ARGUS: Production-Scale Tracing and Performance Diagnosis for over 10,000-GPU Clusters
Pith reviewed 2026-06-26 15:39 UTC · model grok-4.3
The pith
ARGUS provides always-on fine-grained tracing for over 10,000-GPU clusters at under 2% overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
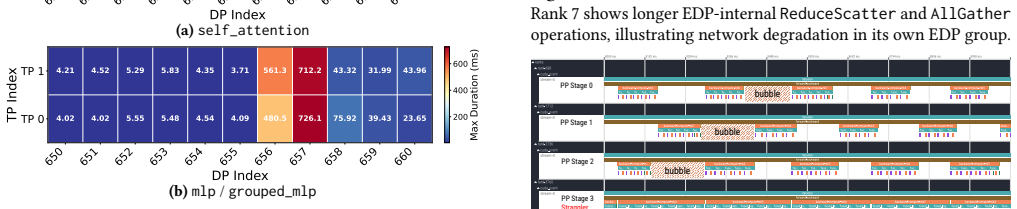
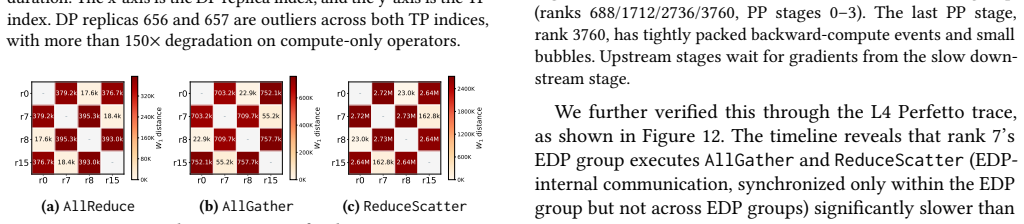
ARGUS decomposes observation along the training call hierarchy into CPU call stacks, framework semantics, and GPU kernel execution, with always-on collection under a combined overhead of less than 2%. It builds a unified data pipeline and compresses raw kernel events by approximately 3,700x from 10 MB to 2.7 KB per rank per step. Its progressive diagnosis framework automatically isolates anomalous windows, straggler ranks, and degraded kernels through iteration-time, phase-level, and kernel-level analysis. Deployed for over six months on a 10,000+ GPU production cluster, ARGUS has supported continuous fail-slow detection and performance optimization across anomalies such as compute straggler
What carries the argument
Hierarchical decomposition of training observations into CPU stacks, framework semantics, and GPU kernels, paired with a unified compression pipeline and staged diagnosis.
If this is right
- Continuous fail-slow detection becomes practical without interrupting training runs.
- Kernel-level insights allow targeted fixes for issues like stragglers and communication degradation.
- Progressive analysis at iteration, phase, and kernel levels narrows down problems automatically.
- Case studies confirm coverage of common anomalies including masked stragglers and JIT stalls.
Where Pith is reading between the lines
- The compression ratios could support scaling the same system to clusters several times larger than 10,000 GPUs.
- Integration of ARGUS data with existing coarse monitors might eliminate the need for separate low-detail tools.
- Wider adoption could shorten debugging cycles for new model architectures by surfacing issues earlier in training.
Load-bearing premise
The hierarchical breakdown of CPU, framework, and kernel layers plus the compression and diagnosis pipeline will identify real production root causes without excessive overhead or loss of accuracy.
What would settle it
A production training run in which a documented performance anomaly occurs but ARGUS reports either more than 2% overhead or fails to flag the affected ranks and kernels.
