EvoRec: Self Evolving Agentic Recommender Systems
Pith reviewed 2026-06-30 10:45 UTC · model grok-4.3
The pith
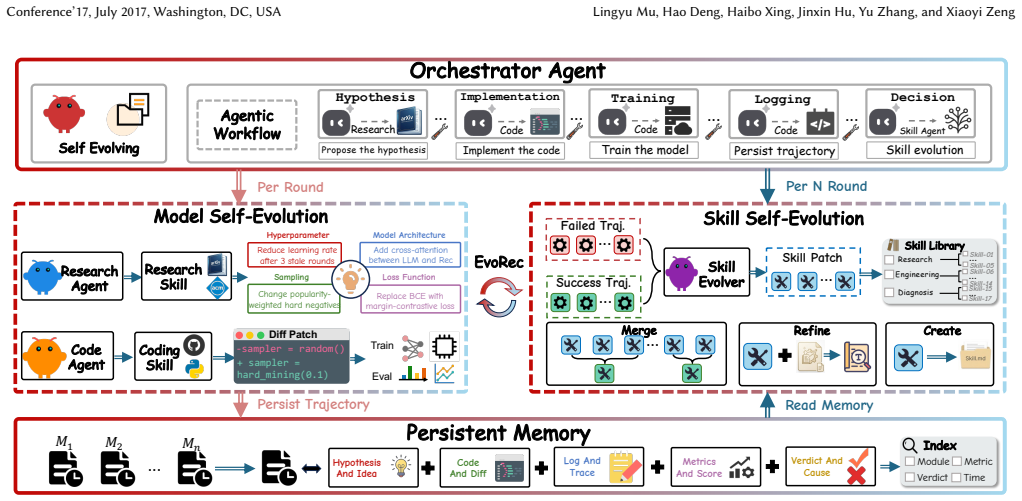
EvoRec uses a Skill Evolver to co-evolve both recommender models and the optimization methodology that drives them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvoRec shows that a multi-agent system can co-evolve the recommendation model and the optimization methodology by letting the Skill Evolver distill reusable methodology from a persistent Memory of past experiments, thereby generating ideas outside any predefined range.
What carries the argument
The Skill Evolver, which periodically distills reusable methodology from the persistent Memory of past experiments to expand the space of future model updates.
If this is right
- Offline metrics rise by up to 5.54 percent over the strongest baseline on two public benchmarks and one industrial dataset.
- An online A/B test records a 1.85 percent revenue increase and a 1.02 percent CTR gain.
- The optimization process moves from repeated search inside a preset space to the generation of structurally new approaches.
Where Pith is reading between the lines
- The same distillation loop could be tested on other automated design tasks such as neural architecture search or hyperparameter tuning pipelines.
- The accumulated Memory and distilled skills might serve as a transferable asset when the same system is applied to a different recommendation domain.
- One could measure whether the rate of new idea generation slows after many iterations or continues to grow with larger Memory stores.
Load-bearing premise
The Skill Evolver can reliably turn records of past experiments into reusable optimization ideas that lie outside the initial search range.
What would settle it
Running the full EvoRec loop on a held-out dataset produces no optimization ideas outside the starting range and yields no measurable lift over a fixed-range agent baseline.
Figures
read the original abstract
Optimizing modern recommender systems still relies heavily on engineers iterating by hand, which is slow and bounded by individual expertise. LLM-based agents open a path toward automating this loop, yet two issues remain. First, the agent is used only as a code translator and accumulates no methodology across iterations. Second, the optimization space is confined to a predefined range and rarely introduces structurally new ideas. To address these problems, we propose EvoRec, a multi-agent framework that co-evolves the recommendation model and the optimization methodology driving it. Four collaborating agents carry out a dual-track loop: the Research Agent and Code Agent iterate the model each round, while the Skill Evolver periodically distills reusable methodology from a persistent Memory of past experiments. Experiments on two public benchmarks and one large-scale industrial dataset show that EvoRec improves offline metrics by up to 5.54% over the strongest baseline, and an online A/B test delivers a 1.85% revenue lift and a 1.02% CTR gain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EvoRec, a multi-agent framework for self-evolving recommender systems. Four agents execute a dual-track co-evolution loop: the Research Agent and Code Agent iterate on the recommendation model each round, while the Skill Evolver periodically distills reusable methodology from a persistent Memory of past experiments. The central claim is that this addresses limitations of prior agentic systems (code translation only, predefined optimization ranges) and yields up to 5.54% offline metric gains on two public benchmarks plus one industrial dataset, plus 1.85% revenue lift and 1.02% CTR gain in an online A/B test.
