SingFox: A Multi-Lingual Singfake Detection Corpus
Pith reviewed 2026-06-26 19:27 UTC · model grok-4.3
The pith
SingFox supplies a 113k-clip multi-lingual corpus in six tracks to benchmark singing deepfake detection and source verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
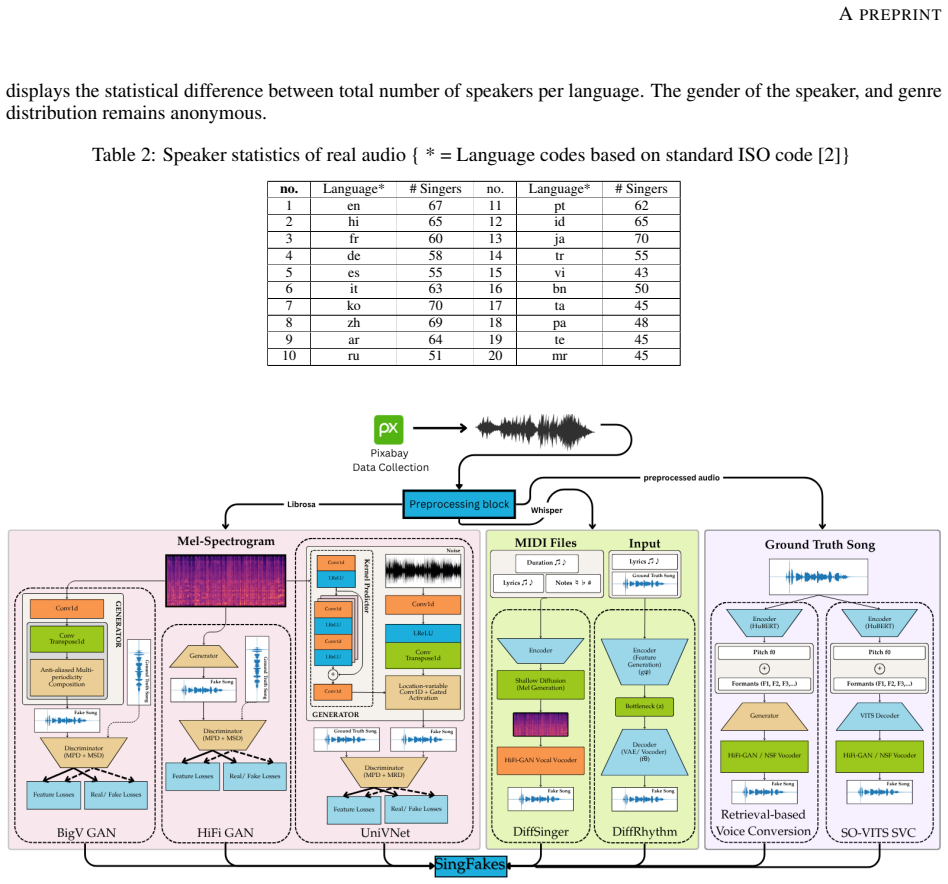
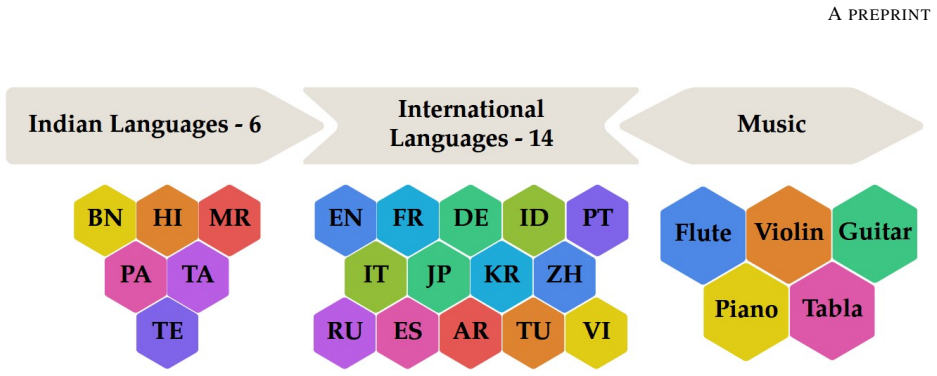
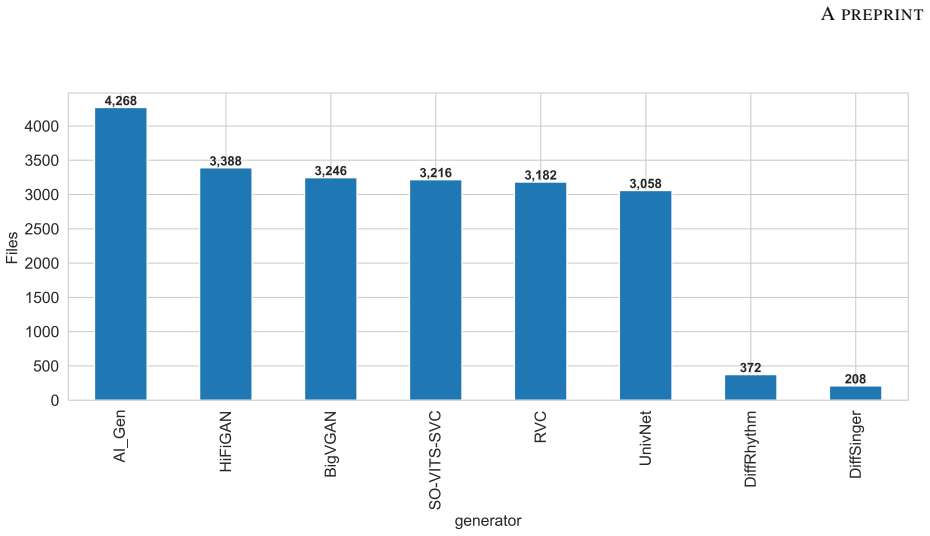
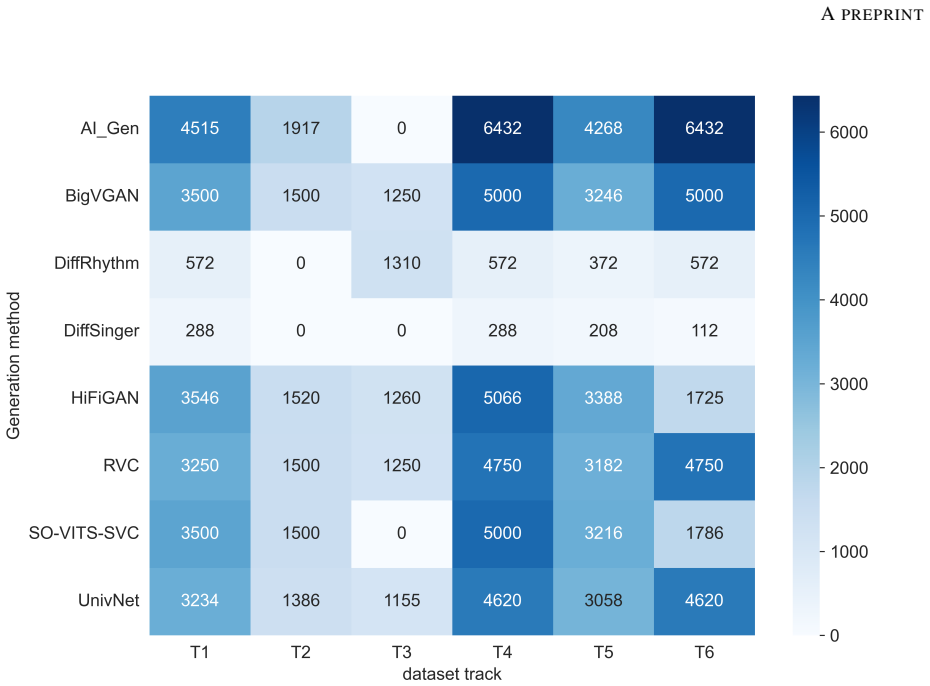
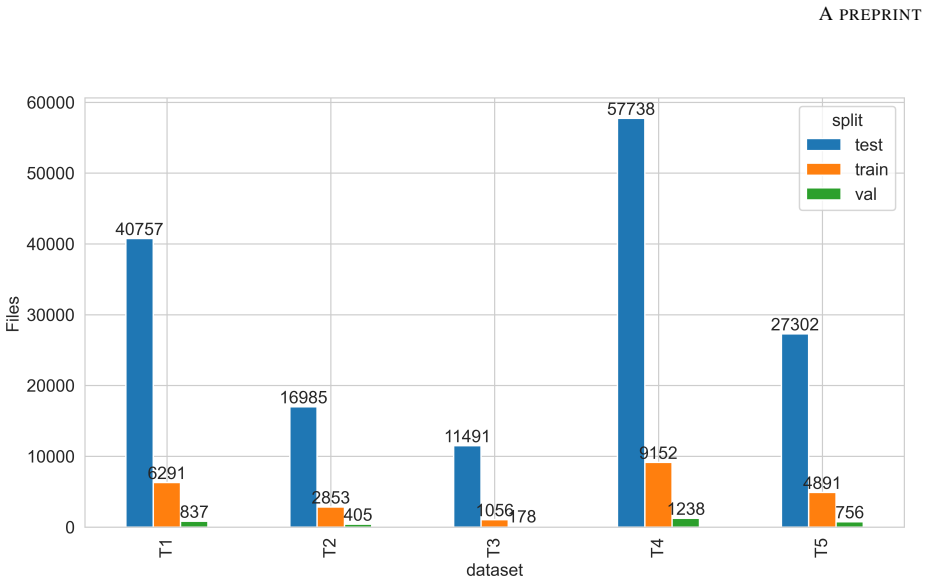
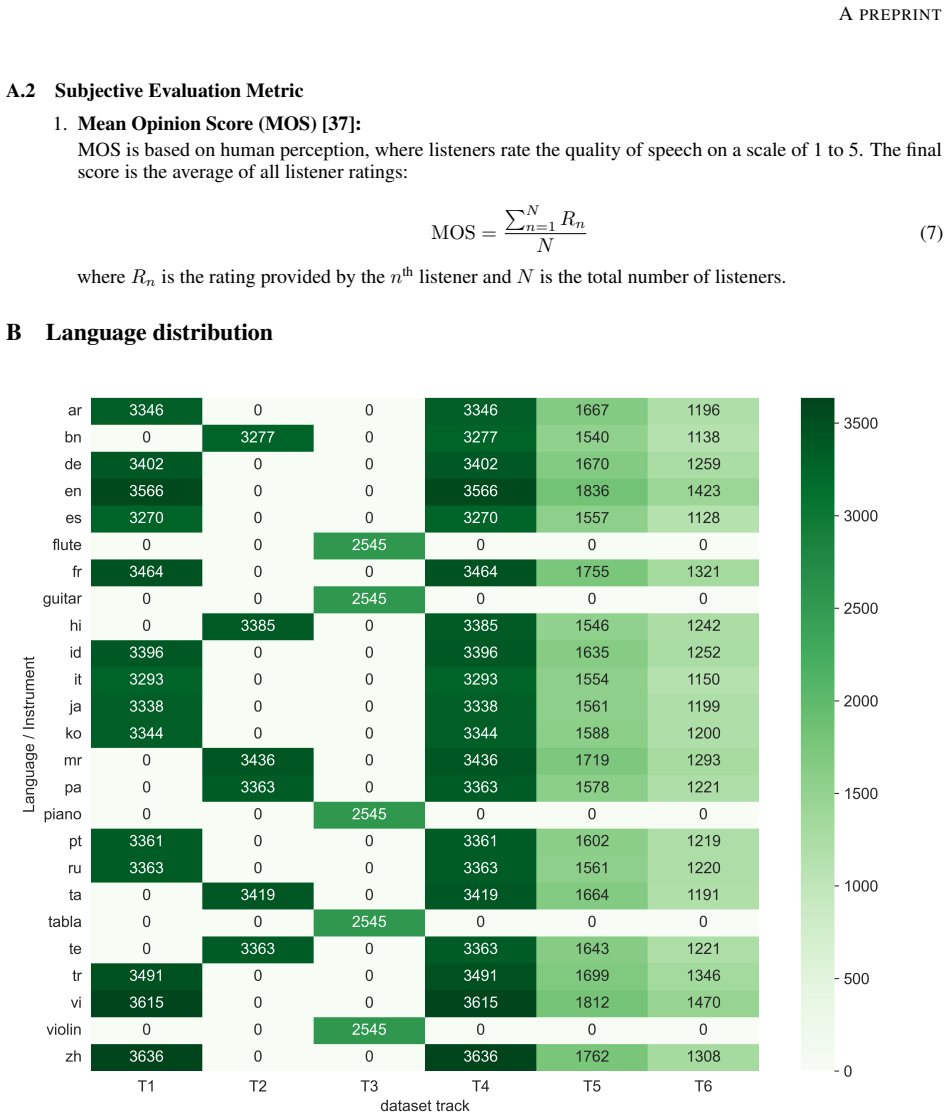
SingFox is a comprehensive dataset encompassing 113,802 audio clips across 20 languages and 1,150 singers, organized into six tracks that target specific novelties in language diversity, genre-specific music, and alternative fake generation methods to evaluate model robustness in singing deepfake detection and source verification.
