Operational Memory Architecture for Kubernetes:Preserving Causal Context Across the Evidence Horizon
Pith reviewed 2026-05-21 12:20 UTC · model grok-4.3
The pith
The Operational Memory Architecture preserves causal failure evidence in Kubernetes by capturing events into chains before the evidence horizon overwrites LastTerminationState.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
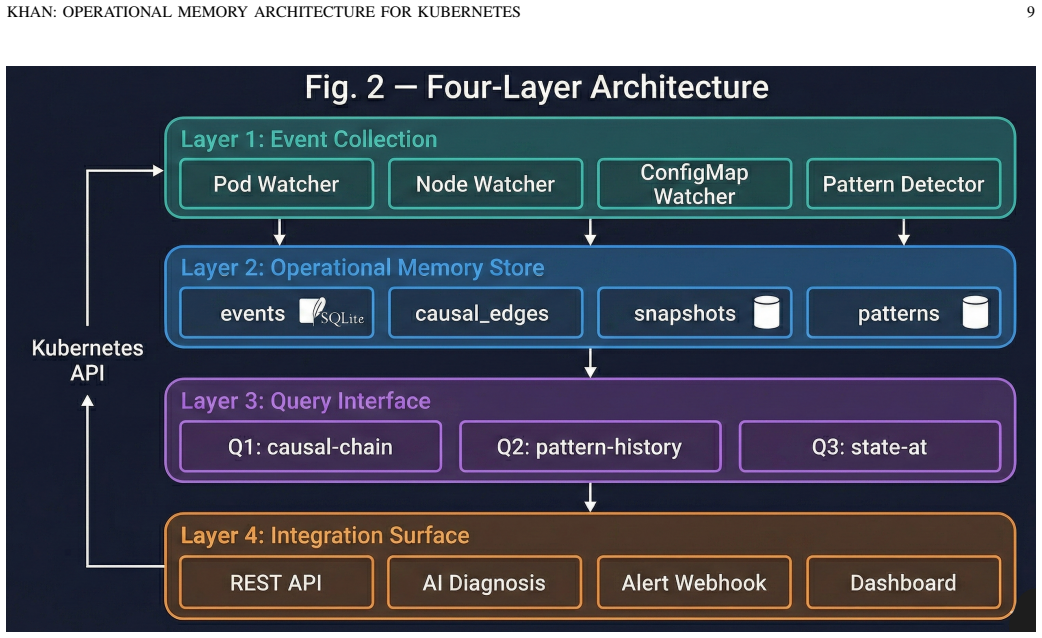
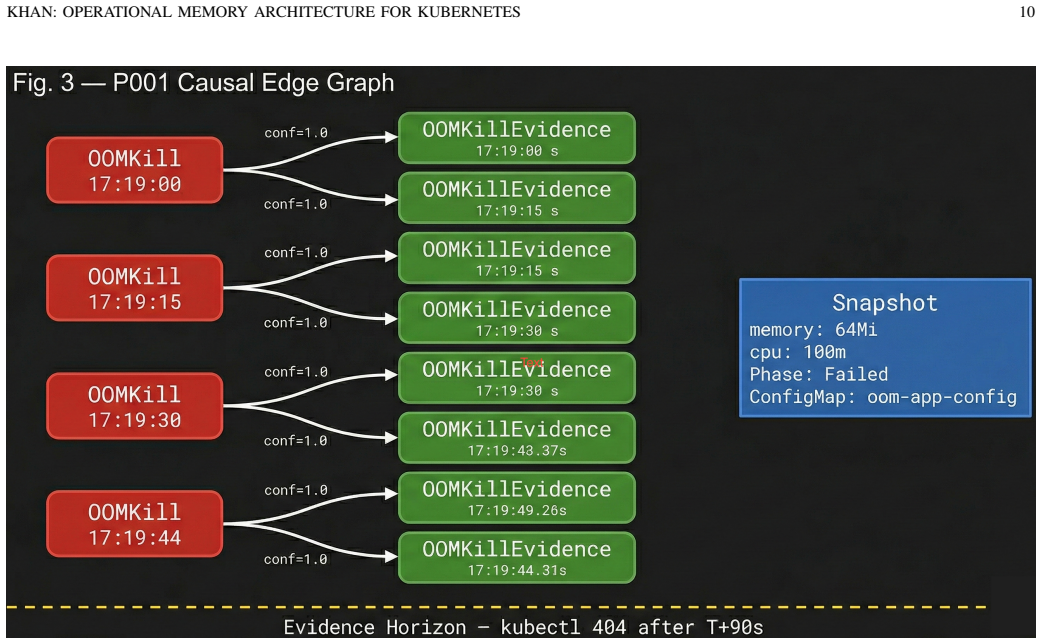
OMA encodes evidence retention and causal reconstruction as explicit architectural requirements. It captures operational events into causal chains using three patterns: P001 for OOMKill chains, P002 for ConfigMap variable misconfiguration, and P003 for ConfigMap volume mount propagation. The architecture preserves this evidence before the evidence horizon is crossed, as shown by a Go-based watcher and SQLite store that maintains mean causal edge latency below 1 ms and under 10 MB memory use.