Significance. If the experimental results hold and the Skill Evolver component is shown to produce structurally novel optimization ideas (rather than longer iteration or better prompting), the work could meaningfully advance automated optimization of recommender systems by enabling methodology accumulation across experiments.
major comments (2)
- [Abstract] Abstract: the headline performance claims (up to 5.54% offline improvement, 1.85% revenue lift) are presented with no information on baselines, statistical tests, data splits, controls, or variance, which is load-bearing for evaluating whether the dual-track co-evolution is responsible for the gains.
- [Abstract] Abstract (and implied § on Skill Evolver): the central attribution of gains to the Skill Evolver distilling reusable methodology from Memory lacks any concrete example of a distilled skill that is structurally new, any ablation removing the Skill Evolver while retaining Research/Code agents, or quantitative evidence isolating the Memory-to-skill pathway as the causal driver; without this the claim that EvoRec exceeds prior agentic systems' predefined-range limitation cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the attribution of gains to the Skill Evolver. We address each point below and indicate where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance claims (up to 5.54% offline improvement, 1.85% revenue lift) are presented with no information on baselines, statistical tests, data splits, controls, or variance, which is load-bearing for evaluating whether the dual-track co-evolution is responsible for the gains.
Authors: The abstract is a high-level summary constrained by length. Full details on baselines (strongest prior agentic and non-agentic recommenders), statistical tests (paired t-tests with p<0.05), data splits (standard temporal splits on public benchmarks plus industrial logs), controls, and variance (reported across 5 seeds) appear in Section 4 and the online A/B test subsection. To make the claims more self-contained, we will revise the abstract to briefly reference the strongest baseline and note statistical significance of the reported gains. revision: yes
-
Referee: [Abstract] Abstract (and implied § on Skill Evolver): the central attribution of gains to the Skill Evolver distilling reusable methodology from Memory lacks any concrete example of a distilled skill that is structurally new, any ablation removing the Skill Evolver while retaining Research/Code agents, or quantitative evidence isolating the Memory-to-skill pathway as the causal driver; without this the claim that EvoRec exceeds prior agentic systems' predefined-range limitation cannot be assessed.
Authors: The manuscript describes the Skill Evolver and Memory in Section 3.3 and provides qualitative examples of distilled skills in the appendix. However, the referee is correct that an explicit ablation isolating the Skill Evolver (while keeping Research/Code agents) and quantitative evidence specifically tracing gains to the Memory-to-skill pathway are not present. We will add both in revision: (1) an ablation table removing the Skill Evolver, and (2) concrete examples of structurally novel optimization ideas generated via the Memory pathway, with before/after performance deltas. revision: yes
Circularity Check
No significant circularity in empirical claims
full rationale
The paper describes an agentic framework and reports measured performance lifts from experiments on two public benchmarks plus one industrial dataset, with no equations, derivations, or first-principles predictions that reduce to fitted parameters or self-definitions by construction. All load-bearing claims are presented as direct experimental outcomes rather than quantities forced by internal definitions or self-citation chains. The Skill Evolver component is described procedurally but its contribution is evaluated via overall system results, not via any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Yin Cheng, Liao Zhou, Xiyu Liang, Dihao Luo, Tewei Lee, Kailun Zheng, Wei- wei Zhang, Mingchen Cai, Jian Dong, and Andy Zhang. 2026. Let the Agent Steer: Closed-Loop Ranking Optimization via Influence Exchange.arXiv preprint arXiv:2603.27765(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Ya- dav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Hao Deng, Haibo Xing, Kanefumi Matsuyama, Moyu Zhang, Jinxin Hu, Hong Wen, Yu Zhang, Xiaoyi Zeng, and Jing Zhang. 2025. CSMF: Cascaded Selective Mask Fine-Tuning for Multi-Objective Embedding-Based Retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2122–2131
2025
- [5]
-
[6]
Ruining He and Julian McAuley. 2016. Ups and Downs: Modeling the Visual Evo- lution of Fashion Trends with One-Class Collaborative Filtering. InProceedings of the 25th International Conference on World Wide Web(Montréal, Québec, Canada) (WWW ’16). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 507–517. doi...
