SHIFT: Dynamic Compute Relocation Framework for Communication-Aware Chiplet-Based Systems
Pith reviewed 2026-06-30 08:54 UTC · model grok-4.3
The pith
SHIFT relocates entire compute node contexts in chiplet systems to cut communication costs, delivering up to 12.5x throughput and 76.8% latency gains in simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
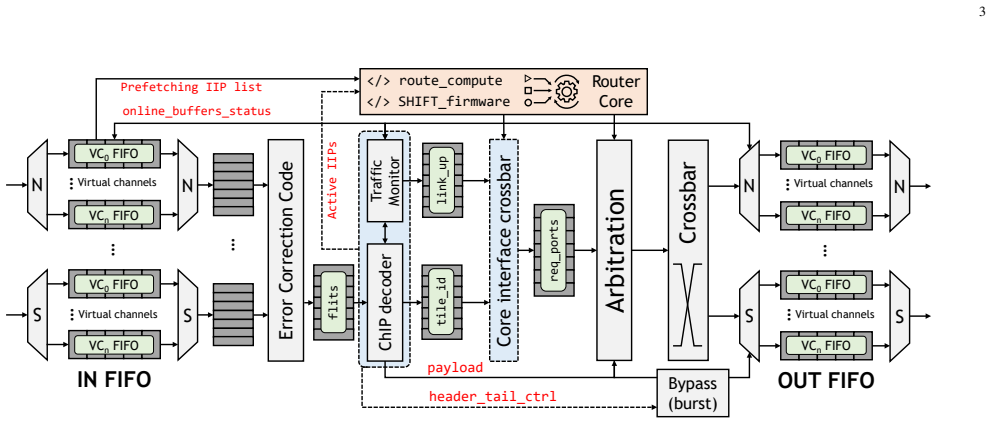
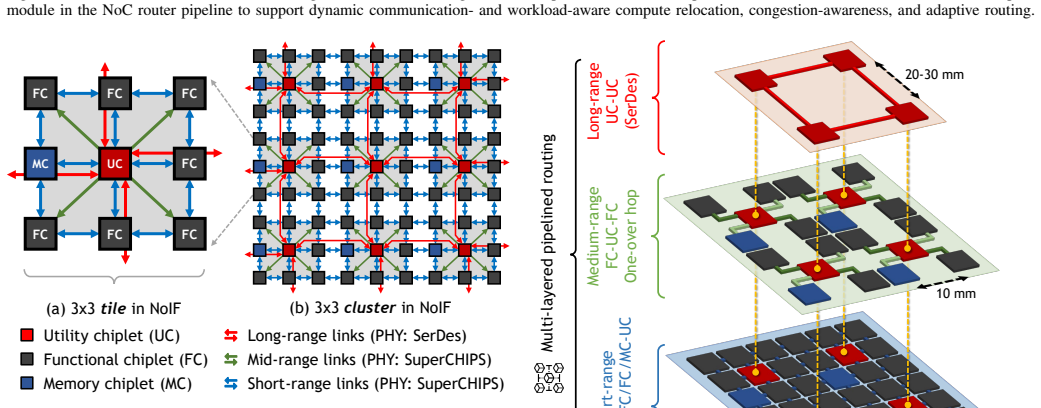
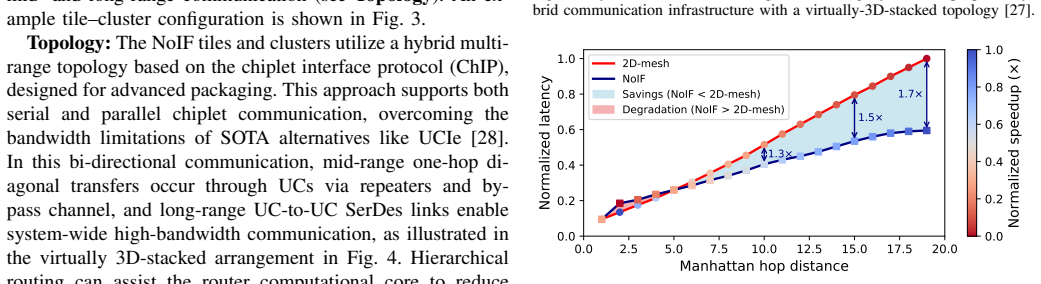
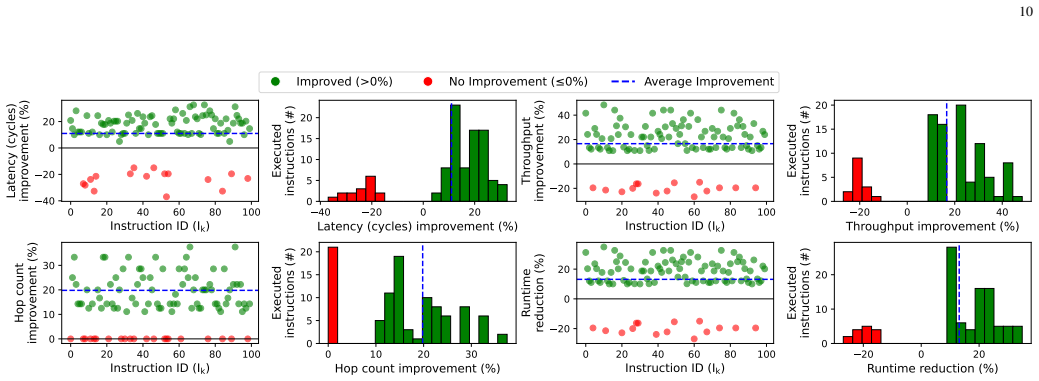
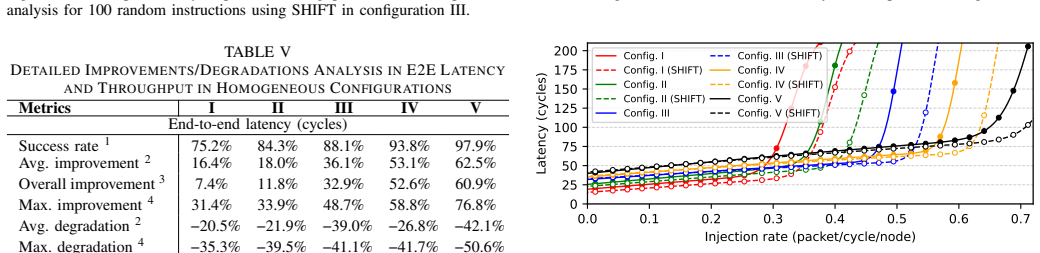
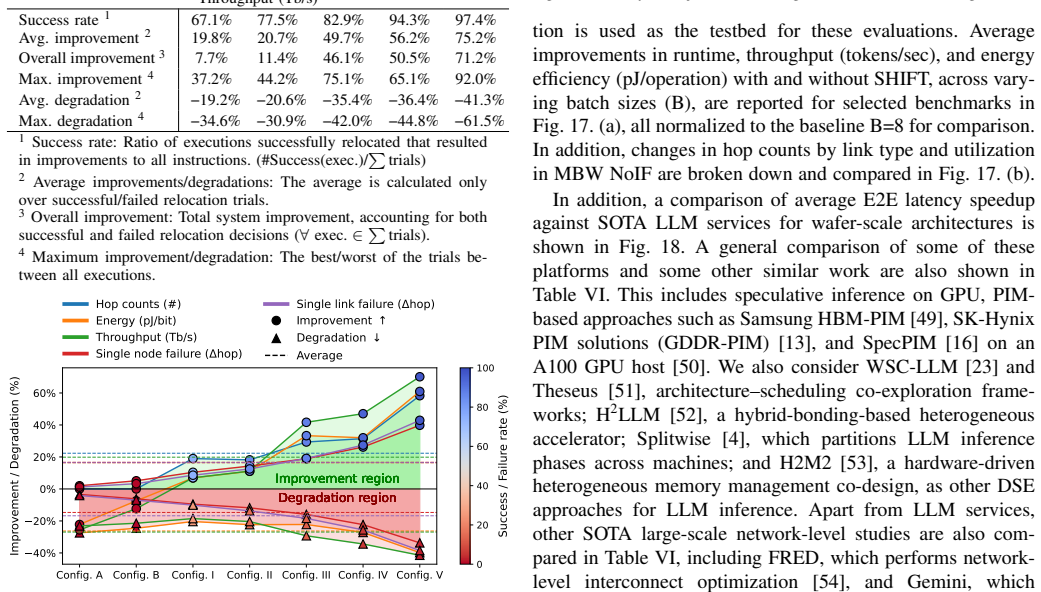
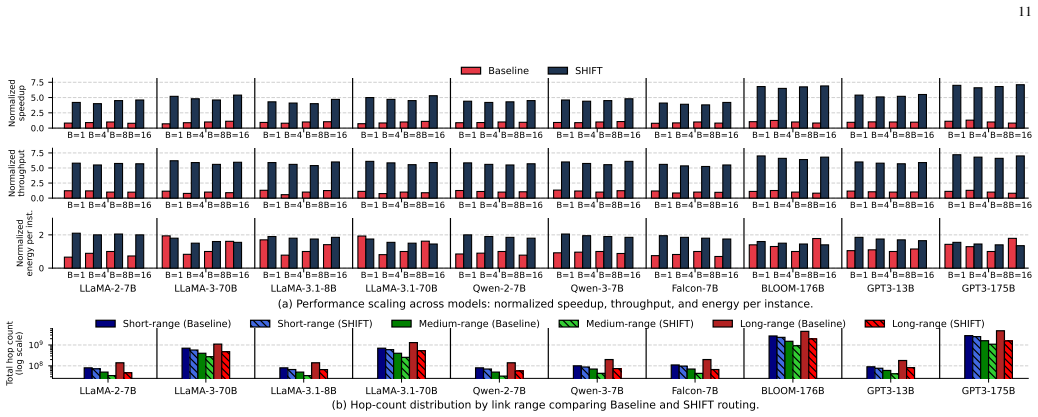
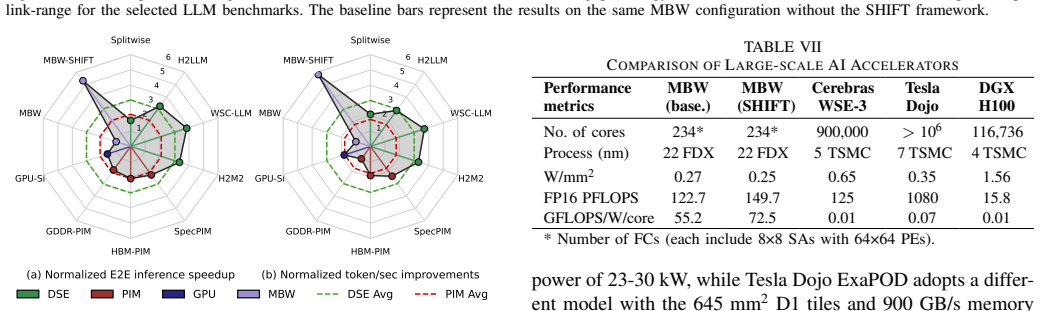
SHIFT is a dynamic compute relocation framework for communication-aware chiplet-based systems. It transfers compute node context and data to more suitably positioned nodes using utility chiplets that perform both routing and relocation. The framework applies adaptive scheduling via a modified shortest-path algorithm augmented by an ML-assisted policy for traffic inference. On random vectors and data patterns the approach achieves relocation success from 75.2% to 97.9%, average latency reductions of 16.4%-62.5% (max 76.8%), throughput gains up to 12.5x, ~8% lower power per unit area, up to 58.3% lower energy-per-bit, and 18% higher performance. On LLM workloads it yields average gains of 4.9x
What carries the argument
Dynamic relocation of entire compute node contexts and data to suitably positioned nodes, executed by utility chiplets that serve as intelligent routing and relocation agents, guided by modified shortest-path scheduling and an ML-assisted traffic-inference policy.