Figures
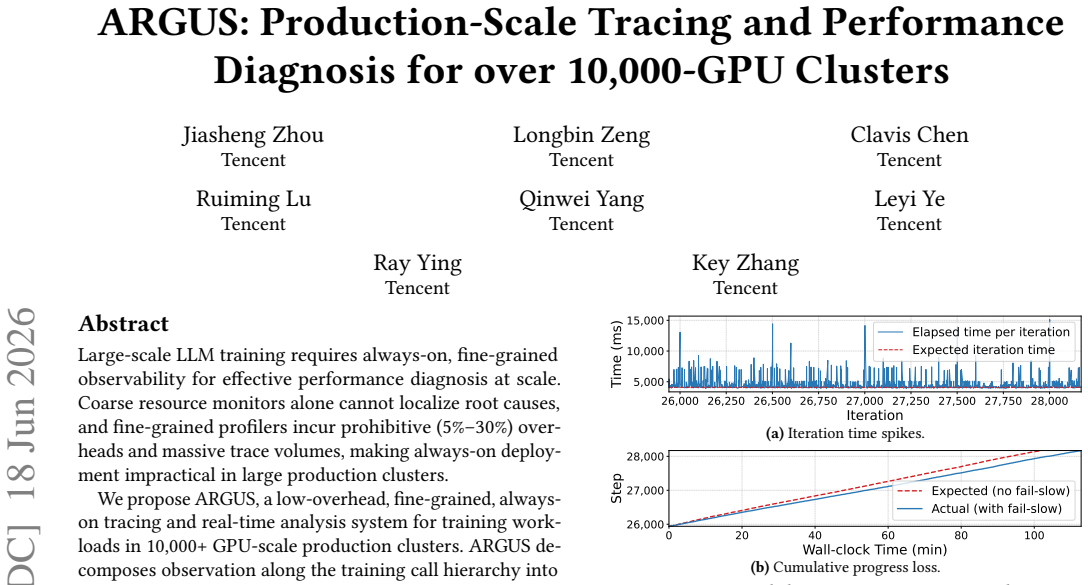

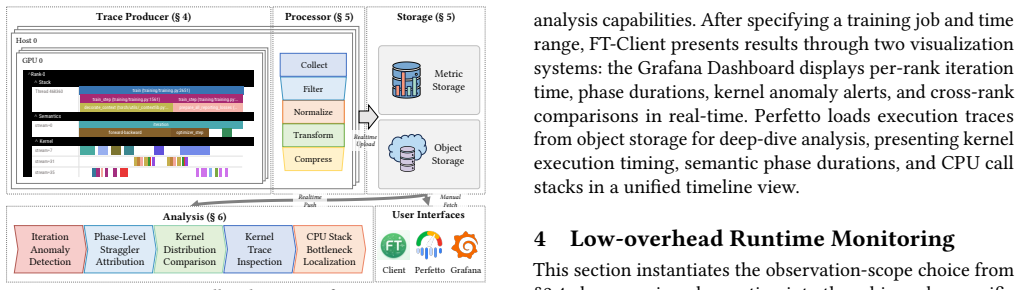



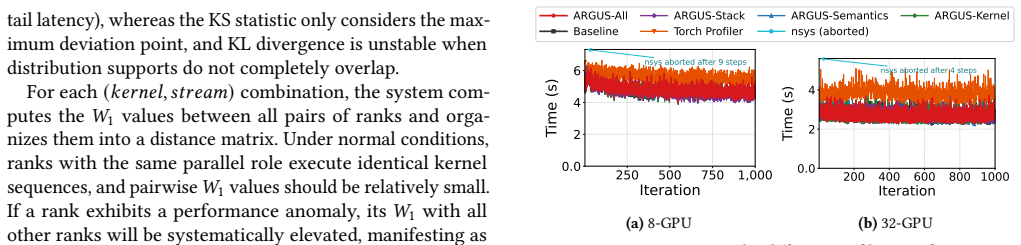
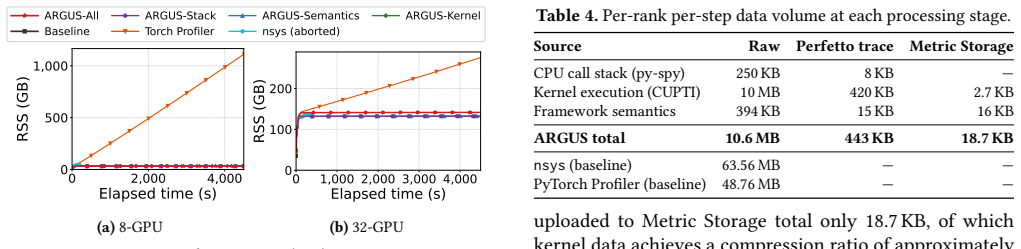



read the original abstract
Large-scale LLM training requires always-on, fine-grained observability for effective performance diagnosis at scale. Coarse resource monitors alone cannot localize root causes, and fine-grained profilers incur prohibitive (5%-30%) overheads and massive trace volumes, making always-on deployment impractical in large production clusters. We propose ARGUS, a low-overhead, fine-grained, always-on tracing and real-time analysis system for training workloads in 10,000+ GPU-scale production clusters. ARGUS decomposes observation along the training call hierarchy into CPU call stacks, framework semantics, and GPU kernel execution, with always-on collection under a combined overhead of less than 2%. It builds a unified data pipeline and compresses raw kernel events by approximately 3,700x from 10 MB to 2.7 KB per rank per step. Its progressive diagnosis framework automatically isolates anomalous windows, straggler ranks, and degraded kernels through iteration-time, phase-level, and kernel-level analysis. Deployed for over six months on a 10,000+ GPU production cluster, ARGUS has supported continuous fail-slow detection and performance optimization. Our case studies further demonstrate its effectiveness across representative anomalies, including compute stragglers, link degradation, pipeline-bubble amplification, FlashAttention JIT stalls, and compute stragglers masked by communication symptoms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ARGUS, a tracing and performance diagnosis system for LLM training on 10,000+ GPU clusters. It claims always-on fine-grained observability via hierarchical decomposition into CPU call stacks, framework semantics, and GPU kernels, achieving <2% combined overhead and ~3700x compression (10 MB to 2.7 KB per rank per step). A progressive diagnosis pipeline isolates anomalies at iteration, phase, and kernel levels. The system was deployed for over six months in production, supporting fail-slow detection and optimization, with case studies on compute stragglers, link degradation, pipeline bubbles, FlashAttention JIT stalls, and masked stragglers.
