FORTE: FOL-guided Optimal Refinement for Text-audio rEtrieval
Pith reviewed 2026-06-27 22:50 UTC · model grok-4.3
The pith
Text queries refined via first-order logic yield more precise audio retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FORTE transforms queries into first-order logic and refines them via a constrained search that preserves semantic invariance while introducing discriminative attributes. The refined representation is aligned with audio embeddings using a lightweight projection module, followed by a predicate-aware re-ranking step that enforces logical consistency at inference. Experiments on AudioCaps and Clotho demonstrate consistent improvements over strong baselines, particularly in challenging fine-grained scenarios.
What carries the argument
FOL-guided query refinement via constrained search combined with lightweight projection and predicate-aware re-ranking.
If this is right
- Retrieval precision increases in fine-grained scenarios.
- The approach uses parameter-efficient modules for alignment.
- Logical consistency is enforced at inference.
- Performance gains appear on AudioCaps and Clotho datasets over baselines like CLAP.
Where Pith is reading between the lines
- The refinement technique could extend to text-to-image or text-to-video retrieval tasks.
- Symbolic preprocessing may reduce the need for large parameter updates in cross-modal models.
- The method suggests hybrid symbolic-neural systems can address modality gaps more effectively.
Load-bearing premise
Converting natural language queries into first-order logic and refining them via constrained search preserves the original semantics while adding attributes that better match audio content.
What would settle it
If experiments on AudioCaps or Clotho show no improvement in standard retrieval metrics when using the FORTE refinements compared to direct embedding matching, the value of the logical refinement would be called into question.
Figures
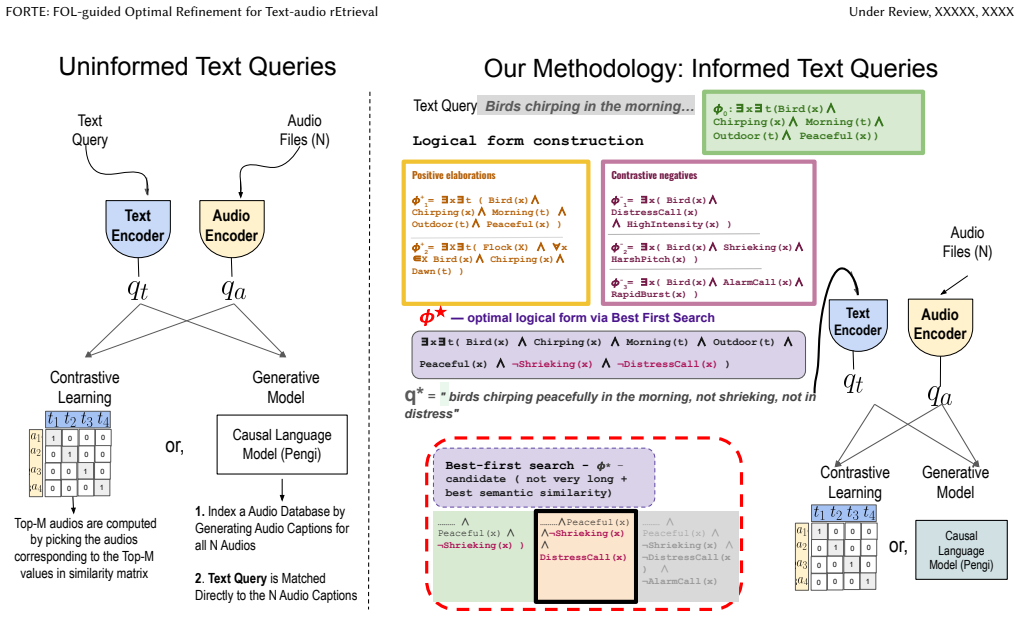
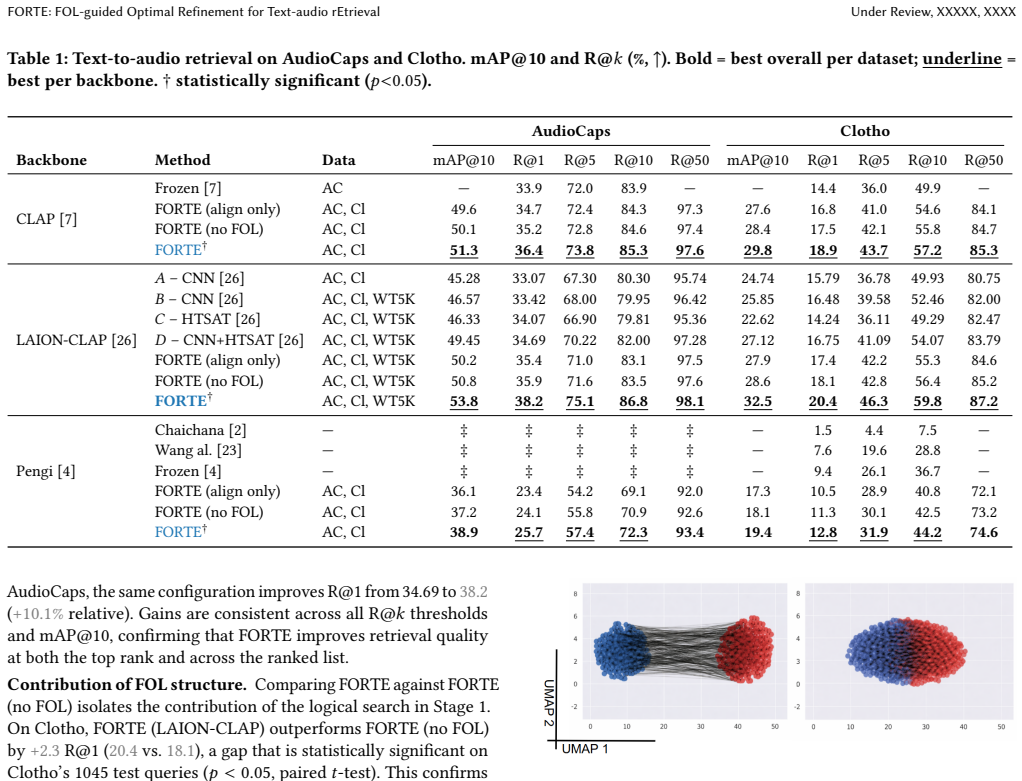

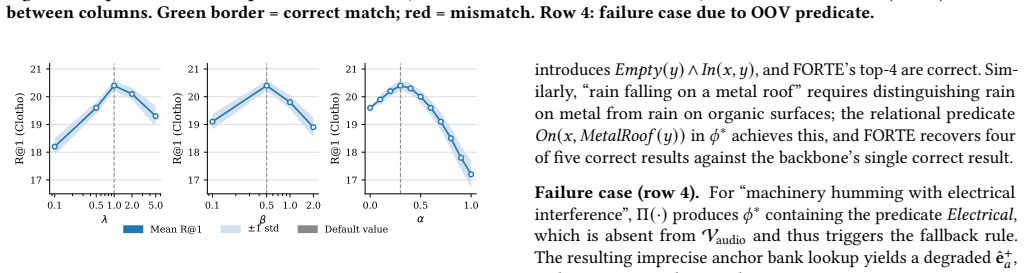

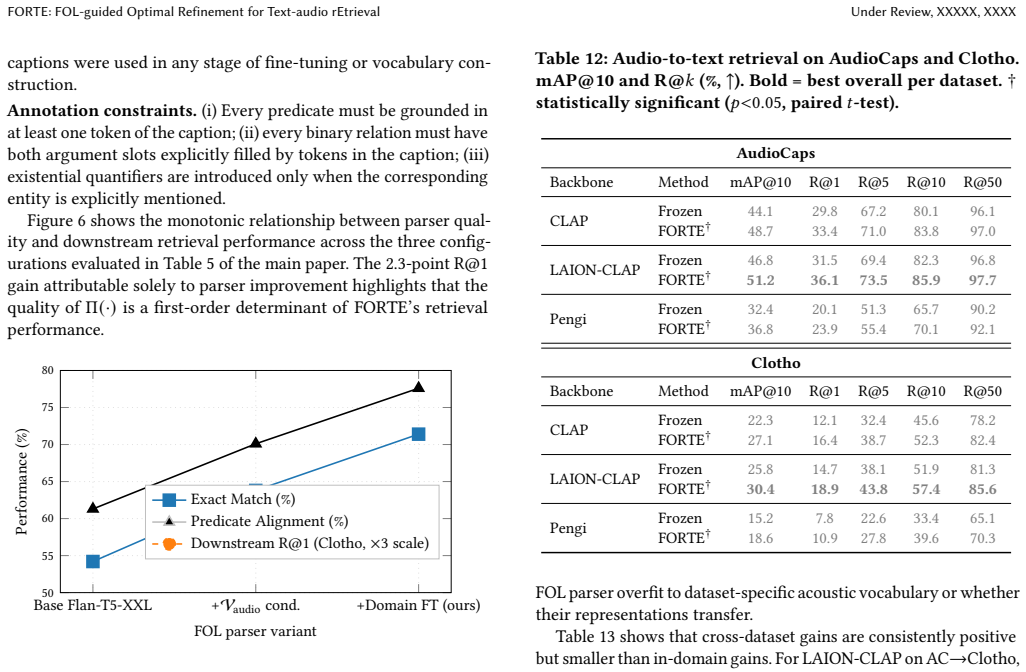


read the original abstract