What carries the argument
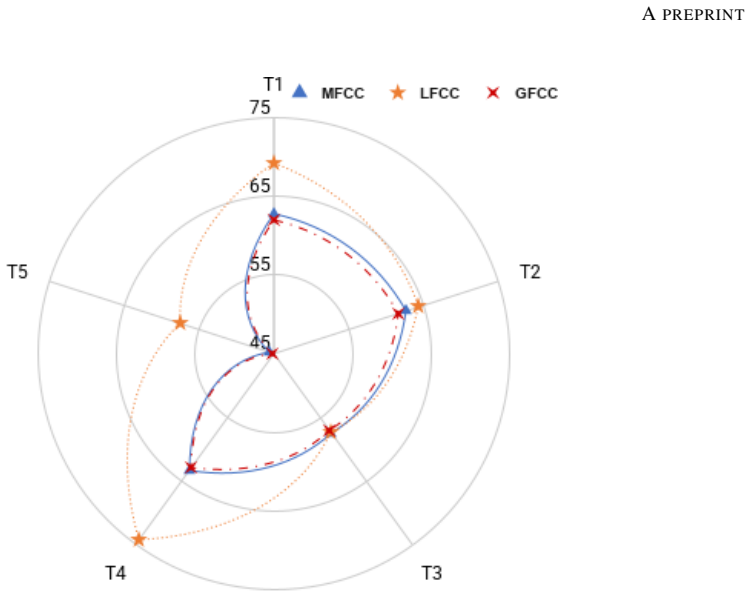
The SingFox dataset divided into six tracks (T1-T6), each targeting a unique form of novelty to emulate real-world scenarios for detection and source verification.
If this is right
- Detection models can be evaluated for performance across global and Indian language sets.
- Robustness can be measured on genre-specific music and on alternative fake-generation techniques.
- The source-verification track enables studies of model explainability alongside detection accuracy.
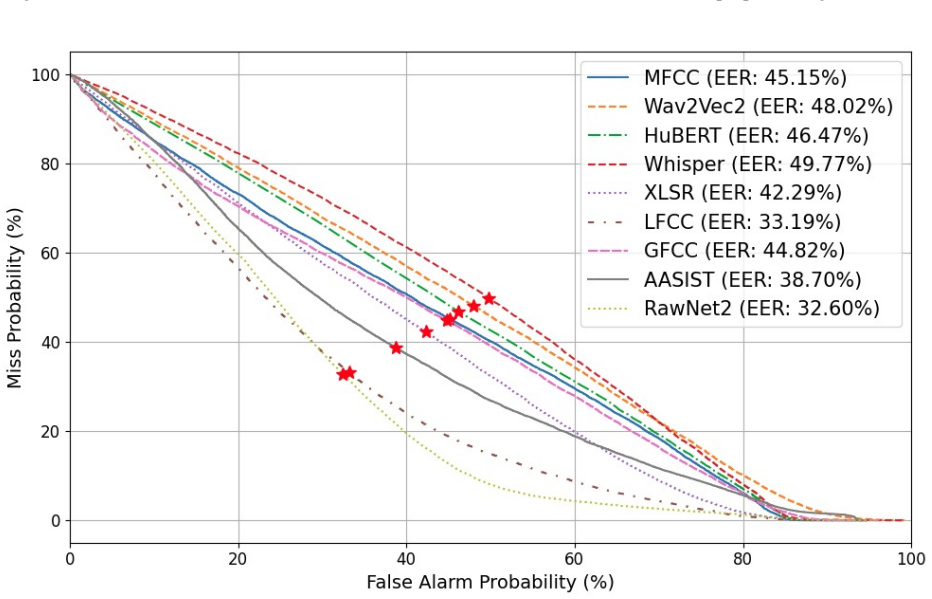
- Public release of the full dataset and code supports direct reproduction of the 77.84 percent cross-dataset result.
Where Pith is reading between the lines
- Models that succeed on SingFox may still require additional data from outside the six tracks to handle entirely new singing styles.
- The multi-lingual coverage could expose language-specific weaknesses in existing deepfake detectors that were trained mostly on English material.
- Researchers could extend the tracks with new genres or languages while reusing the same evaluation protocol.