-
[7]
Xin He, Kaiyong Zhao, and Xiaowen Chu. 2021. AutoML: A survey of the state- of-the-art.Knowledge-based systems212 (2021), 106622
2021
-
[8]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
- [9]
-
[10]
Qijiong Liu, Jieming Zhu, Quanyu Dai, and Xiao-Ming Wu. 2022. Boosting deep CTR prediction with a plug-and-play pre-trainer for news recommendation. In Proceedings of the 29th International Conference on Computational Linguistics. 2823–2833
2022
-
[11]
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tong- wen Huang, and Xiangxiang Chu. 2026. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
2026Reg4rec: Reasoning-enhanced generative model for large-scale recommendation systems
Lingyu Mu, Hao Deng, Haibo Xing, Jinxin Hu, Yu Zhang, Xiaoyi Zeng, and Jing Zhang. 2026Reg4rec: Reasoning-enhanced generative model for large-scale recommendation systems. Masked Diffusion Generative Recommendation.arXiv preprint arXiv:2601.19501(2026Reg4rec: Reasoning-enhanced generative model for large-scale recommendation systems)
-
[13]
Lingyu Mu, Zhengxiao Liu, Zhitong Zhu, and Zheng Lin. 2025. Trust-GRS: A Trustworthy Training Framework for Graph Neural Network Based Recom- mender Systems Against Shilling Attacks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12408–12416
2025
-
[14]
Aashiq Muhamed, Iman Keivanloo, Sujan Perera, James Mracek, Yi Xu, Qingjun Cui, Santosh Rajagopalan, Belinda Zeng, and Trishul Chilimbi. 2021. CTR-BERT: Cost-effective knowledge distillation for billion-parameter teacher models. In NeurIPS Efficient Natural Language and Speech Processing Workshop
2021
-
[15]
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Erchao Zhao, Xiaoxi Jiang, and Guanjun Jiang. 2026. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
-
[17]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. MemGPT: towards LLMs as operating systems. (2023)
2023
-
[18]
Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. 2022. Pinner- former: Sequence modeling for user representation at pinterest. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 3702–3712
2022
-
[19]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
-
[20]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[21]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
- [22]
- [23]
- [24]
-
[25]
Shoujin Wang, Longbing Cao, Yan Wang, Quan Z Sheng, Mehmet A Orgun, and Defu Lian. 2021. A survey on session-based recommender systems.ACM Computing Surveys (CSUR)54, 7 (2021), 1–38
2021
-
[26]
Bin Wu, Xiaowen Yin, Xun Su, and Mingliang Xu. 2026. Modeling Multi-Grained User Interests for Sequential Recommendation.IEEE Transactions on Computa- tional Social Systems(2026)
2026
-
[27]
Chuhan Wu, Fangzhao Wu, Tao Qi, and Yongfeng Huang. 2021. Empowering news recommendation with pre-trained language models. InProceedings of the 44th international ACM SIGIR conference on research and development in informa- tion retrieval. 1652–1656
2021
- [29]
-
[30]
Renjun Xu and Yang Yan. 2026. Agent skills for large language models: Architec- ture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [31]
-
[32]
Chao Yi, Dian Chen, Gaoyang Guo, Jiakai Tang, Jian Wu, Jing Yu, Mao Zhang, Wen Chen, Wenjun Yang, Yujie Luo, et al. 2025. RecGPT-V2 Technical Report. arXiv preprint arXiv:2512.14503(2025). Conference’17, July 2017, Washington, DC, USA Lingyu Mu, Hao Deng, Haibo Xing, Jinxin Hu, Yu Zhang, and Xiaoyi Zeng
-
[33]
Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to go next for recommender systems? id- vs. modality-based recommender models revisited. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2639–2649
2023
-
[34]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei-Chieh Huang, Yifei Yao, Kening Zheng, et al. 2026. Coevoskills: Self-evolving agent skills via co-evolutionary verification.arXiv preprint arXiv:2604.01687(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Song Zhang, Nan Zheng, and Danli Wang. 2022. GBERT: Pre-training user representations for ephemeral group recommendation. InProceedings of the 31st ACM international conference on information & knowledge management. 2631– 2639
2022
-
[37]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for se- quential recommendation with mutual information maximization. InProceedings of the 29th ACM international conference on information & knowledge management. 1893–1902
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.