User Sentiment as a Success Metric: Persistent Biases Under Full Randomization
Pith reviewed 2026-05-25 15:38 UTC · model grok-4.3
The pith
Optional surveys in fully randomized A/B tests produce biased user sentiment estimates because response rates depend on both treatment and user covariates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
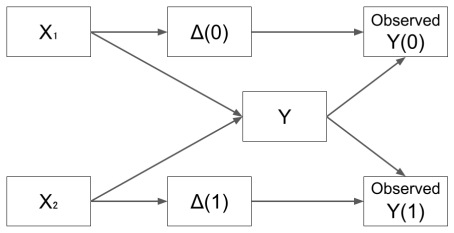
When sentiment is measured only among respondents in a fully randomized A/B test, the observed treatment effect on respondents is not in general equal to the average treatment effect on the treated; consistent estimators for both quantities exist once the problem is recognized as the intersection of a missing-data problem and an observational causal-inference problem, provided the relevant identification conditions hold.
What carries the argument
The explicit mapping of the optional-survey problem onto the intersection of missing-data and observational causal-inference frameworks, which supplies the identification conditions for consistent estimators of average and local treatment effects on treated and respondent users.
If this is right
- Average treatment effects on the treated can be recovered consistently from respondent sentiment data.
- Local treatment effects among respondents can be recovered consistently under the same identification conditions.
- Simpler estimators can achieve performance comparable to more complex models in finite samples.
- The bias from differential response persists even when treatment assignment is fully randomized.
Where Pith is reading between the lines
- The same mapping could be used to correct other optional feedback metrics such as ratings or open-text responses.
- Product teams that ignore response bias may systematically over- or under-estimate the impact of feature changes.
- Empirical checks for the identification conditions could be added as routine diagnostics in A/B testing platforms.
Load-bearing premise
The identification conditions that turn the missing-data-plus-causal-inference mapping into consistent estimators must actually be satisfied by the data-generating process.
What would settle it
An experiment or simulation in which response probability depends on treatment and covariates, the true treatment effects are known, and the proposed estimators fail to recover those known effects.
Figures







read the original abstract
We study user sentiment (reported via optional surveys) as a metric for fully randomized A/B tests. Both user-level covariates and treatment assignment can impact response propensity. We propose a set of consistent estimators for the average and local treatment effects on treated and respondent users. We show that our problem can be mapped onto the intersection of the missing data problem and observational causal inference, and we identify conditions under which consistent estimators exist. We evaluate the performance of estimators via simulation studies and find that more complicated models do not necessarily provide superior performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies biases in user sentiment (from optional surveys) as an outcome metric in fully randomized A/B tests, where both covariates and treatment can affect response propensity. It maps the problem to the intersection of missing-data and observational causal inference settings, proposes consistent estimators for average and local treatment effects on treated and respondent subpopulations, identifies conditions under which such estimators exist, and evaluates finite-sample performance via simulation studies.
Significance. If the identification argument holds, the work supplies a principled correction for non-response bias in a common industry metric. The mapping to established missing-data and causal-inference frameworks, together with the simulation evidence that simpler models can outperform more complex ones, would be a useful methodological contribution to the literature on survey non-response in randomized experiments.
minor comments (2)
- [Abstract] Abstract: the identification conditions are asserted but not summarized even at a high level; a one-sentence statement of the key assumptions (e.g., forms of missingness or ignorability) would make the central claim more immediately evaluable.
- [Simulation studies] The simulation section reports that 'more complicated models do not necessarily provide superior performance,' but does not specify the exact model classes compared or the metrics used to reach this conclusion; adding a short table or explicit list would strengthen the practical takeaway.
Simulated Author's Rebuttal
We thank the referee for the careful reading and positive evaluation of our manuscript. The referee's summary correctly identifies the core contributions: mapping the non-response problem in sentiment surveys to the intersection of missing-data and causal inference frameworks, deriving consistent estimators for ATE and LATE on treated and respondent subpopulations, and providing simulation evidence on estimator performance. We appreciate the recommendation for minor revision.
Circularity Check
No significant circularity detected
full rationale
The central claim maps the sentiment metric problem onto the intersection of missing-data and observational causal inference settings, then identifies conditions for consistent estimators of ATE/LATE on treated and respondent subpopulations. This relies on standard identification results from the external missing-data and causal-inference literature rather than any self-referential fitting, self-definition, or load-bearing self-citation chain. No equations or steps in the provided abstract reduce a prediction or estimator to its own inputs by construction; simulation results are presented only as supporting evidence, not as the proof of consistency. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditions exist under which consistent estimators for treatment effects on respondents and treated users can be identified from the intersection of missing data and causal inference frameworks.