If this is right
- Latency reductions between 16.4% and 76.8% become available for large-scale heterogeneous workloads.
- Throughput can increase by as much as 12.5x while power dissipation per unit area drops roughly 8%.
- Energy-per-bit can fall by up to 58.3% and overall performance can rise 18%.
- LLM workloads can see average gains of 4.9x in runtime, 5.9x in throughput, and 1.8x in energy-efficiency over existing wafer-scale services.
Where Pith is reading between the lines
- The same relocation logic could be tested on other heterogeneous integration platforms such as multi-chip modules or 3D-stacked dies.
- The ML traffic-inference policy might be retrained on traces from different application domains to check generality.
- Integration of the utility-chiplet concept into existing network-on-chip tool flows could be evaluated for design-time overhead.
- Cycle-accurate emulation on FPGA prototypes of the multi-layered routing fabric would provide an intermediate validation step before silicon.
Load-bearing premise
The simulation model of the fine-pitch chiplet architecture with multi-layered routing and the chosen random instruction vectors, data patterns, and LLM workloads accurately represents real traffic and hardware behavior.
What would settle it
Measure actual latency, throughput, and energy metrics on fabricated fine-pitch chiplet hardware running the same LLM workloads and compare against the reported simulation improvements of 4.9x runtime and 5.9x throughput.
Figures
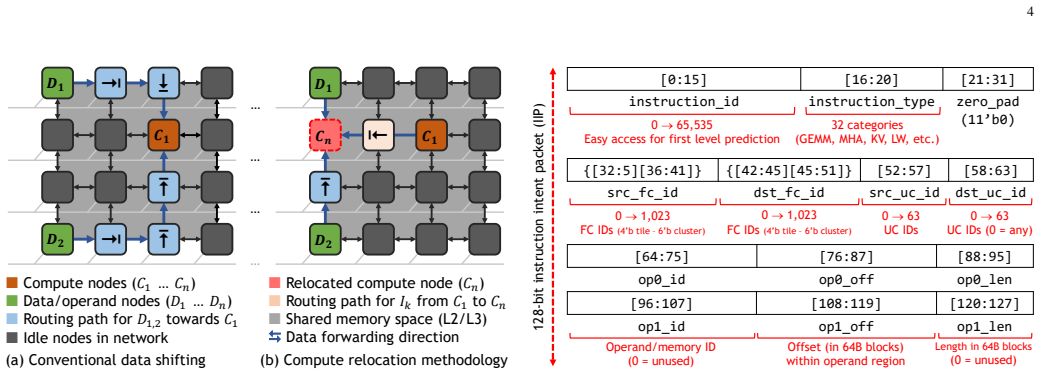
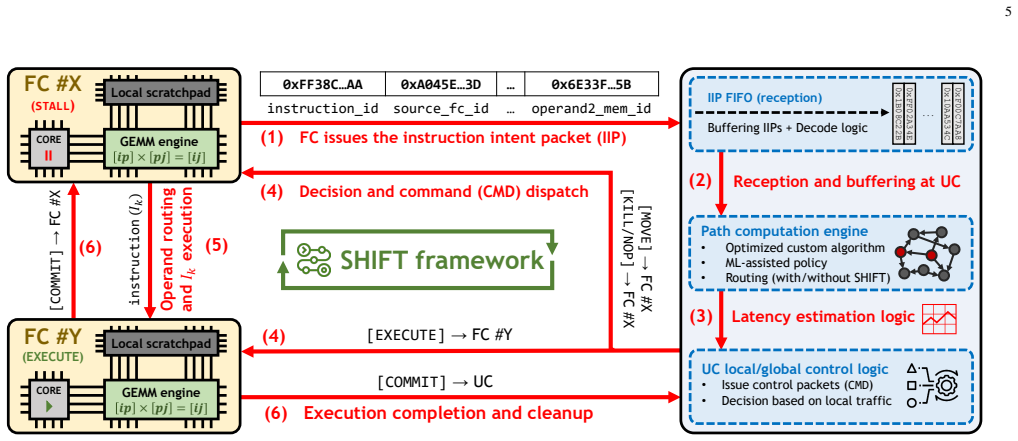


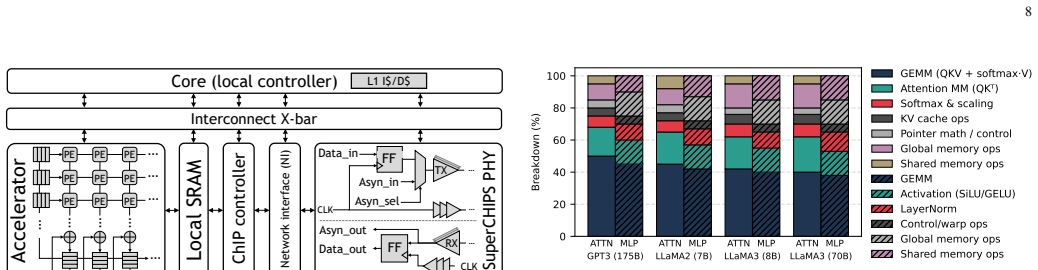

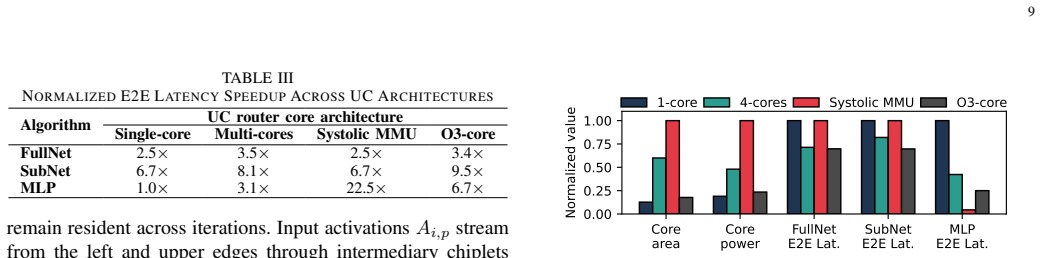


read the original abstract
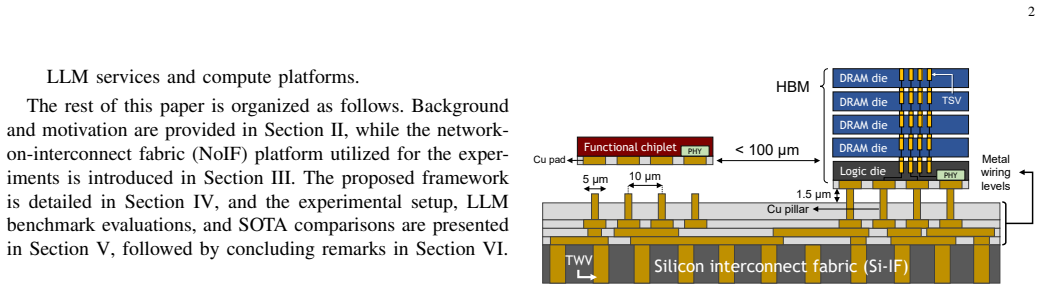
The increasing communication complexity of large-scale heterogeneous systems has motivated runtime methodologies for communication-aware workload placement and routing optimization. These communication limitations are addressed in this paper by proposing SHIFT, a novel topology-agnostic approach that transfers compute node context and data to a more suitably positioned node, rather than only shifting data as in conventional networks-on-chip. The proposed strategy is evaluated on a chiplet-based architecture utilizing a fine-pitch integration platform featuring multiple bandwidth-domains for heterogeneous workloads. The proposed architecture employs multi-layered routing between functional or memory chiplets and utility chiplets, which serve as intelligent nodes for routing and compute relocation. Adaptive scheduling and routing utilize a modified shortest-path algorithm for large-scale systems, complemented by a lightweight ML-assisted policy that infers traffic conditions to improve adaptivity. To