Text-to-audio retrieval has made significant progress with shared embedding models such as CLAP and Pengi, yet they often struggle with fine-grained semantic alignment due to the inherent modality gap between text and audio. In this work, we propose FORTE, a unified framework that integrates structured logical reasoning with parameter-efficient cross-modal alignment to improve retrieval precision. Our approach first transforms queries into first-order logic and refines them via a constrained search that preserves semantic invariance while introducing discriminative attributes. The refined representation is then aligned with audio embeddings using a lightweight projection module, followed by a predicate-aware re-ranking step that enforces logical consistency at inference. Extensive experiments on AudioCaps and Clotho demonstrate consistent improvements over strong baselines, particularly in challenging fine-grained scenarios. Our results highlight the effectiveness of combining symbolic reasoning with representation learning for cross-modal retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FORTE, a unified framework for text-to-audio retrieval that integrates first-order logic (FOL) structured reasoning with parameter-efficient cross-modal alignment. Queries are transformed into FOL and refined via constrained search that preserves semantic invariance while adding discriminative attributes; the result is aligned to audio embeddings via a lightweight projection module and refined at inference by predicate-aware re-ranking. Experiments on AudioCaps and Clotho are stated to yield consistent gains over strong baselines, especially in fine-grained scenarios.
Significance. If the experimental claims hold after proper validation, the work would be of moderate significance for demonstrating a hybrid symbolic-neural approach to narrowing the modality gap in cross-modal retrieval. The combination of FOL refinement with projection and re-ranking is a plausible direction beyond pure embedding models such as CLAP, but the absence of any quantitative evidence, ablations, or formal statements prevents assessment of whether the approach actually delivers the claimed improvements.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent improvements over strong baselines, particularly in challenging fine-grained scenarios' is asserted without any numerical results, tables, ablation studies, or error analysis. This absence makes the soundness of the FOL-guided refinement pipeline impossible to evaluate from the supplied manuscript.