Significance. If the overhead, compression, and diagnostic fidelity claims hold under production workloads, ARGUS would represent a meaningful advance in enabling continuous, fine-grained monitoring for large-scale distributed training where existing profilers are too costly. The reported six-month deployment on a real 10k+ GPU cluster and the listed case studies provide practical evidence of utility beyond synthetic benchmarks.
major comments (2)
- [Abstract] Abstract: The central claim that the 3700x compression and hierarchical decomposition (CPU stacks / framework semantics / GPU kernels) plus progressive diagnosis pipeline 'automatically isolates' root causes without material loss of fidelity is load-bearing but unsupported by any quantitative metric (e.g., root-cause recall against raw traces, false-positive rates, or comparison to unaggregated baselines). The five case studies are listed but supply no precision, recall, or error-bar data.
- [Abstract] Abstract (deployment paragraph): The statement that ARGUS 'has supported continuous fail-slow detection and performance optimization' for six months is presented without any aggregate statistics on detected anomalies, false-alarm rates, or before/after performance improvements across the cluster, making it impossible to assess whether the system meets its diagnostic goals at scale.
minor comments (1)
- [Abstract] The abstract repeatedly uses 'stragglers' in two separate case studies without clarifying whether these are distinct phenomena or a duplication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger quantitative support in the abstract. We address each major comment below and commit to revisions that add the requested metrics where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the 3700x compression and hierarchical decomposition (CPU stacks / framework semantics / GPU kernels) plus progressive diagnosis pipeline 'automatically isolates' root causes without material loss of fidelity is load-bearing but unsupported by any quantitative metric (e.g., root-cause recall against raw traces, false-positive rates, or comparison to unaggregated baselines). The five case studies are listed but supply no precision, recall, or error-bar data.