establish a performance baseline, the initial assessment uses random instruction vectors and data patterns to evaluate the fundamental capabilities of SHIFT. Simulation results exhibit successful relocations over total trials ranging from 75.2% to 97.9% across configurations, with average latency improvements of 16.4%-62.5% and a maximum of 76.8%. In addition, throughput is improved by up to 12.5x, power dissipation per unit area is reduced by ~8%, energy-per-bit is reduced by up to 58.3%, and performance is improved by 18%. To evaluate efficiency under high logic and data density, the framework was tested on standard LLM workloads. Results exhibit average improvements of 4.9x, 5.9x, and 1.8x in runtime, throughput, and energy-efficiency, respectively, surpassing state-of-the-art wafer-scale LLM services and demonstrating compatibility with large-scale platforms and applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SHIFT, a topology-agnostic dynamic compute relocation framework for chiplet-based systems that moves compute node context and data to better-positioned nodes using utility chiplets with multi-layered routing. It employs a modified shortest-path algorithm for adaptive scheduling and routing, augmented by a lightweight ML-assisted policy for traffic inference. Evaluations rely on simulations with random instruction vectors/data patterns and standard LLM workloads, claiming relocation success rates of 75.2%-97.9%, latency reductions of 16.4%-62.5% (max 76.8%), throughput gains up to 12.5x, power/area reduction of ~8%, energy-per-bit reduction up to 58.3%, overall performance improvement of 18%, and for LLMs average gains of 4.9x runtime, 5.9x throughput, and 1.8x energy-efficiency over state-of-the-art wafer-scale services.
Significance. If the simulation results prove reliable after proper validation and methodology disclosure, the work could provide a useful direction for communication optimization in large-scale heterogeneous chiplet systems, especially for high-density AI workloads. The distinction between compute relocation and conventional data movement is a potentially useful conceptual shift for NoC and integration-platform design.
major comments (2)
- [Abstract] Abstract (and Evaluation section): All headline quantitative claims (75.2–97.9 % relocation success, 16.4–76.8 % latency reduction, 12.5× throughput, 4.9× LLM runtime improvement, etc.) are presented as direct outputs of an unspecified simulation engine. No description is given of the simulator, baseline implementations, how the ML policy was trained/validated, workload generation details, or statistical measures such as error bars. This is load-bearing because the central performance assertions rest entirely on these results.