- The source-verification task opens a route to studying which acoustic features models rely on when they label a clip as fake.
Load-bearing premise
The six tracks sufficiently emulate real-world scenarios to assess model robustness.
What would settle it
A controlled test in which models trained and evaluated on SingFox show low accuracy on newly recorded singing deepfakes drawn from languages or genres outside the six tracks would indicate the benchmark does not capture the claimed robustness.
Figures



read the original abstract
In this work, we introduce SingFox, a comprehensive and large-scale dataset specifically designed to support robust evaluation of singing deepfake detection and source tracing systems. SingFox is divided into six distinct tracks (T1--T6), each targeting a unique form of novelty, ranging from language diversity (global and Indian) to genre-specific music and alternative fake generation methods. The dataset encompasses over 113,802 audio clips across 20 languages, totaling more than 126.32 hours of audio data and featuring 1,150 singers. Each track is designed to emulate real-world scenarios and evaluate how reliably models perform under different conditions, thereby assessing their robustness. SingFox aims to foster reproducibility and accelerate research in singing deepfake detection by providing a reliable benchmark for both the singfake detection task and the source verification task (model explainability). Experimental results show a highest accuracy of 77.84\% in cross-dataset evaluation settings. All code and resources required to reproduce the dataset are publicly available at https://github.com/Arth-Shah/SingFox.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SingFox, a large-scale multi-lingual dataset for singing deepfake detection and source tracing, comprising over 113,802 audio clips (126.32 hours) from 1,150 singers across 20 languages. It is organized into six tracks (T1–T6) targeting language diversity, genre-specific music, and alternative fake generation methods, each intended to emulate real-world conditions for assessing model robustness. The work positions the dataset as a reproducible benchmark for both detection and source verification tasks, reports a peak cross-dataset accuracy of 77.84%, and releases all code and resources publicly.
Significance. If the tracks validly represent real-world distributions and failure modes, the dataset release—with its scale, language coverage, and public reproducibility artifacts—would provide a valuable standardized benchmark that could accelerate progress in singing deepfake detection research.
major comments (2)
- [Abstract] Abstract: The claim that the six tracks 'emulate real-world scenarios' and thereby 'assess their robustness' is load-bearing for the central contribution, yet the manuscript supplies no quantitative validation (e.g., distributional statistics, expert listening tests, or comparison against external real-world corpora) to support this emulation.
- [Abstract] Experimental results paragraph: The reported 77.84% cross-dataset accuracy is presented without model architecture, training protocol, data splits, or confidence intervals, preventing assessment of whether the number actually demonstrates the benchmark's utility for robustness evaluation.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence summary of the models or baselines used to obtain the 77.84% figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing SingFox. We address each major comment point-by-point below. We agree that the abstract requires strengthening for the claims made and will revise accordingly to improve clarity and support.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the six tracks 'emulate real-world scenarios' and thereby 'assess their robustness' is load-bearing for the central contribution, yet the manuscript supplies no quantitative validation (e.g., distributional statistics, expert listening tests, or comparison against external real-world corpora) to support this emulation.
Authors: We acknowledge that the abstract's phrasing regarding emulation of real-world scenarios would be strengthened by explicit quantitative support. The tracks are constructed to target documented real-world challenges (language diversity, genre shifts, and alternative generation methods), as described in the dataset construction sections. However, we agree that additional validation is warranted. In the revised manuscript, we will add distributional statistics comparing track characteristics to external real-world singing corpora and, where feasible, expert listening test results to substantiate the design choices. revision: yes
-
Referee: [Abstract] Experimental results paragraph: The reported 77.84% cross-dataset accuracy is presented without model architecture, training protocol, data splits, or confidence intervals, preventing assessment of whether the number actually demonstrates the benchmark's utility for robustness evaluation.
