Robust Audio Tagging under Class-wise Supervision Unreliability
Pith reviewed 2026-05-19 22:22 UTC · model grok-4.3
The pith
Learning one unreliability scalar per sound class down-weights noisy labels and improves audio tagging on weak data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Explicit class-wise modeling of supervision unreliability is an effective and practical strategy for robust audio tagging under large-scale weakly labeled training. The approach learns a separate unreliability parameter for each class and uses it to control supervision strength, addressing spurious label additions, misassignments between similar classes, and weakened label evidence without modifying the model or inference process.
What carries the argument
The Class-wise Supervision Unreliability (CSU) framework, which optimizes one scalar unreliability parameter per class to down-weight less reliable supervision during training.
If this is right
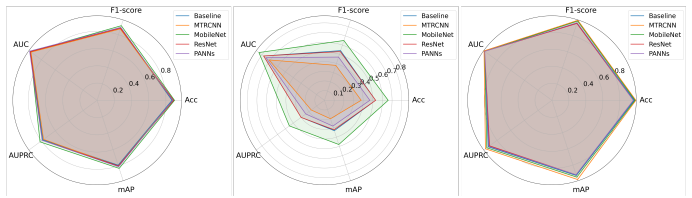
- CSU raises tagging accuracy on AudioSet and controlled benchmarks across multiple model architectures.
- The framework simultaneously handles spurious additions, inter-class misassignments, and weakened label evidence.
- Performance gains appear without any alteration to the underlying tagging network or its test-time behavior.
- A new manually verified benchmark called ESC-FreeGen50 supports evaluation on mixed real and generated audio.
Where Pith is reading between the lines
- The same per-class reliability weighting could transfer to image or text classification tasks that use noisy multi-label supervision.
- The learned scalars might identify which sound classes suffer the most from annotation errors in a given dataset.
- CSU could be stacked with existing noise-robust losses to produce additive gains on very large weak-label collections.
Load-bearing premise
A single scalar per class can adequately capture and correct the combined effects of different label problems without creating new biases or requiring changes to the model.
What would settle it
Training a standard model and a CSU-augmented model on a dataset whose labels are known to be complete and accurate; if CSU yields equal or lower performance, the per-class modeling adds no benefit or introduces unnecessary bias.
Figures







read the original abstract
Weakly labeled datasets such as AudioSet have driven recent progress in audio tagging. However, annotation quality varies across sound classes. Labels may be incomplete, ambiguous, or unreliable, which introduces class-dependent supervision bias during optimisation. The issue becomes harder as real and generated audio are increasingly mixed in training, and generated samples do not always match their intended semantic labels. Prior work mainly addressed unreliable supervision from missing-positive labels, while this paper targets three other sources of unreliable supervision: spurious additions, misassignments between similar classes, and weakened label evidence. These effects introduce class-dependent optimisation bias that is not explicitly modeled by most existing methods. To bridge this gap, the paper proposes a Class-wise Supervision Unreliability (CSU) framework that controls supervision strength at the class level during training. CSU learns a separate unreliability parameter for each class and down-weights less reliable supervision without changing the model architecture or inference process. To support evaluations, this paper also introduces ESC-FreeGen50, a manually verified benchmark of 50 sound classes that combines real and generated audio. Experiments on controlled benchmarks and AudioSet show that CSU improves robustness across different architectures and different sources of supervision unreliability. The results indicate that explicit class-wise modeling of supervision unreliability is an effective and practical strategy for robust audio tagging under large-scale weakly labeled training. Code and data are available at: https://github.com/Yuanbo2020/CSU
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Class-wise Supervision Unreliability (CSU) framework for robust audio tagging on weakly labeled data such as AudioSet. It explicitly models three sources of class-dependent supervision unreliability—spurious additions, misassignments between similar classes, and weakened label evidence—by learning a single scalar unreliability parameter per class that down-weights the corresponding loss term during training. The approach requires no architecture changes or inference modifications. The authors introduce the ESC-FreeGen50 benchmark (real + generated audio, 50 classes) and report performance gains on controlled benchmarks and AudioSet across multiple architectures.
Significance. If the central claim holds, the work supplies a lightweight, architecture-agnostic mechanism for mitigating class-specific label noise that is increasingly common when real and generated audio are mixed. The public release of code and the new manually verified benchmark constitute clear strengths that support reproducibility and further experimentation.
major comments (1)
- [§3] §3 (CSU framework description): the claim that a single scalar λ_c per class suffices to correct the combined effects of spurious additions, misassignments, and weakened evidence rests on the assumption that these distinct error sources produce gradient effects that can be absorbed by one multiplier applied to the entire per-class loss term. No derivation or low-rank analysis is provided showing that the loss geometry aligns these effects along a single axis; without such justification the learned λ_c may represent a compromise that leaves residual bias.
minor comments (2)
- [Abstract] Abstract: quantitative improvements (e.g., mAP deltas) and the specific architectures tested are mentioned only at high level; adding one sentence with concrete numbers would improve clarity.