- [Abstract] Abstract (and Evaluation section): The simulation model of the fine-pitch chiplet architecture, multi-layered routing between functional/memory/utility chiplets, bandwidth domains, and chosen traffic patterns (random vectors + LLM traces) receives no validation against silicon measurements, RTL correlation, or cycle-accurate reference traces. The assumption that modeled delays and traffic statistics match real hardware behavior is therefore untested and directly supports every reported speedup and efficiency number.
minor comments (1)
- [Abstract] The claim of surpassing “state-of-the-art wafer-scale LLM services” is stated without citing the specific prior works or quantitative comparisons used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on methodological transparency. We address each point below and will revise the manuscript accordingly to strengthen the evaluation section.
read point-by-point responses
-
Referee: [Abstract] Abstract (and Evaluation section): All headline quantitative claims (75.2–97.9 % relocation success, 16.4–76.8 % latency reduction, 12.5× throughput, 4.9× LLM runtime improvement, etc.) are presented as direct outputs of an unspecified simulation engine. No description is given of the simulator, baseline implementations, how the ML policy was trained/validated, workload generation details, or statistical measures such as error bars. This is load-bearing because the central performance assertions rest entirely on these results.
Authors: We agree that the manuscript requires expanded disclosure of the simulation methodology to support reproducibility and the reported claims. In the revised version we will add a dedicated subsection detailing the simulator, baseline implementations, the training/validation procedure and hyperparameters for the ML-assisted policy, workload generation process for both random vectors and LLM traces, and statistical measures including error bars or variance across runs. revision: yes
-
Referee: [Abstract] Abstract (and Evaluation section): The simulation model of the fine-pitch chiplet architecture, multi-layered routing between functional/memory/utility chiplets, bandwidth domains, and chosen traffic patterns (random vectors + LLM traces) receives no validation against silicon measurements, RTL correlation, or cycle-accurate reference traces. The assumption that modeled delays and traffic statistics match real hardware behavior is therefore untested and directly supports every reported speedup and efficiency number.
Authors: The evaluation relies on a parameterized cycle-accurate simulation model derived from published chiplet integration parameters and NoC literature. We acknowledge that direct silicon or RTL correlation for this specific architecture is not provided. In revision we will expand the model description, cite the sources of all timing and bandwidth parameters, add sensitivity analysis, and explicitly state the modeling assumptions and limitations. Full hardware validation lies beyond the scope of the current simulation study. revision: partial
Circularity Check
No circularity; simulation results are direct outputs without fitted predictions or self-referential derivations
full rationale
The paper proposes the SHIFT framework for dynamic compute relocation in chiplet systems and reports performance metrics from simulations using random instruction vectors, data patterns, and standard LLM workloads. No equations, fitted parameters, or derivations are described that reduce by construction to the inputs. Results (e.g., relocation success rates, latency improvements) are presented as simulator outputs rather than predictions derived from self-defined or fitted quantities. Any self-citations are not load-bearing for the central claims, and the evaluation chain remains independent of the reported numbers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High-Bandwidth Chiplet Interconnects for Advanced Packaging Technologies in AI/ML Applica- tions: Challenges and Solutions,
S. Li, M.-S. Lin, W.-C. Chen, and C.-C. Tsai, “High-Bandwidth Chiplet Interconnects for Advanced Packaging Technologies in AI/ML Applica- tions: Challenges and Solutions,”IEEE Open Journal of the Solid-State Circuits Society, V ol. 4, pp. 351–364, 2024
2024
-
[2]
Silicon Interconnect Fabric: A Versatile Heterogeneous Integration Platform for AI Systems,
S. S. Iyer, S. Jangam, and B. Vaisband, “Silicon Interconnect Fabric: A Versatile Heterogeneous Integration Platform for AI Systems,”IBM Journal of Research and Development, V ol. 63, No. 3, pp. 5:1–5:16, Nov.-Dec. 2019
2019
-
[3]
Attention is all you need,
A. Vaswaniet al., “Attention is all you need,”Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17, p. 6000–6010. Red Hook, NY , USA: Curran Associates Inc., 2017
2017
-
[4]
Splitwise: Efficient Generative LLM Inference Using Phase Splitting,
P. Patelet al., “Splitwise: Efficient Generative LLM Inference Using Phase Splitting,”2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pp. 118–132, 2024
2024
-
[5]
A 7-nm 4-GHz Arm¹-Core-Based CoWoS¹ Chiplet Design for High-Performance Computing,
M.-S. Linet al., “A 7-nm 4-GHz Arm¹-Core-Based CoWoS¹ Chiplet Design for High-Performance Computing,”IEEE Journal of Solid-State Circuits (JSSC), V ol. 55, No. 4, pp. 956–966, Apr. 2020. 13
2020
-
[6]
