Joycent: Diffusion-based Accent TTS without Accented Phone Prediction
Pith reviewed 2026-06-27 03:12 UTC · model grok-4.3
The pith
Joycent generates accented speech directly from standard phone sequences and speech references using a diffusion model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
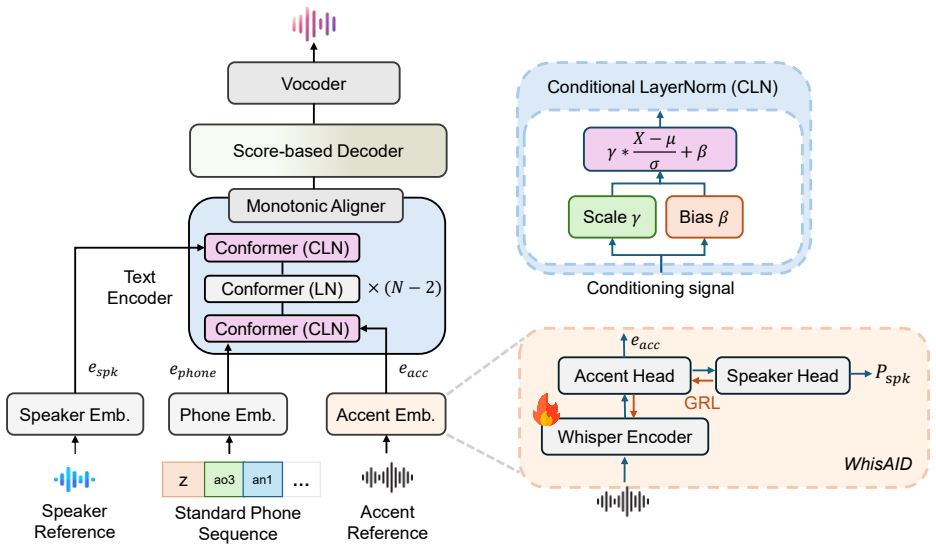
Joycent synthesizes accented speech directly from standard phone sequences and speech references by conditioning a diffusion model on accent and speaker representations that are integrated through conditional layer normalization in the text encoder, with accent features supplied by WhisAID, thereby eliminating the accented phone prediction step and its associated error accumulation.
What carries the argument
Conditional layer normalization (CLN) in the text encoder together with accent representations from WhisAID, which injects accent information into the diffusion synthesis process without requiring an explicit accented-phone conversion stage.
If this is right
- The method removes dependence on scarce paired standard-to-accented phone sequence data.
- Error accumulation from separate phone conversion and synthesis stages is avoided.
- Acoustic accent features such as prosody and rhythm can be modeled directly through conditioning rather than text phone sequences.
- Speaker identity remains preserved while accentedness improves over baseline systems.
Where Pith is reading between the lines
- The same conditioning approach could be tested on non-Mandarin accents to check cross-language applicability.
- Removing the separate accent identification model might allow fully joint training of accent and synthesis components.
- The direct synthesis route opens questions about whether similar bypasses work for other speech attributes like emotion or dialect.
Load-bearing premise
That accent and speaker representations integrated through conditional layer normalization and WhisAID features can capture acoustic accent traits such as prosody and rhythm without any explicit accented phone conversion.
What would settle it
A listening test or acoustic analysis in which Joycent output shows no improvement or a decline in accent accuracy or prosody match relative to two-stage baseline systems on the same test set.
Figures
read the original abstract
Accent text-to-speech (TTS) aims to synthesize speech with target accents. Existing accent TTS systems typically rely on a two-stage pipeline that first converts standard phone sequences into accented phone sequences and then synthesizes accented speech. However, such approaches suffer from error accumulation and require paired standard-accented phone sequence data, which is often limited in practice. Moreover, text-based accented phone representations are insufficient to model acoustic accent characteristics such as prosody and rhythm. In this work, we propose Joycent, a diffusion-based accent TTS model that synthesizes accented speech directly from standard phone sequences and speech references without accented phone prediction. Joycent integrates accent and speaker representations through conditional layer normalization (CLN) in the text encoder. We introduce WhisAID, a Mandarin accent identification model trained on accented Mandarin speech to extract accent representations. Experimental results show that Joycent improves accentedness while preserving speaker identity compared with baseline systems. We release our code and demos at: https://github.com/oshindow/Joycent-code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Joycent, a diffusion-based accent TTS model that synthesizes accented speech directly from standard phone sequences and speech references without requiring accented phone prediction. It integrates accent and speaker representations via conditional layer normalization (CLN) in the text encoder and introduces WhisAID, a Mandarin accent identification model trained on accented speech, to extract accent representations. The central claim is that experimental results demonstrate improved accentedness while preserving speaker identity relative to baseline systems.