What carries the argument
Operational Memory Architecture (OMA), which builds causal chains from operational events using three defined patterns and stores them to retain evidence past the evidence horizon.
If this is right
- Causal failure context remains available for inspection after pod restarts in crash loops.
- Mean latency for building causal edges stays below 1 ms under load.
- Memory usage remains under 10 MB while processing events at roughly 2.8 per second.
- The three patterns cover diagnostically valuable context for typical failures.
Where Pith is reading between the lines
- The same retention approach could apply to other container orchestration systems that rotate event state.
- Adding patterns for network or storage failures would expand coverage without changing the core store.
- Operators could query the stored chains directly instead of reconstructing context from scattered logs.
Load-bearing premise
The three defined patterns are sufficient to encode the diagnostically valuable context across typical pod lifecycle transitions.
What would settle it
A stress test with 20 crash-looping pods that shows causal chains for OOMKill or ConfigMap events are missing after multiple restarts would falsify the preservation claim.
Figures
read the original abstract
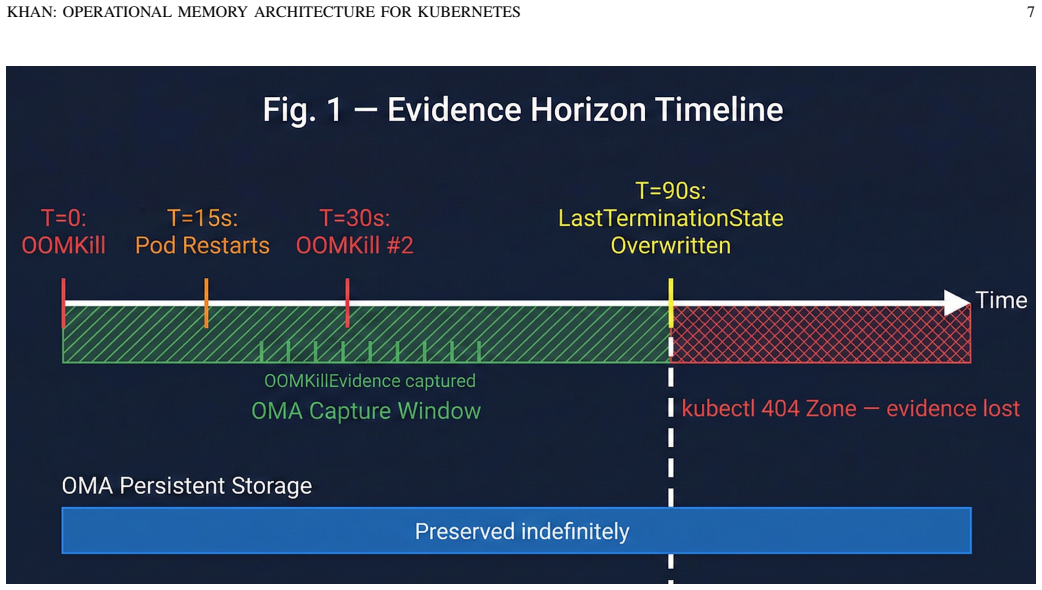
Kubernetes clusters generate rich operational events during pod lifecycle transitions, yet the platform's native event retention model discards the most diagnostically valuable context. The LastTerminationState field, which records a container's last failure, is overwritten shortly after a pod restart. We define this as the evidence horizon. During high-frequency crash loops, this horizon may be crossed multiple times before inspection, permanently losing critical evidence. This paper introduces the Operational Memory Architecture (OMA) to preserve causal failure evidence before event rotation. OMA encodes evidence retention and causal reconstruction as explicit architectural requirements. It captures operational events into causal chains using three patterns: P001 (OOMKill chain), P002 (ConfigMap variable misconfiguration), and P003 (ConfigMap volume mount propagation). We implement OMA as an open-source system with a Go-based Kubernetes watcher, SQLite operational memory store, and a simple query interface. Experiments on Minikube and AKS include a 30-run latency analysis and stress tests with up to 20 crash-looping pods. Causal edges are built with mean latency below 1 ms. The collector processes ~2.8 events/sec while using under 10 MB memory, showing minimal overhead and effective evidence preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Kubernetes discards diagnostically valuable context when the LastTerminationState field is overwritten after pod restarts (termed the evidence horizon), and introduces the Operational Memory Architecture (OMA) to preserve causal failure evidence. OMA encodes retention and reconstruction via three explicit patterns (P001 OOMKill chain, P002 ConfigMap variable misconfiguration, P003 ConfigMap volume mount propagation), implemented as an open-source Go-based Kubernetes watcher with SQLite storage and a query interface. Experiments on Minikube and AKS report mean causal-edge latency below 1 ms, throughput of ~2.8 events/sec, and memory use under 10 MB in stress tests with up to 20 crash-looping pods.
Significance. If the preservation mechanism generalizes, OMA supplies a low-overhead, practical system for retaining causal operational context in Kubernetes, which could improve debugging of transient failures. The open-source implementation together with concrete 30-run latency measurements and stress-test results on both local and cloud platforms constitutes a tangible engineering contribution.