8.1 Lakefield and Mobility Compute: A 3D Stacked 10nm and 22FFL Hybrid Processor System in 12×12mm 2, 1mm Package-on-Package,
W. Gomeset al., “8.1 Lakefield and Mobility Compute: A 3D Stacked 10nm and 22FFL Hybrid Processor System in 12×12mm 2, 1mm Package-on-Package,”Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), pp. 144–146, Feb. 2020
2020
-
[7]
Fine-Grained DRAM: Energy-Efficient DRAM for Extreme Bandwidth Systems,
M. O’Connoret al., “Fine-Grained DRAM: Energy-Efficient DRAM for Extreme Bandwidth Systems,”Proceedings of the IEEE/ACM In- ternational Symposium on Microarchitecture (MICRO), pp. 41–54, Oct. 2017
2017
-
[8]
A Cost-Aware Operator Migration Approach for Dis- tributed Stream Processing System,
J. Tanet al., “A Cost-Aware Operator Migration Approach for Dis- tributed Stream Processing System,”IEEE Transactions on Cloud Com- puting, V ol. 13, No. 1, pp. 441–454, 2025
2025
-
[9]
Task mapping on SMART NoC: Contention matters, not the distance,
L. Yanget al., “Task mapping on SMART NoC: Contention matters, not the distance,”2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), pp. 1–6, 2017
2017
-
[10]
A software-defined tensor streaming multiprocessor for large-scale machine learning,
D. Abtset al., “A software-defined tensor streaming multiprocessor for large-scale machine learning,”Proceedings of the 49th Annual International Symposium on Computer Architecture, ser. ISCA ’22, p. 567–580. New York, NY , USA: Association for Computing Machinery,
-
[11]
[Online]. Available: https://doi.org/10.1145/3470496.3527405
-
[12]
Azul: An Accelerator for Sparse Iterative Solvers Leveraging Distributed On-Chip Memory,
A. Feldmannet al., “Azul: An Accelerator for Sparse Iterative Solvers Leveraging Distributed On-Chip Memory,”2024 57th IEEE/ACM Inter- national Symposium on Microarchitecture (MICRO), pp. 643–656, 2024
2024
-
[13]
Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology,
V . Seshadriet al., “Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology,”2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 273–287, 2017
2017
-
[14]
System architecture and software stack for GDDR6- AiM,
Y . Kwonet al., “System architecture and software stack for GDDR6- AiM,”2022 IEEE Hot Chips 34 Symposium (HCS), Cupertino, CA, USA, pp. 1–25, 2022
2022
-
[15]
Shared-PIM: Enabling Concurrent Computation and Data Flow for Faster Processing-in-DRAM,
A. Mamdouhet al., “Shared-PIM: Enabling Concurrent Computation and Data Flow for Faster Processing-in-DRAM,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, V ol. 44, No. 11, pp. 4395–4404, 2025
2025
-
[16]
S. Maet al., “PIMSAB: A Processing-In-Memory System with Spatially-Aware Communication and Bit-Serial-Aware Computation,” ACM Trans. Archit. Code Optim., V ol. 21, No. 4, Nov. 2024. [Online]. Available: https://doi.org/10.1145/3690824
-
[17]
C. Liet al., “SpecPIM: Accelerating Speculative Inference on PIM-Enabled System via Architecture-Dataflow Co-Exploration,” Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 3, ser. ASPLOS ’24, p. 950–965. New York, NY , USA: Association for Computing Machinery, 2024. [Onl...
-
[18]
CoWoS Architecture Evolution for Next Generation HPC on 2.5D System in Package,
Y .-C. Huet al., “CoWoS Architecture Evolution for Next Generation HPC on 2.5D System in Package,”Proceedings of the IEEE Interna- tional Electronic Components and Technology Conference (ECTC), pp. 1022–1026, May 2023
2023
-
[19]
On Optimizing Inter- and Intra-Chiplet Interconnection Topologies for Robust Multi-Chiplet Systems,
X. Wanget al., “On Optimizing Inter- and Intra-Chiplet Interconnection Topologies for Robust Multi-Chiplet Systems,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, V ol. 44, No. 10, pp. 3976–3989, 2025
2025
-
[20]
Kite: A Family of Heterogeneous Interposer Topologies Enabled via Accurate Interconnect Modeling,
S. Bharadwaj, J. Yin, B. Beckmann, and T. Krishna, “Kite: A Family of Heterogeneous Interposer Topologies Enabled via Accurate Interconnect Modeling,”Proceedings of the ACM/IEEE Design Automation Confer- ence (DAC), pp. 1–6, 2020
2020
-
[21]
Floorplet: Performance-Aware Floorplan Framework for Chiplet Integration,
S. Chenet al., “Floorplet: Performance-Aware Floorplan Framework for Chiplet Integration,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, V ol. 43, No. 6, pp. 1638–1649, 2024
2024
-
[22]
H3D-LLM: Heterogeneous 3D Chiplet Design for LLM Inference with Dynamic Task Scheduling and Memory-Aware Orchestration,
H. Kouet al., “H3D-LLM: Heterogeneous 3D Chiplet Design for LLM Inference with Dynamic Task Scheduling and Memory-Aware Orchestration,”2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD), pp. 1–9, 2025
2025
-
[23]
WaferLLM: Large Language Model Inference at Wafer Scale,
C. Heet al., “WaferLLM: Large Language Model Inference at Wafer Scale,” 2025. [Online]. Available: https://arxiv.org/abs/2502.04563
-
[24]
WSC-LLM: Efficient LLM Service and Architecture Co-exploration for Wafer-scale Chips,
Z. Xuet al., “WSC-LLM: Efficient LLM Service and Architecture Co-exploration for Wafer-scale Chips,”Proceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25, p. 1–17. New York, NY , USA: Association for Computing Machinery,
-
[25]
Available: https://doi.org/10.1145/3695053.3731101
[Online]. Available: https://doi.org/10.1145/3695053.3731101
-
[26]
Hybrid Interconnect Infrastructure for Inter-Chiplet Communication in Wafer- Scale Systems,