Significance. If the results hold, the approach could simplify accent TTS by eliminating error accumulation in two-stage pipelines and the need for paired standard-accented phone data, while better capturing acoustic features such as prosody and rhythm through direct diffusion modeling and conditional normalization. The public release of code and demos supports reproducibility.
major comments (2)
- [Experiments] Experiments section: the abstract asserts that experiments show improvement in accentedness while preserving speaker identity, but supplies no dataset sizes, baseline descriptions, metrics, statistical tests, or ablation results. This absence prevents verification of whether the data support the central claim.
- [Method] Method section: the claim that integrating accent and speaker representations through CLN in the text encoder together with accent features from WhisAID is sufficient to capture acoustic accent characteristics (prosody, rhythm) without explicit accented-phone conversion lacks supporting ablation studies or analysis to establish sufficiency.
minor comments (1)
- The abstract notes the release of code and demos at a GitHub repository, which is a positive contribution for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract asserts that experiments show improvement in accentedness while preserving speaker identity, but supplies no dataset sizes, baseline descriptions, metrics, statistical tests, or ablation results. This absence prevents verification of whether the data support the central claim.
Authors: We agree that the experiments section in the submitted manuscript lacks the necessary details on dataset sizes, baseline descriptions, metrics, statistical tests, and ablation results. In the revised version, we will expand this section to include all of these elements, with explicit reporting of dataset statistics, full baseline specifications, evaluation metrics, any statistical significance tests performed, and ablation studies to allow verification of the central claims. revision: yes
-
Referee: [Method] Method section: the claim that integrating accent and speaker representations through CLN in the text encoder together with accent features from WhisAID is sufficient to capture acoustic accent characteristics (prosody, rhythm) without explicit accented-phone conversion lacks supporting ablation studies or analysis to establish sufficiency.
Authors: The referee is correct that the current manuscript does not include ablation studies or additional analysis to substantiate the sufficiency of the CLN-based integration and WhisAID features for modeling acoustic accent characteristics. We will add targeted ablation experiments and analysis in the revised manuscript to demonstrate the individual and combined contributions of these components to prosody, rhythm, and overall accentedness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a diffusion-based TTS architecture that directly maps standard phone sequences plus speech references to accented output via conditional layer normalization in the text encoder and accent embeddings extracted by a separately trained WhisAID model. No equations, parameter-fitting steps, or self-citations are supplied that would reduce any claimed prediction or uniqueness result to an input by construction. The central modeling choice (avoiding explicit accented-phone conversion) is presented as an architectural decision justified by the limitations of prior two-stage pipelines, not by any self-referential derivation or renamed empirical pattern. The reported improvements are therefore external to the model definition itself.
Axiom & Free-Parameter Ledger
invented entities (1)
-
WhisAID
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wanget al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wanget al., “Neural codec language models are zero-shot text to speech synthesizers,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 705–718, 2025
2025
-
[3]
Grad-tts: A diffusion probabilistic model for text-to-speech,
V . Popov, I. V ovket al., “Grad-tts: A diffusion probabilistic model for text-to-speech,” inProc. ICML, 2021, pp. 8599–8608
2021
-
[4]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wanget al., “Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” inProc. ICML, 2024
2024
-
[5]
Indextts: An industrial- level controllable and efficient zero-shot text-to-speech system,
W. Deng, S. Zhou, J. Shu, J. Wang, and W. Lu, “Indextts: An industrial- level controllable and efficient zero-shot text-to-speech system,”arXiv preprint arXiv:2502.05512, 2025
-
[6]
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Denget al., “Indextts2: A breakthrough in emotionally expressive and duration-controlled auto- regressive zero-shot text-to-speech,”arXiv preprint arXiv:2506.21619, 2025
-
[7]
Maskgct: Zero-shot text-to-speech with masked generative codec transformer,
Y . Wang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zhenget al., “Maskgct: Zero-shot text-to-speech with masked generative codec transformer,” in Proc. ICLR, 2025
2025
-
[8]
Macst: Multi-accent speech synthesis via text transliteration for accent conversion,
S. Inoue, S. Wanget al., “Macst: Multi-accent speech synthesis via text transliteration for accent conversion,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[9]
Accent-vits:accent transfer for end-to-end tts,
L. Ma, Y . Zhanget al., “Accent-vits:accent transfer for end-to-end tts,” arXiv preprint arXiv: 2312.16850, 2023
-
[10]
L2-GEN: A Neural Phoneme Paraphrasing Approach to L2 Speech Synthesis for Mispronunciation Diagnosis,
D. Zhang, A. Ganesan, S. Campbell, and D. Korzekwa, “L2-GEN: A Neural Phoneme Paraphrasing Approach to L2 Speech Synthesis for Mispronunciation Diagnosis,” inProc. Interspeech, 2022, pp. 4317– 4321
2022
-
[11]
Few-Shot Synthetic Accented Speech for ASR Fine-Tuning: What Helps and When?