Authors: The abstract summarizes the peak result at a high level, while the full manuscript details the model architectures, training protocols, data splits, and evaluation methodology in the Experiments section. To address the concern about self-containment, we will revise the abstract to include brief references to these elements and report confidence intervals for the accuracy figures in the updated version. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a dataset release paper whose central contribution is the introduction of SingFox with six tracks, data statistics, and reported cross-dataset accuracy. No equations, derivations, fitted parameters, or mathematical claims appear in the provided abstract or description. The experimental result (77.84% accuracy) is presented as an empirical observation rather than a derived prediction from internal inputs. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The derivation chain is empty by nature of the contribution type, making internal circularity impossible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benesty, J
J. Benesty, J. Chen, Y . Huang, and I. Cohen. Pearson Correlation Coefficient. InNoise Reduction in Speech Processing, pages 1–4. Springer, 2009
2009
-
[2]
J. D. Byrum. Iso 639-1 and iso 639-2: International standards for language codes. iso 15924: International standard for names of scripts. InIFLA Council and General Conference. ERIC, 1999, Bangkok, Thailand
1999
- [3]
-
[4]
X. Chen, H. Wu, R. Jang, and H.-y. Lee. Singing voice graph modeling for singfake detection. InINTERSPEECH, pages 4843–4847, 2024, Kos Island, Greece
2024
-
[5]
M. Chhibber, J. Mishra, and T. H. Kinnunen. Advancing zero-shot open-set speech deepfake source tracing.arXiv preprint arXiv:2509.24674, 2025, {Last Accessed:27 thF ebruary,2026}
Pith/arXiv arXiv 2025
-
[6]
K. Cho, B. Van Merriënboer, Ç. Gulçehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724–1734, 2014, Doha, Qatar
2014
-
[7]
Comanducci, P
L. Comanducci, P. Bestagini, and S. Tubaro. Fakemusiccaps: A dataset for detection and attribution of synthetic music generated via text-to-music models.Journal of Imaging, 11(7):242, 2025
2025
-
[8]
Davis and P
S. Davis and P. Mermelstein. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences.IEEE Transactions on Acoustics, Speech, and Signal Processing, 28(4):357–366, 1980. 12 APREPRINT
1980
-
[9]
A. Firc, M. Chhibber, J. Mishra, V . Pratap Singh, T. Kinnunen, and K. Malinka. STOPA: A dataset of systematic variation of deepfake audio for open-set source tracing and attribution. InINTERSPEECH, pages 1553–1557, 2025, Rotterdam, Netherlands
2025
-
[10]
J. Han, E. Yang, and U. Oh. Understanding the use of AI-based audio generation models by end-users. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, volume 355, pages 1–7. ACM, 2024, Hamburg, Germany
2024
-
[11]
Hermansky and N
H. Hermansky and N. Morgan. RASTA processing of speech.IEEE Transactions on Speech and Audio Processing, 2(4):578–589, 2002
2002
-
[12]
Y . Hong, J. Feng, H. Chen, J. Lan, H. Zhu, W. Wang, and J. Zhang. Wildfake: A large-scale and hierarchical dataset for AI-generated images detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 3500–3508, 2025, Philadelphia, Pennsylvania, USA
2025
-
[13]
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
2021
-
[14]
Huang, J
Z. Huang, J. Hu, X. Li, Y . He, X. Zhao, B. Peng, B. Wu, X. Huang, and G. Cheng. SIDA: Social media image deepfake detection, localization, and explanation with large multimodal model. InComputer Vision and Pattern Recognition Conference (CVPR), pages 28831–28841, 2025, Nashville, Tennessee, USA
2025
-
[15]
Ito and L
K. Ito and L. Johnson. The LJ Speech dataset. https://keithito.com/LJ-Speech-Dataset/, 2017. {Last Accessed:3 rd March, 2026}
2017
-
[16]
W. Jang, D. Lim, J. Yoon, B. Kim, and J. Kim. UnivNet: A neural vocoder with multi-resolution spectrogram discriminators for high-fidelity waveform generation. InINTERSPEECH, pages 2207–2211, 2021, Brno, Czechia
2021
-
[17]
J.-w. Jung, Y . Wu, X. Wang, J.-H. Kim, S. Maiti, Y . Matsunaga, H.-j. Shim, J. Tian, N. Evans, J. S. Chung, et al. SpoofCeleb: Speech deepfake detection and SASV in the wild.IEEE Open Journal of Signal Processing, 6:68–77, 2025
2025
-
[18]
Klein, T
N. Klein, T. Chen, H. Tak, R. Casal, and E. Khoury. Source tracing of audio deepfake systems. InINTERSPEECH, pages 1100–1104, 2024, Kos Island, Greece
2024
-
[19]
J. Kong, J. Kim, and J. Bae. HiFi-GAN: Generative adversarial networks for efficient and high-fidelity speech synthesis.Advances in Neural Information Processing Systems (NIPS), Virtual, 33:17022–17033, 2020