Reference graph
Works this paper leans on
-
[1]
Anderson, E. W. Customer satisfaction and word of mouth. Journal of Service Research 1, 1 (1998), 5–17
work page 1998
-
[2]
Anderson, E. W., and Sullivan, M. W. The antecedents and conse- quences of customer satisfaction for firms. Marketing Science 12, 2 (1993), 125–143
work page 1993
-
[3]
Bang, H., and Robins, J. M. Doubly robust estimation in missing data and causal inference models. Biometrics 61, 4 (2005), 962–973
work page 2005
-
[4]
Brick, J. M., and Kalton, G. Handling missing data in survey research. Statistical methods in medical research 5 , 3 (1996), 215–238
work page 1996
-
[5]
Double/debiased machine learning for treatment and structural parameters
Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., and Robins, J. Double/debiased machine learning for treatment and structural parameters. The Econometrics Jour- nal 21, 1 (2018), C1–C68
work page 2018
-
[6]
de Leeuw, E. D. Counting and measuring online: The quality of in- ternet surveys. BMS: Bulletin of Sociological Methodology / Bulletin de Mthodologie Sociologique, 114 (2012), 68–78
work page 2012
-
[7]
The one number you need to grow
F Reichheld, F. The one number you need to grow. Harvard business review 81 (06 2004), 46–54, 124
work page 2004
-
[8]
Gustafsson, A., Johnson, M., and Roos, I. The effects of customer satisfaction, relationship commitment dimensions, and triggers on customer retention. Journal of Marketing - J MARKETING 69 (10 2005), 210–218
work page 2005
-
[9]
Hainmueller, J. Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies. Political Analysis 20, 1 (2012), 2546
work page 2012
-
[10]
Imbens, G. W., and Rubin, D. B. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction . Cambridge University Press, 2015
work page 2015
-
[11]
Compensating for missing survey data
Kalton, G. Compensating for missing survey data. Research report series. Survey Research Center, Institute for Social Research, the University of Michigan, 1983
work page 1983
-
[12]
Kalton, G., and Flores-Cervantes, I. Weighting methods. Journal of official statistics 19 , 2 (2003), 81
work page 2003
-
[13]
Kang, J. D. Y., and Schafer, J. L. Demystifying double robustness: A comparison of alternative strategies for estimating a population mean from incomplete data. Statist. Sci. 22 , 4 (11 2007), 523–539
work page 2007
-
[14]
Online controlled experiments at large scale
Kohavi, R., Deng, A., Frasca, B., W alker, T., Xu, Y., and Pohlmann, N. Online controlled experiments at large scale. In Proceed- 17 ings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, NY, USA, 2013), KDD ’13, ACM, pp. 1168–1176
work page 2013
-
[15]
Little, R. J. A., and Rubin, D. B. Statistical Analysis with Missing Data. John Wiley & Sons, Inc., New York, NY, USA, 1986
work page 1986
-
[16]
Morgan, N. A., Anderson, E. W., and Mittal, V. Understanding firms’ customer satisfaction information usage. Journal of Marketing 69 , 3 (2005), 131–151
work page 2005
-
[17]
Muller, H., and Sedley, A. Hats: Large-scale in-product measurement of user attitudes: Experiences with happiness tracking surveys. In Proceed- ings of the 26th Australian Computer-Human Interaction Conference on Designing Futures: The Future of Design (New York, NY, USA, 2014), OzCHI ’14, ACM, pp. 308–315
work page 2014
-
[18]
Measuring Customer Satisfaction: Hot Buttons and Other Measurement Issues
Myers, J. Measuring Customer Satisfaction: Hot Buttons and Other Measurement Issues. American Marketing Association, 1999
work page 1999
- [19]
-
[20]
Adversarial Bal- ancing for Causal Inference
Ozery-Flato, M., Thodoroff, P., and El-Hay, T. Adversarial Bal- ancing for Causal Inference. arXiv e-prints (Oct 2018), arXiv:1810.07406
-
[21]
Causality: Models, Reasoning and Inference, 2nd ed
Pearl, J. Causality: Models, Reasoning and Inference, 2nd ed. Cambridge University Press, New York, NY, USA, 2009
work page 2009
-
[22]
Rubin, D. B. Inference and missing data. Biometrika 63, 3 (1976), 581– 592
work page 1976
-
[23]
Overlapping experiment infrastructure: More, better, faster experimentation
Tang, D., Agarwal, A., O’Brien, D., and Meyer, M. Overlapping experiment infrastructure: More, better, faster experimentation. In Pro- ceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, NY, USA, 2010), KDD ’10, ACM, pp. 17–26
work page 2010
-
[24]
Anderson, E., Fornell, C., and T
W. Anderson, E., Fornell, C., and T. Rust, R. Customer sat- isfaction, productivity, and profitability: Differences between goods and services. Marketing Science 16 (05 1997), 129–145
work page 1997
-
[25]
From infrastructure to culture: A/b testing challenges in large scale social net- works
Xu, Y., Chen, N., Fernandez, A., Sinno, O., and Bhasin, A. From infrastructure to culture: A/b testing challenges in large scale social net- works. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, NY, USA, 2015), KDD ’15, ACM, pp. 2227–2236. 18 A Proof of Lemma 2 First recall that ATETR is de...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.