Authors: We agree that the abstract's claims on automatic root-cause isolation would be strengthened by quantitative metrics. The case studies provide concrete demonstrations of the progressive diagnosis pipeline isolating issues at different levels, but they are presented qualitatively. In the revision we will add a dedicated evaluation subsection that reports root-cause recall and false-positive rates by comparing ARGUS outputs against manually labeled ground truth from the raw traces in the five case studies, along with error bars where multiple runs are available. revision: yes
-
Referee: [Abstract] Abstract (deployment paragraph): The statement that ARGUS 'has supported continuous fail-slow detection and performance optimization' for six months is presented without any aggregate statistics on detected anomalies, false-alarm rates, or before/after performance improvements across the cluster, making it impossible to assess whether the system meets its diagnostic goals at scale.
Authors: The six-month deployment claim is currently stated qualitatively based on operational experience. We acknowledge that aggregate statistics would allow readers to better evaluate impact at scale. In the revised manuscript we will include available deployment data, such as the total number of anomalies flagged, observed false-alarm incidents, and documented performance gains from optimizations informed by ARGUS. revision: yes
Circularity Check
No circularity: systems description with no derivations or self-referential predictions
full rationale
The paper is a systems-engineering description of ARGUS (architecture, hierarchical decomposition into CPU stacks/framework/GPU kernels, compression pipeline, progressive diagnosis, and six-month deployment on a 10k+ GPU cluster). It reports measured overhead (<2%), compression ratio (~3700x), and case studies but contains no equations, fitted parameters, uniqueness theorems, or predictions that reduce to their own inputs by construction. No self-citation load-bearing steps appear in the provided text. The central claims rest on empirical deployment and qualitative case studies rather than any mathematical derivation chain, so no circularity is present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI at Meta. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
Pith/arXiv arXiv 2024
-
[2]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language Models are Few-Shot Learners. InAdvances in Neural Information Processing Systems 33 (NeurIPS)
2020
-
[3]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradb...
2023
-
[4]
Cloud Native Computing Foundation. 2024. Prometheus: Monitoring system and time series database.https://prometheus.io
2024
-
[5]
Weihao Cui, Ji Zhang, Han Zhao, Chao Liu, Jian Sha, Bo Sang, Bing- sheng He, Minyi Guo, and Quan Chen. 2026. FLARE: Anomaly Diag- nostics for Divergent LLM Training in GPU Clusters of Thousand-Plus Scale. In23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26). USENIX Association, Renton, WA, 1021– 1035
2026
-
[6]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[7]
InAdvances in Neural Information Processing Systems 35 (NeurIPS)
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems 35 (NeurIPS)
-
[8]
Dao-AILab. 2025. FlashAttention-4: CuTe DSL JIT Compilation and Caching.https://github.com/Dao-AILab/flash-attention
2025
-
[9]
Datadog. 2024. Vector: A lightweight, ultra-fast tool for building observability pipelines.https://vector.dev
2024
-
[10]
Yangtao Deng, Xiang Shi, Zhuo Jiang, Xingjian Zhang, Lei Zhang, Zhang Zhang, Bo Li, Zuquan Song, Hang Zhu, Gaohong Liu, Fuliang Li, Shuguang Wang, Haibin Lin, Jianxi Ye, and Minlan Yu. 2025. Minder: Faulty Machine Detection for Large-scale Distributed Model Training. In22nd USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 25). USENI...
2025
-
[11]
Yangtao Deng, Lei Zhang, Qinlong Wang, Xiaoyun Zhi, Xinlei Zhang, Zhuo Jiang, Haohan Xu, Lei Wang, Zuquan Song, Gaohong Liu, Yang Bai, Shuguang Wang, Wencong Xiao, Jianxi Ye, Minlan Yu, and Hong Xu. 2025. Mycroft: Tracing Dependencies in Collective Communication Towards Reliable LLM Training. InProceedings of the ACM SIGOPS 31st Symposium on Operating Sys...
2025
-
[12]
Jianbo Dong, Bin Luo, Jun Zhang, Pengcheng Zhang, Fei Feng, Yikai Zhu, Ang Liu, Zian Chen, Yi Shi, Hairong Jiao, Gang Lu, Yu Guan, Ennan Zhai, Wencong Xiao, Hanyu Zhao, Man Yuan, Siran Yang, Xiang Li, Jiamang Wang, Rui Men, Jianwei Zhang, Chang Zhou, Dennis Cai, Yuan Xie, and Binzhang Fu. 2025. Enhancing Large-Scale AI Training Efficiency: The C4 Solution...