major comments (1)
- The central preservation claim rests on the assumption that the three hardcoded patterns (P001–P003) are sufficient to capture diagnostically valuable context across typical pod lifecycle transitions. The experiments and analysis address only crash-loop scenarios that map directly onto these patterns; no data or argument is supplied for other common transitions such as ImagePullBackOff, Evicted, or FailedScheduling, leaving the generalizability of the evidence-retention guarantee unsupported.
minor comments (2)
- The latency and throughput figures are presented without error bars, variance, or statistical significance measures, and no baseline comparison to native Kubernetes event handling is provided.
- Details on how causal edges are validated (e.g., ground-truth construction or manual inspection) are absent from the experimental description.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the practical engineering contribution of the open-source implementation and measurements. We address the single major comment below regarding the scope of the patterns and generalizability.
read point-by-point responses
-
Referee: The central preservation claim rests on the assumption that the three hardcoded patterns (P001–P003) are sufficient to capture diagnostically valuable context across typical pod lifecycle transitions. The experiments and analysis address only crash-loop scenarios that map directly onto these patterns; no data or argument is supplied for other common transitions such as ImagePullBackOff, Evicted, or FailedScheduling, leaving the generalizability of the evidence-retention guarantee unsupported.
Authors: We agree that the reported experiments and analysis are confined to crash-loop scenarios that exercise P001–P003. The manuscript presents these three patterns as concrete, representative encodings of causal chains that cross the evidence horizon (LastTerminationState overwrite), rather than an exhaustive catalog. The OMA watcher itself is pattern-agnostic: it ingests all relevant Kubernetes events and stores them in the SQLite operational memory before rotation occurs. We will revise the manuscript to (1) add an explicit Scope and Limitations subsection clarifying that P001–P003 illustrate the mechanism for termination-related failures and that other states (e.g., ImagePullBackOff, Evicted, FailedScheduling) would require additional pattern definitions, and (2) argue that the core architectural guarantee—capturing causal context prior to the evidence horizon—remains applicable once the appropriate patterns are supplied. No new experimental data for those states will be added in this revision, as that would constitute a separate study. revision: yes
Circularity Check
No circularity: implementation and measurement study with no derivations or fitted predictions
full rationale
The paper introduces OMA as an explicit architectural design implemented via a Go watcher and SQLite store, then measures its performance on crash-loop scenarios using the three author-defined patterns P001-P003. No equations, first-principles derivations, or statistical predictions appear; the patterns are presented as chosen encoding mechanisms rather than outputs derived from data or prior results. The work is therefore self-contained as an engineering artifact whose claims rest on direct implementation and empirical overhead measurements rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Kubernetes LastTerminationState is overwritten shortly after pod restart, creating an evidence horizon that loses diagnostic context during crash loops.