- [Method] The description of how the unreliability parameters are initialized and regularized is brief; a short paragraph or equation clarifying the optimization objective for λ_c would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We provide a point-by-point response to the major comment below.
read point-by-point responses
-
Referee: [§3] §3 (CSU framework description): the claim that a single scalar λ_c per class suffices to correct the combined effects of spurious additions, misassignments, and weakened evidence rests on the assumption that these distinct error sources produce gradient effects that can be absorbed by one multiplier applied to the entire per-class loss term. No derivation or low-rank analysis is provided showing that the loss geometry aligns these effects along a single axis; without such justification the learned λ_c may represent a compromise that leaves residual bias.
Authors: We acknowledge the validity of this observation. The CSU framework models the net effect of the three mentioned sources of unreliability through a single per-class scalar because each source ultimately attenuates the trustworthiness of the class label in the loss computation. Spurious additions introduce false positives, misassignments confuse similar classes, and weakened evidence reduces label strength—all of which can be approximated by down-weighting the entire loss contribution for that class. While a detailed analysis of the loss geometry (e.g., via Hessian or gradient alignment) is not included in the current manuscript, the approach is justified by its simplicity and effectiveness in practice. We will update the manuscript in §3 to explicitly state this modeling assumption and discuss potential limitations regarding residual bias. revision: partial
Circularity Check
No significant circularity; empirical framework with external validation
full rationale
The paper proposes the CSU framework as a practical training modification that learns one scalar unreliability parameter per class to down-weight supervision. These parameters are optimized jointly with the model on the training data and are not derived from or equated to the reported performance metrics. Evaluations use held-out test sets on AudioSet and the newly introduced manually verified ESC-FreeGen50 benchmark; code release permits independent reproduction. No derivation chain, self-citation, or ansatz reduces the central effectiveness claim to the fitted parameters by construction. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- class-wise unreliability parameter
axioms (1)
- domain assumption Unreliable supervision from spurious additions, misassignments, and weakened evidence introduces class-dependent optimisation bias not captured by existing methods
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
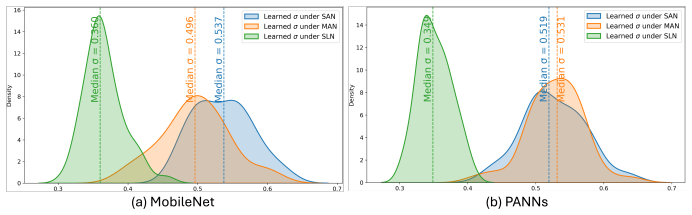
Lsurr,i = 1/σ_i² Li(W) + log(σ_i +1) with σ_i >0 learned per class
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
scaled logit z_i = f_i / σ_i² controlling supervision strength
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. F. Gemmeke, D. P. Ellis, D. Freedman, et al., AudioSet: An ontology and human-labeled dataset for audio events, in: IEEE International Conference on Acoustics, Speech, and Signal Processing, 2017, pp. 776–780
work page 2017
-
[2]
E. Fonseca, J. Pons, X. Favory, F. Font, D. Bogdanov, et al., FSD50K: an 30 open dataset of human-labeled sound events, IEEE/ACM Transactions on Au- dio, Speech, and Language Processing 30 (2022) 829–852
work page 2022
-
[3]
Y . Hou, Q. Ren, A. Mitchell, W. Wang, J. Kang, T. Belpaeme, D. Botteldooren, Soundscape captioning using sound affective quality network and large language model, IEEE Transactions on Multimedia 28 (2026) 2186–2200
work page 2026
-
[4]
E. Fonseca, M. Plakal, F. Font, D. P. Ellis, X. Serra, Audio tagging with noisy labels and minimal supervision, in: IEEE AASP DCASE 2019, 2019, p. 69
work page 2019
-
[5]
E. Fonseca, S. Hershey, M. Plakal, D. P. Ellis, et al., Addressing missing labels in large-scale sound event recognition using a teacher-student framework with loss masking, IEEE Signal Processing Letters 27 (2020) 1235–1239
work page 2020
-
[6]
E. Fonseca, M. Plakal, D. P. Ellis, F. Font, et al., Learning sound event classi- fiers from web audio with noisy labels, in: IEEE International Conference on Acoustics, Speech, and Signal Processing, 2019, pp. 21–25
work page 2019
-
[7]
Iqbal, Noisy web supervision for audio classification, Ph.D
T. Iqbal, Noisy web supervision for audio classification, Ph.D. thesis, University of Surrey (2022)
work page 2022
-
[8]
Y . Gong, Y .-A. Chung, J. Glass, Psla: Improving audio tagging with pretrain- ing, sampling, labeling, and aggregation, IEEE/ACM Transactions on Audio, Speech, and Language Processing 29 (2021) 3292–3306
work page 2021
-
[9]
A. E. Méndez Méndez, et al., Eliciting confidence for improving crowdsourced audio annotations, ACM on Human-Computer Interaction 6 (2022) 1–25
work page 2022
- [10]