2025
-
[13]
Jianbo Dong, Kun Qian, Pengcheng Zhang, Zhilong Zheng, Liang Chen, Fei Feng, Yichi Xu, Yikai Zhu, Gang Lu, Xue Li, Zhihui Ren, Zhicheng Wang, Bin Luo, Peng Zhang, Yang Liu, Yanqing Chen, Yu Guan, Weicheng Wang, Chaojie Yang, Yang Zhang, Man Yuan, Hanyu Zhao, Yong Li, Zihan Zhao, Shan Li, Xianlong Zeng, Zhiping Yao, Binzhang Fu, Ennan Zhai, Wei Lin, Chao W...
2025
-
[14]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
2022
-
[15]
Ben Frederickson. 2024. py-spy: Sampling profiler for Python programs. https://github.com/benfred/py-spy
2024
-
[16]
Google. 2024. Perfetto: System-wide profiling for Android and Linux. https://perfetto.dev
2024
-
[17]
Grafana Labs. 2024. Grafana: The open observability platform.https: //grafana.com
2024
-
[18]
Yu Guan, Zhiyu Yin, Haoyu Chen, Sheng Cheng, Chaojie Yang, Kun Qian, Tianyin Xu, Pengcheng Zhang, Yang Zhang, Hanyu Zhao, Yong Li, Dennis Cai, and Ennan Zhai. 2026. EROICA: Online Performance Troubleshooting for Large-scale Model Training. In23rd USENIX Sym- posium on Networked Systems Design and Implementation (NSDI 26). USENIX Association, Renton, WA, 1113–1130
2026
-
[19]
Qinghao Hu, Zhisheng Ye, Zerui Wang, Guoteng Wang, Meng Zhang, Qiaoling Chen, Peng Sun, Dahua Lin, Xiaolin Wang, Yingwei Luo, Yonggang Wen, and Tianwei Zhang. 2024. Characterization of Large Language Model Development in the Datacenter. In21st USENIX Sym- posium on Networked Systems Design and Implementation (NSDI 24). USENIX Association, Santa Clara, CA, 709–729
2024
-
[20]
Songlin Huang and Chenshu Wu. 2025. Neutrino: Fine-grained GPU Kernel Profiling via Programmable Probing. In19th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 25). USENIX Association, Boston, MA, 331–344
2025
-
[21]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. 2019. GPipe: Efficient Training of Giant Neu- ral Networks Using Pipeline Parallelism. InAdvances in Neural In- formation Processing Systems 32 (NeurIPS). Curran Associates, Inc., Vancouver, BC, Canada, 103–112
2019
-
[22]
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, 13 Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xi...
2024
-
[23]
Brown, Ben- jamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Ben- jamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models.arXiv preprint arXiv:2001.08361(2020)
Pith/arXiv arXiv 2020
-
[24]
Apostolos Kokolis, Michael Kuchnik, John Hoffman, Adithya Kumar, Parth Malani, Faye Ma, Zachary DeVito, Shubho Sengupta, Kalyan Saladi, and Carole-Jean Wu. 2024. Revisiting Reliability in Large-Scale Machine Learning Research Clusters.arXiv preprint arXiv:2410.21680 (2024)
arXiv 2024
-
[25]
Jinkun Lin, Ziheng Jiang, Zuquan Song, Sida Zhao, Menghan Yu, Zhanghan Wang, Chenyuan Wang, Zuocheng Shi, Xiang Shi, Wei Jia, Zherui Liu, Shuguang Wang, Haibin Lin, Xin Liu, Aurojit Panda, and Jinyang Li. 2025. Understanding Stragglers in Large Model Train- ing Using What-if Analysis. In19th USENIX Symposium on Operating Systems Design and Implementation ...
