A computationally-tractable measure of global sensitivity for sampling-based Bayesian inference
Pith reviewed 2026-06-29 11:06 UTC · model grok-4.3
The pith
Fisher divergence measure quantifies global sensitivity of Bayesian posteriors from samples alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under mild regularity conditions the Fisher divergence between a reference posterior and a perturbed posterior controls the total variation distance on the entire posterior and supplies explicit bounds on the resulting shifts in the first two moments; the quantity is obtained from posterior samples and score evaluations without requiring additional sampling or optimisation.
What carries the argument
Fisher divergence between reference and perturbed posteriors, which serves as an upper bound on distributional and moment changes.
If this is right
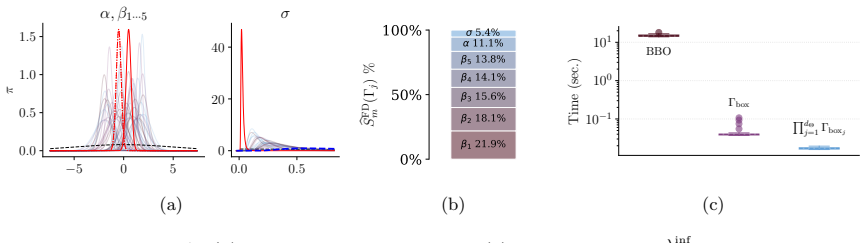
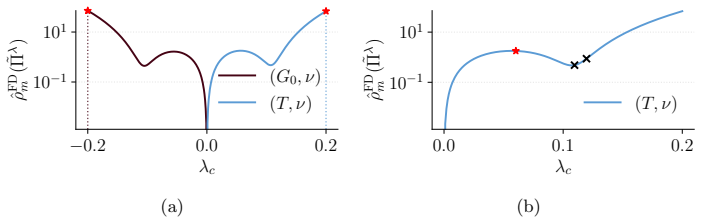
- The measure applies directly to generalised Bayesian inference with unnormalised models.
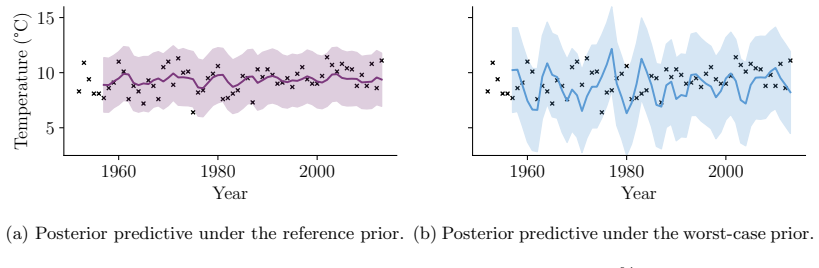
- It remains tractable for Bayesian time-series models.
- It supports sensitivity checks inside neural simulation-based inference pipelines.
- Bounds on the first two posterior moments follow from the same divergence quantity.
Where Pith is reading between the lines
- Low values would indicate that posterior inferences are stable to modest hyperparameter changes in the prior or likelihood.
- The same sampling-plus-score workflow could be reused to compare robustness across several candidate models.
- If score functions are cheap, the method could be inserted as a routine diagnostic step before committing to expensive downstream decisions.
Load-bearing premise
Mild regularity conditions must hold on the posteriors and score functions must be evaluable.
What would settle it
A concrete perturbation where the computed Fisher divergence is small yet the total variation distance between posteriors or the moment shifts exceed the claimed bounds.