2020
-
[20]
Kubichek
R. Kubichek. Mel cepstral distance measure for objective speech quality assessment. InIEEE Pacific Rim Conference on Communications Computers and Signal Processing (PACRIM), volume 1, pages 125–128, 1993, Victoria, BC, Canada
1993
-
[21]
LeCun, Y
Y . LeCun, Y . Bengio, and G. Hinton. Deep learning.Nature, 521(7553):436–444, 2015
2015
-
[22]
S. G. Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon. BigVGAN: A universal neural vocoder with large-scale training. In 11th International Conference on Learning Representations (ICLR), Kigali, Rwanda, 2023
2023
-
[23]
M. Li, Y . Ahmadiadli, and X.-P. Zhang. A survey on speech deepfake detection.ACM Computing Surveys, 57(7):1–38, 2025
2025
-
[24]
J. Liu, C. Li, Y . Ren, F. Chen, and Z. Zhao. Diffsinger: Singing voice synthesis via shallow diffusion mechanism. InAAAI conference on Artificial Intelligence, volume 36, pages 11020–11028, 2022, (Virtual) USA
2022
-
[25]
X. Liu, X. Wang, M. Sahidullah, J. Patino, H. Delgado, T. Kinnunen, M. Todisco, J. Yamagishi, N. Evans, A. Nautsch, et al. ASVSpoof 2021: Towards spoofed and deepfake speech detection in the wild.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2507–2522, 2023
2021
-
[26]
K. T. Mai, S. Bray, T. Davies, and L. D. Griffin. Warning: Humans cannot reliably detect speech deepfakes.PLoS One, 18(8):285–333, 2023
2023
-
[27]
Müller, P
N. Müller, P. Czempin, F. Diekmann, A. Froghyar, and K. Böttinger. Does audio deepfake detection generalize? InINTERSPEECH, pages 2783–2787, 2022, Incheon, Korea
2022
-
[28]
N. M. Müller et al. MLAAD: The multi-language audio anti-spoofing dataset. InInternational Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, pages 1–7, 2024
2024
-
[29]
Negroni, D
V . Negroni, D. Salvi, P. Bestagini, S. Tubaro, et al. Source verification for speech deepfakes. InINTERSPEECH, pages 1–5. 2025, Rotterdam, Netherlands. 13 APREPRINT
2025
-
[30]
Z. Ning, H. Chen, Y . Jiang, C. Hao, G. Ma, S. Wang, J. Yao, and L. Xie. Diffrhythm: Blazingly fast and embar- rassingly simple end-to-end full-length song generation with latent diffusion.arXiv preprint arXiv:2503.01183, 2025 {Last Accessed:17 th Feb, 2026}
arXiv 2025
-
[31]
Panayotov, G
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur. Librispeech: an asr corpus based on public domain audio books. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210, 2015, South Brisbane, Queensland, Australia
2015
-
[32]
Radford, J
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever. Robust speech recognition via large-scale weak supervision. InInternational Conference on Machine Learning (ICML), pages 28492–28518, 2023, Honolulu, HI, USA
2023
-
[33]
M. A. Rahman, Z. I. A. Hakim, N. H. Sarker, B. Paul, and S. A. Fattah. SONICS: Synthetic or not - identifying counterfeit songs. InThe13 th International Conference on Learning Representations, (ICLR), Singapore, 2025
2025
-
[34]
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. InIEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), volume 2, pages 749–752, 2001, Salt Lake City, Utah, USA
2001
-
[35]
GitHub: https://github.com/RVC-Project/Retrieval-based-V oice-Conversion-WebUI.{Last Accessed: 27th, F ebruary,2025}, 2024
RVC-Project. GitHub: https://github.com/RVC-Project/Retrieval-based-V oice-Conversion-WebUI.{Last Accessed: 27th, F ebruary,2025}, 2024
2025
-
[36]
Siami-Namini, N
S. Siami-Namini, N. Tavakoli, and A. S. Namin. The performance of lstm and bilstm in forecasting time series. In IEEE International Conference on Big Data (Big Data), pages 3285–3292, 2019, Los Angeles, CA, USA
2019
-
[37]
R. C. Streijl, S. Winkler, and D. S. Hands. Mean Opinion Score (MOS) revisited: Methods and applications, limitations and alternatives.Multimedia Systems, 22(2):213–227, 2016
2016
-
[38]
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen. An algorithm for intelligibility prediction of time–frequency weighted noisy speech.IEEE Transactions on Audio, Speech, and Language Processing, 19(7):2125–2136, 2011
2011
-
[39]
Todisco, X
M. Todisco, X. Wang, V . Vestman, M. Sahidullah, H. Delgado, A. Nautsch, J. Yamagishi, N. Evans, T. Kinnunen, and K. A. Lee. ASVSpoof 2019: Future horizons in spoofed and fake audio detection. InINTERSPEECH, pages 1008–1012, 2019, Graz, Austria
2019
-
[40]
X. Wang, H. Delgado, H. Tak, J. weon Jung, H. jin Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. Kinnunen, N. Evans, K. A. Lee, J. Yamagishi, M. Jeong, G. Zhu, Y . Zang, Y . Zhang, S. Maiti, F. Lux, N. Müller, W. Zhang, C. Sun, S. Hou, S. Lyu, S. Le Maguer, C. Gong, H. Guo, L. Chen, and V . Singh. ASVspoof 5: Design, collection and validation of ...
