LinkNav: Surfacing Interconnected Information in Scientific Articles
Pith reviewed 2026-06-27 23:19 UTC · model grok-4.3
The pith
LinkNav uses a language model to generate questions from passages in academic papers and locate their answers in distant sections, surfacing connections that average ten segments apart.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
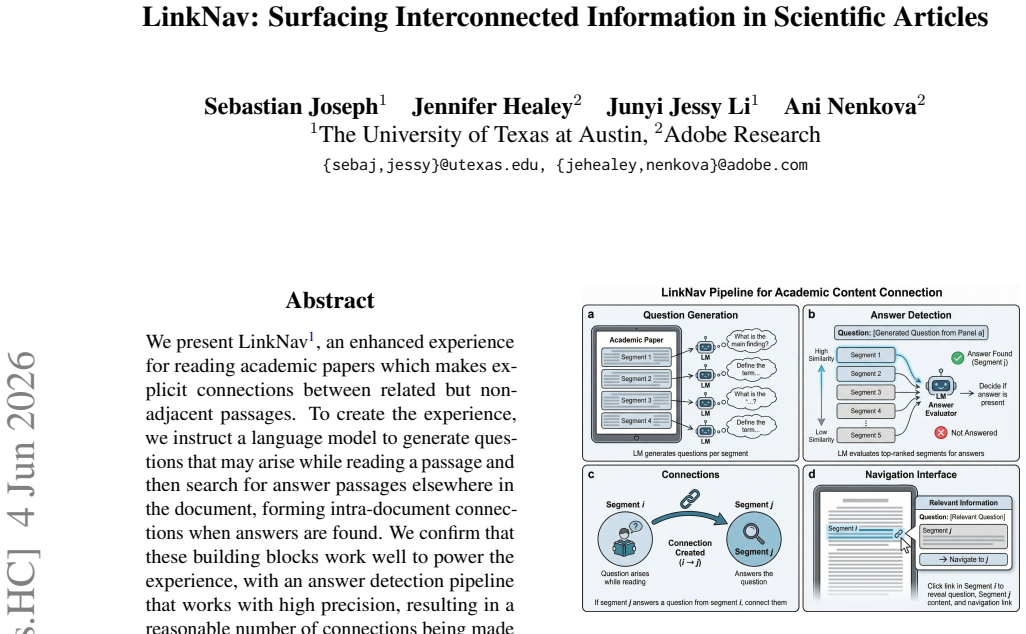
LinkNav instructs a language model to generate questions that may arise while reading a passage and then searches for answer passages elsewhere in the document, forming intra-document connections when answers are found. An answer detection pipeline operates with high precision and yields a reasonable number of connections per document. On a dataset of academic papers, connected passages are on average ten segments away from each other.
What carries the argument
Question-generation step that produces potential reader questions from a passage, followed by an answer-detection step that identifies matching passages elsewhere in the same document.
If this is right
- Readers gain access to connections between sections that are on average ten segments apart and would otherwise remain hidden.
- The question-and-answer pipeline produces enough valid links to create a usable navigation layer without overwhelming the document.
- Explicit links turn a linear text into a set of traversable relationships inside one paper.
- The same building blocks can be applied to any document where non-adjacent passages contain related content.
Where Pith is reading between the lines
- The approach could support new interfaces that let readers jump between related ideas rather than scrolling sequentially.
- Similar question-generation techniques might help surface connections across multiple papers or across different document types.
- If the links prove reliable, standard PDF and e-reader tools might eventually embed them by default.
Load-bearing premise
The questions created by the language model and the passages flagged as answers are both accurate and useful to actual human readers.
What would settle it
A study in which readers examine the generated links and judge most of them to be either factually wrong or already obvious from the surrounding text.
Figures
read the original abstract
We present LinkNav, an enhanced experience for reading academic papers which makes explicit connections between related but non-adjacent passages. To create the experience, we instruct a language model to generate questions that may arise while reading a passage and then search for answer passages elsewhere in the document, forming intra-document connections when answers are found. We confirm that these building blocks work well to power the experience, with an answer detection pipeline that works with high precision, resulting in a reasonable number of connections being made for a document. On a dataset of academic papers, we find that connected passages are on average ten segments away from each other, making explicit connections that a reader may have otherwise missed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents LinkNav, a reading interface for academic papers that uses an LLM to generate questions from a passage and then detects answer passages elsewhere in the same document to create explicit intra-document links. The central claims are that the answer-detection pipeline achieves high precision, that a reasonable number of connections are surfaced per document, and that on a dataset of papers the connected passages are on average ten segments apart, thereby surfacing links a reader might otherwise miss.