Figures
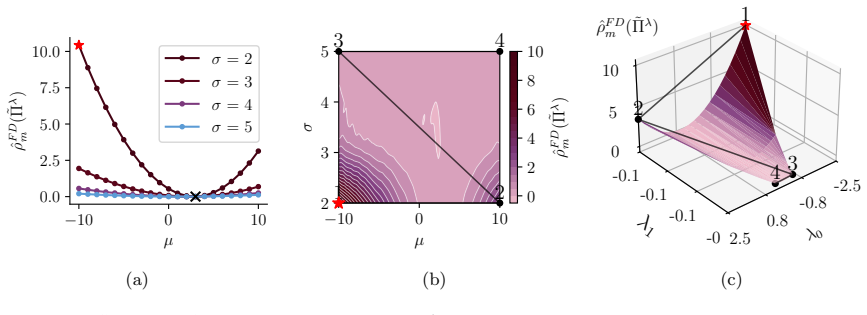
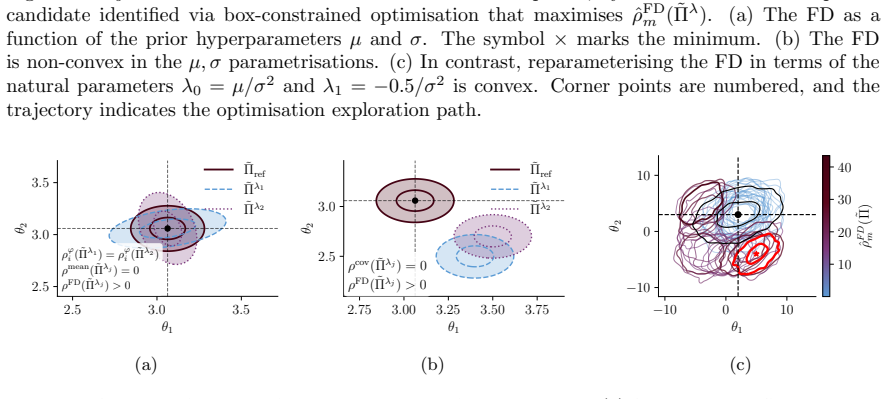
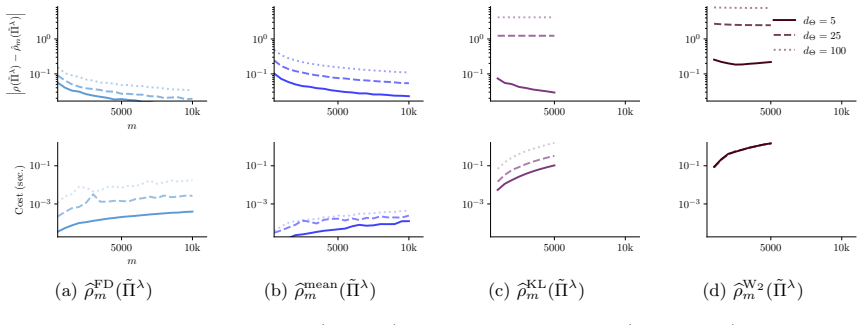
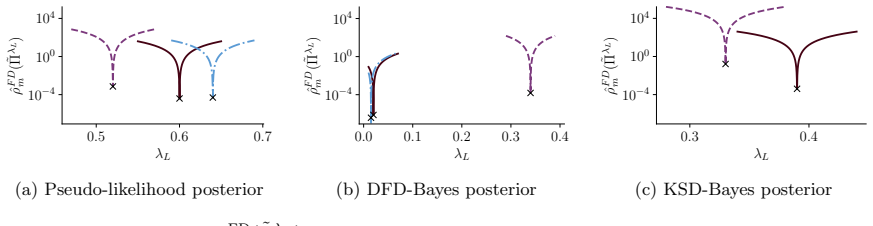
read the original abstract
Bayesian inference can often be sensitive to the choice of hyperparameters of the prior or likelihood, yet defining and quantifying this sensitivity in a principled and computationally feasible way remains challenging in practice. Unfortunately, existing sensitivity methods are rarely applicable in modern Bayesian workflows due to their high computational cost and poor performance in moderate to high dimensions. To address these limitations, we introduce a new approach to global sensitivity analysis based on the Fisher divergence. Our method only requires a set of samples from a reference posterior and the ability to evaluate score functions, making it broadly computationally tractable. Under mild regularity conditions, it controls changes in the whole posterior, and provides a bound on the impact of perturbations on the first two moments. We demonstrate these strengths on challenging Bayesian inference problems which are practically out of reach of existing approaches, including generalised Bayesian inference for unnormalised models, inference in Bayesian models of time series, and neural simulation-based inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Fisher divergence-based global sensitivity measure for sampling-based Bayesian inference. It requires only reference posterior samples and score function evaluations, making it tractable in moderate-to-high dimensions. Under mild regularity conditions the measure is claimed to control changes to the full posterior and to bound perturbations to the first two moments; demonstrations are provided for generalised Bayesian inference with unnormalised models, time-series models, and neural simulation-based inference.