2025
-
[26]
Meta Research. 2024. Holistic Trace Analysis: A Library to Analyze PyTorch Traces.https://github.com/facebookresearch/ HolisticTraceAnalysis
2024
-
[27]
Devanur, Gregory R
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized Pipeline Parallelism for DNN Training. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP ’19). Association for Computing Machinery, New York, NY, USA, 1–15
2019
-
[28]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. InProceedings of the International Conference for High...
2021
-
[29]
NVIDIA. 2024. CUDA C++ Programming Guide: Asynchronous Concurrent Execution and Events.https://docs.nvidia.com/cuda/ cuda-c-programming-guide/
2024
-
[30]
NVIDIA. 2024. CUPTI: CUDA Profiling Tools Interface.https: //developer.nvidia.com/cupti
2024
-
[31]
NVIDIA. 2024. NCCL: NVIDIA Collective Communications Library. https://developer.nvidia.com/nccl
2024
-
[32]
NVIDIA. 2025. NVIDIA CUTLASS Documentation: CuTe DSL Introduc- tion.https://docs.nvidia.com/cutlass/4.4.1/media/docs/pythonDSL/ cute_dsl_general/dsl_introduction.html
2025
-
[33]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Brad- bury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, Hi...
2019
-
[34]
PyTorch. 2025. Kineto: A CPU+GPU Profiling Library.https://github. com/pytorch/kineto
2025
-
[35]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[36]
InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis
ZeRO: Memory Optimizations Toward Training Trillion Param- eter Models. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–16
-
[37]
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2022. BLOOM: A 176B-Parameter Open- Access Multilingual Language Model.arXiv preprint arXiv:2211.05100 (2022)
Pith/arXiv arXiv 2022
-
[38]
David W. Scott. 1992.Multivariate Density Estimation: Theory, Practice, and Visualization. John Wiley & Sons
1992
-
[39]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. InarXiv preprint arXiv:1909.08053
Pith/arXiv arXiv 2019
-
[40]
Tencent Hunyuan Team. 2024. HunYuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent.arXiv preprint arXiv:2411.02265(2024)
arXiv 2024
-
[41]
John W. Tukey. 1977.Exploratory Data Analysis. Addison-Wesley
1977
-
[42]
2009.Optimal Transport: Old and New
Cédric Villani. 2009.Optimal Transport: Old and New. Springer
2009
-
[43]
Borui Wan, Gaohong Liu, Zuquan Song, Jun Wang, Yun Zhang, Guangming Sheng, Shuguang Wang, Houmin Wei, Chenyuan Wang, Weiqiang Lou, Xi Yang, Mofan Zhang, Kaihua Jiang, Cheng Ren, Xi- aoyun Zhi, Menghan Yu, Zhe Nan, Zhuolin Zheng, Baoquan Zhong, Qinlong Wang, Huan Yu, Jinxin Chi, Wang Zhang, Yuhan Li, Zixian Du, Sida Zhao, Yongqiang Zhang, Jingzhe Tang, Zhe...
2025
-
[44]
Tianyuan Wu, Wei Wang, Yinghao Yu, Siran Yang, Wenchao Wu, Qinkai Duan, Guodong Yang, Jiamang Wang, Lin Qu, and Liping Zhang
-
[45]
In2025 USENIX Annual Technical Conference (USENIX ATC 25)
GREYHOUND: Hunting Fail-Slows in Hybrid-Parallel Training at Scale. In2025 USENIX Annual Technical Conference (USENIX ATC 25). USENIX Association, Boston, MA, 731–747
-
[46]
Zhiyi Yao, Pengbo Hu, Congcong Miao, Xuya Jia, Zuning Liang, Yue- dong Xu, Chunzhi He, Hao Lu, Mingzhuo Chen, Xiang Li, Zekun He, Yachen Wang, Xianneng Zou, and Juncheng Jiang. 2025. Holmes: Lo- calizing Irregularities in LLM Training with Mega-scale GPU Clusters. In22nd USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 25). USENIX A...
2025
-
[47]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.Proceedings of the VLDB Endowment16, 12 ...
2023
-
[48]
take buffer
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Au- tomating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX As...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.