This makes the training-free procedure fully auditable. revision: yes
Circularity Check
No significant circularity; fixed rule selected on one cell and evaluated independently on held-out cells
full rationale
The TASR predicate (repeat answer AND logit margin > 0.25 after isotonic calibration) is selected by exhaustive enumeration on a single canonical cell, after which the threshold and calibration are locked and applied to 26+ non-overlapping extension cells spanning different models, retrievers, and corpora. Reported F1 and call-count metrics on those cells are direct empirical measurements, not quantities that reduce by construction to the selection cell's fitted threshold. No self-citations, uniqueness theorems, or ansatzes appear in the load-bearing steps; the signal-quality comparison between logit margin and verbalized confidence supplies independent grounding. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- logit_margin_threshold
axioms (1)
- domain assumption Isotonic calibration produces a reliable margin that separates answer quality across models and retrievers
Reference graph
Works this paper leans on
-
[1]
Asai, A., Wu, Z., Wang, Y., Sil, A., Hajishirzi, H.: Self-rag: Learning to retrieve, generate, and critique through self-reflection (2023).https://doi.org/10.48550/ arXiv.2310.11511,https://arxiv.org/abs/2310.11511
Pith/arXiv arXiv 2023
-
[2]
Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., Liu, Z.: M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embeddings through self- knowledge distillation (2025).https://doi.org/10.48550/arXiv.2402.03216, https://arxiv.org/abs/2402.03216
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03216 2025
-
[3]
Du,W.: When+1% isnot enough: Apaired bootstrapprotocolfor evaluatingsmall improvements (2025).https://doi.org/10.48550/arXiv.2511.19794,https:// arxiv.org/abs/2511.19794
-
[4]
dev/gemma(2025)
GemmaTeam,GoogleDeepMind:Gemma4technicalreport.https://ai.google. dev/gemma(2025)
2025
-
[5]
In: Proceedings of the 28th International Conference on Computational Linguistics (COLING) (2020), 2WikiMultiHopQA
Ho, X., Duong Nguyen, A.K., Sugawara, S., Aizawa, A.: Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. In: Proceedings of the 28th International Conference on Computational Linguistics (COLING) (2020), 2WikiMultiHopQA
2020
-
[6]
In: Trans- actions on Machine Learning Research (2022) TASR: Training-Free Adaptive Stopping 19
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., Grave, E.: Unsupervised dense information retrieval with contrastive learning. In: Trans- actions on Machine Learning Research (2022) TASR: Training-Free Adaptive Stopping 19
2022
-
[7]
In: Proceedings of the 9th International Conference on Learning Rep- resentations (ICLR) (2021)
Izacard, G., Grave, E.: Distilling knowledge from reader to retriever for question answering. In: Proceedings of the 9th International Conference on Learning Rep- resentations (ICLR) (2021)
2021
-
[8]
Wang, Y ., Qu, W., Zhai, S., Jiang, Y ., Zichen, L., Liu, Y ., Dong, Y ., and Zhang, J
Jeong, S., Baek, J., Cho, S., Hwang, S.J., Park, J.C.: Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity. In: Proceedings of the 2024 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies (NAACL- HLT). pp. 7036–7050 (2024).https://doi.org...
-
[9]
Jiang, Z., Xu, F.F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J., Yang, Y., Callan, J., Neubig, G.: Active retrieval augmented generation (2023).https://doi.org/ 10.48550/arXiv.2305.06983,https://arxiv.org/abs/2305.06983
-
[10]
Joshi, M., Choi, E., Weld, D.S., Zettlemoyer, L.: Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension (2017).https://doi.org/ 10.48550/arXiv.1705.03551,https://arxiv.org/abs/1705.03551
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.03551 2017
-
[11]
In: Transactions of the Association for Computational Linguistics
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M.W., Dai, A.M., Uszkoreit, J., Le, Q., Petrov, S.: Natural questions: A benchmark for question answering research. In: Transactions of the Association for Computational Linguisti...
2019
-
[12]
Lahmy, M., Yozevitch, R.: Replace, don’t expand: Mitigating context dilution in multi-hop RAG via fixed-budget evidence assembly (2025),https://arxiv.org/ abs/2512.10787
arXiv 2025
-
[13]
Levy, S., Mazor, N., Shalmon, L., Hassid, M., Stanovsky, G.: More documents, same length: Isolating the challenge of multiple documents in RAG (2025).https: //doi.org/10.48550/arXiv.2503.04388,https://arxiv.org/abs/2503.04388
-
[14]
Lin, J., Ma, X., Lin, S.C., Yang, J.H., Pradeep, R., Nogueira, R.: Pyserini: A Python toolkit for reproducible information retrieval research with sparse and dense representations. In: Proceedings of the 44th International ACM SIGIR Con- ference on Research and Development in Information Retrieval. pp. 2356–2362 (2021).https://doi.org/10.1145/3404835.3463238
-
[15]
Luccioni, S., Jernite, Y., Strubell, E.: Power hungry processing: Watts driving the cost of AI deployment? In: Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT). pp. 85–99 (2024).https://doi.org/ 10.1145/3630106.3658542
-
[16]
co/mistralai(2025)
Mistral AI: Devstral-small-2-24b-instruct (release 2512).https://huggingface. co/mistralai(2025)
2025
-
[17]
Model card (2026)
NVIDIA: NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4. Model card (2026)
2026
-
[18]
Park, J., Cho, S., Lee, J.Y.: Stop-RAG: Value-based retrieval control for it- erative RAG (2025).https://doi.org/10.48550/arXiv.2510.14337,https:// arxiv.org/abs/2510.14337
-
[19]
Measuring and Narrowing the Compositionality Gap in Language Models
Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N., Lewis, M.: Measuring and narrowing the compositionality gap in language models. In: Bouamor, H., Pino, J., Bali, K. (eds.) Findings of the Association for Computational Linguis- tics: EMNLP 2023. pp. 5687–5711. Association for Computational Linguistics, Sin- gapore (Dec 2023).https://doi.org/10.18653/...
-
[20]
Kieback et al
Qwen Team: Qwen3.6-27B: Flagship-level coding in a 27B dense model (April 2026),https://qwen.ai/blog?id=qwen3.6-27b 20 A. Kieback et al
2026
-
[21]
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., Manning, C.D.: Just ask for calibration: Strategies for eliciting calibrated confi- dence scores from language models fine-tuned with human feedback. In: Proceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2023).https://doi.org/10.1...
-
[22]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), Long Papers
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A.: Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), Long Papers. pp. 10014–10037 (2023).https://doi.org/10. 18653/v1/2023.acl-long.557
2023
-
[23]
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language mod- els (2023).https://doi.org/10.48550/arXiv.2203.11171,https://arxiv.org/ abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2023
-
[24]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W., Salakhutdinov, R., Manning, C.D.: HotpotQA: A dataset for diverse, explainable multi-hop question answer- ing. In: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J. (eds.) Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 2369–2380. Association for Computationa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.