Significance. If the generated connections prove both accurate and useful to readers, the work could contribute a practical HCI technique for improving navigation and comprehension in long scientific documents. The approach of question-generation plus answer retrieval is straightforward and leverages existing LLM capabilities, but the absence of human validation leaves the claimed reader benefit unanchored.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the claim of 'high precision' for the answer detection pipeline is stated without any quantitative results, dataset size, error bars, baseline comparisons, or inter-annotator agreement; this directly undermines the assertion that the pipeline 'works well to power the experience.'
- [Abstract and §5] Abstract and §5 (Results/Discussion): the claim that connected passages are 'on average ten segments away' and 'making explicit connections that a reader may have otherwise missed' rests on automated metrics alone; no human evaluation, usefulness ratings, or user study is reported to support the HCI benefit or the 'may have otherwise missed' assertion.
minor comments (2)
- [§4] The manuscript should clarify the exact segmentation method used to compute 'segments' and report the total number of papers and segments in the evaluation dataset.
- [Figure 1] Figure captions and the system diagram would benefit from explicit labels indicating which components are LLM-driven versus rule-based.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, acknowledging where the manuscript requires strengthening and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the claim of 'high precision' for the answer detection pipeline is stated without any quantitative results, dataset size, error bars, baseline comparisons, or inter-annotator agreement; this directly undermines the assertion that the pipeline 'works well to power the experience.'
Authors: We agree the current text states 'high precision' without supporting numbers, dataset details, or comparisons. We will revise §4 to report the exact precision of the answer-detection pipeline, the number of papers and segments evaluated, any variance or error analysis performed, and relevant baselines. The abstract will be updated to reference these results. revision: yes
-
Referee: [Abstract and §5] Abstract and §5 (Results/Discussion): the claim that connected passages are 'on average ten segments away' and 'making explicit connections that a reader may have otherwise missed' rests on automated metrics alone; no human evaluation, usefulness ratings, or user study is reported to support the HCI benefit or the 'may have otherwise missed' assertion.
Authors: The reported average distance and connection counts are derived solely from automated segment analysis. We acknowledge that this does not directly demonstrate reader benefit or that connections would otherwise be missed. We will revise the abstract and §5 to qualify these claims as automated observations, add an explicit limitations paragraph, and include future-work discussion of planned human validation studies. revision: partial
Circularity Check
No circularity: empirical system description with no derivations or fitted predictions
full rationale
The paper presents LinkNav as a system that uses an LLM to generate questions from passages and detect answers elsewhere in the document to form intra-document links. The central empirical claim (connected passages average ten segments apart) is a direct measurement on a dataset of papers, not a model prediction derived from fitted parameters or prior self-citations. No equations, ansatzes, uniqueness theorems, or self-referential definitions appear. The pipeline is described as a sequence of LLM calls and detection steps whose outputs are evaluated for precision on held-out data; these steps do not reduce to tautologies or rename their own inputs. The absence of human evaluation noted by the skeptic is a question of external validity, not circularity in the reported chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yuan Chang, Ziyue Li, Hengyuan Zhang, Yuanbo Kong, Yanru Wu, Zhijiang Guo, and Ngai Wong
Peerqa: A scientific question an- swering dataset from peer reviews.Preprint, arXiv:2502.13668. Yuan Chang, Ziyue Li, Hengyuan Zhang, Yuanbo Kong, Yanru Wu, Zhijiang Guo, and Ngai Wong
-
[2]