invented entities (1)
-
Operational Memory Architecture (OMA)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OMA encodes evidence retention and causal reconstruction as explicit architectural requirements. It captures operational events into causal chains using three patterns: P001 (OOMKill chain), P002 (ConfigMap variable misconfiguration), and P003 (ConfigMap volume mount propagation).
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_add unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The causal edges OMA constructs are analogous to happened-before relationships [9]: if an OOMKillEvidence event e2 is observed for pod P within 90 seconds of an OOMKill event e1 for the same pod, then e1 → e2 in the happened-before sense.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Prometheus: From metrics to insight,
Prometheus Authors, “Prometheus: From metrics to insight,” prometheus.io, 2024. [Online]. Available: https://prometheus.io
work page 2024
-
[2]
Canopy: An end-to-end performance tracing and analysis system,
J. Kaldor, J. Mace, M. Bejda, E. Gao, W. Kuropatwa, J. O’Neill, K. W. Ong, B. Schaller, P. Shan, B. Viscomi, V . Venkataraman, K. Veeraraghavan, and Y . J. Song, “Canopy: An end-to-end performance tracing and analysis system,” inProc. ACM Symp. Oper. Syst. Princ. (SOSP), Shanghai, China, 2017, pp. 34–50
work page 2017
-
[3]
C. Gormley and Z. Tong,Elasticsearch: The Definitive Guide.Sebastopol, CA, USA: O’Reilly Media, 2015
work page 2015
-
[4]
OpenTelemetry Authors, “OpenTelemetry specification,” opentelemetry.io, 2024. [Online]. Available: https://opentelemetry.io/docs/specs/otel/
work page 2024
-
[5]
The Kubernetes Authors, “Kubernetes documentation,” kubernetes.io, 2024. [Online]. Available: https://kubernetes.io/docs/
work page 2024
-
[6]
Drain: An online log parsing approach with fixed depth tree,
P. He, J. Zhu, Z. Zheng, and M. R. Lyu, “Drain: An online log parsing approach with fixed depth tree,” inProc. IEEE Int. Conf. Web Services (ICWS), Honolulu, HI, USA, 2017, pp. 33–40
work page 2017
- [7]
-
[8]
Pearl,Causality: Models, Reasoning, and Inference,2nd ed
J. Pearl,Causality: Models, Reasoning, and Inference,2nd ed. Cambridge, U.K.: Cambridge Univ. Press, 2009
work page 2009
-
[9]
Time, clocks, and the ordering of events in a distributed system,
L. Lamport, “Time, clocks, and the ordering of events in a distributed system,”Commun. ACM, vol. 21, no. 7, pp. 558–565, Jul. 1978
work page 1978
-
[10]
CloudRCA: A root cause analysis framework for cloud computing platforms,
W. Wang, M. Chen, J. Zhang, S. Qin, A. Qin, X. Ding, P. Chen, and Y . Kang, “CloudRCA: A root cause analysis framework for cloud computing platforms,” inProc. ACM Int. Conf. Inf. Knowl. Manage. (CIKM), Queensland, Australia, 2021, pp. 4373–4382
work page 2021
-
[11]
B. Burns, B. Grant, D. Oppenheimer, E. Brewer, and J. Wilkes, “Borg, Omega, and Kubernetes,”ACM Queue, vol. 14, no. 1, pp. 70–93, Jan. 2016, DOI: 10.1145/2898442.2898444
-
[12]
Velero: Backup and migrate Kubernetes applications,
VMware Tanzu, “Velero: Backup and migrate Kubernetes applications,” velero.io, 2024. [Online]. Available: https://velero.io
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.