Significance. If the stated bounds hold, the contribution would be practically useful: it supplies a computationally feasible sensitivity diagnostic that existing methods cannot scale to the regimes the authors target. The grounding in the standard Fisher divergence (rather than ad-hoc or fitted quantities) and the explicit focus on sampling-based workflows are strengths. Reproducible demonstrations on otherwise intractable problems would further strengthen the case.
major comments (1)
- [Abstract / theoretical section] Abstract and theoretical development: the central claim that the Fisher divergence 'controls changes in the whole posterior' and 'provides a bound on the impact of perturbations on the first two moments' is stated without derivation details, explicit regularity conditions, or error analysis. A load-bearing section (presumably the main theoretical result) must supply the precise statement of the conditions, the proof strategy, and any counter-example checks before the claim can be verified.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the need for greater transparency in the theoretical claims. The single major comment concerns the presentation of the central results on posterior control and moment bounds. We address it directly below.
read point-by-point responses
-
Referee: [Abstract / theoretical section] Abstract and theoretical development: the central claim that the Fisher divergence 'controls changes in the whole posterior' and 'provides a bound on the impact of perturbations on the first two moments' is stated without derivation details, explicit regularity conditions, or error analysis. A load-bearing section (presumably the main theoretical result) must supply the precise statement of the conditions, the proof strategy, and any counter-example checks before the claim can be verified.
Authors: We agree that the current manuscript states these claims at a high level without supplying the full set of regularity conditions, the complete proof outline, or an accompanying error analysis in a single load-bearing section. In the revised version we will add an expanded theoretical subsection (new Section 3.2) that (i) lists the precise regularity conditions (twice-differentiability of the log-density, integrability of the score, and a uniform bound on the Hessian), (ii) sketches the proof strategy via the data-processing inequality for Fisher divergence followed by a Taylor expansion of the perturbed posterior, and (iii) includes a short discussion of the resulting error terms together with a simple counter-example check confirming that the bounds fail when the regularity conditions are violated. These additions will make the claims directly verifiable without altering the main results. revision: yes
Circularity Check
No significant circularity; derivation grounded in standard Fisher divergence
full rationale
The paper defines a global sensitivity measure directly from the Fisher divergence (a standard information-theoretic quantity) and derives its properties (posterior control and moment bounds) under stated mild regularity conditions using samples and score evaluations. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the central claims remain independent of the target result and are externally falsifiable via the divergence definition itself. This is the most common honest non-finding for papers that import a known divergence and apply it to sensitivity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild regularity conditions on the posteriors and score functions
Reference graph
Works this paper leans on
-
[1]
Then, cFDm(˜Πref∥˜Πλ)−FD( ˜Πref∥˜Πλ) = 1 m mX i=1 gtest(θi; ˜Πλ)
By construction,E ˜Πλ[gtest(θ; ˜Πλ)] = 0. Then, cFDm(˜Πref∥˜Πλ)−FD( ˜Πref∥˜Πλ) = 1 m mX i=1 gtest(θi; ˜Πλ). By Theorem 1 (forq= 1) and Remark 1 of Durmus et al. (2024), it follows that ifg test ∈L √ V , then under Assumption 2 the following moment inequality holds E 1 m mX i=1 gtest(θi; ˜Πλ) !2 ≤ C( ˜Πλ) m ,(25) for some C( ˜Πλ)≤K ′ gtest(·; ˜Πλ) 2...
2024
-
[2]
Since ˜ΠΛ ∈ PΓ we have: ∆(θ; ˜Πλ) = ∇θT(θ) ⊤(λπref −λ π) + (λL −λ Lref )∇ θl(θ;x 1:n) 2 2 . Using the fact that (a+b) 2 ≤2(a 2 +b 2) and the operator norm inequality,∥Ax∥ 2 ≤ ∥A∥ 2∥x∥2, we obtain: ∆(θ; ˜Πλ)≤2∥∇ θT(θ) ⊤(λπref −λ π)∥2 2 + 2 (λL −λ Lref )2 ∥∇θl(θ;x 1:n)∥2 2 ≤2∥λ πref −λ π∥2 2 ∥∇θT(θ)∥ 2 2 + 2 (λL −λ Lref )2 ∥∇θl(θ;x 1:n)∥2 2. Dividing by p V...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.