Y . Safari, R. Mohammadrezaee, D. Al Saleh, and B. Vaisband, “Hybrid Interconnect Infrastructure for Inter-Chiplet Communication in Wafer- Scale Systems,”Proceedings of the IEEE International Electronic Com- ponents and Technology Conference (ECTC), pp. 2229–2236, May 2024
2024
-
[27]
Power Delivery for Silicon Interconnect Fabric,
Y . Safari and B. Vaisband, “Power Delivery for Silicon Interconnect Fabric,”2021 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5, 2021
2021
-
[28]
Communication Considerations for Silicon Interconnect Fabric,
B. Vaisband and S. S. Iyer, “Communication Considerations for Silicon Interconnect Fabric,”Proceedings of the Workshop on System Level Interconnect Prediction (SLIP), pp. 1–6, Jun. 2019
2019
-
[29]
Multi-Range Communication for Chiplet-Based Systems,
A. Delavari, A. Chandrasekaran, and B. Vaisband, “Multi-Range Communication for Chiplet-Based Systems,”Proceedings of the Great Lakes Symposium on VLSI 2026, ser. GLSVLSI ’26, p. 724–729. New York, NY , USA: Association for Computing Machinery, 2026. [Online]. Available: https://doi.org/10.1145/3787109.3815249
-
[30]
Chiplets Interface Protocol (ChIP) for Ultra-Large-Scale Applications,
A. Delavari and B. Vaisband, “Chiplets Interface Protocol (ChIP) for Ultra-Large-Scale Applications,”IEEE Journal on Emerging and Selected Topics in Circuits and Systems, V ol. 15, No. 3, 2025
2025
-
[31]
ReD: A Reliable and Deadlock- Free Routing for 2.5-D Chiplet-Based Interposer Networks,
E. Taheri, S. Pasricha, and M. Nikdast, “ReD: A Reliable and Deadlock- Free Routing for 2.5-D Chiplet-Based Interposer Networks,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, V ol. 43, No. 12, pp. 4599–4612, 2024
2024
-
[32]
BuffeRS: A Buffer Reservation Scheduling Strategy for Router Bypassing in NoCs and Multichiplet Networks,
Z. Liu, X. Wu, and Y . Ye, “BuffeRS: A Buffer Reservation Scheduling Strategy for Router Bypassing in NoCs and Multichiplet Networks,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, V ol. 45, No. 6, pp. 2635–2648, 2026
2026
-
[33]
Breaking the Sorting Barrier for Directed Single-Source Shortest Paths,
R. Duanet al., “Breaking the Sorting Barrier for Directed Single-Source Shortest Paths,” 2025. [Online]. Available: https: //arxiv.org/abs/2504.17033
-
[34]
Dijkstra-Through-Time: Ahead of time hardware scheduling method for deterministic workloads,
V . T. Roche and P. M. Velayuthan, “Dijkstra-Through-Time: Ahead of time hardware scheduling method for deterministic workloads,” 2021. [Online]. Available: https://arxiv.org/abs/2112.10486
-
[35]
A Support Vector Regression (SVR)-Based Latency Model for Network-on-Chip (NoC) Architectures,
Z.-L. Qianet al., “A Support Vector Regression (SVR)-Based Latency Model for Network-on-Chip (NoC) Architectures,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, V ol. 35, No. 3, pp. 471–484, 2016
2016
-
[36]
LPNet: A DNN based latency prediction technique for application mapping in Network-on-Chip design,
R. Sambangi, H. Manghnani, and S. Chattopadhyay, “LPNet: A DNN based latency prediction technique for application mapping in Network-on-Chip design,”Microprocessors and Microsystems, V ol. 87, p. 104370, 2021. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0141933121005214
2021
-
[37]
Fast and Accurate NoC Latency Estimation for Application-Specific Traffics via Machine Learning,
Y . Li and P. Zhou, “Fast and Accurate NoC Latency Estimation for Application-Specific Traffics via Machine Learning,”IEEE Transactions on Circuits and Systems II: Express Briefs, V ol. 70, No. 9, pp. 3569– 3573, 2023
2023
-
[38]
PreNoc: Neural Network based Predictive Routing for Network-on-Chip Architectures,
M. A. Kinsy, S. Khadka, and M. Isakov, “PreNoc: Neural Network based Predictive Routing for Network-on-Chip Architectures,”Proceedings of the Great Lakes Symposium on VLSI 2017, ser. GLSVLSI ’17, pp. 65–70. New York, NY , USA: Association for Computing Machinery,
2017
-
[39]
Available: https://doi.org/10.1145/3060403.3060406
[Online]. Available: https://doi.org/10.1145/3060403.3060406
-
[40]
DRLAR: A deep reinforcement learning-based adaptive routing framework for network-on-chips,
S. Wanget al., “DRLAR: A deep reinforcement learning-based adaptive routing framework for network-on-chips,”Computer Networks, V ol. 246, p. 110419, 2024. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S1389128624002512
2024
-
[41]
Gemmini: Enabling Systematic Deep-Learning Archi- tecture Evaluation via Full-Stack Integration,
H. Gencet al., “Gemmini: Enabling Systematic Deep-Learning Archi- tecture Evaluation via Full-Stack Integration,”Proceedings of the 58th Annual Design Automation Conference (DAC), 2021
2021
-
[42]
Silicon-Interconnect Fabric for Fine-Pitch (≤10 µm) Heterogeneous Integration,
S. Jangam and S. S. Iyer, “Silicon-Interconnect Fabric for Fine-Pitch (≤10 µm) Heterogeneous Integration,”IEEE Transactions on Com- ponents, Packaging and Manufacturing Technology (TCPMT), V ol. 11, No. 5, pp. 727–738, May 2021
2021
-
[43]
Inside the Cerebras Wafer-Scale Cluster,
S. Lie, “Inside the Cerebras Wafer-Scale Cluster,”IEEE Micro, V ol. 44, No. 3, pp. 49–57, 2024
2024
-
[44]
Architecting Waferscale Processors - A GPU Case Study,
S. Palet al., “Architecting Waferscale Processors - A GPU Case Study,” 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 250–263, 2019