Y . Halychanskyi, N. B. Bozdag, M. Hasegawa-Johnson, D. Hakkani-T¨ur, and V . Kindratenko, “Few-shot accent synthesis for asr with llm-guided phoneme editing,”arXiv preprint arXiv: 2604.27273, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Scalable controllable accented tts,
H. L. Xinyuan, Z. Cai, A. Garg, K. Duh, L. P. Garc’ia-Perera, S. Khu- danpur, N. Andrews, and M. Wiesner, “Scalable controllable accented tts,” inProc. ASRU, 2025, pp. 1–8
2025
-
[13]
Controllable accented text-to- speech synthesis with fine and coarse-grained intensity rendering,
R. Liu, B. Sisman, G. Gao, and H. Li, “Controllable accented text-to- speech synthesis with fine and coarse-grained intensity rendering,”IEEE Transactions on Audio, Speech and Language Processing, vol. 32, pp. 2188–2201, 2024
2024
-
[14]
DART: disentanglement of accent and speaker representation in multispeaker text-to-speech,
J. Melechovsk ´y, A. Mehrish, B. Sisman, and D. Herremans, “DART: disentanglement of accent and speaker representation in multispeaker text-to-speech,”arXiv preprint arXiv: 2410.13342, 2024
-
[15]
RAD-MMM: Multilingual Multiaccented Multispeaker Text To Speech,
R. Badlani, R. Valle, K. J. Shih, J. F. Santos, S. Gururani, and B. Catanzaro, “RAD-MMM: Multilingual Multiaccented Multispeaker Text To Speech,” inProc. Interspeech, 2023, pp. 626–630
2023
-
[16]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kimet al., “Robust speech recognition via large-scale weak supervision,” inProc. ICML, vol. 202, 2023, pp. 28 492–28 518
2023
-
[17]
Unsupervised domain adaptation by backpropagation,
Y . Ganin and V . S. Lempitsky, “Unsupervised domain adaptation by backpropagation,” inProc. ICML, 2015, pp. 1180–1189
2015
-
[18]
Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yanget al., “Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions,” inProc. ICASSP, 2018, pp. 4779–4783
2018
-
[19]
Adaspeech: Adaptive text to speech for custom voice,
M. Chen, X. Tanet al., “Adaspeech: Adaptive text to speech for custom voice,” inProc. ICLR, 2021
2021
-
[20]
Glow-tts: A generative flow for text-to-speech via monotonic alignment search,
J. Kim, S. Kim, J. Kong, and S. Yoon, “Glow-tts: A generative flow for text-to-speech via monotonic alignment search,” inProc. NeurIPS, 2020
2020
-
[21]
Con- former: Convolution-augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yuet al., “Con- former: Convolution-augmented Transformer for Speech Recognition,” inProc. Interspeech, 2020, pp. 5036–5040
2020
-
[22]
Accentbox: Towards high- fidelity zero-shot accent generation,
J. Zhong, K. Richmond, Z. Su, and S. Sun, “Accentbox: Towards high- fidelity zero-shot accent generation,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[23]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),”arXiv preprint arXiv: 1606.08415, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inProc. NeurIPS, 2020
2020
-
[25]
Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi- resolution spectrogram,
R. Yamamoto, E. Song, and J. Kim, “Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi- resolution spectrogram,” inProc. ICASSP, 2020, pp. 6199–6203
2020
-
[26]
AISHELL-3: A multi-speaker mandarin TTS corpus,
Y . Shi, H. Buet al., “AISHELL-3: A multi-speaker mandarin TTS corpus,” inProc. Interspeech, 2021, pp. 2756–2760
2021
-
[27]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2019
2019
-
[28]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inProc. ICLR, 2015
2015
-
[29]
Amphion: An open-source audio, music and speech generation toolkit,
X. Zhang, L. Xue, Y . Gu, Y . Wang, J. Li, H. Heet al., “Amphion: An open-source audio, music and speech generation toolkit,” inProc. SLT, 2024
2024
-
[30]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proc. NeurIPS, vol. 33, 2020, pp. 12 449–12 460
2020
-
[31]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wanget al., “Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training,” arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.