- [Abstract] Abstract: no equations, formal definitions, or pseudocode are provided for the FOL transformation step, the constrained search procedure, the semantic-invariance guarantee, the lightweight projection module, or the predicate-aware re-ranking. Without these, it is impossible to verify whether the refinement step preserves invariance or adds discriminative power as claimed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent improvements over strong baselines, particularly in challenging fine-grained scenarios' is asserted without any numerical results, tables, ablation studies, or error analysis. This absence makes the soundness of the FOL-guided refinement pipeline impossible to evaluate from the supplied manuscript.
Authors: We agree that the abstract would be strengthened by including concrete numerical support for the claims. The full manuscript contains these details in Section 4 (Experiments), with tables reporting recall metrics on AudioCaps and Clotho, ablations in Section 5, and error analysis. In the revision we will add 1-2 key quantitative results (e.g., R@1 gains in fine-grained subsets) to the abstract while respecting length constraints. revision: yes
-
Referee: [Abstract] Abstract: no equations, formal definitions, or pseudocode are provided for the FOL transformation step, the constrained search procedure, the semantic-invariance guarantee, the lightweight projection module, or the predicate-aware re-ranking. Without these, it is impossible to verify whether the refinement step preserves invariance or adds discriminative power as claimed.
Authors: The abstract is a concise summary and therefore omits detailed equations and pseudocode, which appear in Section 3 with formal definitions of the FOL transformation, constrained search (including the invariance argument), projection module, and re-ranking procedure, plus Algorithm 1. We will revise the abstract to include a brief high-level notation or explicit reference to these formal components so readers can locate the verification details immediately. revision: partial
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description outline a high-level pipeline (FOL transformation, constrained refinement preserving invariance, projection, and re-ranking) without any equations, parameter-fitting steps, or derivations. No self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations appear. The central claims rest on empirical results on AudioCaps and Clotho rather than any reduction of outputs to inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Converting natural-language queries to first-order logic and performing constrained refinement preserves semantic invariance.