Treereview: A dynamic tree of questions framework for deep and efficient llm-based scientific peer review. Preprint, arXiv:2506.07642. Jeremy R. Cole, Palak Jain, Julian Martin Eisensch- los, Michael J.Q. Zhang, Eunsol Choi, and Bhuwan Dhingra
-
[3]
Andrew Head, Kyle Lo, Dongyeop Kang, Raymond Fok, Sam Skjonsberg, Daniel S
Qlarify: Re- cursively expandable abstracts for directed infor- mation retrieval over scientific papers.Preprint, arXiv:2310.07581. Andrew Head, Kyle Lo, Dongyeop Kang, Raymond Fok, Sam Skjonsberg, Daniel S. Weld, and Marti A. Hearst
-
[4]
InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems, CHI ’21, New York, NY , USA
Augmenting scientific papers with just- in-time, position-sensitive definitions of terms and symbols. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems, CHI ’21, New York, NY , USA. Association for Computing Machinery. Baorong Huang, Juhua Dou, and Hai Zhao
2021
-
[5]
InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6544–6555, Online
Inquisitive question gener- ation for high level text comprehension. InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6544–6555, Online. Association for Computational Linguistics. Wei-Jen Ko, Cutter Dalton, Mark Simmons, Eliza Fisher, Greg Durrett, and Junyi Jessy Li
2020
-
[6]
InProceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11752–11764, Abu Dhabi, United Arab Emirates
Dis- course comprehension: A question answering frame- work to represent sentence connections. InProceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11752–11764, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Yoonjoo Lee, Nedim Lipka, Zichao Wang, Ryan Rossi, Puneet Mathur, Tong Sun,...
2022
-
[7]
InProceedings of the Tenth In- ternational Conference on Language Resources and Evaluation (LREC 2016), Paris, France
Improving the annotation of sentence specificity. InProceedings of the Tenth In- ternational Conference on Language Resources and Evaluation (LREC 2016), Paris, France. European Language Resources Association (ELRA). Zihao Lin, Zichao Wang, Yuanting Pan, Varun Man- junatha, Ryan Rossi, Angela Lau, Lifu Huang, and Tong Sun
2016
-
[8]
Kyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X
Persona-sq: A personalized sug- gested question generation framework for real-world documents.Preprint, arXiv:2412.12445. Kyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X. Zhang, Cassidy Trier, Chloe Anas- tasiades, Tal August, Russell Authur, Danielle Bragg, Erin Bransom, Isabel Cachola, Stefan Candra, Yo- ganand Chandrasekhar, Yen-Sung Che...
-
[9]
Kyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X
The semantic reader project: Augmenting scholarly documents through ai-powered interactive reading interfaces.Preprint, arXiv:2303.14334. Kyle Lo, Joseph Chee Chang, Andrew Head, Jonathan Bragg, Amy X. Zhang, Cassidy Trier, Chloe Anas- tasiades, Tal August, Russell Authur, Danielle Bragg, Erin Bransom, Isabel Cachola, Stefan Candra, Yo- ganand Chandrasekh...
-
[10]
InProceedings of the 2004 Con- ference on Empirical Methods in Natural Language Processing, pages 404–411, Barcelona, Spain
TextRank: Bring- ing order into text. InProceedings of the 2004 Con- ference on Empirical Methods in Natural Language Processing, pages 404–411, Barcelona, Spain. Asso- ciation for Computational Linguistics. Roni Rabin, Alexandre Djerbetian, Roee Engelberg, Lidan Hackmon, Gal Elidan, Reut Tsarfaty, and Amir Globerson
2004
-
[11]
Infolossqa: Characterizing and recovering information loss in text simplification. Preprint, arXiv:2401.16475. Siyuan Wang, Zhongyu Wei, Zhihao Fan, Yang Liu, and Xuanjing Huang
-
[12]
InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Pro- cessing, pages 19969–19987, Miami, Florida, USA
Which ques- tions should I answer? salience prediction of inquis- itive questions. InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Pro- cessing, pages 19969–19987, Miami, Florida, USA. Association for Computational Linguistics. Yating Wu, Ritika Mangla, Greg Durrett, and Junyi Jessy Li
2024
-
[13]
follow_up_questions
QUDeval: The evaluation of questions under discussion discourse parsing. InPro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 5344– 5363, Singapore. Association for Computational Lin- guistics. 8 A Question Generation Prompt Prompt A System: You are logical, intelligent, insightful, precise, and can understan...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.