2019
-
[45]
The graph neural networking challenge: a worldwide competition for education in AI/ML for networks,
J. Su ´arez-Varelaet al., “The graph neural networking challenge: a worldwide competition for education in AI/ML for networks,”ACM SIGCOMM Computer Communication Review, V ol. 51, No. 3, pp. 9– 16, 2021
2021
-
[46]
Unveiling the potential of Graph Neural Networks for network modeling and optimization in SDN,
K. Ruseket al., “Unveiling the potential of Graph Neural Networks for network modeling and optimization in SDN,”Proceedings of the 2019 ACM Symposium on SDN Research, ser. SOSR ’19, pp. 140–151. New York, NY , USA: Association for Computing Machinery, 2019. [Online]. Available: https://doi.org/10.1145/3314148.3314357
-
[47]
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning,
L. Zhenget al., “Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning,”16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pp. 559–578. Carlsbad, CA: USENIX Association, Jul. 2022. [Online]. Available: https://www.usenix.org/conference/osdi22/presentation/zheng-lianmin
2022
-
[48]
LLM-Inference-Bench: Inference Bench- marking of Large Language Models on AI Accelerators,
K. T. Chitty-Venkataet al., “LLM-Inference-Bench: Inference Bench- marking of Large Language Models on AI Accelerators,”Proceedings of the SC Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, pp. 1362–1379, 2024. 14
2024
-
[49]
NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing,
G. Heoet al., “NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing,”Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 3, ser. ASPLOS ’24, p. 722–737. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available: https://doi.org/10...
-
[50]
Face, “Models,” https://huggingface.co/models, accessed: 2025-09- 20
H. Face, “Models,” https://huggingface.co/models, accessed: 2025-09- 20
2025
-
[51]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvronet al., “LLaMA 2: Open Foundation and Fine-Tuned Chat Models,” 2023. [Online]. Available: https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Hardware architecture and software stack for PIM based on commercial DRAM technology: Industrial product,
S. Leeet al., “Hardware architecture and software stack for PIM based on commercial DRAM technology: Industrial product,”2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), pp. 43–56, 2021
2021
-
[53]
NVIDIA A100 Tensor Core GPU: Performance and Innovation,
J. Choquetteet al., “NVIDIA A100 Tensor Core GPU: Performance and Innovation,”IEEE Micro, V ol. 41, No. 2, pp. 29–35, Mar. 2021
2021
-
[54]
Theseus: Exploring Efficient Wafer-Scale Chip Design for Large Language Models,
J. Zhuet al., “Theseus: Exploring Efficient Wafer-Scale Chip Design for Large Language Models,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025
2025
-
[55]
C. Liet al., “H2-LLM: Hardware-Dataflow Co-Exploration for Heterogeneous Hybrid-Bonding-based Low-Batch LLM Inference,” Proceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25, p. 194–210. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3695053.3731008
-
[56]
Hardware-based Heterogeneous Memory Management for Large Language Model Inference,
S. Hwanget al., “Hardware-based Heterogeneous Memory Management for Large Language Model Inference,” 2025. [Online]. Available: https://arxiv.org/abs/2504.14893
-
[57]
FRED: A Wafer-scale Fabric for 3D Parallel DNN Training,
S. Rashidiet al., “FRED: A Wafer-scale Fabric for 3D Parallel DNN Training,”Proceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25, p. 34–48. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3695053.3731055
-
[58]
Gemini: Mapping and Architecture Co-exploration for Large-scale DNN Chiplet Accelerators,
J. Caiet al., “Gemini: Mapping and Architecture Co-exploration for Large-scale DNN Chiplet Accelerators,”2024 IEEE International Sym- posium on High-Performance Computer Architecture (HPCA), pp. 156– 171, 2024
2024
-
[59]
Designing a 2048-Chiplet, 14336-Core Waferscale Pro- cessor,
S. Palet al., “Designing a 2048-Chiplet, 14336-Core Waferscale Pro- cessor,”2021 58th ACM/IEEE Design Automation Conference (DAC), pp. 1183–1188, 2021
2048
-
[60]
The Microarchitecture of DOJO, Tesla’s Exa-Scale Computer,
E. Talpeset al., “The Microarchitecture of DOJO, Tesla’s Exa-Scale Computer,”IEEE Micro, V ol. 43, No. 3, pp. 31–39, 2023
2023
-
[61]
NVIDIA Hopper H100 GPU: Scaling Performance,
J. Choquette, “NVIDIA Hopper H100 GPU: Scaling Performance,” IEEE Micro, V ol. 43, No. 3, pp. 9–17, 2023
2023
-
[62]
Language Models are Few-Shot Learners
T. B. Brownet al., “Language Models are Few-Shot Learners,” 2020. [Online]. Available: https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[63]
A. Grattafiori, A. Dubey, and A. Jauhri, “The LLaMA 3 Herd of Models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Benchmarking the Performance of Large Language Models on the Cerebras Wafer Scale Engine,
Z. Zhang, D. Parikh, Y . Zhang, and V . Prasanna, “Benchmarking the Performance of Large Language Models on the Cerebras Wafer Scale Engine,”2024 IEEE High Performance Extreme Computing Conference (HPEC), pp. 1–7, 2024. Arvin Delavari(Student Member, IEEE) received the B.Sc. degree in electrical and electronics engi- neering from Iran University of Scienc...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.