Reference graph
Works this paper leans on
-
[1]
Alexei Baevski et al. 2022. data2vec: A General Framework for Self-supervised Learning. InICML
2022
-
[2]
Yuatyong Chaichana, Pittawat Taveekitworachai, Warit Sirichotedumrong, Pot- sawee Manakul, and Kunat Pipatanakul. 2026. Extending Audio Context for Long-Form Understanding in Large Audio-Language Models. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 6046–6066
2026
-
[3]
Soham Deshmukh et al. 2023. Pengi: An Audio Language Model for Audio Tasks. InNeurIPS
2023
-
[4]
Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang. 2023. Pengi: An audio language model for audio tasks.Advances in Neural Information Processing Systems36 (2023), 18090–18108
2023
- [5]
-
[7]
InICASSP
CLAP: Learning Audio-Text Representations from Natural Language Su- pervision. InICASSP
-
[8]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
-
[9]
arXiv:2206.04769 [cs.SD] https://arxiv.org/abs/2206.04769
CLAP: Learning Audio Concepts From Natural Language Supervision. arXiv:2206.04769 [cs.SD] https://arxiv.org/abs/2206.04769
-
[10]
Gemmeke, Daniel P
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Au- dio Set: An ontology and human-labeled dataset for audio events. InProc. IEEE ICASSP 2017. New Orleans, LA
2017
-
[11]
Sreyan Ghosh et al. 2024. GAMA: A Large Audio-Language Model with Advanced Reasoning Capabilities. InEMNLP
2024
-
[12]
Sreyan Ghosh et al. 2025. Audio Flamingo 2: Long-Audio Understanding and Reasoning. InICML
2025
-
[13]
Edward Hu et al. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InICLR
2022
-
[14]
Justin Johnson et al. 2017. Inferring and Executing Programs for Visual Reasoning. InICCV
2017
-
[15]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Late Interaction. InSIGIR
2020
-
[16]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. [n. d.]. AudioCaps: Generating Captions for Audios in The Wild
-
[17]
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. 2022. Mind the gap: Understanding the modality gap in multi-modal con- trastive representation learning.Advances in Neural Information Processing Systems35 (2022), 17612–17625
2022
-
[18]
Jiayuan Mao et al. 2019. Neural-Symbolic Concept Learner. InICLR
2019
-
[19]
Rodrigo Nogueira and Kyunghyun Cho. 2021. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Alec Radford et al . 2021. Learning Transferable Visual Models From Natural Language Supervision. InICML
2021
-
[21]
Tim Sainburg, Leland McInnes, and Timothy Q Gentner. [n. d.]. Parametric UMAP: learning embeddings with deep neural networks for representation and semi-supervised learning. ([n. d.])
-
[22]
Changli Tang, Wenyi Yu, Guangzhi Sun, and Xianzhao Chen. 2024. SALMONN: Towards Generic Hearing Abilities for Large Language Models.arXiv preprint arXiv:2310.13289(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Wen Wang et al . 2025. MATS: An Audio Language Model under Text-only Supervision. InICML
2025
- [25]
-
[27]
Yusong Wu*, Ke Chen*, Tianyu Zhang*, Yuchen Hui*, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation. InIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP
2023
-
[28]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Marianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2024. Large-scale Contrastive Language- Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation. arXiv:2211.06687 [cs.SD] https://arxiv.org/abs/2211.06687
-
[29]
Bajian Xiang, Shuaijiang Zhao, Tingwei Guo, and Wei Zou. 2025. Understanding the Modality Gap: An Empirical Study on the Speech-Text Alignment Mechanism of Large Speech Language Models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 5187–5202
2025
- [30]
-
[31]
Xiaohua Zhai et al . 2023. Sigmoid Loss for Language Image Pre-Training. In ICCV. Organisation.This supplementary is organised as follows. • §6 — Full implementation details (architecture, training, hyper- parameters). •§7 — LLM prompt templates for generating𝜙 + and𝜙 −. • §8 — FOL parser grammar, predicate vocabulary, and fallback rules. • §9 — Extended ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.