2026
-
[41]
Z. Wu, J. Yamagishi, T. Kinnunen, C. Hanilçi, M. Sahidullah, A. Sizov, N. Evans, M. Todisco, and H. Delgado. ASVSpoof: The automatic speaker verification spoofing and countermeasures challenge.IEEE Journal of Selected Topics in Signal Processing, 11(4):588–604, 2017
2017
-
[42]
Y . Xie, J. Zhou, X. Lu, Z. Jiang, Y . Yang, H. Cheng, and L. Ye. FSD: An initial Chinese dataset for fake song detection. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4605–4609, 2024, Seoul, Korea
2024
-
[43]
X. Xuan, Y . Xiao, R. K. Das, and T. Kinnunen. Multilingual source tracing of speech deepfakes: A first benchmark. In 5th Symposium on Security and Privacy in Speech Communicatio (SPSC), pages 27–34, 2025, Delft, Netherlands
2025
-
[44]
Yamagishi, C
J. Yamagishi, C. Veaux, and K. MacDonald. CSTR VCTK Corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92).The Rainbow Passage which the speakers read out can be found in the International Dialects of English Archive:(http://web. ku. edu/˜ idea/readings/rainbow. htm)., 2019
2019
-
[45]
Yamagishi, X
J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evans, et al. ASVSpoof 2021: Accelerating progress in spoofed and deepfake speech detection. InASVSpoof Workshop, pages 47–54, 2021, Kos Island, Greece
2021
-
[46]
Z. Yan, T. Yao, S. Chen, Y . Zhao, X. Fu, J. Zhu, D. Luo, C. Wang, S. Ding, Y . Wu, et al. Df40: Toward next- generation deepfake detection.Advances in Neural Information Processing Systems (NeurIPS), 37:29387–29434, 2024, Vancouver, Canada
2024
-
[47]
Y . Zang, J. Shi, Y . Zhang, R. Yamamoto, J. Han, Y . Tang, S. Xu, W. Zhao, J. Guo, T. Toda, and Z. Duan. CtrSVDD: A benchmark dataset and baseline analysis for controlled singing voice deepfake detection. InINTERSPEECH 2024, Kos, Greece, pages 4783–4787
2024
-
[48]
Y . Zang, Y . Zhang, M. Heydari, and Z. Duan. Singfake: Singing voice deepfake detection. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12156–12160, 2024, Seoul, Korea. 14 APREPRINT
2024
-
[49]
Zhang, J
Y . Zhang, J. Cong, H. Xue, L. Xie, P. Zhu, and M. Bi. Visinger: Variational inference with adversarial learning for end-to-end singing voice synthesis. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7237–7241, 2022, (Virtual) Singapore
2022
-
[50]
Zhang, Y
Y . Zhang, Y . Zang, J. Shi, R. Yamamoto, T. Toda, and Z. Duan. SVDD 2024: The inaugural singing voice deepfake detection challenge. InIEEE Spoken Language Technology Workshop (SLT), pages 782–787, 2024, Macao, China
2024
-
[51]
Zhao and D
X. Zhao and D. Wang. Analyzing noise robustness of MFCC and GFCC features in speaker identification. In IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pages 7204–7208, 2013, Vancover, Canada
2013
-
[52]
T. Zhu, X. Wang, X. Qin, and M. Li. Source tracing: Detecting voice spoofing. InAsia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pages 216–220, 2022, Chiang Mai, Thailand. A Performance Metrices A.1 Objective Evaluation Metrics 1.Perceptual Evaluation of Speech Quality (PESQ) [34]: This metric estimates...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.