- [11]
- [12]
-
[13]
Z. Zhou, R. Li, W. Ai, X. Li, Z. Teng, B. Zhang, J. Du, Affinity-aware uncertainty quantification for learning with noisy labels, Pattern Recognition 172 (2026) 112495
work page 2026
-
[14]
Y . Wang, X. Ma, Z. Chen, Y . Luo, J. Yi, J. Bailey, Symmetric cross entropy for robust learning with noisy labels, in: IEEE/CVF International Conference on Computer Vision, 2019, pp. 322–330
work page 2019
-
[15]
S. Reed, H. Lee, D. Anguelov, C. Szegedy, D. Erhan, A. Rabinovich, Train- ing deep neural networks on noisy labels with bootstrapping, in: International Conference on Learning Representations, 2015
work page 2015
-
[16]
M. N. Rizve, K. Duarte, Y . S. Rawat, M. Shah, In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learn- ing, in: International Conference on Learning Representations, 2020
work page 2020
- [17]
- [18]
- [19]
-
[20]
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, M. D. Plumbley, AudioLDM2: Learning holistic audio generation with self- 32 supervised pretraining, IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing 32 (2024) 2871–2883
work page 2024
- [21]
- [22]
-
[23]
N. M. Müller, et al., Human perception of audio deepfakes, in: International Workshop on Deepfake Detection for Audio Multimedia, 2022, pp. 85–91
work page 2022
-
[24]
K. J. Piczak, ESC: Dataset for environmental sound classification, in: ACM International Conference on Multimedia, 2015, pp. 1015–1018
work page 2015
-
[25]
F. Font, G. Roma, X. Serra, Freesound technical demo, ACM International Con- ference on Multimedia (2013)
work page 2013
-
[26]
N. Natarajan, I. S. Dhillon, P. K. Ravikumar, A. Tewari, Learning with noisy labels, in: Advances in Neural Information Processing Systems, V ol. 26, 2013
work page 2013
-
[27]
H. Song, M. Kim, D. Park, Y . Shin, J.-G. Lee, Learning from noisy labels with deep neural networks: A survey, IEEE Transactions on Neural Networks and Learning Systems 34 (11) (2022) 8135–8153
work page 2022
-
[28]
Y . Liu, H. Cheng, K. Zhang, Identifiability of label noise transition matrix, in: International Conference on Machine Learning, PMLR, 2023, pp. 21475–21496
work page 2023
-
[29]
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L.-C. Chen, Mobilenetv2: In- verted residuals and linear bottlenecks, in: IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 4510–4520. 33
work page 2018
-
[30]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: IEEE conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
work page 2016
-
[31]
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, M. D. Plumbley, PANNs: Large- scale pretrained audio neural networks for audio pattern recognition, IEEE/ACM Transactions on Audio, Speech, and Language Processing 28 (2020) 2880–2894
work page 2020
-
[32]
W. Chen, Y . Liang, Z. Ma, Z. Zheng, X. Chen, EAT: self-supervised pre-training with efficient audio transformer, in: International Joint Conference on Artificial Intelligence, 2024, pp. 3807–3815
work page 2024
-
[33]
Y . Hou, S. Song, C. Yu, W. Wang, et al., Audio event-relational graph represen- tation learning for acoustic scene classification, IEEE Signal Processing Letters 30 (2023) 1382–1386
work page 2023
-
[34]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, in: Interna- tional Conference on Learning Representations, 2015
work page 2015
-
[35]
N. Srivastava, G. Hinton, et al., Dropout: A simple way to prevent neural net- works from overfitting, Journal of Machine Learning Research 15 (1) (2014) 1929–1958
work page 2014
- [36]
-
[37]
G. Patrini, A. Rozza, et al., Making deep neural networks robust to label noise: A loss correction approach, in: IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 1944–1952
work page 2017
-
[38]
Y . Hou, Q. Ren, W. Wang, D. Botteldooren, Sound-based recognition of touch 34 gestures and emotions for enhanced human-robot interaction, in: IEEE Interna- tional Conference on Acoustics, Speech, and Signal Processing, 2025, pp. 1–5
work page 2025
-
[39]
B. Zhu, K. Xu, Q. Kong, H. Wang, Y . Peng, Audio tagging by cross filtering noisy labels, IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing 28 (2020) 2073–2083
work page 2020
-
[40]
Y . Gong, Y . Chung, J. Glass, AST: Audio Spectrogram Transformer, in: INTER- SPEECH, 2021, pp. 571–575
work page 2021
-
[41]
A. Nagrani, S. Yang, A. Arnab, A. Jansen, C. Schmid, C. Sun, Attention bot- tlenecks for multimodal fusion, in: Advances in Neural Information Processing Systems, V ol. 34, 2021, pp. 14200–14213
work page 2021
- [42]
-
[43]
S. Srivastava, Y . Wang, et al., Conformer-based self-supervised learning for non- speech audio tasks, in: IEEE International Conference on Acoustics, Speech, and Signal Processing, 2022, pp. 8862–8866
work page 2022
- [44]
-
[45]
S. Chen, Y . Wu, C. Wang, S. Liu, D. Tompkins, Z. Chen, W. Che, X. Yu, F. Wei, Beats: Audio pre-training with acoustic tokenizers, in: International Conference on Machine Learning, PMLR, 2023, pp. 5178–5193
work page 2023
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.